さまざまなビジネスシナリオの要件をより適切に満たすために、StarRocks は複数のデータモデルをサポートしています。StarRocks に保存されるデータは、特定のモデルに基づいて編成する必要があります。このトピックでは、さまざまなインポート方法の基本的な概念、原則、システム構成、およびシナリオについて説明します。ベストプラクティスと FAQ についても、このトピックで説明します。
背景情報
データインポート機能を使用すると、対応するモデルに基づいて生データをクレンジングおよび変換し、後続のデータクエリと使用のために StarRocks にインポートできます。StarRocks は複数のインポート方法をサポートしています。インポートするデータの量またはインポート頻度に基づいて、ビジネス要件を満たすインポート方法を使用できます。
次の図は、さまざまなデータソースと、StarRocks でサポートされている対応するインポート方法を示しています。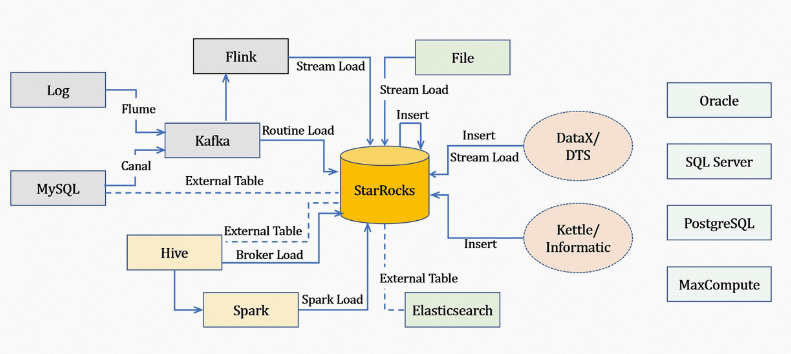
使用するデータソースに基づいて、インポート方法を選択できます。
オフラインデータのインポート:使用するデータソースが Hive または Hadoop 分散ファイルシステム(HDFS)の場合、Broker Load インポート方法を使用することをお勧めします。多数のデータテーブルをインポートする場合は、データ移行を必要としない Hive 外部テーブルを使用できます。ただし、Hive 外部テーブルのパフォーマンスは Broker Load インポート方法よりも低くなります。
リアルタイムデータのインポート:ログデータとバイナリデータベースログを Kafka に同期した後、Routine Load インポート方法を使用して StarRocks にデータをインポートすることをお勧めします。Routine Load 複数テーブルの結合と ETL(抽出、変換、書き出し)操作が必要な場合は、Flink コネクタ を使用して事前にデータを処理できます。次に、Stream Load インポート方法を使用して、データを StarRocks に書き込みます。
プログラムから StarRocks へのデータのインポート:Stream Load インポート方法を使用することをお勧めします。Stream Load トピックのサンプル Java コードまたは Python コードを参照できます。
テキストファイルのインポート:Stream Load インポート方法を使用することをお勧めします。
MySQL からのデータのインポート:MySQL 外部テーブルを使用し、
insert into new_table select * from external_table文を実行してデータをインポートすることをお勧めします。StarRocks 内のデータのインポート:外部スケジューラと共に INSERT インポート方法を使用して、単純な ETL 処理を実装することをお勧めします。
このトピックの画像と一部の情報は、オープンソース StarRocks のデータロードの概要からのものです。
使用上の注意
StarRocks にデータをインポートするために、プログラム接続が確立されることがよくあります。StarRocks にデータをインポートする際は、次の点に注意してください。
適切なインポート方法を選択します。データ量、インポート頻度、またはデータソースの場所に基づいて、インポート方法を選択できます。
たとえば、生データが HDFS に保存されている場合は、Broker Load メソッドを使用してデータをインポートできます。
インポート方法のプロトコルを決定します。Broker Load インポート方法を使用する場合、外部システムは MySQL プロトコルを使用して、定期的にインポートジョブを送信および表示できる必要があります。
データインポートのモードを決定します。データインポートは、同期モードと非同期モードに分類されます。非同期モードを使用する場合、外部システムはコマンドを実行してデータインポートを表示し、コマンドの結果に基づいてインポートが成功したかどうかを判断する必要があります。
ラベル生成ポリシーを設定します。ラベル生成ポリシーは、各ジョブでインポートされるデータが一意で静的である必要があるという原則を満たしている必要があります。
Exactly-Once 配信を確保します。外部システムはデータインポートの少なくとも 1 回の配信を保証し、StarRocks のラベルメカニズムはデータインポートの最大 1 回の配信を保証します。これにより、データインポート全体で Exactly-Once 配信を実現できます。
用語
用語 | 説明 |
インポートジョブ | インポートジョブは、指定されたデータソースからデータを読み取り、データをクレンジングおよび変換してから、StarRocks にインポートするために使用されます。データがインポートされると、データをクエリできます。 |
ラベル | ラベルは、インポートジョブを識別するために使用されます。各インポートジョブにはラベルがあります。 インポートジョブのラベルを指定することも、システム生成のラベルを使用することもできます。ラベルはデータベース内で一意です。各ラベルは 1 つのインポートジョブにのみ使用できます。インポートジョブが完了した後、このインポートジョブのラベルを再利用して別のインポートジョブを送信することはできません。失敗したインポートジョブのラベルのみ再利用できます。このメカニズムにより、特定のラベルに関連付けられたデータは 1 回だけインポートされます。これにより、最大 1 回のセマンティクスが実装されます。 |
原子性 | StarRocks によって提供されるすべてのインポート方法は、原子性を保証します。原子性とは、ジョブ内のすべての適格データがインポートされるか、適格データがまったくインポートされないかのいずれかであることを示します。適格データには、データ型の変換エラーなど、品質の問題により除外されたデータは含まれません。 |
MySQL プロトコルと HTTP プロトコル | StarRocks では、MySQL プロトコルと HTTP プロトコルを使用してインポートジョブを送信できます。 |
Broker Load | デプロイされたブローカーを使用して HDFS などの外部データソースからデータを読み取り、StarRocks にデータをインポートするインポート方法。ブローカープロセスは計算リソースを使用して、データを前処理およびインポートします。 |
FE | フロントエンド(FE)ノードは、StarRocks のメタデータおよびスケジューリングノードです。データインポートプロセス中に、FE ノードを使用してインポート実行計画を生成し、インポートジョブをスケジュールします。 |
BE | バックエンド(BE)ノードは、StarRocks の計算およびストレージノードです。BE ノードは、データに対して ETL 操作を実行し、データを保存するために使用されます。 |
タブレット | タブレットは、StarRocks テーブルの論理シャードです。StarRocks テーブルは、パーティションルールとバケットルールに基づいて複数のタブレットに分割できます。詳細については、「Apache StarRocks」を参照してください。 |
基本原則
次の図は、インポートジョブの実行方法を示しています。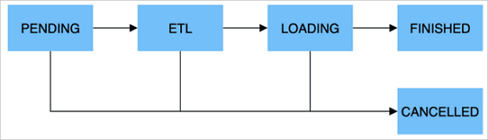
次の表に、インポートジョブのステージを示します。
ステージ | 説明 |
PENDING | オプション。ジョブが送信され、FE ノードによるスケジュールを待機しています。 |
ETL | オプション。データが前処理されます。これには、クレンジング、パーティション分割、ソート、および集約が含まれます。 |
LOADING | データがクレンジング、変換され、BE ノードに送信されて処理されます。すべてのデータがインポートされると、データはキューに入れられ、有効になるのを待機します。この場合、ジョブステータスは LOADING のままです。 |
FINISHED | データが有効になると、ジョブステータスは FINISHED に変わり、データをクエリできます。FINISHED は、インポートジョブの最終ステータスです。 |
CANCELLED | ジョブが FINISHED 状態になる前に、いつでもジョブをキャンセルできます。インポートエラーが発生した場合、StarRocks はジョブを自動的にキャンセルすることもできます。CANCELLED も、インポートジョブの最終ステータスです。 |
次の表に、サポートされているデータ型を示します。
データ型 | 説明 |
整数 | TINYINT、SMALLINT、INT、BIGINT、および LARGEINT。例:1、1000、1234。 |
浮動小数点 | FLOAT、DOUBLE、および DECIMAL。例:1.1、0.23、0.356。 |
日付 | DATE および DATETIME。例:2017-10-03 および 2017-06-13 12:34:03。 |
文字列 | CHAR および VARCHAR。例:"I am a student" および "a"。 |
インポート方法
さまざまなデータインポート要件を満たすために、StarRocks は HDFS、Kafka、オンプレミスファイルなど、さまざまなデータソースからデータをインポートするためのさまざまな方法を提供しています。StarRocks では、同期モードと非同期モードでデータをインポートできます。
すべてのインポート方法は CSV データ形式をサポートしています。Broker Load は、Parquet および ORC データ形式もサポートしています。
データインポート方法
インポート方法 | 説明 | インポートモード |
Broker Load | この方法は、ブローカープロセスを使用して外部ソースからデータを読み取り、MySQL プロトコルを使用して StarRocks にデータをインポートするジョブを作成します。送信されたジョブは非同期モードで実行されます。 この方法は、インポートするデータが HDFS などのブローカープロセスにアクセスできるシステムに保存されており、データ量が数十ギガバイトから数百ギガバイトの範囲である場合に適しています。 | 非同期モード |
Stream Load | この方法は、同期モードで StarRocks にデータをインポートします。HTTP リクエストを送信して、オンプレミスファイルまたはデータストリームを StarRocks にインポートし、システムがインポート結果を返すのを待機できます。返された結果に基づいて、インポートが成功したかどうかを判断できます。 Stream Load は、プログラムを使用して、オンプレミスファイルまたはデータストリームからデータをインポートする場合に適しています。詳細については、「Stream Load」をご参照ください。 | 同期モード |
Routine Load | この方法は、指定されたデータソースからデータを自動的にインポートします。MySQL プロトコルを使用して、ルーチンインポートジョブを送信できます。次に、常駐スレッドが生成され、Kafka などのデータソースから継続的にデータを読み取り、StarRocks にインポートします。詳細については、「Routine Load」をご参照ください。 | 非同期モード |
Insert Into | この方法は、MySQL の INSERT 文と同様の方法で使用されます。StarRocks では、 | 同期モード |
インポートモード
外部プログラムを使用してデータをインポートする場合は、インポートロジックを決定する前にインポート方法を選択する必要があります。
同期モード
同期モードでは、外部システムがインポートジョブを作成した後、StarRocks はジョブを同期的に実行します。インポートジョブが完了すると、StarRocks はインポート結果を返します。外部システムは、戻り値の結果に基づいて、インポートが成功したかどうかを判断できます。
手順:
外部システムがインポートジョブを作成します。
StarRocks はインポート結果を返します。
外部システムはインポート結果を判断します。インポートジョブが失敗した場合、別のインポートジョブを作成できます。
非同期モード
非同期モードでは、外部システムがインポートジョブを作成した後、StarRocks はジョブが作成されたことを示す結果を返します。これは、データがインポートされたことを意味するわけではありません。インポートジョブは非同期的に実行されます。ジョブが作成されると、外部システムは特定のコマンドを実行して、インポートジョブのステータスをポーリングします。インポートジョブの作成に失敗した場合、外部システムは失敗情報に基づいて別のインポートジョブを作成するかどうかを判断できます。
手順:
外部システムがインポートジョブを作成します。
StarRocks はインポートジョブの作成結果を返します。
外部システムは、戻り値の結果に基づいて次の手順に進むかどうかを判断します。インポートジョブが作成された場合は、手順 4 に進みます。インポートジョブの作成に失敗した場合は、手順 1 に戻り、インポートジョブを再度作成します。
外部システムは、ステータスが FINISHED または CANCELLED に変わるまで、インポートジョブのステータスをポーリングします。
シナリオ
シナリオ | 説明 |
HDFS からデータをインポートする | HDFS に保存されているデータをインポートする場合、データ量が数十ギガバイトから数百ギガバイトの範囲である場合は、Broker Load を使用して StarRocks にデータをインポートできます。この場合、HDFS データソースは、デプロイされたブローカープロセスにアクセスできる必要があります。インポートジョブは非同期モードで実行されます。 |
オンプレミスファイルをインポートする | データがオンプレミスファイルに保存されており、データ量が 10 GB 未満の場合は、Stream Load を使用してデータを StarRocks にすばやくインポートできます。HTTP プロトコルを使用してインポートジョブを作成し、同期モードでインポートジョブを実行できます。次に、HTTP リクエストの戻り値の結果に基づいて、インポートが成功したかどうかを判断できます。 |
Kafka からデータをインポートする | Kafka などのストリーミングデータソースから StarRocks にリアルタイムでデータをインポートする場合は、Routine Load を使用できます。StarRocks が Kafka から継続的にデータを読み取ってインポートできるようにするには、MySQL プロトコルを使用してルーチンインポートジョブを作成します。 |
INSERT INTO 文を使用してデータをインポートする | テストを実行する場合、または一時データを処理する場合は、INSERT INTO ステートメントを使用して StarRocks テーブルにデータを書き込むことができます。 INSERT INTO tbl SELECT ...; 文は、StarRocks テーブルからデータを読み取り、別のテーブルにデータをインポートするために使用されます。 |
メモリ制限
パラメータを構成して、単一インポートジョブのメモリサイズを制限できます。これにより、インポートジョブが過剰なメモリを占有してメモリ不足(OOM)エラーが発生することを防ぎます。ジョブのメモリサイズを制限するために使用される方法は、インポート方法によって異なります。詳細については、各インポート方法の対応するトピックを参照してください。
ほとんどの場合、インポートジョブは複数の BE ノードで実行されます。単一 BE ノードのインポートジョブのメモリサイズを制限するようにパラメータを構成できます。各 BE ノードのインポートジョブで使用できる最大メモリサイズを指定することもできます。詳細については、このトピックの一般的なシステム構成トピックを参照してください。
インポートジョブのメモリサイズを小さく指定すると、メモリ使用量が上限に達したときにデータが頻繁にディスクに書き込まれるため、インポート効率に影響を与える可能性があります。ジョブのメモリサイズを過度に大きく指定すると、インポートの同時実行性が高いため、OOM エラーが発生する可能性があります。ビジネス要件に基づいて、メモリ関連のパラメータを構成する必要があります。
一般的なシステム構成
FE ノードの構成
次の表に、FE ノードのシステムパラメータを示します。fe.conf 構成ファイルのパラメータを変更できます。
パラメータ | 説明 |
max_load_timeout_second | インポートの最大タイムアウト期間と最小タイムアウト期間。単位:秒。デフォルトでは、最大タイムアウト期間は 3 日、最小タイムアウト期間は 1 秒です。指定するインポートタイムアウト期間はこの範囲内である必要があります。このパラメータは、すべてのタイプのインポートジョブに有効です。 |
min_load_timeout_second | |
desired_max_waiting_jobs | 待機キューが収容できるインポートジョブの最大数。デフォルト値:100。 たとえば、FE ノードの PENDING 状態のインポートジョブの数がこのパラメータの値に達すると、新しいインポートリクエストは拒否されます。PENDING 状態は、インポートジョブが実行されるのを待機していることを示します。このパラメータは、非同期インポートジョブにのみ有効です。PENDING 状態の非同期インポートジョブの数が上限に達すると、後続のインポートジョブの作成リクエストは拒否されます。 |
max_running_txn_num_per_db | 各データベースで許可される進行中のインポートジョブの最大数。デフォルト値:100。 データベースで実行されるインポートジョブの数が指定した最大数に達すると、後続のインポートジョブは実行されません。この状況で同期インポートジョブが送信されると、ジョブは拒否されます。非同期インポートジョブが送信されると、ジョブはキューで待機します。 |
label_keep_max_second | インポートジョブの履歴レコードの保存期間。 StarRocks は、完了し、FINISHED または CANCELLED 状態にあるインポートジョブのレコードを一定期間保持します。このパラメータを使用して保存期間を設定できます。デフォルトの保存期間は 3 日です。このパラメータは、すべてのタイプのインポートジョブに有効です。 |
BE ノードの構成
次の表に、BE ノードのシステムパラメータを示します。be.conf 構成ファイルのパラメータを変更できます。
パラメータ | 説明 |
push_write_mbytes_per_sec | BE ノードの 1 タブレットあたりの最大書き込み速度。デフォルト値は 10 で、書き込み速度が 10 MB/s であることを示します。 ほとんどの場合、最大書き込み速度はスキーマと使用されるシステムに基づいて 10 MB/s から 30 MB/s の範囲です。このパラメータの値を変更して、データのインポート速度を制御できます。 |
write_buffer_size | 最大メモリブロックサイズ。インポートされたデータは、最初に BE ノードのメモリブロックに書き込まれます。インポートされたデータの量が指定した最大メモリブロックサイズに達すると、データはディスクに書き込まれます。デフォルトサイズは 100 MB です。 最大メモリブロックサイズが非常に小さい場合、BE ノードに多数の小さなファイルが生成される可能性があります。最大メモリブロックサイズを増やすと、生成されるファイルの数を減らすことができます。最大メモリブロックサイズが過度に大きい場合、リモートプロシージャコール(RPC)がタイムアウトする可能性があります。詳細については、tablet_writer_rpc_timeout_sec パラメータの説明を参照してください。 |
tablet_writer_rpc_timeout_sec | インポートプロセス中にデータのバッチ(1024 行)を送信するための RPC タイムアウト期間。デフォルト値:600。単位:秒。 RPC には、複数のタブレットのメモリブロック内のデータをディスクに書き込む操作が含まれる場合があります。この場合、ディスク書き込み操作が原因で RPC タイムアウトが発生する可能性があります。RPC タイムアウト期間を調整して、send batch fail エラーなどのタイムアウトエラーを減らすことができます。write_buffer_size パラメータを高い値に設定する場合は、tablet_writer_rpc_timeout_sec パラメータの値も増やす必要があります。 |
streaming_load_rpc_max_alive_time_sec | 各 Writer スレッドの待機タイムアウト期間。データインポートプロセス中に、StarRocks は Writer スレッドを起動して、各タブレットからデータを受信し、各タブレットにデータを書き込みます。デフォルト値:600。単位:秒。 Writer プロセスが指定した待機タイムアウト期間内にデータを受信しない場合、StarRocks は Writer スレッドを自動的に破棄します。システムが低速でデータを処理する場合、Writer スレッドは長時間次のバッチのデータを受信しない可能性があり、そのため |
load_process_max_memory_limit_percent | 各 BE ノードのすべてのインポートジョブに使用できるメモリの最大量と最大パーセンテージ。StarRocks は、2 つのパラメータの値のうち小さい方のメモリ消費量を、許可される最終的なメモリ消費量として識別します。
|
load_process_max_memory_limit_bytes |