StarRocks では、オンプレミス マシンから 10 GB 未満の CSV ファイルをインポートできます。このトピックでは、Stream Load の基本原則とベストプラクティスについて説明します。また、Stream Load モードでデータをインポートする方法の例も示します。
背景情報
Stream Load は同期インポート方式であり、HTTP リクエストを送信することで、オンプレミス ファイルまたはデータストリームを StarRocks にインポートできます。Stream Load モードでは、インポートが完了した後にインポート結果が返されます。リクエストの戻り値に基づいて、インポートが成功したかどうかを判断できます。
用語
coordinator: データを受信し、他のデータノードにデータを配信し、データのインポート後に結果を返すノード。
基本原則
Stream Load では、HTTP リクエストを送信することでインポートジョブを送信できます。フロントエンド(FE)ノードにリクエストを送信すると、FE ノードは HTTP リダイレクトを実行してリクエストをバックエンド(BE)ノードに転送します。BE ノードに直接リクエストを送信することもできます。 BE ノードはコーディネーターノードとして機能し、テーブルスキーマによってデータを分割し、関連する BE ノードにデータを配信します。その後、コーディネーターノードはインポートジョブの結果を返します。
次の図は、Stream Load の仕組みを示しています。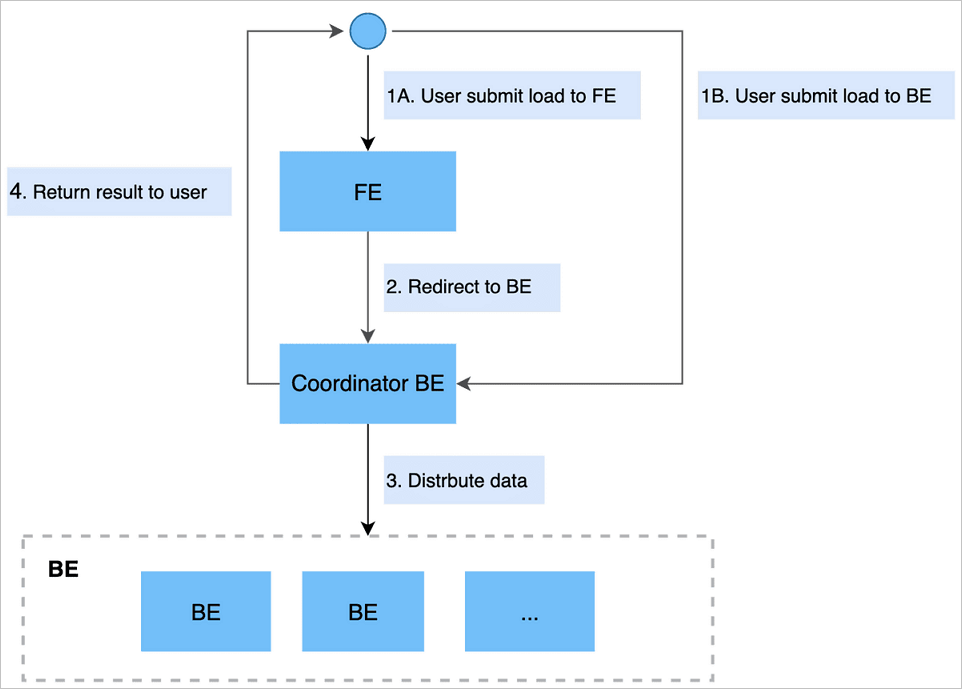
例
インポートジョブの作成
Stream Load モードでは、データは HTTP プロトコルを使用して送信および転送されます。この例では、curl コマンドを使用してインポートジョブを送信します。他の HTTP クライアントを使用してデータを送信および転送することもできます。
構文
curl --location-trusted -u user:passwd [-H ""...] -T data.file -XPUT \
http://fe_host:http_port/api/{db}/{table}/_stream_loadHTTP はチャンク転送エンコーディングと非チャンク転送エンコーディングをサポートしています。非チャンク転送エンコーディングの場合、Content-Length ヘッダーフィールドを使用して、アップロードするコンテンツの長さを指定する必要があります。これにより、データ整合性が確保されます。
エラーが発生した場合に不要なデータ送信を防ぐために、Expect ヘッダーを 100-continue に設定することをお勧めします。
サポートされているヘッダープロパティは、次の表のインポートジョブパラメーターの説明で確認できます。パラメーターは -H "key1:value1" 形式で構成されます。複数のパラメーターが関係する場合は、複数 -H を使用してパラメーターを示す必要があります。例: -H "key1:value1" -H "key2:value2"。 Stream Load モードでは、インポートジョブに関連するすべてのパラメーターがヘッダーで構成されます。次の表にパラメーターを示します。
パラメーター | 説明 | |
署名パラメーター | user:passwd | Stream Load では、インポートジョブは HTTP プロトコルを使用して作成されます。基本アクセス認証を使用して、インポートジョブの署名が生成されます。 StarRocks は、署名に基づいてユーザー ID とインポート権限を認証します。 |
インポートジョブパラメーター | label | インポートジョブのラベル。同じラベルのデータは繰り返しインポートできません。 インポートジョブのラベルを指定して、データが繰り返しインポートされないようにすることができます。 StarRocks は、過去 30 分以内に完了したジョブのラベルを保持します。 |
column_separator | インポートするファイルの列区切り文字。デフォルト値: \t。 印刷不可文字が列区切り文字として使用される場合、区切り文字は 16 進数形式で、\x プレフィックスで始まる必要があります。たとえば、Hive ファイルの列区切り文字が \x01 の場合、このパラメーターを | |
row_delimiter | インポートするファイルの行区切り文字。デフォルト値: \n。 重要 \n は curl コマンドを使用して渡すことはできません。行区切り文字として \n を指定すると、Shell は \n を直接渡すのではなく、最初にバックスラッシュ(\)を渡し、次に n を渡します。 Bash スクリプトを使用して文字列をエスケープできます。 \n と \t を渡す場合は、文字列をドル記号($)と全角一重引用符(')で開始し、半角一重引用符(')で終了します。例: | |
columns | インポートするファイルの列と StarRocks テーブルの列間のマッピング。 ソースファイルの列が StarRocks テーブルの列と同じ場合は、このパラメーターを構成する必要はありません。それ以外の場合は、このパラメーターを構成してデータ変換ルールを指定する必要があります。このパラメーターは、次の方法で構成できます。ファイルの列名に対応する StarRocks テーブルの列名を順番に指定します。または、計算に基づいて列を指定します。
| |
where | データフィルター条件。このパラメーターを構成して、不要なデータをフィルタリングできます。 たとえば、k1 列の値が 20180601 のデータのみをインポートする場合、データインポート中にこのパラメーターを | |
max_filter_ratio | 除外できるデータの最大比率。たとえば、特定の基準に準拠していないため、データが除外されます。デフォルト値: 0。有効な値: 0 ~ 1。 説明 基準に準拠していないデータには、WHERE 条件によって除外されたデータは含まれません。 | |
partitions | データをインポートするパーティション。 データをインポートするパーティションを確認した場合は、このパラメーターを構成することをお勧めします。指定されたパーティションに属さないデータは除外されます。たとえば、p1 パーティションと p2 パーティションにデータをインポートする場合、このパラメーターを | |
timeout | インポートジョブのタイムアウト期間。デフォルト値: 600。 有効な値: 1 ~ 259200。単位: 秒。 | |
strict_mode | インポートジョブの厳密モードを有効にするかどうかを指定します。デフォルトでは、厳密モードが有効になっています。 厳密モードを無効にするには、パラメーターを | |
timezone | インポートジョブのタイムゾーン。デフォルトのタイムゾーンは UTC + 08:00 です。 このパラメーターは、インポートジョブに関係するすべてのタイムゾーン関連関数の結果に影響します。 | |
exec_mem_limit | インポートジョブで使用できるメモリの最大サイズ。デフォルト値: 2。単位: GB。 | |
例
curl --location-trusted -u root -T date -H "label:123" \
http://abc.com:8030/api/test/date/_stream_loadインポートジョブが完了すると、インポートジョブに関する情報が JSON 形式で返されます。戻り値の例:
{
"TxnId": 11672,
"Label": "f6b62abf-4e16-4564-9009-b77823f3c024",
"Status": "Success",
"Message": "OK",
"NumberTotalRows": 199563535,
"NumberLoadedRows": 199563535,
"NumberFilteredRows": 0,
"NumberUnselectedRows": 0,
"LoadBytes": 50706674331,
"LoadTimeMs": 801327,
"BeginTxnTimeMs": 103,
"StreamLoadPlanTimeMs": 0,
"ReadDataTimeMs": 760189,
"WriteDataTimeMs": 801023,
"CommitAndPublishTimeMs": 199"
}パラメーター | 説明 |
TxnId | インポートジョブのトランザクション ID。トランザクション ID は、Alibaba Cloud によって完全に管理できます。 |
Label | インポートジョブのラベル。ラベルを指定した場合、ラベルが返されます。ラベルを指定していない場合、システムは自動的にラベルを生成します。 |
Status | インポートジョブのステータス。有効な値:
|
ExistingJobStatus | 既存のラベルに対応するインポートジョブのステータス。このパラメーターは、Status パラメーターの値が Label Already Exists の場合にのみ表示されます。返された値に基づいて、既存のラベルに対応するインポートジョブのステータスを取得できます。有効な値:
|
Message | インポートジョブのステータスの詳細な説明。インポートジョブが失敗した場合、詳細な失敗原因が返されます。 |
NumberTotalRows | データストリームから読み取られたデータ行の総数。 |
NumberLoadedRows | インポートジョブでインポートされたデータ行の数。このパラメーターは、インポートジョブのステータスが Success の場合にのみ返されます。 |
NumberFilteredRows | インポートジョブで除外されたデータ行の数。品質が基準に準拠していないデータ行は除外されます。 |
NumberUnselectedRows | WHERE 条件によって除外されたデータ行の数。 |
LoadBytes | ソースファイルのデータサイズ。 |
LoadTimeMs | インポートジョブの期間。単位: ミリ秒。 |
ErrorURL | 除外されたデータエントリの URL。最初の 1,000 データエントリのみが保持されます。インポートジョブが失敗した場合、次のコマンドを実行して除外されたデータを取得できます。その後、データを分析して調整できます。 |
インポートジョブのキャンセル
Stream Load モードでは、プロセスを停止してインポートジョブをキャンセルできます。インポートジョブがタイムアウトしたか、エラーが発生した場合、システムは自動的にジョブをキャンセルします。
ps -ef | grep stream_loadベストプラクティス
シナリオ
Stream Load は、ソースファイルがメモリまたはローカルディスクに保存されているシナリオに適しています。 Stream Load は同期インポート方式です。インポートジョブの結果を同期的に取得する場合は、Stream Load でインポートジョブを送信できます。
データサイズ
Stream Load モードでは、BE ノードがデータをインポートおよび配信します。 1 GB ~ 10 GB のデータをインポートするには、Stream Load を使用することをお勧めします。デフォルトでは、Stream Load モードでインポートできるデータの最大サイズは 10 GB です。したがって、サイズが 10 GB を超えるファイルをインポートするには、BE ノードの streaming_load_max_mb パラメーターを変更する必要があります。たとえば、インポートするファイルのサイズが 15 GB(15,360 MB)の場合、BE ノードの streaming_load_max_mb パラメーターを 15 GB を超えるデータサイズに設定できます。
curl --location-trusted -u 'admin:****' -XPOST http://be-c-****-internal.starrocks.aliyuncs.com:8040/api/update_config?streaming_load_max_mb=15360Stream Load で送信されるインポートジョブのデフォルトのタイムアウト期間は 600 秒です。タイムアウト期間を調整するには、EMR コンソール で、StarRocks インスタンスの FE ノードの timeout パラメーターの値を変更します。
完全な例
データは、特定のクライアントの /mnt/disk1/customer.tbl ディレクトリに保存されています。データを StarRocks インスタンスの stream_load データベースの customer テーブルにインポートします。
データのダウンロード: customer.tbl
インスタンス情報: Stream Load モードで同時に処理できるインポートジョブの数は、インスタンスサイズの影響を受けません。
手順:
インポートするファイルのサイズがデフォルトの上限を超えている場合は、BE ノードの BE.conf 構成ファイルを変更します。たとえば、streaming_load_max_mb パラメーターを 15360 に設定できます。単位: MB。
curl --location-trusted -u 'admin:*****' -XPOST http://be-c-****-internal.starrocks.aliyuncs.com:8040/api/update_config?streaming_load_max_mb=15360インスタンスの [インスタンス構成] タブで、stream_load_default_timeout_second パラメーターの値を変更します。この例では、値を 3600 に設定します。
customer という名前の宛先テーブルを作成します。
CREATE TABLE `customer` ( `c_custkey` bigint(20) NULL COMMENT "", `c_name` varchar(65533) NULL COMMENT "", `c_address` varchar(65533) NULL COMMENT "", `c_nationkey` bigint(20) NULL COMMENT "", `c_phone` varchar(65533) NULL COMMENT "", `c_acctbal` double NULL COMMENT "", `c_mktsegment` varchar(65533) NULL COMMENT "", `c_comment` varchar(65533) NULL COMMENT "" ) ENGINE=OLAP DUPLICATE KEY(`c_custkey`) COMMENT "OLAP" DISTRIBUTED BY HASH(`c_custkey`) BUCKETS 24 PROPERTIES ( "replication_num" = "1", "in_memory" = "false", "storage_format" = "DEFAULT", "enable_persistent_index" = "false", "compression" = "LZ4" );インポートジョブを作成します。データセットに大量のデータが含まれている場合は、バックグラウンドで操作を実行できます。
curl --location-trusted -u 'admin:*****' -T /mnt/disk1/customer.tbl -H "label:labelname" -H "column_separator:|" http://fe-c-****-internal.starrocks.aliyuncs.com:8030/api/load_test/customer/_stream_load次の情報が返されます。
{ "TxnId": 575, "Label": "labelname", "Status": "Success", "Message": "OK", "NumberTotalRows": 150000, "NumberLoadedRows": 150000, "NumberFilteredRows": 0, "NumberUnselectedRows": 0, "LoadBytes": 24196144, "LoadTimeMs": 1081, "BeginTxnTimeMs": 104, "StreamLoadPlanTimeMs": 106, "ReadDataTimeMs": 85, "WriteDataTimeMs": 850, "CommitAndPublishTimeMs": 20 }説明エラー
"ErrorURL": "http://***:8040/api/_load_error_log?file=error_log_***"が報告された場合は、curlコマンドを実行して詳細を表示できます。
統合のサンプルコード
Java を使用して Stream Load でインポートジョブを送信する方法については、「stream_load」をご参照ください。
Spark を使用して Stream Load でインポートジョブを送信する方法については、「01_sparkStreaming2StarRocks」をご参照ください。