StarRocks Flink コネクタは、Stream Load を使用して Apache Flink から StarRocks テーブルへデータをストリーミングします。レコードをメモリ内にバッファリングし、バッチ単位でフラッシュすることで、大規模なデータインジェストにおいて、組み込みの flink-connector-jdbc よりも高いスループットを実現します。DataStream API、Table API & SQL、および Python API をサポートしています。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
制限事項
Flink を実行しているマシンから、StarRocks インスタンスの以下のポートへのアクセスが可能である必要があります。
FE ノード:
http_port(デフォルト:8030)およびquery_port(デフォルト:9030)BE ノード:
be_http_port(デフォルト:8040)
StarRocks のユーザーアカウントには、対象テーブルに対する SELECT 権限および INSERT 権限が必要です。
コネクタのバージョン互換性:
コネクタ Flink StarRocks Java Scala 1.2.9 1.15–1.18 2.1 以降 8 2.11、2.12 1.2.8 1.13–1.17 2.1 以降 8 2.11、2.12 1.2.7 1.11–1.15 2.1 以降 8 2.11、2.12
Flink コネクタ JAR の取得
JAR を取得するには、以下のいずれかの方法を選択し、その後 Flink クラスターにアップロードしてください。
方法 1:Maven Central からダウンロード
Maven Central Repository から直接 JAR をダウンロードします。
JAR のファイル名形式:
Flink 1.15 以降:
flink-connector-starrocks-${connector_version}_flink-${flink_version}.jar例:flink-connector-starrocks-1.2.8_flink-1.17.jarFlink 1.15 より前:
flink-connector-starrocks-${connector_version}_flink-${flink_version}_${scala_version}.jar例:flink-connector-starrocks-1.2.7_flink-1.14_2.12.jar
方法 2:Maven 依存関係として追加
pom.xml にコネクタを追加します。
Flink 1.15 以降:
<dependency> <groupId>com.starrocks</groupId> <artifactId>flink-connector-starrocks</artifactId> <version>${connector_version}_flink-${flink_version}</version> </dependency>Flink 1.15 より前:
<dependency> <groupId>com.starrocks</groupId> <artifactId>flink-connector-starrocks</artifactId> <version>${connector_version}_flink-${flink_version}_${scala_version}</version> </dependency>
方法 3:ソースコードからビルド
Flink コネクタのソースコード をクローンします。
ご利用の Flink バージョン向けに JAR をビルドします。
sh build.sh <flink_version>たとえば、 Flink 1.17 の場合:
sh build.sh 1.17生成された JAR を
target/ディレクトリで確認します。ファイル名はflink-connector-starrocks-1.2.7_flink-1.17-SNAPSHOT.jarの形式になります。非公式リリースでは、ファイル名に
SNAPSHOTサフィックスが含まれます。
Flink クラスターへの JAR のアップロード
Flink クラスター上の flink-{flink_version}/lib ディレクトリに JAR をアップロードします。
EMR-5.19.0 を実行している EMR クラスターの場合は、JAR を /opt/apps/FLINK/flink-current/lib に配置します。
Flink クラスターの起動
Flink クラスターのマスターノードにログインします。詳細については、「クラスターへのログイン」をご参照ください。
クラスターを起動します。
/opt/apps/FLINK/flink-current/bin/start-cluster.sh
設定
完全なパラメーター リファレンスについては、「Apache Flink® からデータを継続的にロードする | StarRocks」をご参照ください。
パラメーター
必須パラメーター
| パラメーター | 説明 |
|---|---|
connector | starrocks に固定されます。 |
jdbc-url | StarRocks への接続に使用する JDBC URL。形式:jdbc:mysql://<FE 内部アドレス>:9030。例:jdbc:mysql://fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:9030。FE 内部アドレスの取得方法については、「インスタンス一覧および詳細の表示」をご参照ください。 |
load-url | Stream Load 用の FE HTTP アドレス。形式:<FE 内部アドレス>:8030。例:fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:8030。 |
database-name | StarRocks のデータベース名。 |
table-name | StarRocks のテーブル名。 |
username | StarRocks のユーザーアカウント。このアカウントには、対象テーブルに対する SELECT 権限および INSERT 権限が必要です。権限の付与については、「ユーザーおよびデータ権限の管理」をご参照ください。 |
password | StarRocks ユーザーアカウントのパスワード。 |
任意パラメーター
| パラメーター | デフォルト値 | 有効な値 | 説明 |
|---|---|---|---|
sink.semantic | at-least-once | at-least-once、exactly-once | 配信セマンティクス保証。 |
sink.version | AUTO | V1、V2、AUTO | Stream Load インターフェイスのバージョン。Flink コネクタ 1.2.4 以降でサポートされています。V2 では Stream Load トランザクションインターフェイス(StarRocks 2.4 以降が必要)を使用し、より安定した 1 回限りのセマンティクス実装により、メモリ使用量を削減します。AUTO では、サポートされている場合に V2 を自動選択します。 |
sink.label-prefix | — | — | Stream Load リクエストのラベルプレフィックス。Flink コネクタ 1.2.8 以降で 1 回限りのセマンティクスを使用する場合、チェックポイント中に Flink ジョブが失敗した際にオープン状態のトランザクションをクリーンアップするために、このパラメーターを設定します。 |
sink.buffer-flush.max-bytes | 94371840(90 MB) | 64 MB~10 GB | フラッシュがトリガーされるまでの最大バッファサイズ。at-least-once のみ適用されます。 |
sink.buffer-flush.max-rows | 500000 | 64,000~5,000,000 | フラッシュがトリガーされるまでの最大バッファ行数。V1 および at-least-once のみ適用されます。 |
sink.buffer-flush.interval-ms | 300000 | 1,000~3,600,000 | フラッシュ間の最大間隔(ミリ秒単位)。at-least-once のみ適用されます。 |
sink.max-retries | 3 | 0~10 | Stream Load 失敗後の再試行回数。V1 のみ適用されます。 |
sink.connect.timeout-ms | 30000 | 100~60,000 | FE への HTTP 接続タイムアウト(ミリ秒単位)。Flink コネクタ 1.2.9 より前では、デフォルト値は 1000 でした。 |
sink.socket.timeout-ms | -1 | — | HTTP クライアントがデータを待機するタイムアウト(ミリ秒単位)。-1 はタイムアウトなしを意味します。Flink コネクタ 1.2.10 以降でサポートされています。 |
sink.wait-for-continue.timeout-ms | 10000 | 3,000~60,000 | FE HTTP 100-continue 応答を待機するタイムアウト(ミリ秒単位)。Flink コネクタ 1.2.7 以降でサポートされています。 |
sink.ignore.update-before | TRUE | TRUE、FALSE | プライマリキーを持つテーブルへの書き込み時に UPDATE_BEFORE レコードを無視するかどうか。この値を FALSE に設定すると、そのレコードは DELETE として処理されます。Flink コネクタ 1.2.8 以降でサポートされています。 |
sink.parallelism | — | — | Flink SQL 向けの書き込み並列度。未設定の場合、Flink が並列度を決定します。 |
sink.properties.* | — | — | インポート動作を制御する Stream Load パラメーター。 |
sink.properties.format | csv | csv、json | Stream Load のデータ形式。 |
sink.properties.column_separator | \t | — | CSV データの列区切り文字。 |
sink.properties.row_delimiter | \n | — | CSV データの行区切り文字。 |
sink.properties.max_filter_ratio | 0 | 0~1 | データ品質の問題によりフィルターされる行の最大割合。 |
sink.properties.partial_update | false | TRUE、FALSE | 部分更新を有効にするかどうか。 |
sink.properties.partial_update_mode | row | row、column | 部分更新モード。row は、多数の列と小規模なバッチを伴うリアルタイム更新に適しています。column は、少数の列と多数の行を伴う一括更新に適しており、このようなシナリオではパフォーマンスを大幅に向上させることができます。 |
sink.properties.strict_mode | false | true、false | Stream Load の Strict モードを有効にするかどうか。Strict モードでは、不適切な値を持つ行の処理方法が制御されます。 |
sink.properties.compression | NONE | lz4_frame | Stream Load JSON データの圧縮アルゴリズム。StarRocks 3.2.7 以降が必要です。Flink コネクタ 1.2.10 以降でサポートされています。 |
データ型マッピング
| Flink 型 | StarRocks 型 |
|---|---|
| BOOLEAN | BOOLEAN |
| TINYINT | TINYINT |
| SMALLINT | SMALLINT |
| INTEGER | INTEGER |
| BIGINT | BIGINT |
| FLOAT | FLOAT |
| DOUBLE | DOUBLE |
| DECIMAL | DECIMAL |
| BINARY | INT |
| CHAR | STRING |
| VARCHAR | STRING |
| STRING | STRING |
| DATE | DATE |
| TIMESTAMP_WITHOUT_TIME_ZONE(N) | DATETIME |
| TIMESTAMP_WITH_LOCAL_TIME_ZONE(N) | DATETIME |
| ARRAY<T> | ARRAY<T> |
| MAP<KT,VT> | JSON STRING |
| ROW<arg T...> | JSON STRING |
注意事項
フラッシュポリシー
コネクタはレコードをメモリ内にバッファリングし、Stream Load を介して StarRocks にフラッシュします。フラッシュがトリガーされるタイミングは、配信セマンティクスによって異なります。
`at-least-once` の場合、以下のいずれかの条件が満たされると、フラッシュがトリガーされます:
バッファリングされたデータサイズが
sink.buffer-flush.max-bytesに達した場合。バッファリングされた行数が
sink.buffer-flush.max-rowsに達した場合(シンクバージョンV1のみ)。最後のフラッシュからの経過時間が
sink.buffer-flush.interval-msに達した場合。
exactly-once の場合、メモリ内のデータは Flink のチェックポイントがトリガーされたときにのみフラッシュされます。この場合、sink.buffer-flush.max-bytes および sink.buffer-flush.interval-ms パラメーターは、しきい値に達してもデータが自動的にフラッシュされないため、効果がありません。
1 回限りのセマンティクス
Flink コネクタ 1.2.4 以降では、StarRocks 2.4 で導入された Stream Load トランザクションインターフェイスを用いて 1 回限りのセマンティクスが実装されています。このアプローチは、従来の非トランザクション方式と比較して、メモリ使用量が少なく、チェックポイントのオーバーヘッドも低減されます。
Flink コネクタ 1.2.8 以降で 1 回限りのセマンティクスを使用する場合は、sink.label-prefix を設定してください。コネクタはこのプレフィックスを使用して、チェックポイント中に Flink ジョブが失敗した際にオープン状態のトランザクションを特定およびクリーンアップします。
サンプル
Flink SQL を使用したデータ書き込み
StarRocks で
testというデータベースを作成し、プライマリキーを持つテーブルscore_boardを作成します。CREATE DATABASE test; CREATE TABLE test.score_board( id int(11) NOT NULL COMMENT "", name varchar(65533) NULL DEFAULT "" COMMENT "", score int(11) NOT NULL DEFAULT "0" COMMENT "" ) ENGINE=OLAP PRIMARY KEY(id) DISTRIBUTED BY HASH(id);Flink クラスターのマスターノードにログインします。詳細については、「クラスターへのログイン」をご参照ください。
Flink SQL クライアントを起動します。
/opt/apps/FLINK/flink-current/bin/sql-client.shStarRocks テーブルに対応する Flink テーブルを作成し、データを挿入します。
対象が StarRocks のプライマリキーを持つテーブルの場合、Flink テーブルの DDL でプライマリキーを明示的に定義する必要があります(上記の例を参照)。Duplicate Key テーブルなどの他のテーブルタイプでは、プライマリキーの定義は任意です。
CREATE TABLE `score_board` ( `id` INT, `name` STRING, `score` INT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'starrocks', 'jdbc-url' = 'jdbc:mysql://<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:9030', 'load-url' = '<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:8030', 'database-name' = 'test', 'table-name' = 'score_board', 'username' = 'admin', 'password' = '<password>' ); INSERT INTO `score_board` VALUES (1, 'starrocks', 100), (2, 'flink', 100);
Flink DataStream API を使用したデータ書き込み
レコードの形式に応じて、以下のいずれかのアプローチを選択してください。すべての例では、Flink SQL の例で使用したのと同じ score_board テーブルに書き込みます。
CSV 文字列レコードの書き込み
レコードが CSV 形式の文字列である場合、sink.properties.format を csv に設定し、列区切り文字を指定します。GitHub 上の完全な例をご参照ください。
/**
* CSV 形式のレコードを生成します。各レコードは "\t" で区切られた 3 つの値から構成されます。
* これらの値は、StarRocks テーブルの列 `id`、`name`、`score` に対応します。
*/
String[] records = new String[]{
"1\tstarrocks-csv\t100",
"2\tflink-csv\t100"
};
DataStream<String> source = env.fromElements(records);
StarRocksSinkOptions options = StarRocksSinkOptions.builder()
.withProperty("jdbc-url", jdbcUrl)
.withProperty("load-url", loadUrl)
.withProperty("database-name", "test")
.withProperty("table-name", "score_board")
.withProperty("username", "root")
.withProperty("password", "")
.withProperty("sink.properties.format", "csv")
.withProperty("sink.properties.column_separator", "\t")
.build();
SinkFunction<String> starRockSink = StarRocksSink.sink(options);
source.addSink(starRockSink);JSON 文字列レコードの書き込み
レコードが JSON 形式の文字列である場合、sink.properties.format を json に設定し、外側の配列を除去するために strip_outer_array を有効にします。GitHub 上の完全な例をご参照ください。
/**
* JSON 形式のレコードを生成します。
* 各レコードは、列 id、name、score に対応する 3 つのキーと値のペアから構成されます。
*/
String[] records = new String[]{
"{\"id\":1, \"name\":\"starrocks-json\", \"score\":100}",
"{\"id\":2, \"name\":\"flink-json\", \"score\":100}"
};
DataStream<String> source = env.fromElements(records);
StarRocksSinkOptions options = StarRocksSinkOptions.builder()
.withProperty("jdbc-url", jdbcUrl)
.withProperty("load-url", loadUrl)
.withProperty("database-name", "test")
.withProperty("table-name", "score_board")
.withProperty("username", "root")
.withProperty("password", "")
.withProperty("sink.properties.format", "json")
.withProperty("sink.properties.strip_outer_array", "true")
.build();
SinkFunction<String> starRockSink = StarRocksSink.sink(options);
source.addSink(starRockSink);カスタム Java オブジェクトの書き込み
レコードがカスタム Java オブジェクトである場合、StarRocks テーブルと一致するスキーマを定義し、各オブジェクトを Object[] に変換する StarRocksSinkRowBuilder を実装します。GitHub 上の完全な例をご参照ください。
POJO の定義:
public static class RowData {
public int id;
public String name;
public int score;
public RowData() {}
public RowData(int id, String name, int score) {
this.id = id;
this.name = name;
this.score = score;
}
}シンクの設定:
RowData[] records = new RowData[]{
new RowData(1, "starrocks-rowdata", 100),
new RowData(2, "flink-rowdata", 100)
};
DataStream<RowData> source = env.fromElements(records);
StarRocksSinkOptions options = StarRocksSinkOptions.builder()
.withProperty("jdbc-url", jdbcUrl)
.withProperty("load-url", loadUrl)
.withProperty("database-name", "test")
.withProperty("table-name", "score_board")
.withProperty("username", "root")
.withProperty("password", "")
.build();
// StarRocks テーブルのレイアウトと一致するようにスキーマを定義します。
TableSchema schema = TableSchema.builder()
.field("id", DataTypes.INT().notNull()) // プライマリキー列には notNull() が必要です
.field("name", DataTypes.STRING())
.field("score", DataTypes.INT())
.primaryKey("id")
.build();
RowDataTransformer transformer = new RowDataTransformer();
SinkFunction<RowData> starRockSink = StarRocksSink.sink(schema, options, transformer);
source.addSink(starRockSink);トランスフォーマーの実装:
private static class RowDataTransformer implements StarRocksSinkRowBuilder<RowData> {
/**
* RowData の各フィールドを Object[] の対応する位置にマップします。
* 配列のレイアウトは、上記で定義したスキーマと一致している必要があります。
*/
@Override
public void accept(Object[] internalRow, RowData rowData) {
internalRow[0] = rowData.id;
internalRow[1] = rowData.name;
internalRow[2] = rowData.score;
// プライマリキーを持つテーブルの場合、最後の要素を UPSERT または DELETE を示すために設定します。
internalRow[internalRow.length - 1] = StarRocksSinkOP.UPSERT.ordinal();
}
}Flink CDC 3.0 を使用したデータ同期
Flink CDC 3.0 フレームワーク を使用すると、MySQL や Kafka などの CDC ソースから StarRocks へストリーミング ELT パイプラインを構築できます。このパイプラインにより、以下の操作が可能です。
StarRocks へのデータベースおよびテーブルの自動作成
全量および増分データの同期
スキーマ変更の伝搬
Flink コネクタ v1.2.9 以降では、このコネクタが Flink CDC 3.0 に統合され、StarRocks Pipeline コネクタとして提供されます。StarRocks v3.2.1 以降と併用することで、fast_schema_evolution 機能を活用でき、カラムの追加・削除を高速化し、リソース消費を削減できます。
ベストプラクティス
プライマリキーを持つテーブルへのインポート
プライマリキーを持つテーブルでは、細かい粒度での書き込み制御を実現するために、部分更新および条件付き更新がサポートされています。
StarRocks テーブルのセットアップ
CREATE DATABASE `test`;
CREATE TABLE `test`.`score_board`
(
`id` int(11) NOT NULL COMMENT "",
`name` varchar(65533) NULL DEFAULT "" COMMENT "",
`score` int(11) NOT NULL DEFAULT "0" COMMENT ""
)
ENGINE=OLAP
PRIMARY KEY(`id`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`id`);
INSERT INTO `test`.`score_board` VALUES (1, 'starrocks', 100), (2, 'flink', 100);Flink SQL クライアントを起動します。
/opt/apps/FLINK/flink-current/bin/sql-client.sh部分更新
部分更新では、他の列に影響を与えることなく特定の列だけを更新できます。
sink.properties.partial_updateを有効にして Flink テーブルを作成します。sink.properties.partial_update:部分更新モードを有効にします。sink.properties.columns:Flink コネクタ 1.2.7 以前では、更新対象の列を指定し、末尾に__opを追加します。__opフィールドは UPSERT または DELETE を示し、コネクタによって自動的に設定されます。Flink コネクタ 1.2.8 以降では不要です。
CREATE TABLE `score_board` ( `id` INT, `name` STRING, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'starrocks', 'jdbc-url' = 'jdbc:mysql://<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:9030', 'load-url' = '<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:8030', 'database-name' = 'test', 'table-name' = 'score_board', 'username' = 'admin', 'password' = '<password>', 'sink.properties.partial_update' = 'true', -- Flink コネクタ バージョン 1.2.7 以前のみ必要 'sink.properties.columns' = 'id,name,__op' );更新データを挿入します —
name列のみが変更され、score列は変更されません。INSERT INTO score_board VALUES (1, 'starrocks-update'), (2, 'flink-update');SQL エディターで結果を確認します。
SELECT * FROM `test`.`score_board`;name列には新しい値が反映され、score列は変更されていません。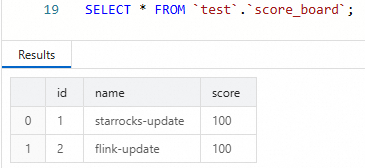
条件付き更新
条件付き更新では、受信した値が既存の行と比較して指定された条件を満たす場合にのみ、行が書き込まれます。
この例では、受信した score 値がテーブル内の現在の値以上である場合にのみ、行が更新されます。
sink.properties.merge_conditionをscoreに設定して Flink テーブルを作成します。sink.properties.merge_condition:更新条件として使用される列。ここでは、scoreは、受信したスコアが現在のスコア以上である場合にのみ行が更新されることを意味します。sink.version:条件付き更新にはV1を設定する必要があります。
CREATE TABLE `score_board` ( `id` INT, `name` STRING, `score` INT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'starrocks', 'jdbc-url' = 'jdbc:mysql://<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:9030', 'load-url' = '<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:8030', 'database-name' = 'test', 'table-name' = 'score_board', 'username' = 'admin', 'password' = '<password>', 'sink.properties.merge_condition' = 'score', 'sink.version' = 'V1' );既存のデータと同じプライマリキーを持つ 2 行を挿入します。1 行目は低い
score(99 < 100)、2 行目は高いscore(101 > 100)です。INSERT INTO `score_board` VALUES (1, 'starrocks-update', 99), (2, 'flink-update', 101);SQL エディターで結果を確認します。
SELECT * FROM `test`.`score_board`;2 行目のみが更新されます。1 行目は、受信した
score(99)が既存の値(100)より小さいため、変更されません。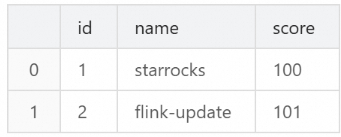
Bitmap 列へのインポート
Bitmap 列は、ユニークビジター(UV)の計算など、正確な重複排除カウントを高速化します。Flink にはネイティブの Bitmap 型がないため、Flink テーブルでは BIGINT 型の列を使用し、to_bitmap() 関数で変換します。
SQL エディターで、Bitmap 列を持つ集計テーブルを作成します。
CREATE TABLE `test`.`page_uv` ( `page_id` INT NOT NULL COMMENT 'page ID', `visit_date` datetime NOT NULL COMMENT 'access time', `visit_users` BITMAP BITMAP_UNION NOT NULL COMMENT 'user ID' ) ENGINE=OLAP AGGREGATE KEY(`page_id`, `visit_date`) DISTRIBUTED BY HASH(`page_id`);page_idおよびvisit_dateは集計キーです。visit_usersには集計関数としてBITMAP_UNIONが使用されます。対応する Flink テーブルを作成し、
sink.properties.columnsを使用してvisit_user_id(BIGINT)をto_bitmap()関数で Bitmap に変換します。CREATE TABLE `page_uv` ( `page_id` INT, `visit_date` TIMESTAMP, `visit_user_id` BIGINT ) WITH ( 'connector' = 'starrocks', 'jdbc-url' = 'jdbc:mysql://<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:9030', 'load-url' = '<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:8030', 'database-name' = 'test', 'table-name' = 'page_uv', 'username' = 'admin', 'password' = '<password>', 'sink.properties.columns' = 'page_id,visit_date,visit_user_id,visit_users=to_bitmap(visit_user_id)' );Flink SQL クライアントでデータを挿入します。
INSERT INTO `page_uv` VALUES (1, CAST('2020-06-23 01:30:30' AS TIMESTAMP), 13), (1, CAST('2020-06-23 01:30:30' AS TIMESTAMP), 23), (1, CAST('2020-06-23 01:30:30' AS TIMESTAMP), 33), (1, CAST('2020-06-23 02:30:30' AS TIMESTAMP), 13), (2, CAST('2020-06-23 01:30:30' AS TIMESTAMP), 23);SQL エディターでページごとの UV カウントを照会します。
SELECT page_id, COUNT(DISTINCT visit_users) FROM page_uv GROUP BY page_id;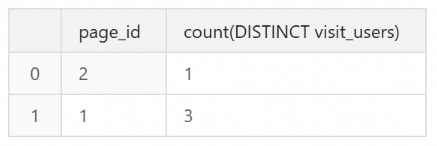
HLL 列へのインポート
HLL(HyperLogLog)列は、Bitmap よりも少ないストレージオーバーヘッドで、大規模な近似重複排除カウントをサポートします。設定方法は同様で、Flink では BIGINT 型の列を使用し、hll_hash() 関数で変換します。
SQL エディターで、HLL 列を持つ集計テーブルを作成します。
CREATE TABLE `test`.`hll_uv` ( `page_id` INT NOT NULL COMMENT 'page ID', `visit_date` DATETIME NOT NULL COMMENT 'access time', `visit_users` HLL HLL_UNION NOT NULL COMMENT 'user ID' ) ENGINE=OLAP AGGREGATE KEY(`page_id`, `visit_date`) DISTRIBUTED BY HASH(`page_id`);対応する Flink テーブルを作成し、
sink.properties.columnsを使用してvisit_user_id(BIGINT)をhll_hash()関数で HLL に変換します。CREATE TABLE `hll_uv` ( `page_id` INT, `visit_date` TIMESTAMP, `visit_user_id` BIGINT ) WITH ( 'connector' = 'starrocks', 'jdbc-url' = 'jdbc:mysql://<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:9030', 'load-url' = '<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:8030', 'database-name' = 'test', 'table-name' = 'hll_uv', 'username' = 'admin', 'password' = '<password>', 'sink.properties.columns' = 'page_id,visit_date,visit_user_id,visit_users=hll_hash(visit_user_id)' );Flink SQL クライアントでデータを挿入します。
INSERT INTO `hll_uv` VALUES (3, CAST('2023-07-24 12:00:00' AS TIMESTAMP), 78), (4, CAST('2023-07-24 13:20:10' AS TIMESTAMP), 2), (3, CAST('2023-07-24 12:30:00' AS TIMESTAMP), 674);SQL エディターでページごとの UV カウントを照会します。
SELECT `page_id`, COUNT(DISTINCT `visit_users`) FROM `hll_uv` GROUP BY `page_id`;