この Topic では、Data Lake Formation (DLF) を使用して、Paimon テーブルにデータを書き込む EMR Serverless Spark タスクを実行する方法について説明します。テストファイルをアップロードし、タスクを作成して実行し、ログまたはコンソールで結果を表示して、データが正しく書き込まれ、クエリできることを確認します。
前提条件
DLF データカタログを作成済みであること。 詳細については、「データカタログ」をご参照ください。
DLF を使用するワークスペースを作成済みであること。 詳細については、「ワークスペースの作成」をご参照ください。
手順
ステップ 1: テストファイルの準備
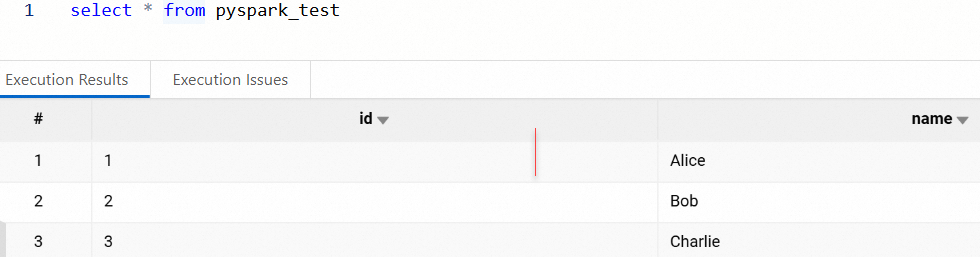
単純な DataFrame を作成し、pyspark_test という名前の Paimon テーブルに書き込みます。次に、Spark SQL を使用してテーブルデータをクエリし、データが正しく書き込まれていることを確認します。
Java
次のセクションでは、Java コードの例を示します。SparkExample-1.0-SNAPSHOT.jar をクリックして、テスト JAR パッケージをダウンロードします。
Maven 依存関係
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.5.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.5.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.5.2</version>
<scope>provided</scope>
</dependency>コード例
package org.example;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.Arrays;
import java.util.List;
public class DlfAccess {
public static void main(String[] args) {
// SparkSession インスタンスを作成します。
SparkSession spark = SparkSession.builder()
.appName("DLF Example")
.enableHiveSupport()
.getOrCreate();
// DataFrame を構築します。
List<Row> data = Arrays.asList(
RowFactory.create(1, "Alice"),
RowFactory.create(2, "Bob"),
RowFactory.create(3, "Charlie")
);
StructType schema = DataTypes.createStructType(new StructField[] {
DataTypes.createStructField("id", DataTypes.IntegerType, false),
DataTypes.createStructField("name", DataTypes.StringType, false)
});
// DataFrame を作成し、テーブルに書き込みます。
Dataset<Row> df = spark.createDataFrame(data, schema);
spark.sql("drop table if exists pyspark_test");
df.write().format("paimon").mode("overwrite").saveAsTable("pyspark_test");
// クエリを実行して、最初の 10 レコードを取得します。
Dataset<Row> tableDf = spark.sql("select * from pyspark_test limit 10");
tableDf.show();
spark.stop();
}
}Python
ワークスペースが DLF 1.0 (レガシー) にアタッチされている場合は、Spark 構成に spark.sql.extensions org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions パラメーターを追加します。
コード例
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("DLF test") \
.enableHiveSupport() \
.getOrCreate()
# テストデータ
data = [
(1, "Alice"),
(2, "Bob"),
(3, "Charlie")
]
spark.sql("drop table if exists pyspark_test")
# DataFrame を作成し、テーブルに書き込みます。
df = spark.createDataFrame(data, schema='id int, name string')
df.write.format('paimon').mode("overwrite").saveAsTable("pyspark_test")
# テーブルをクエリして検証します。
spark.sql("select * from pyspark_test").show()
ステップ 2: テストファイルのアップロード
リソースアップロードページに移動します。
EMR コンソールにログインします。
左側のナビゲーションウィンドウで、 を選択します。
[Spark] ページで、ターゲットワークスペースの名前をクリックします。
左側のナビゲーションウィンドウで、[ファイル管理] をクリックします。
[ファイル管理] ページで、[ファイルのアップロード] をクリックします。
[ファイルのアップロード] ダイアログボックスで、アップロードエリアをクリックして Python ファイルまたは JAR パッケージを選択するか、ファイルをアップロードエリアにドラッグします。
ステップ 3: バッチタスクの作成と実行
左側のナビゲーションウィンドウで、[データ開発] をクリックします。
[開発フォルダー] タブで、
 (新規) アイコンをクリックします。
(新規) アイコンをクリックします。ダイアログボックスで、[名前] を入力します。[バッチタスク] セクションで、PySpark または JAR を選択します。次に、[OK] をクリックします。
右上隅で、ターゲットキューを選択します。
キューの追加方法の詳細については、「リソースキューの管理」をご参照ください。
新しい開発タブで、次のパラメーターを構成し、他のパラメーターはデフォルト設定のままにして、[実行] をクリックします。
JAR
パラメーター
説明
メイン JAR リソース
アップロードした JAR パッケージを選択します。
メインクラス
Spark タスクを送信するときに指定するメインクラス。この例では、
org.example.DlfAccessと入力します。PySpark
パラメーター
説明
メイン Python リソース
[ワークスペースリソース] を選択し、[リソースアップロード] ページでアップロードした Python ファイルを選択します。
ステップ 4: 結果の表示
タスクが完了したら、次のいずれかの方法で結果を表示できます。
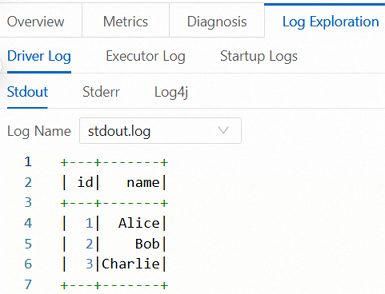
方法 1: ログクエリで結果を直接表示する
タスクの実行後、[実行履歴] セクションで、タスクのアクション列にある [ログクエリ] をクリックします。
[ログクエリ] タブで、ログ情報を表示できます。
方法 2: Data Lake Formation コンソールで結果を表示する
DLF コンソールにログインします。
対応するカタログとデータベースに移動して、テストテーブルを表示します。
方法 3: SQL 開発を使用して結果を表示する
[データ開発] で、SQL 開発タスクを作成し、クエリを実行してデータが正しく書き込まれたことを確認します。詳細については、「SparkSQL 開発」をご参照ください。