EMR Serverless Spark の組み込み SQL エディターでは、Spark SQL ジョブをインタラクティブに記述して実行できます。ジョブの実行後、Spark UI にアクセスして、実行ステータス、リソース使用量、ログを確認できます。
前提条件
開始する前に、以下をご用意ください。
-
ワークスペース。「ワークスペースの作成」をご参照ください。
-
SQL セッションインスタンス。「SQL セッションの管理」をご参照ください。
Spark SQL ジョブの作成
DLF カタログパラメータは SparkSession の初期化中に読み込まれます。spark.sql.catalog.dlf.warehouse などのカタログ関連パラメータを PySpark コード内で spark.conf.set() を使用して動的に設定しても、有効になりません。これらのパラメータを正しく設定するには、ジョブを送信する際に起動パラメータとして指定します。例えば、EMR Serverless Spark コンソールの [Configuration] セクションで、または CLI で --conf パラメータを使用して spark.sql.catalog.dlf.warehouse=oss://your-bucket/warehouse-path を追加します。
-
開発ページに移動します。
-
EMR コンソール にログインします。
-
左側のナビゲーションペインで、[EMR Serverless] \> [Spark] を選択します。
-
[Spark] ページで、対象のワークスペースの名前をクリックします。
-
[EMR Serverless Spark] ページで、左側のナビゲーションペインで [開発] をクリックします。
-
-
ジョブを作成します。
-
[開発] タブで、
 アイコンをクリックします。
アイコンをクリックします。 -
ダイアログボックスで、[名前] を入力し、タイプを [SparkSQL] に設定して、[OK] をクリックします。
-
右上隅で、データカタログ、データベース、および実行中の SQL セッションインスタンスを選択します。 新しい SQL セッションインスタンスを作成するには、ドロップダウンリストから [SQL セッションに接続] を選択します。 詳細については、「SQL セッションの管理」をご参照ください。

-
エディターに SQL 文を入力します。
例 1:基本的な SQL 操作
データベースの作成、そのデータベースへの切り替え、テーブルの作成、行の挿入、データのクエリを実行します。
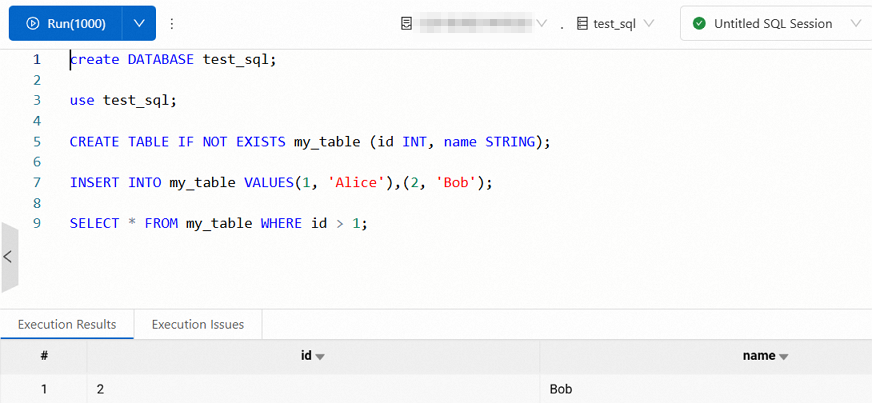
create DATABASE test_sql; use test_sql; CREATE TABLE IF NOT EXISTS my_table (id INT, name STRING); INSERT INTO my_table VALUES(1, 'Alice'),(2, 'Bob'); SELECT * FROM my_table WHERE id > 1;結果は次の図のとおりです。
例 2:CSV ベースの外部テーブル
Object Storage Service (OSS) 内の CSV ファイルに基づく外部テーブルを作成し、分析クエリを実行します。
oss://<bucketname>/user/を実際のバケットパスに置き換えます。-
外部テーブルを作成します。このテーブルに
ordersという名前を付け、以下のフィールドを定義します。-
order_id: 注文 ID。 -
order_date:注文タイムスタンプです。例:'2025-07-01 10:00:00'。 -
order_category: 商品カテゴリ。たとえば、'電子機器'や'アパレル'などです。 -
order_revenue: 注文金額。
CREATE TABLE orders ( order_id STRING, -- 注文 ID order_date STRING, -- 注文タイムスタンプ order_category STRING, -- 製品カテゴリ order_revenue DOUBLE -- 注文額 ) USING CSV OPTIONS ( path 'oss://<bucketname>/user/', header 'true' ); -
-
テストデータを挿入します。
INSERT OVERWRITE TABLE orders VALUES ('o1', '2025-07-01 10:00:00', 'Electronics', 5999.0), ('o2', '2025-07-02 11:30:00', 'Apparel', 299.0), ('o3', '2025-07-03 14:45:00', 'Electronics', 899.0), ('o4', '2025-07-04 09:15:00', 'Home Goods', 99.0), ('o5', '2025-07-05 16:20:00', 'Electronics', 1999.0), ('o6', '2025-07-06 08:00:00', 'Apparel', 199.0), ('o7', '2025-07-07 12:10:00', 'Electronics', 799.0), ('o8', '2025-07-08 18:30:00', 'Home Goods', 59.0), ('o9', '2025-07-09 20:00:00', 'Electronics', 399.0), ('o10', '2025-07-10 07:45:00', 'Apparel', 599.0), ('o11', '2025-07-11 09:00:00', 'Electronics', 1299.0), ('o12', '2025-07-12 13:20:00', 'Home Goods', 159.0), ('o13', '2025-07-13 17:15:00', 'Apparel', 499.0), ('o14', '2025-07-14 21:30:00', 'Electronics', 999.0), ('o15', '2025-07-15 06:10:00', 'Home Goods', 299.0); -
分析クエリを実行します。次のクエリは、総収益が 1,000 を超えるカテゴリを対象に、15日間のカテゴリ別売上実績 (注文数、流通取引総額 (GMV)、平均注文額、最新の注文日時) を、GMV の降順で返します。
SELECT order_category, COUNT(order_id) AS order_count, SUM(order_revenue) AS gmv, AVG(order_revenue) AS avg_order_amount, MAX(order_date) AS latest_order_date FROM orders WHERE CAST(order_date AS TIMESTAMP) BETWEEN '2025-07-01' AND '2025-07-15' GROUP BY order_category HAVING SUM(order_revenue) > 1000 ORDER BY gmv DESC, order_category ASC;
例 3:Hive Parquet テーブルの作成 (DLF フォーマットテーブル)
デフォルトでは、EMR Serverless Spark はテーブルフォーマットとして Apache Paimon を使用します。代わりに Hive Parquet テーブルを作成するには、ジョブの起動パラメーターでデフォルト設定を上書きする必要があります。
起動パラメーター
Hive Parquet テーブルを作成する前に、次の Spark 設定パラメーターを追加して、Paimon カタログがテーブル作成をインターセプトしないようにします:
spark.sql.catalog.spark_catalog=org.apache.spark.sql.hive.HiveCatalog spark.sql.defaultFileFormat=parquetこれらのパラメーターは、EMR Serverless Spark コンソールの [設定] セクションで、または CLI で
--confパラメーターを使用して追加できます。SQL メソッド
Hive Parquet テーブルを作成するには、
CREATE TABLE ... USING PARQUET構文を使用してください。STORED AS PARQUETは使用しないでください。CREATE TABLE my_parquet_table ( id INT, name STRING, created_at TIMESTAMP ) USING PARQUET;DataFrame API メソッド
df.write.format("parquet").saveAsTable(...)を使用して、データを Hive Parquet テーブルとして書き込みます。df.write.format("parquet").saveAsTable("my_parquet_table")説明ワークスペースが DLF Catalog に関連付けられている場合は、Spark セッションまたは SQL 文を使用してテーブルを作成し、メタデータカタログとの一貫性を確保することを推奨します。
-
-
(任意) 右側の[バージョン情報]タブをクリックして、バージョンを比較します。エディターに、バージョン間の SQL コードの差分がハイライト表示されます。
-
-
ジョブを実行して公開します。
-
[実行] をクリックします。 結果は [実行結果] タブに表示されます。 エラーが発生した場合は、[実行に関する問題] タブを確認します。 右側の実行履歴パネルには、過去 3 日間の記録が表示されます。
-
ジョブが正しく実行されることを確認したら、右上隅にある[公開]をクリックします。
-
[公開] ダイアログボックスで、リリースノートを入力し、[OK] をクリックします。
-
Spark UI へのアクセス
Spark UI では、タスクの実行ステータス、リソース使用量、ログ情報を確認でき、Spark ジョブの分析や最適化に役立ちます。
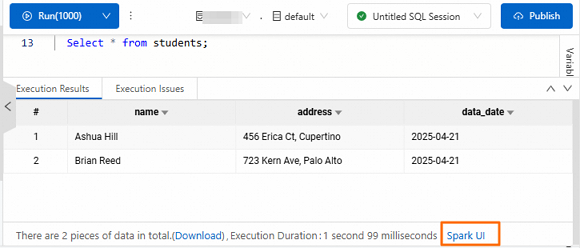
実行結果からのアクセス
この方法では、esr-4.2.0 (esr-4.x)、esr-3.2.0 (esr-3.x)、または esr-2.6.0 (esr-2.x) 以降のエンジンバージョンが必要です。
SQL ステートメントが実行された後、[実行結果] タブの下部にある[Spark UI] をクリックします。
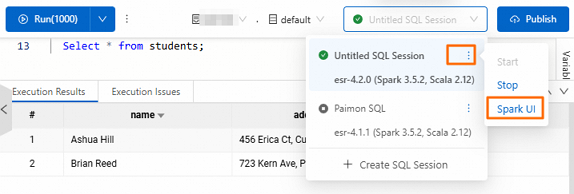
セッションインスタンスからのアクセス
SQL ステートメントの実行後、セッションインスタンスを見つけ、![]() \> [Spark UI] を選択します。
\> [Spark UI] を選択します。
キーボードショートカット
| 機能 | Windows | Mac | 説明 |
|---|---|---|---|
| 現在のスクリプトを実行 | Ctrl + Enter |
Command + Enter |
すべての SQL 文、または選択した範囲のみを実行します。[Run] のクリックと同じです。 |
| SQL のフォーマット | Ctrl + P |
Command + P |
SQL の構造をフォーマットします:インデント、改行、キーワードの大文字/小文字を標準化します。 |
| テキストの検索 | Ctrl + F |
Command + F |
現在のスクリプトでキーワードを検索します。 |
| タスクの保存 | Ctrl + S |
Command + S |
未公開のジョブを保存して、データの損失を防ぎます。 |
次のステップ
ワークフローを作成し、ジョブの定期実行をスケジュールします。「ワークフローの作成」をご参照ください。スケジューリングの具体的な例については、「Spark SQL 開発のクイックスタート」をご参照ください。
よくある質問
クエリ結果の 10,000 行のダウンロード制限を超えることはできますか?
いいえ。EMR Serverless Spark のデータ開発におけるクエリ結果のダウンロードには、プラットフォームのハードリミットが適用されます。 最大 10,000 行までダウンロードでき、合計ファイルサイズは 10 MB を超えることはできません。この制限は設定で変更することはできません。
より大きなデータセットをエクスポートするには、次のいずれかの方法を使用してください:
-
spark-submitを使用してジョブを送信し、結果を Object Storage Service (OSS) または Hadoop 分散ファイルシステム (HDFS) に書き込みます。 -
DataWorks のオフライン同期タスクを使用してデータをエクスポートします。
EMR Serverless Spark は Spark History 用のパブリック API を提供していますか?
はい。 EMR Serverless Spark はパブリック API を提供しています。 利用可能な API 操作の一覧については、「API 概要」をご参照ください。