スケーリンググループがプリエンプティブルインスタンスを自動的にスケジュールできるようにすることで、ファインチューニングコストを削減できます。プリエンプティブルインスタンスが中断またはリクレイムされた場合、スケーリンググループで新しいインスタンスが起動され、最新のチェックポイントからトレーニングが再開されるため、継続的な進捗が保証されます。
ソリューションの概要
このソリューションは、スケーリンググループに基づいて、大規模モデルの低コストのファインチューニングを実現します。プリエンプティブルインスタンスを優先し、永続的なチェックポイントストレージに Object Storage Service (OSS) を活用します。また、以下の主要な機能により、トレーニングの継続性を維持します。
プリエンプティブルインスタンス優先:スケーリンググループのトレーニングタスクでは、プリエンプティブルインスタンスが優先されます。チェックポイントは回復力のために OSS バケットに自動的に保存されます。
フェールオーバーの継続性による自動スケーリング:プリエンプティブルインスタンスが中断またはリクレイムされた場合、Auto Scaling はまず、他のゾーンで代替プリエンプティブルインスタンスのプロビジョニングを試みます。プリエンプティブルインスタンスタイプが利用できない場合は、自動的に従量課金インスタンスにフォールバックします。どちらの場合も、トレーニングは最新のチェックポイントからシームレスに再開されます。
プリエンプティブルインスタンスへの自動フォールバック:プリエンプティブルインスタンスタイプが再び利用可能になると、Auto Scaling は自動的に従量課金からプリエンプティブルインスタンスに切り替わり、トレーニングは最新のチェックポイントから再開されます。
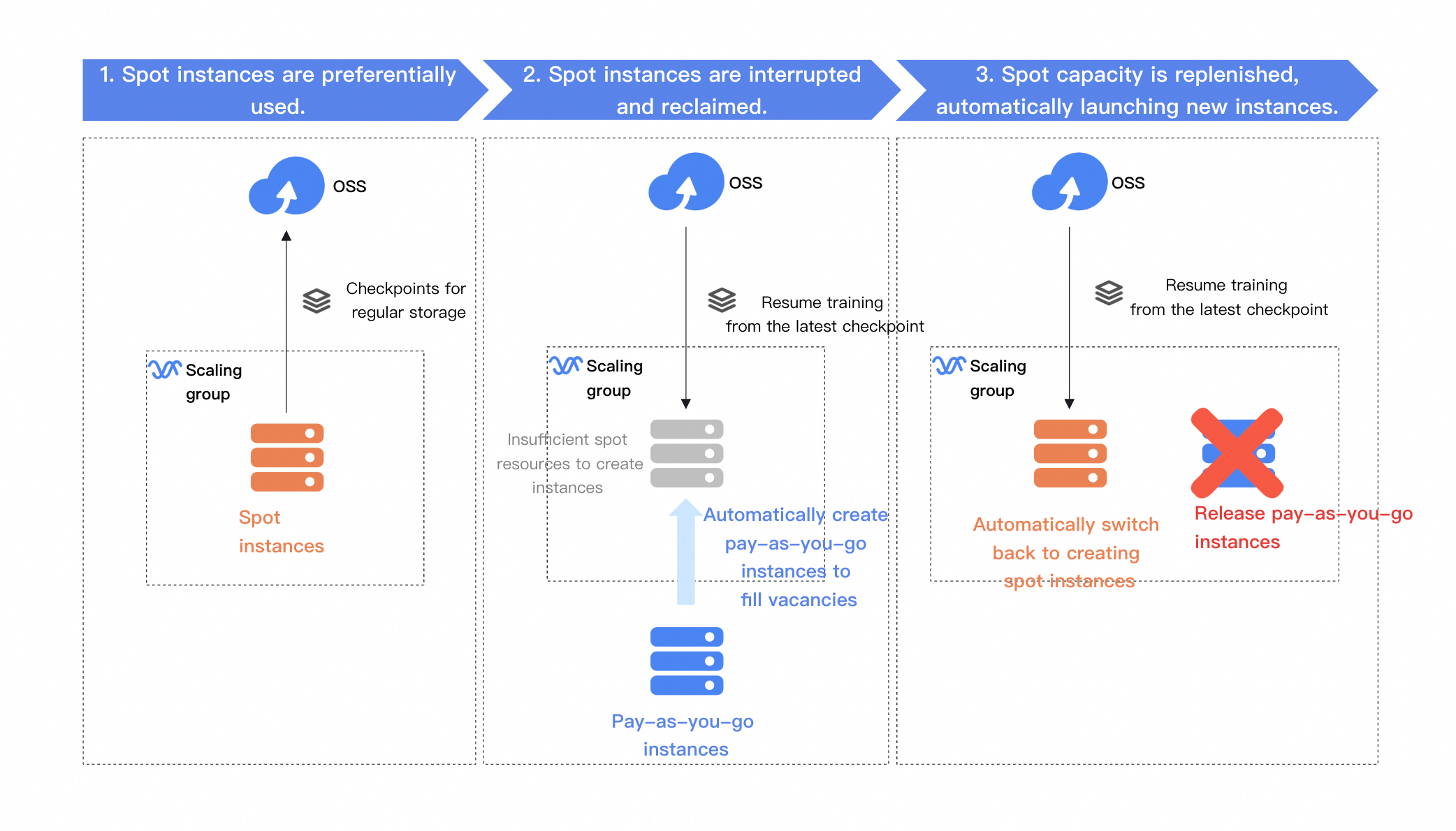
コストを最大限に節約するには、トレーニングプロセス全体でプリエンプティブルインスタンスを使用するようにスケーリンググループを構成しますが、これによりトレーニングの完了時間が遅れる可能性があります。プリエンプティブルインスタンスタイプが利用できなくなった場合は、トレーニングを一時停止し、プリエンプティブルインスタンスのインベントリが復元されたら後で再開します。スケーリンググループとプリエンプティブルインスタンスを組み合わせてコストを最適化する方法の詳細については、「プリエンプティブルインスタンスを使用してコストを削減する」をご参照ください。
コスト比較
以下の表のコスト比較は参考値です。実際の節約額は実際の使用状況によって異なります。
12 時間のトレーニング期間を想定し、プリエンプティブルインスタンスの単価は 1 時間あたり 3.5 人民元、従量課金インスタンスのコストは 1 時間あたり 10 人民元です。次の表は、2 つのオプションのコスト比較を示しています。
モード | すべてプリエンプティブル | ハイブリッド(プリエンプティブル + 従量課金) | すべて従量課金 |
説明 | プリエンプティブルインスタンスが中断およびリクレイムされると、トレーニングは一時停止されます。プリエンプティブルインスタンスタイプのインベントリが復元されると、新しいプリエンプティブルインスタンスが自動的に作成され、トレーニングが再開されます。 | プリエンプティブルインスタンスは、中断およびリクレイムされるまで 1 時間実行されます。中断後、プリエンプティブルキャパシティを待機している間、従量課金インスタンスが 0.5 時間使用されます。プリエンプティブルインスタンスタイプのインベントリが利用可能になると、トレーニングは新しいプリエンプティブルインスタンスに切り替わります。 | トレーニングは従量課金インスタンスのみで行われます。 |
コスト | 12 時間 × 3.5 人民元/時間 = 42 | 8 時間 × 3.5 人民元/時間 + 4 時間 × 10 人民元/時間 = 68 | 12 時間 × 10 人民元/時間 = 120 |
従量課金インスタンスのみを使用した場合と比較したコスト削減 | 65% | 43.33% | 0% |
手順
必須のトレーニング環境を含むベースイメージを作成します。
このイメージは、スケーリンググループのインスタンスの起動テンプレートとして機能します。組み込みの自動起動スクリプトにより、新しいインスタンスはトレーニングを迅速に再開し、自動的に実行できます。
スケーリンググループを作成および構成します。
スケーリンググループは、既存のインスタンスが中断またはリクレイムされたときに、新しいプリエンプティブルインスタンスまたは従量課金インスタンスを自動的に起動することで、トレーニングタスクの継続を保証します。
トレーニングを開始します。
スケーリンググループが構成されると、スケールアウトイベントが自動的にトリガーされます。これにより、新しいインスタンスが作成され、事前定義された自動化ルールに基づいてトレーニングタスクがすぐに開始されます。
テスト:中断とリクレイムをシミュレートする
インスタンスの中断とリクレイムを手動でトリガーして、システムが新しいインスタンスを自動的に起動し、中断されたトレーニングタスクを正しく再開することを確認します。この検証は、リソースリクレイムシナリオ中の安定性と信頼性を確保するために不可欠です。
1. 必須のトレーニング環境を含むベースイメージを作成する
このトピックでは、単一マシン、単一 GPU のセットアップで Swift トレーニングフレームワークを使用して、DeepSeek-R1-Distill-Qwen-7B モデルの自己認知ファインチューニングを行う手順を示します。
タスクインスタンスの起動効率を向上させるには、まず必要なトレーニング環境と依存関係を持つインスタンスを作成し、それからカスタムイメージを生成してスケーリンググループの起動テンプレートとして使用します。このイメージには、プリインストール済みの自動トレーニングスクリプトと起動サービスを含めて、プロセス全体が手動介入なしで実行されるようにする必要があります。イメージの作成に使用される Elastic Compute Service (ECS) インスタンスのアーキテクチャを次の図に示します。
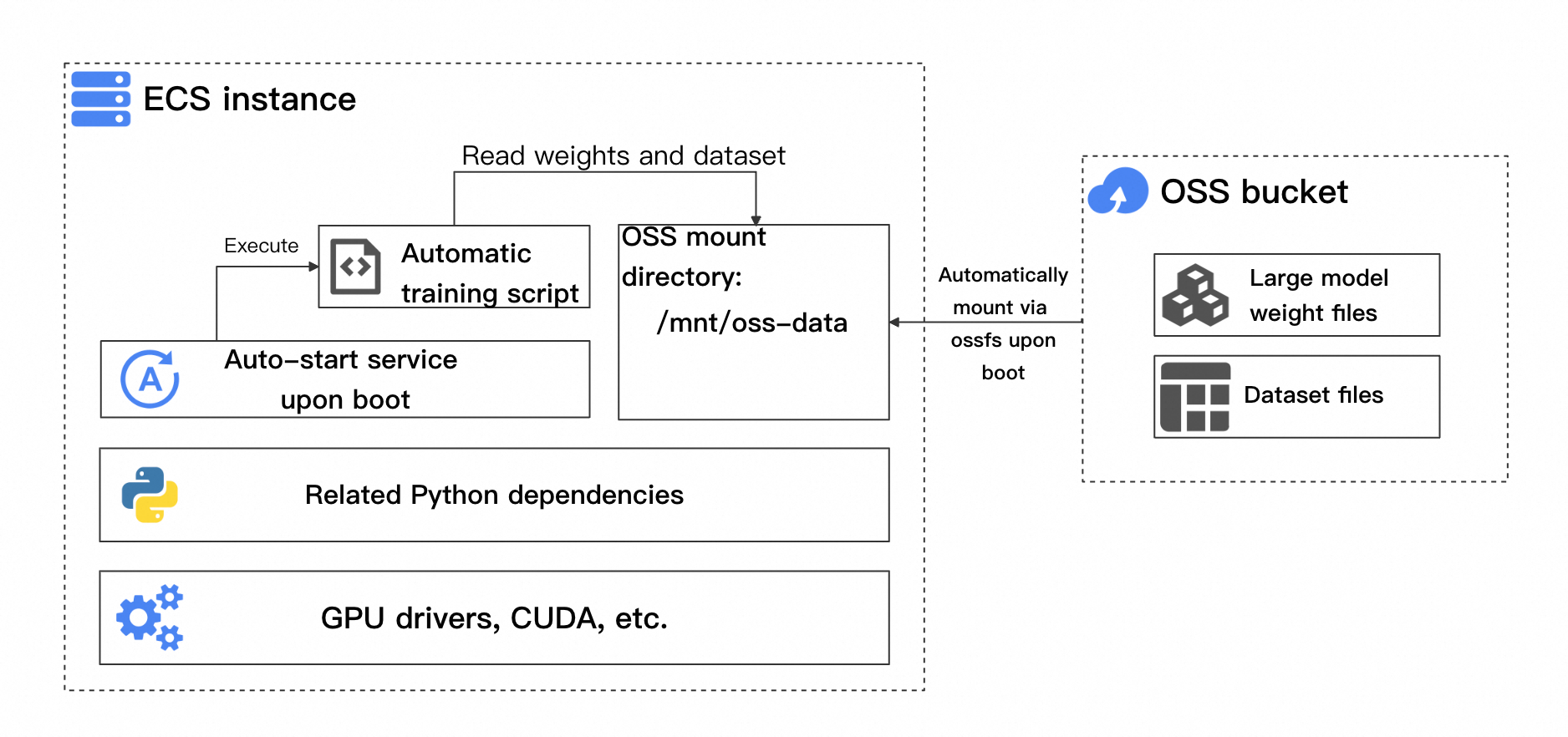
重要なポイントは次のとおりです。
基本的なトレーニング環境の依存関係:必要な依存関係には、GPU ドライバー、CUDA、および Python パッケージが含まれます。具体的な依存関係は、選択したトレーニングフレームワークによって異なります。
自動トレーニングスクリプト:このスクリプトは、最新のチェックポイントからトレーニングを再開するかどうか、およびトレーニングがすでに完了しているかどうかを自動的に検出する必要があります。
起動時にバケットを自動的にマウントする:トレーニングスクリプトが開始されると、モデルの重みファイル、データセット、およびトレーニングで生成されたチェックポイントが OSS バケットから直接読み取られます。
インスタンスの起動時にトレーニングを自動的に開始する:インスタンスの起動後、トレーニングスクリプトが自動的に実行され、OSS バケットからファイルを読み取ってトレーニングが開始または再開されます。
重要な点を理解したら、次の手順に従ってイメージを作成します。
1.1 インスタンスを作成し、基本環境を構築する
このインスタンスは、イメージを作成するためのテンプレートとして機能します。後で、Auto Scaling はこのイメージからスケーリンググループに新しいインスタンスを自動的に起動します。
ECS コンソール に移動して、GPU インスタンスを作成します。
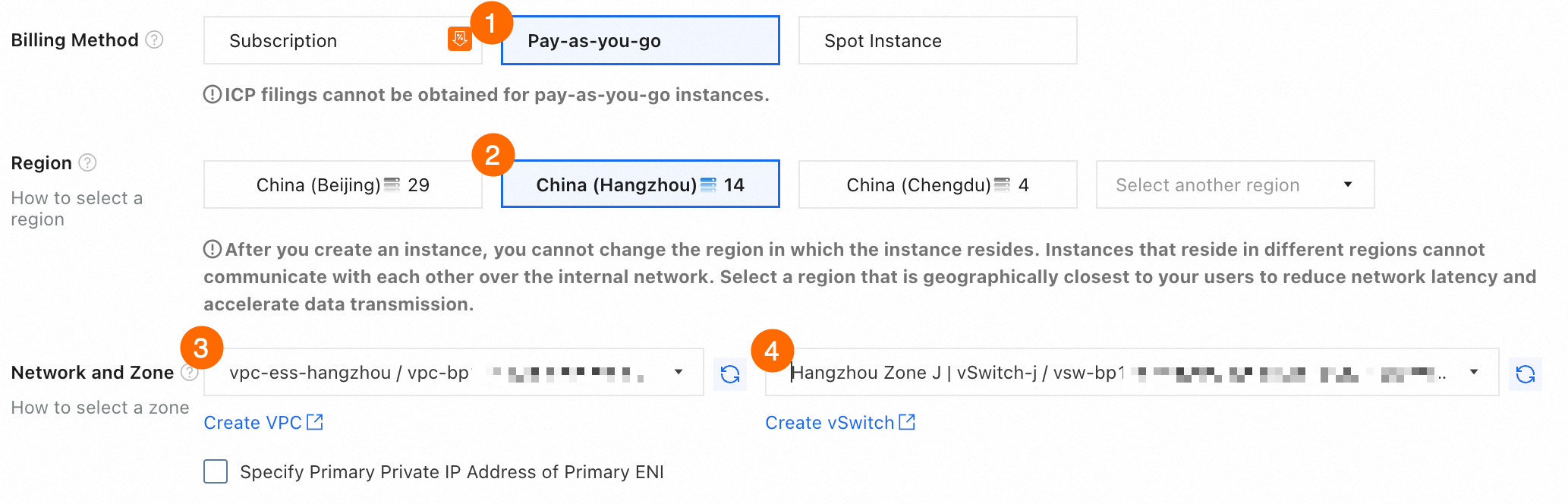
まず、従量課金 GPU インスタンスを作成して、基本環境をセットアップする必要があります。この例では、中国 (杭州) リージョンのゾーン J にデプロイされた
ecs.gn7i-c8g1.2xlargeインスタンスタイプを使用します。構成手順を次の図に示します。① 課金方法:値を [従量課金] に設定します。
② リージョン:[中国 (杭州)] を選択します。
③④ ネットワークとゾーン:VPC と vSwitch を選択します。VPC または vSwitch が存在しない場合は、画面の指示に従って作成します。
⑤⑥ インスタンス > すべてのインスタンスタイプ:
ecs.gn7i-c8g1.2xlargeを選択します。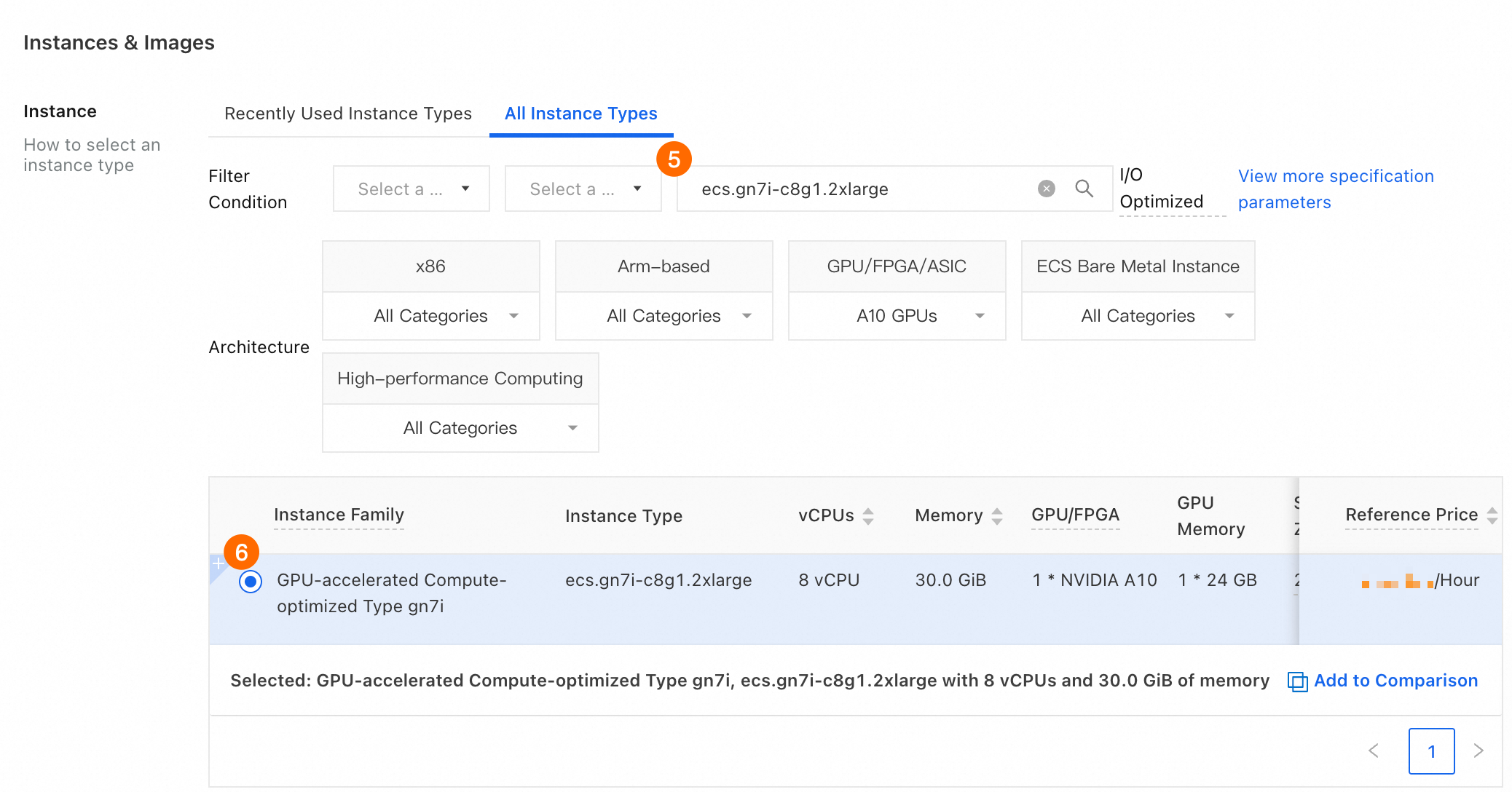
⑦⑧⑨ イメージ > パブリックイメージ:[Ubuntu 22.04 64 ビット] を選択します。
⑩ GPU ドライバーの自動インストール:[CUDA バージョン 12.4.1]、[ドライバーバージョン 550.127.08]、[cuDNN バージョン 9.2.0.82] を指定します。
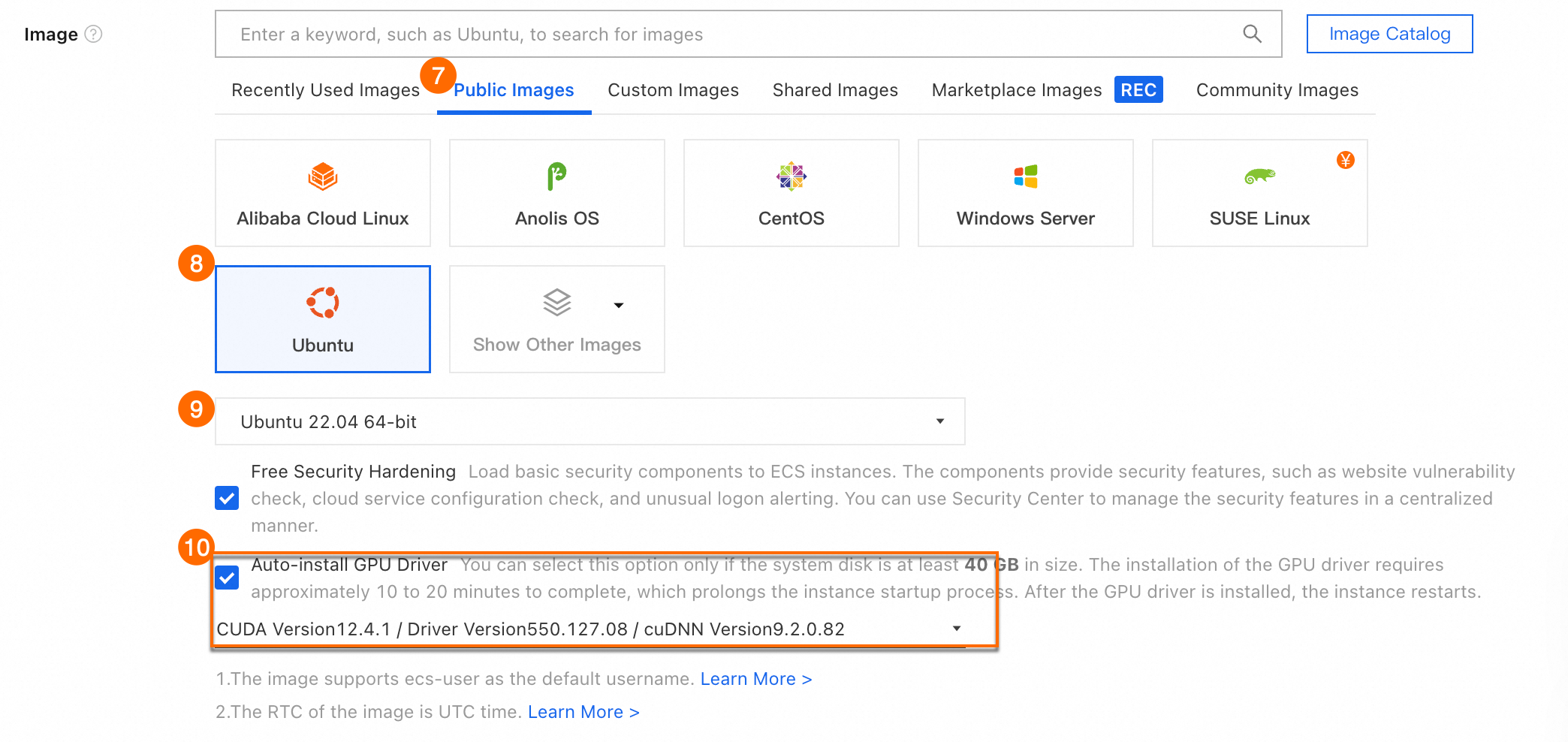
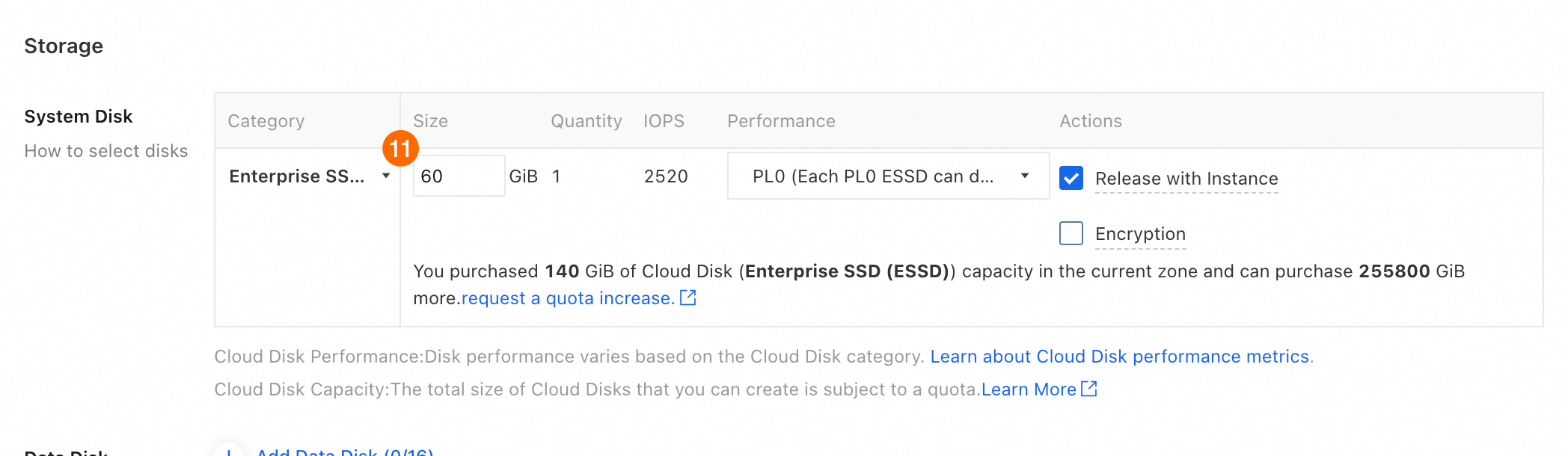
⑪ [システムディスク] > [サイズ]:[60 GiB] と入力します。
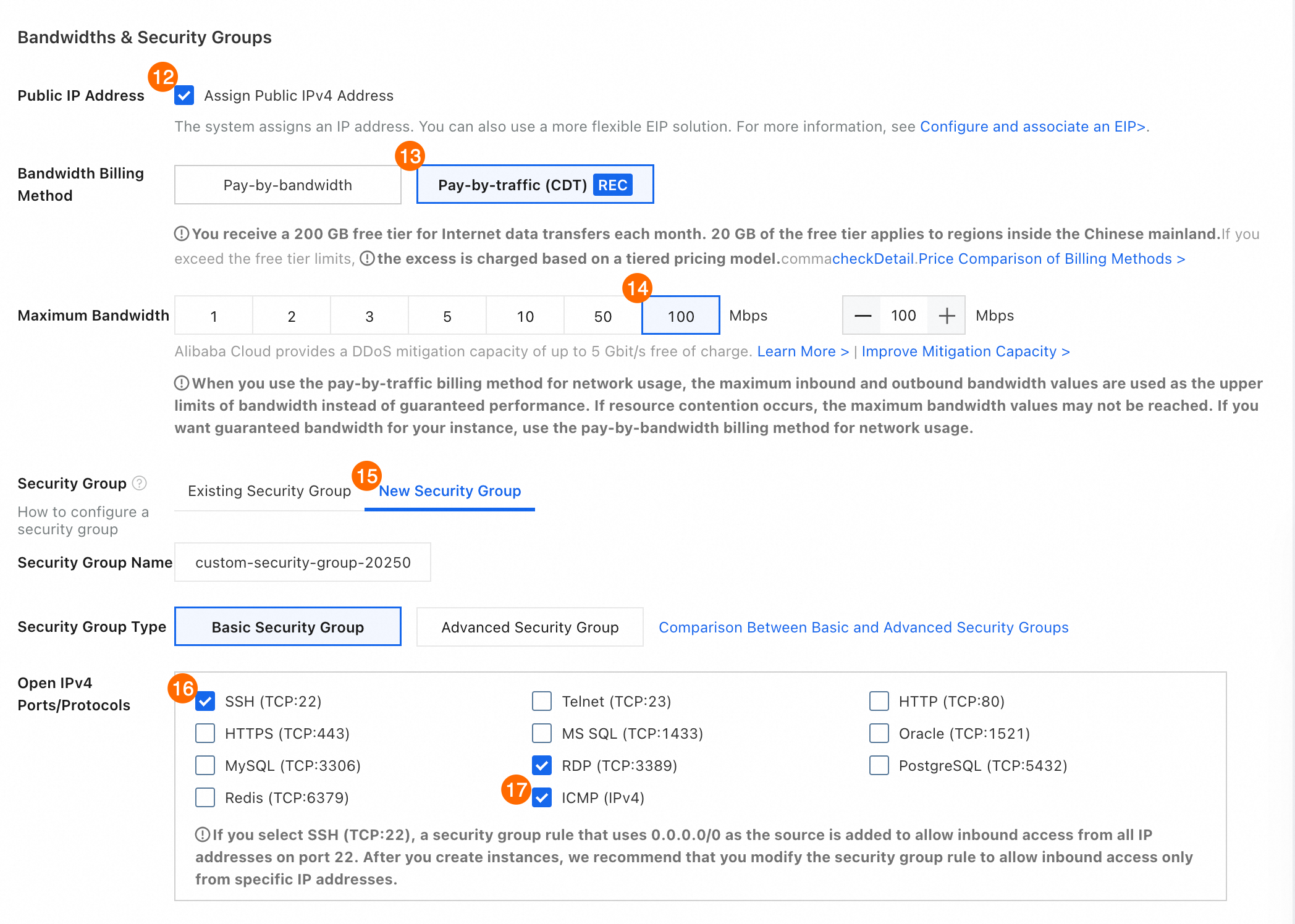
⑫ パブリック IP アドレス:[パブリック IPv4 アドレスを割り当てる] を選択して、インターネットアクセスとファイルダウンロードを有効にします。
⑬ 帯域幅課金方法: [従量課金制] を選択します。
⑭ 最大帯域幅: 100 Mbps を選択します。
⑮ セキュリティグループ:新しいセキュリティグループ. タブをクリックします。
⑯ セキュリティグループの種類: 値を [基本セキュリティグループ] に設定します。
⑰ IPv4 ポート/プロトコルの開放:SSH (TCP: 22)ICMP (IPv4) と を選択して、後続のリモート接続を容易にします。
⑱⑲⑳ ログ資格情報: [キーペア] を選択します。このキーペアは、ECS インスタンスにログオンするために必要です。 [カスタムパスワード] に値を設定することもできます。プロンプトに従って設定を完了します。
㉑ インスタンス名:ECS インスタンスの名前を入力します。検索を容易にするために、明確で覚えやすいインスタンス名を使用してください。この例では、
ess-lora-deepseek7b-templateが使用されています。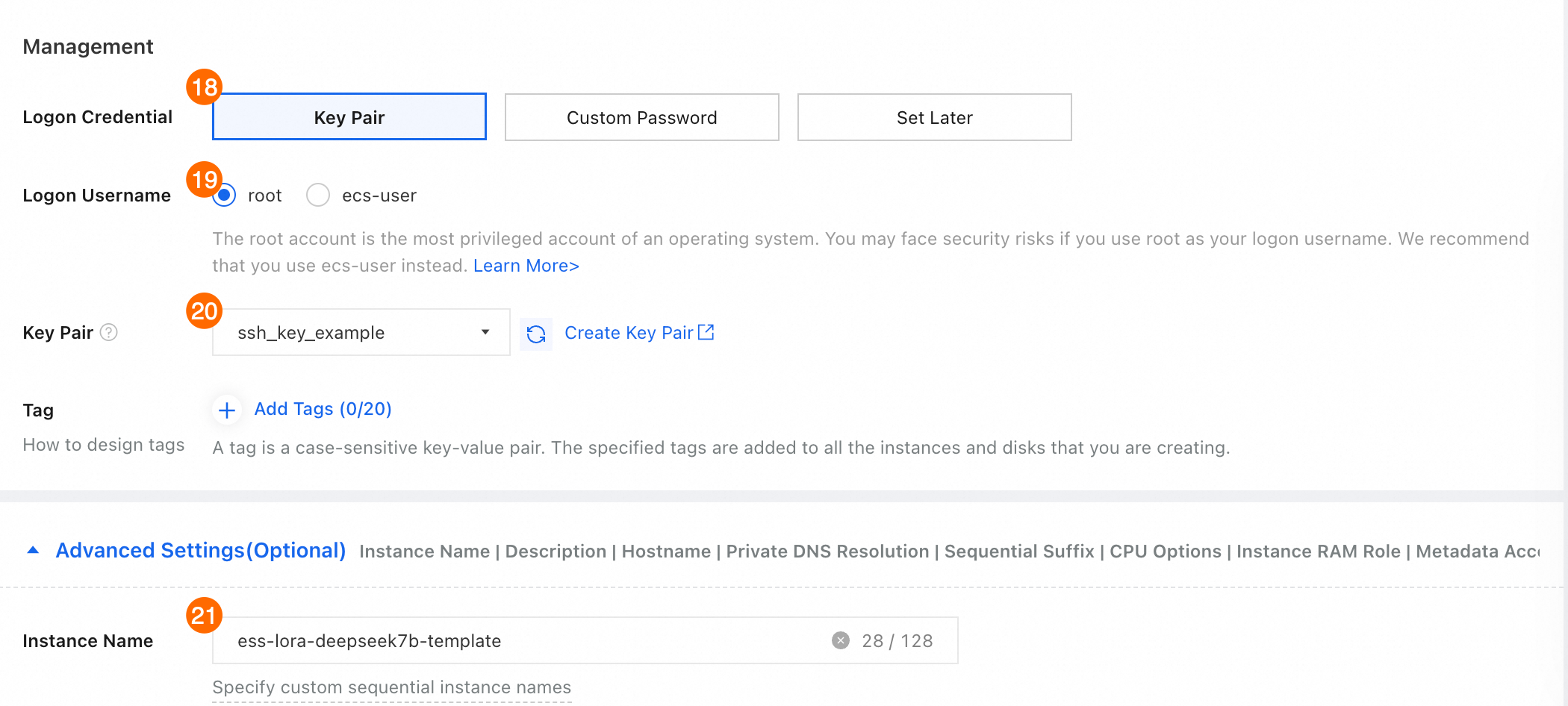
[注文の確認] をクリックします。ECS インスタンスが作成されるまで待ちます。
ECS インスタンスの準備ができたら、接続して GPU ドライバーのインストールが完了するまで待ちます。
ECS コンソール - インスタンス に移動します。
前の手順で作成した ECS インスタンスを見つけて、[アクション] 列の [接続] をクリックします。Workbench を使用して接続を確立し、プロンプトに従って ECS インスタンスにログインします。
ECS インスタンスが見つからない場合は、現在のリージョンがインスタンスのリージョンと一致しているかどうかを確認してください。左上隅のドロップダウンリストを使用してリージョンを切り替えることができます。
ECS インスタンスが停止している場合は、ページを更新して起動するまで待ちます。
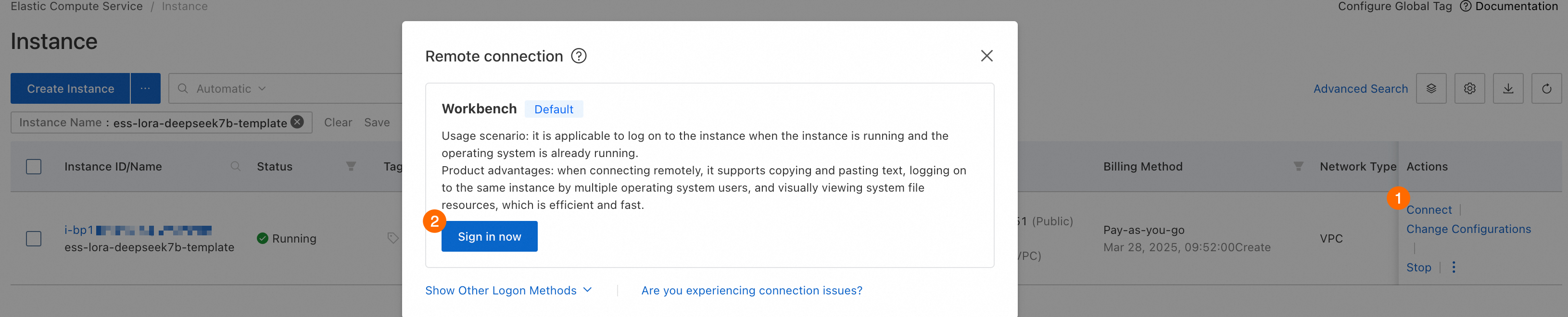
ECS インスタンスに接続したら、GPU ドライバーのインストールが完了するまで待ちます。インストール後、ECS インスタンスに再接続するように求められます。
インターフェースが応答しなくなった場合は、ページを更新して ECS インスタンスに再接続してみてください。
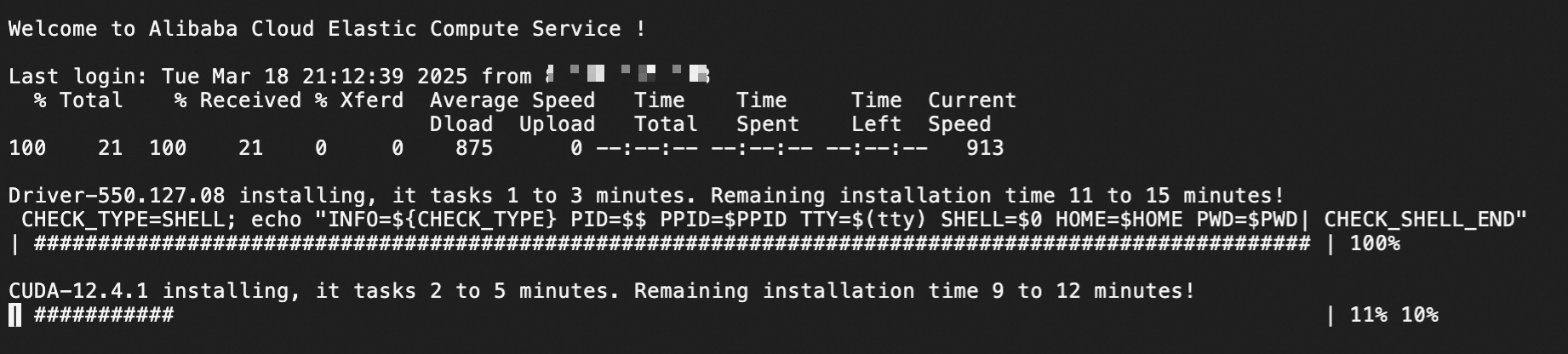
ECS インスタンスに接続した後にこのページが表示されないのは、ドライバーがすでにインストールされている可能性があります。ドライバーがインストールされているかどうかを確認するには、次のコマンドを実行します。
nvidia-smi次のページが表示された場合は、ドライバーがインストールされています。
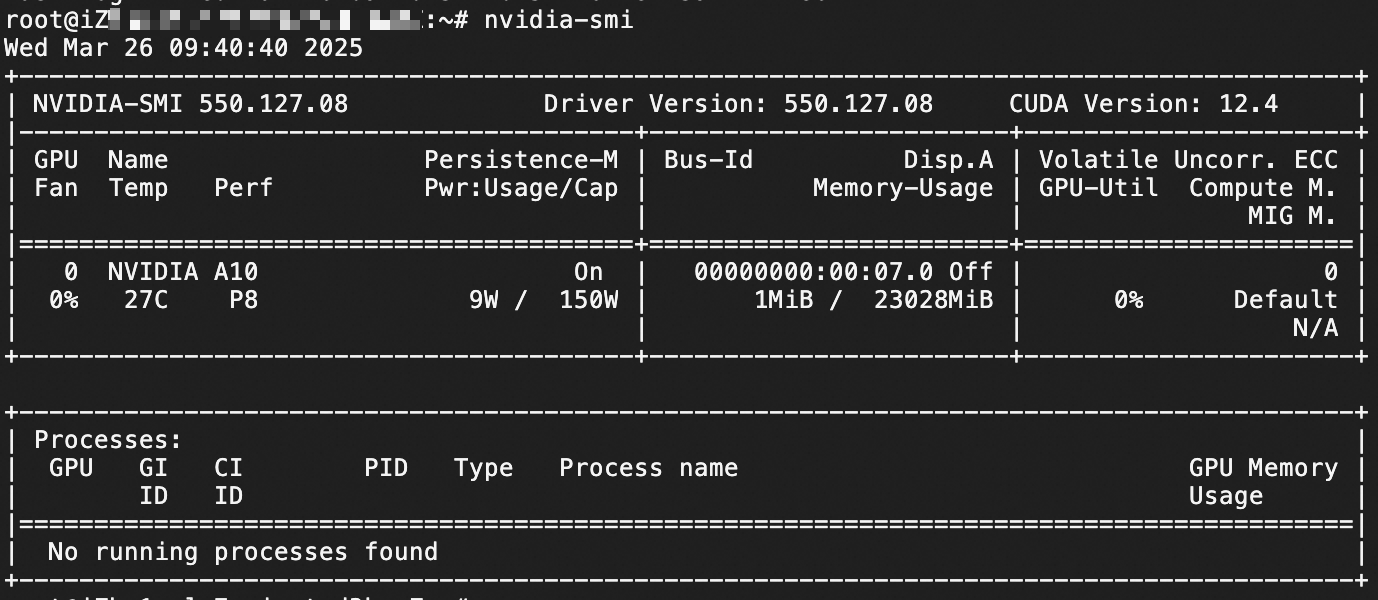
このページが表示されない場合は、起動ドライバーがインストールされていないか、問題が発生しています。新しいインスタンスを作成し、セットアップ中に [GPU ドライバーの自動インストール] を選択することをお勧めします。
ドライバーを手動でインストールする場合は、「GPU アクセラレーションコンピューティング最適化 Linux インスタンスに Tesla ドライバーを手動でインストールする」をご参照ください。
Python の依存関係をインストールします。
トレーニングに必要な Python の依存関係をインストールするには、次のコマンドを実行します。
この例では、Python 3.10 を含む [Ubuntu 22.04 64 ビット] イメージを使用します。そのため、Python の依存関係を個別にインストールする必要はありません。
# Ubuntu 22.04 64 ビットイメージにはデフォルトで Python 3.10 が含まれているため、追加のインストールは必要ありません。 python3 -m pip install --upgrade pip # Alibaba Cloud の内部イメージリポジトリに切り替えます。 pip config set global.index-url http://mirrors.cloud.aliyuncs.com/pypi/simple/ pip install modelscope==1.22.3 pip install openai==1.61.0 pip install tqdm==4.67.1 pip install "vllm>=0.5.1" -U pip install "lmdeploy>=0.5,<0.6.5" -U --no-deps pip install autoawq -U --no-deps pip install auto_gptq optimum bitsandbytes -U pip install ms-swift[all] pip install timm -U pip install deepspeed==0.14.* -U pip install qwen_vl_utils decord librosa pyav icecream -U
依存関係がインストールされるのを待っている間に、アイコンをクリックして マルチターミナル 機能を有効にし、手順 1.2 の手順に進むことができます。
1.2 OSS バケットを作成してアタッチする
モデルの重みファイル、データセット、およびトレーニング中に生成されたチェックポイントを保存するには、まず OSS バケットを作成する必要があります。バケットを作成したら、追加のデータディスクとして ECS インスタンスにアタッチします。
OSS コンソール に移動して、バケットを作成します。
次の図は、この例の主要なパラメーター設定を示しています。リストされていないパラメーターについては、デフォルト値を保持します。
② バケット名:バケットの名前を入力します。バケット名は、バケットをマウントするときに必要です。
③ リージョン:リージョンを選択します。選択したリージョンは、ECS インスタンスのリージョンと一致している必要があります。この例では、リージョンは [中国 (杭州)] である必要があります。
ECS インスタンスを使用して、同じリージョン内の OSS バケットに内部ネットワーク経由でアクセスできます。このネットワークのトラフィックには料金はかかりません。詳細については、「OSS の内部エンドポイントを使用して ECS インスタンスから OSS リソースにアクセスする」をご参照ください。

RAM ロールを作成してバインドします。
Resource Access Management (RAM) ロールは、ECS インスタンスに OSS バケットへのアクセス許可を付与するために使用されます。RAM ロールを作成してバインドするには、次の手順を実行します。
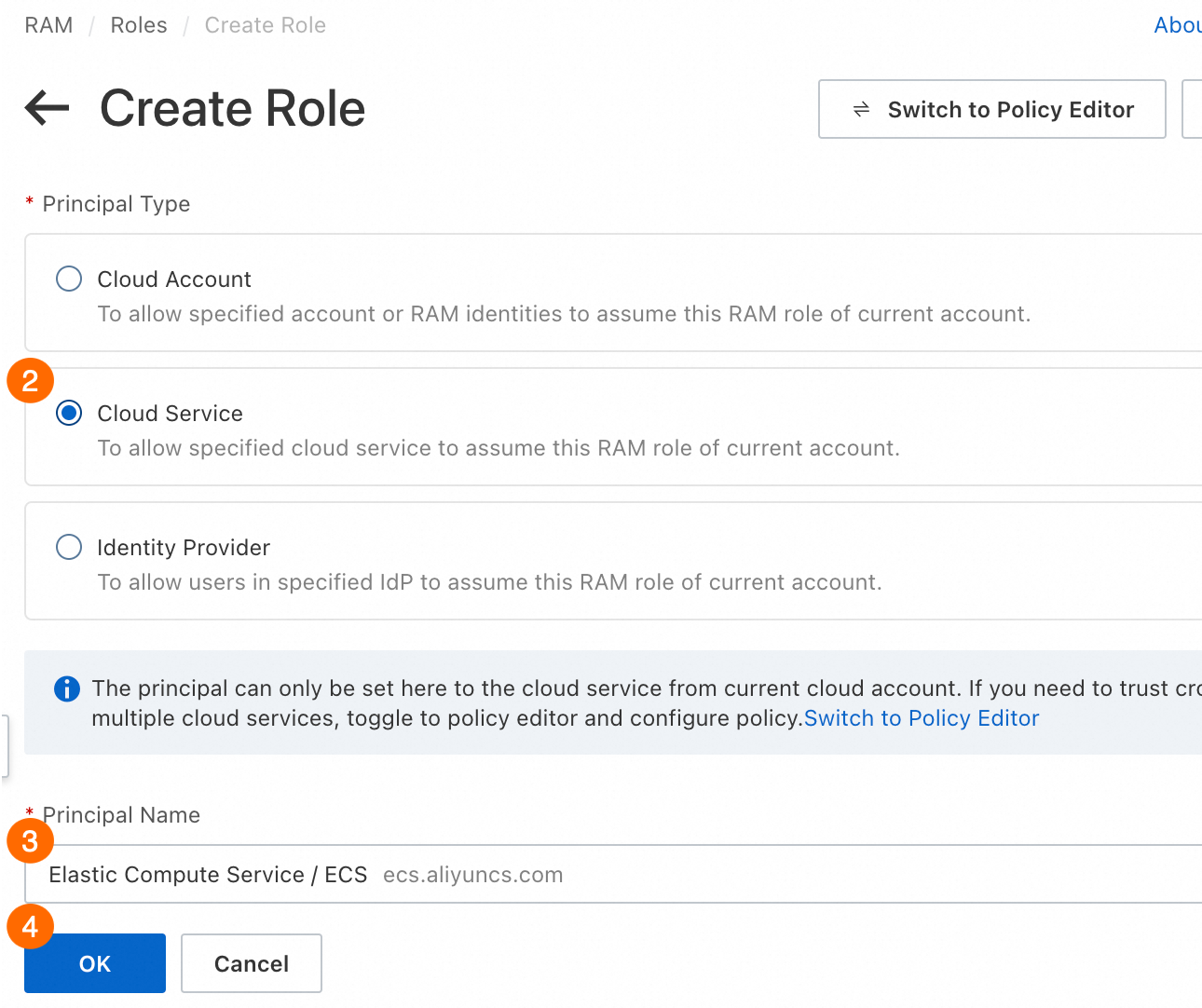
RAM コンソール で、RAM ロールを作成します。次の図は、この例の主要なパラメーター設定を示しています。
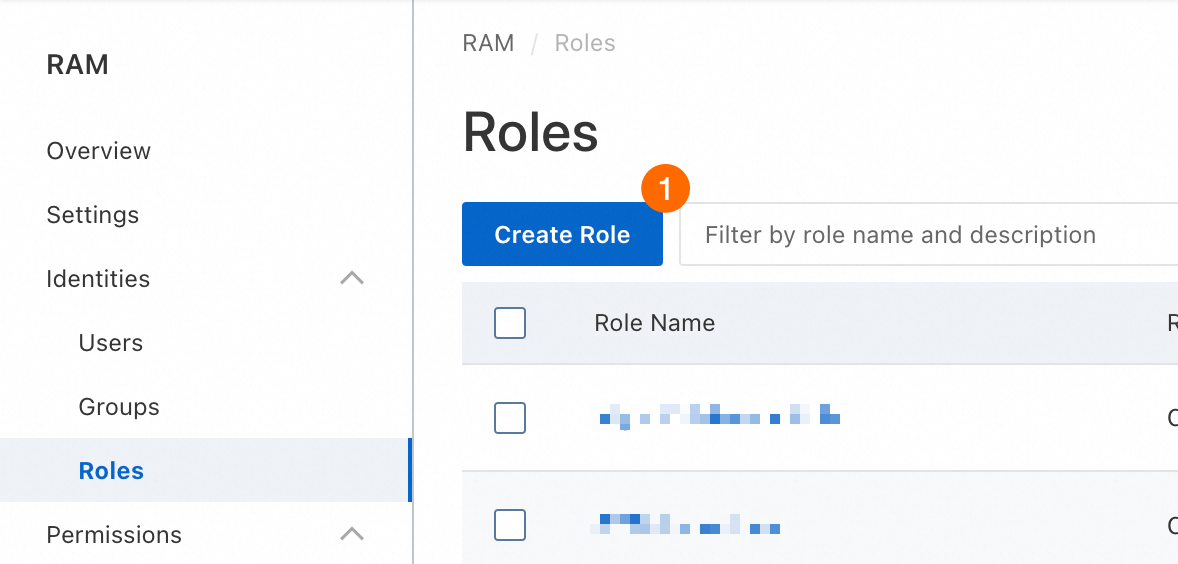
② プリンシパルタイプ:[クラウドサービス] を選択します。
③ プリンシパル名:[Elastic Compute Service] を選択します。これは、RAM ロールが ECS インスタンスに割り当てられることを指定します。
④ [OK] をクリックし、プロンプトに従って RAM ロールの名前を指定します。
RAM コンソール で、次の図に示すようにカスタムポリシーを作成します。
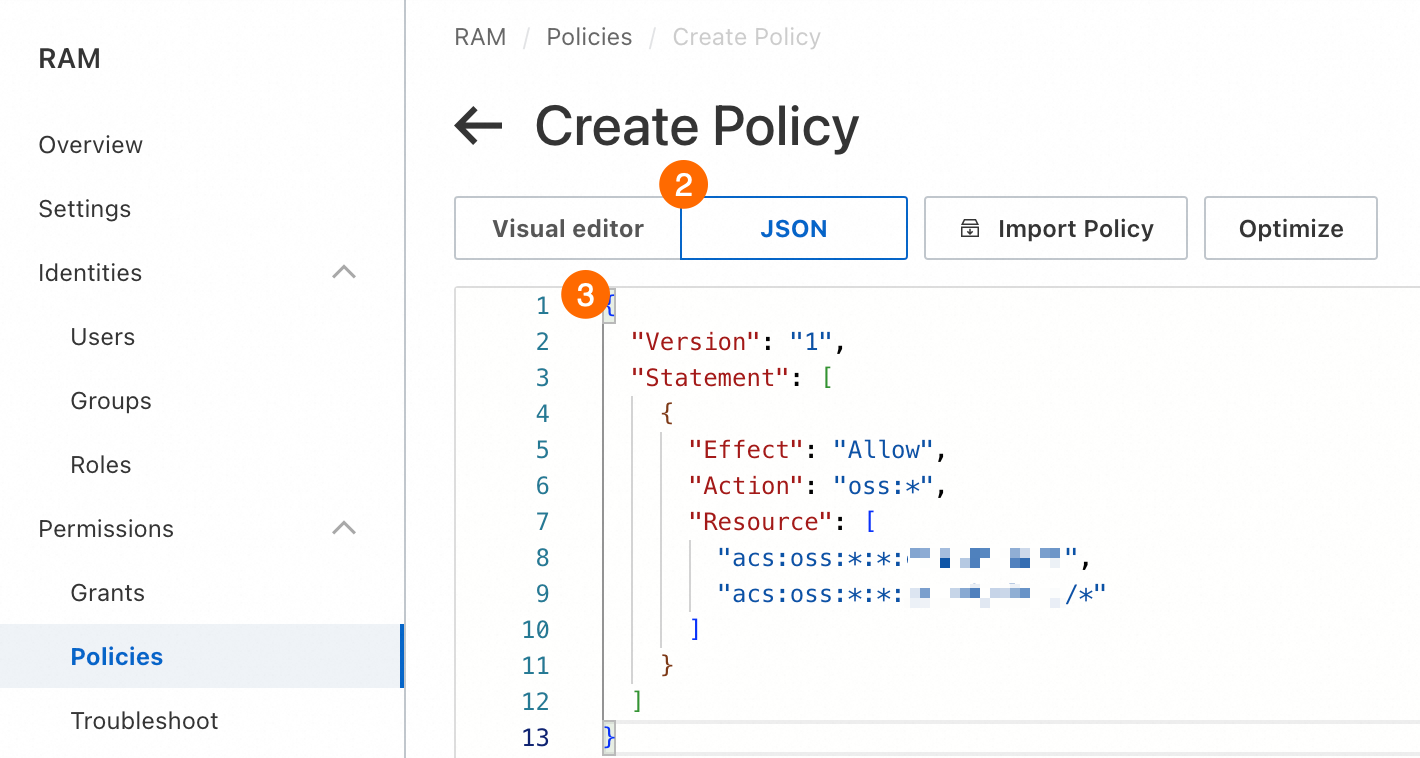
③ このポリシーは、OSS バケットにアクセスするために必要なすべての権限を付与します。ポリシースクリプトは次のとおりです。
重要カスタムポリシーを構成する際は、
<bucket_name>を実際に作成したバケットの名前に置き換えてください。{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": "oss:*", "Resource": [ "acs:oss:*:*:<bucket_name>", "acs:oss:*:*:<bucket_name>/*" ] } ] }[OK] をクリックし、プロンプトに従ってポリシー名を設定します。
RAM コンソール で、RAM ロールに権限を付与します。
⑥ プリンシパル:作成した RAM ロールを選択します。
⑦ ポリシー:作成したカスタムポリシーを選択します。
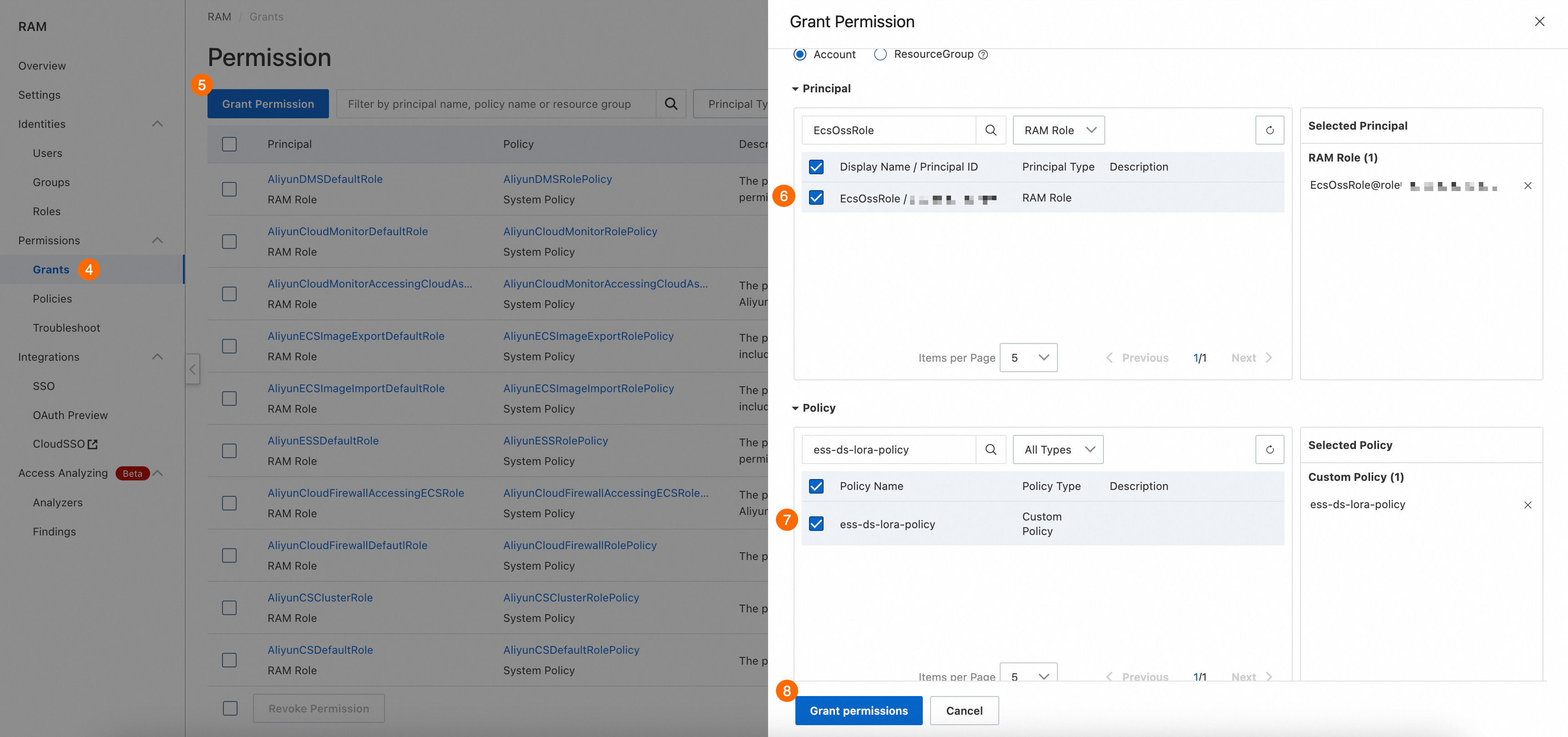
[権限の付与] をクリックします。
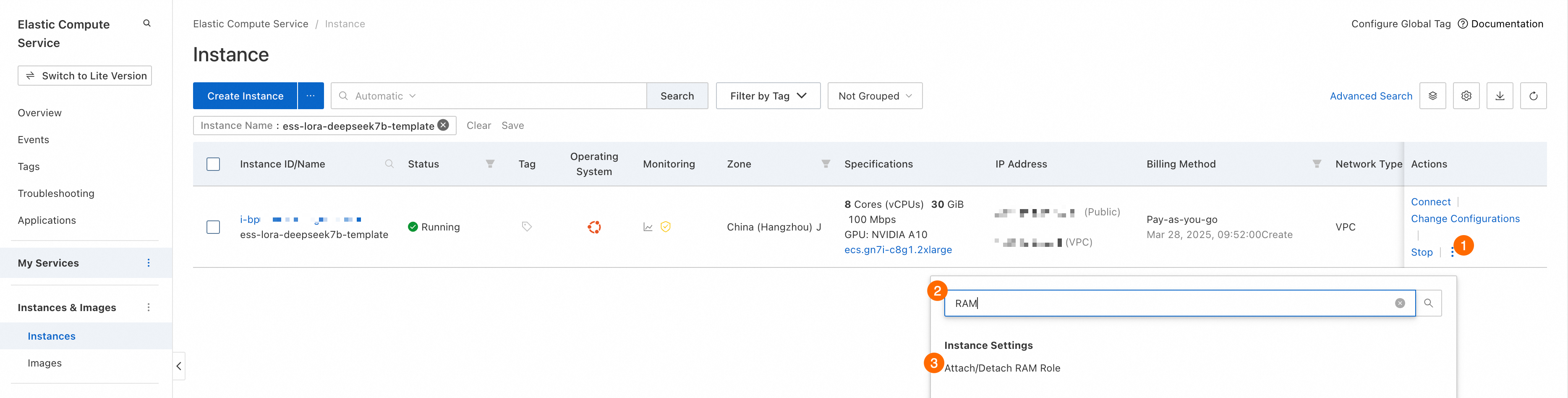
ECS コンソール にログインし、ECS インスタンスに RAM ロールを割り当てます。
ECS インスタンスが見つからない場合は、現在のリージョンがインスタンスのリージョンと一致しているかどうかを確認してください。左上隅のドロップダウンリストを使用してリージョンを切り替えることができます。
OSS バケットを ECS インスタンスにマウントします。
手順 1.1 で作成した ECS インスタンスに接続し、次のコマンドを実行して ossfs をインストールします。
wget https://gosspublic.alicdn.com/ossfs/ossfs_1.91.5_ubuntu22.04_amd64.deb apt-get update DEBIAN_FRONTEND=noninteractive apt-get install gdebi-core DEBIAN_FRONTEND=noninteractive gdebi -n ossfs_1.91.5_ubuntu22.04_amd64.deb次のコマンドを実行して OSS バケットをマウントします。コマンドのパラメーター設定を次の値で更新します。
<bucket_name>:これを、作成したバケットの名前に置き換えます。<ecs_ram_role>:これを、作成した RAM ロールの名前に置き換えます。ECS コンソール に移動し、RAM ロールが割り当てられているインスタンスを見つけて、次の図に示す手順に従って [RAM ロールの割り当て/割り当て解除] ページに移動します。
このページには、インスタンスに割り当てられている RAM ロールが表示されます。
ECS インスタンスが見つからない場合は、現在のリージョンがインスタンスのリージョンと一致しているかどうかを確認してください。左上隅のドロップダウンリストを使用してリージョンを切り替えることができます。
<internal_endpoint>:これをoss-cn-hangzhou-internal.aliyuncs.comに置き換えます。重要この例では、バケットは [中国 (杭州)] リージョンにあります。そのため、使用される VPC エンドポイントは
oss-cn-hangzhou-internal.aliyuncs.comです。中国 (杭州) 以外のリージョンに OSS バケットを作成した場合は、VPC エンドポイントを取得し、
<internal_endpoint>を取得した VPC エンドポイントに置き換えます。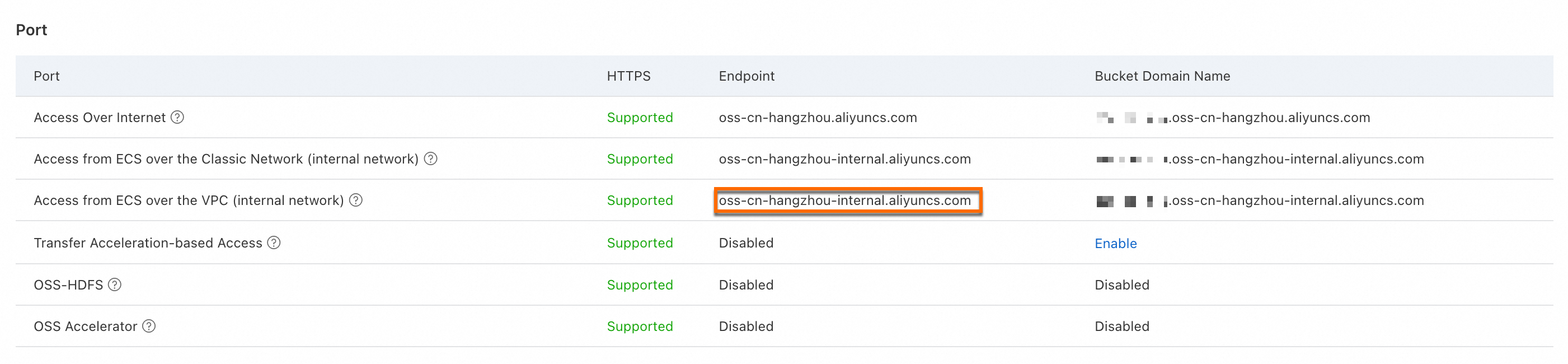
# バケット名、VPC エンドポイント、および RAM ロールをそれぞれの実際の値に置き換えます。 BUCKET_NAME="<bucket_name>" ECS_RAM_ROLE="<ecs_ram_role>" INTERNAL_ENDPOINT="<internal_endpoint>" # バケットのマウントディレクトリ。 BUCKET_MOUNT_PATH="/mnt/oss-data" #1. マウントする前に fstab ファイルをバックアップします。 cp /etc/fstab /etc/fstab.bak #2. マウントディレクトリを作成します。 mkdir $BUCKET_MOUNT_PATH #3. バケットをインスタンスにマウントします。 ossfs $BUCKET_NAME $BUCKET_MOUNT_PATH -ourl=$INTERNAL_ENDPOINT -oram_role=http://100.100.100.200/latest/meta-data/ram/security-credentials/$ECS_RAM_ROLE #4. インスタンスの起動時に自動マウントを有効にします。 echo "ossfs#$BUCKET_NAME $BUCKET_MOUNT_PATH fuse _netdev,url=http://$INTERNAL_ENDPOINT,ram_role=http://100.100.100.200/latest/meta-data/ram/security-credentials/$ECS_RAM_ROLE,allow_other 0 0" | sudo tee -a /etc/fstab
ストレージ容量が利用可能かどうかを確認します。
OSS バケットにファイルをアップロードします。
インスタンスで次のコマンドを実行して、マウントディレクトリにファイルが表示されるかどうかを確認します。
ls /mnt/oss-data/表示された場合は、マウントが成功しています。

1.3 モデルとデータセットを準備する
このトピックで参照されているモデルの重みファイルとデータセットは、ModelScope コミュニティからダウンロードできます。ECS インスタンスに接続した後、モデルとデータセットを OSS バケットのマウントディレクトリにダウンロードし、すべてのファイルのダウンロードが完了するまで待ちます。
データセットをダウンロードする
# バケットのマウントディレクトリ。 BUCKET_MOUNT_PATH="/mnt/oss-data" # ModelScope コミュニティからファインチューニングデータセットをダウンロードします。 # 手順 1.1 でインストールした modelscope ツールを使用します。 modelscope download --dataset swift/self-cognition --local_dir $BUCKET_MOUNT_PATH/self-cognition modelscope download --dataset AI-ModelScope/alpaca-gpt4-data-zh --local_dir $BUCKET_MOUNT_PATH/alpaca-gpt4-data-zh modelscope download --dataset AI-ModelScope/alpaca-gpt4-data-en --local_dir $BUCKET_MOUNT_PATH/alpaca-gpt4-data-en進捗が停止した場合は、Enter キーを数回押してみてください。
モデルの重みファイルをダウンロードする
重要モデルの重みファイルが大きすぎてダウンロードに失敗した場合、または
please try againメッセージが表示された場合は、コマンドを再試行してダウンロードを再開してください。# バケットのマウントディレクトリ。 BUCKET_MOUNT_PATH="/mnt/oss-data" # ModelScope コミュニティから DeepSeek-R1-Distill-Qwen-7B モデルをダウンロードします。 modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir $BUCKET_MOUNT_PATH/DeepSeek-R1-Distill-Qwen-7B進捗が停止した場合は、Enter キーを数回押してみてください。
モデルの重みファイルが有効かどうかを確認する
ダウンロードが完了したら、ターミナルで次のコマンドを実行してモデルの機能をテストし、モデルの重みファイルが完全かどうかを確認します。
# バケットのマウントディレクトリ。 BUCKET_MOUNT_PATH="/mnt/oss-data" CUDA_VISIBLE_DEVICES=0 swift infer \ --model $BUCKET_MOUNT_PATH/DeepSeek-R1-Distill-Qwen-7B \ --stream true \ --infer_backend pt \ --max_new_tokens 2048次の図に示すように、モデルの重みファイルがロードされたら、大規模モデルとの対話を開始できます。モデルの重みファイルのロードに失敗した場合は、もう一度ダウンロードしてみてください。

テストが完了したら、
exitと入力します。
1.4 自動トレーニングスクリプトを作成する
自動トレーニングスクリプトを作成します。
次のコマンドを実行して自動トレーニングスクリプトを作成し、実行権限を付与します。このスクリプトは、最新のチェックポイントからトレーニングを自動的に再開し、トレーニングの進捗状況が完了するまで監視します。
# 自動トレーニングスクリプトを作成します。 cat <<EOF > /root/train.sh #!/bin/bash # バケットのマウントディレクトリ。 BUCKET_MONTH_PATH="/mnt/oss-data" # モデルの重みファイルとデータセットのストレージディレクトリ。 MODEL_PATH="\$BUCKET_MONTH_PATH/DeepSeek-R1-Distill-Qwen-7B" DATASET_PATH="\$BUCKET_MONTH_PATH/alpaca-gpt4-data-zh#500 \$BUCKET_MONTH_PATH/alpaca-gpt4-data-en#500 \$BUCKET_MONTH_PATH/self-cognition#500" # 出力ディレクトリを設定します。 OUTPUT_DIR="\$BUCKET_MONTH_PATH/output" mkdir -p "\$OUTPUT_DIR" # 操作を必要とせずにトレーニングが完了したことを確認します。 if [ -f "\$OUTPUT_DIR/logging.jsonl" ]; then last_line=\$(tail -n 1 "\$OUTPUT_DIR/logging.jsonl") if echo "\$last_line" | grep -q "last_model_checkpoint" && echo "\$last_line" | grep -q "best_model_checkpoint"; then echo "トレーニングはすでに完了しています。終了します。" exit 0 fi fi # 復旧パラメーターを初期化します。 RESUME_ARG="" # 最新のチェックポイントを見つけます LATEST_CHECKPOINT=\$(ls -dt \$OUTPUT_DIR/checkpoint-* 2>/dev/null | head -1) if [ -n "\$LATEST_CHECKPOINT" ]; then RESUME_ARG="--resume_from_checkpoint \$LATEST_CHECKPOINT" echo "トレーニングを次から再開します: \$LATEST_CHECKPOINT" else echo "チェックポイントが見つかりません。新しいトレーニングを開始します。" fi # トレーニングコマンドを開始します。 CUDA_VISIBLE_DEVICES=0 swift sft \\ --model \$MODEL_PATH \\ --train_type lora \\ --dataset \$DATASET_PATH \\ --torch_dtype bfloat16 \\ --num_train_epochs 1 \\ --per_device_train_batch_size 1 \\ --per_device_eval_batch_size 1 \\ --learning_rate 1e-4 \\ --lora_rank 8 \\ --lora_alpha 32 \\ --target_modules all-linear \\ --gradient_accumulation_steps 16 \\ --eval_steps 50 \\ --save_steps 10 \\ --save_total_limit 5 \\ --logging_steps 5 \\ --max_length 2048 \\ --output_dir "\$OUTPUT_DIR" \\ --add_version False \\ --overwrite_output_dir True \\ --system 'You are a helpful assistant.' \\ --warmup_ratio 0.05 \\ --dataloader_num_workers 4 \\ --model_author swift \\ --model_name swift-robot \\ \$RESUME_ARG EOF # 実行権限を付与します。 chmod +x /root/train.sh次のコマンドを実行して、スクリプトが正しく実行されることを確認します。
./train.sh次の図に示すように、コマンドを実行した後にモデルが正しくロードされ、トレーニングが問題なく開始された場合は、モデルファイルが有効であり、依存関係が完全であることが確認されます。トレーニングを終了するには、
CTRL + Cを押します。
そうでない場合は、手順 1.1 の説明に従って Python の依存関係を再インストールし、手順 1.3 の指示に従ってモデルの重みファイルとデータセットをダウンロードします。
Linux サービスをセットアップし、システム起動時に自動起動を有効にします。
次のコマンドを実行して Linux サービスを作成し、システム起動時にトレーニングスクリプトが自動的に起動するようにします。
# ログストレージディレクトリを作成します。 mkdir -p /root/train-service-log # サービス構成ファイルを作成します。 cat <<EOF > /etc/systemd/system/train.service [Unit] Description=Train AI Model Script After=network.target local-fs.target remote-fs.target Requires=local-fs.target remote-fs.target [Service] ExecStart=/root/train.sh WorkingDirectory=/root/ User=root Environment="PATH=/usr/bin:/usr/local/bin" Environment="CUDA_VISIBLE_DEVICES=0" StandardOutput=append:/root/train-service-log/train.log StandardError=append:/root/train-service-log/train_error.log [Install] WantedBy=multi-user.target EOF # systemd 構成をリロードします。 systemctl daemon-reload # システム起動時に train.service が自動的に起動するようにします。 systemctl enable train.serviceコマンドを実行すると、次の結果が生成されます。

1.5 イメージを作成する
前のすべての手順を完了したら、構成済みのインスタンスからカスタムイメージを作成します。このイメージは、スケールアウトされたインスタンスの起動テンプレートとして機能するため、依存関係を毎回再インストールする必要がなくなります。
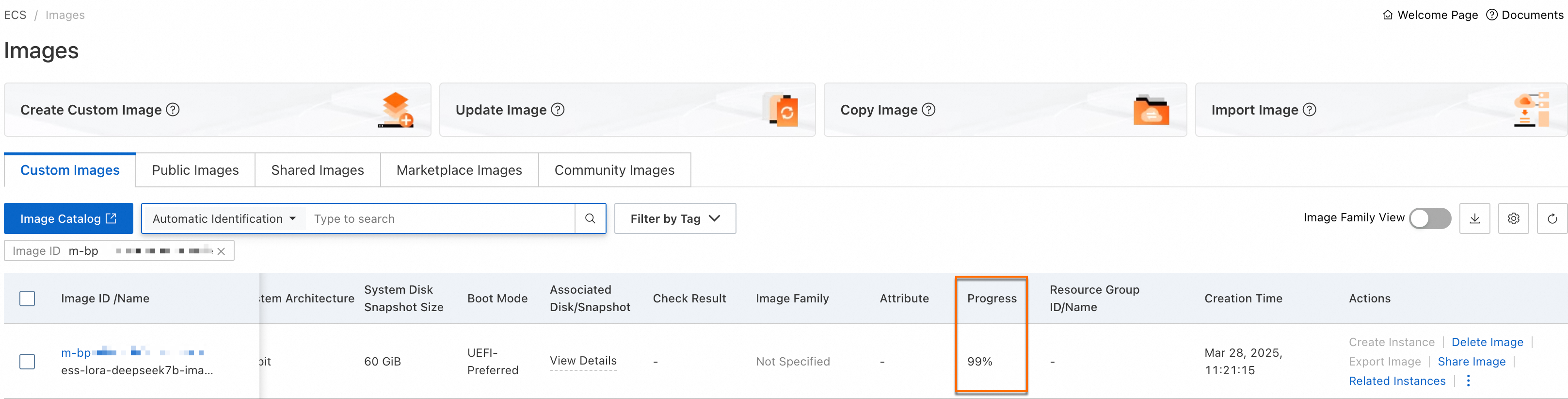
イメージの準備ができたら、手順 1.1 で作成したインスタンスを リリース できます。
2. スケーリンググループを作成する
インスタンス管理を自動化するスケーリンググループを構成できます。スケーリンググループは、既存のインスタンスが中断またはリクレイムされた場合に、新しいプリエンプティブルインスタンスまたは従量課金インスタンスが自動的に作成されてトレーニングが再開されるようにします。利用可能な場合は、プリエンプティブルインスタンスが従量課金インスタンスを自動的に置き換えてコストを削減します。
2.1 スケーリンググループを作成する
スケーリンググループを作成するには、次の手順を実行します。
Auto Scaling コンソール に移動します。
重要スケーリンググループは、手順 1.1 で作成した ECS インスタンスと同じリージョンにある必要があります。
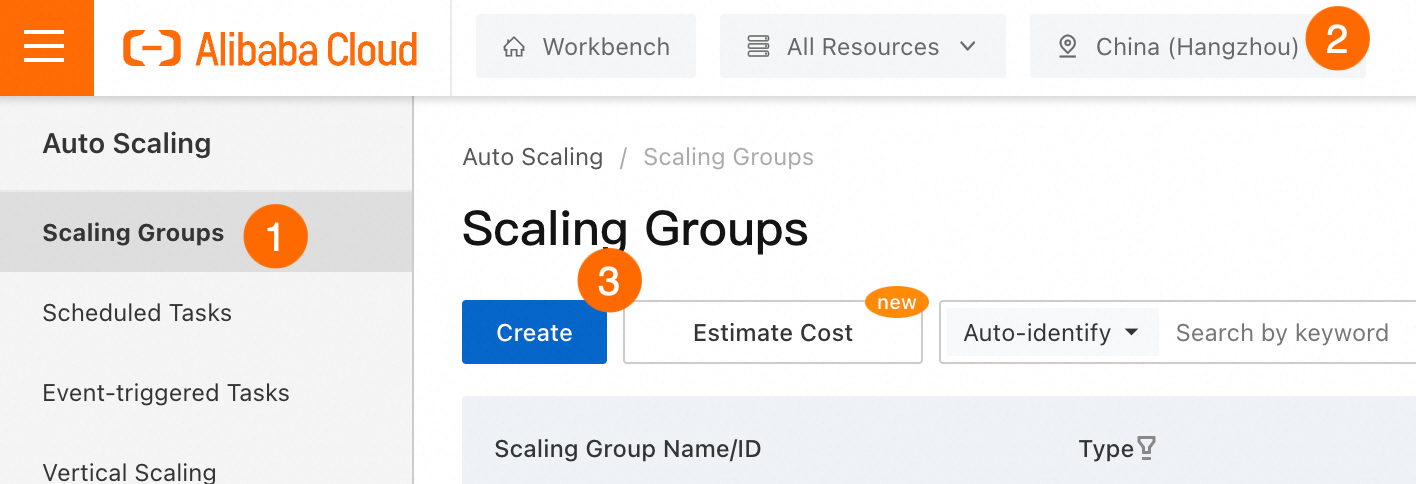
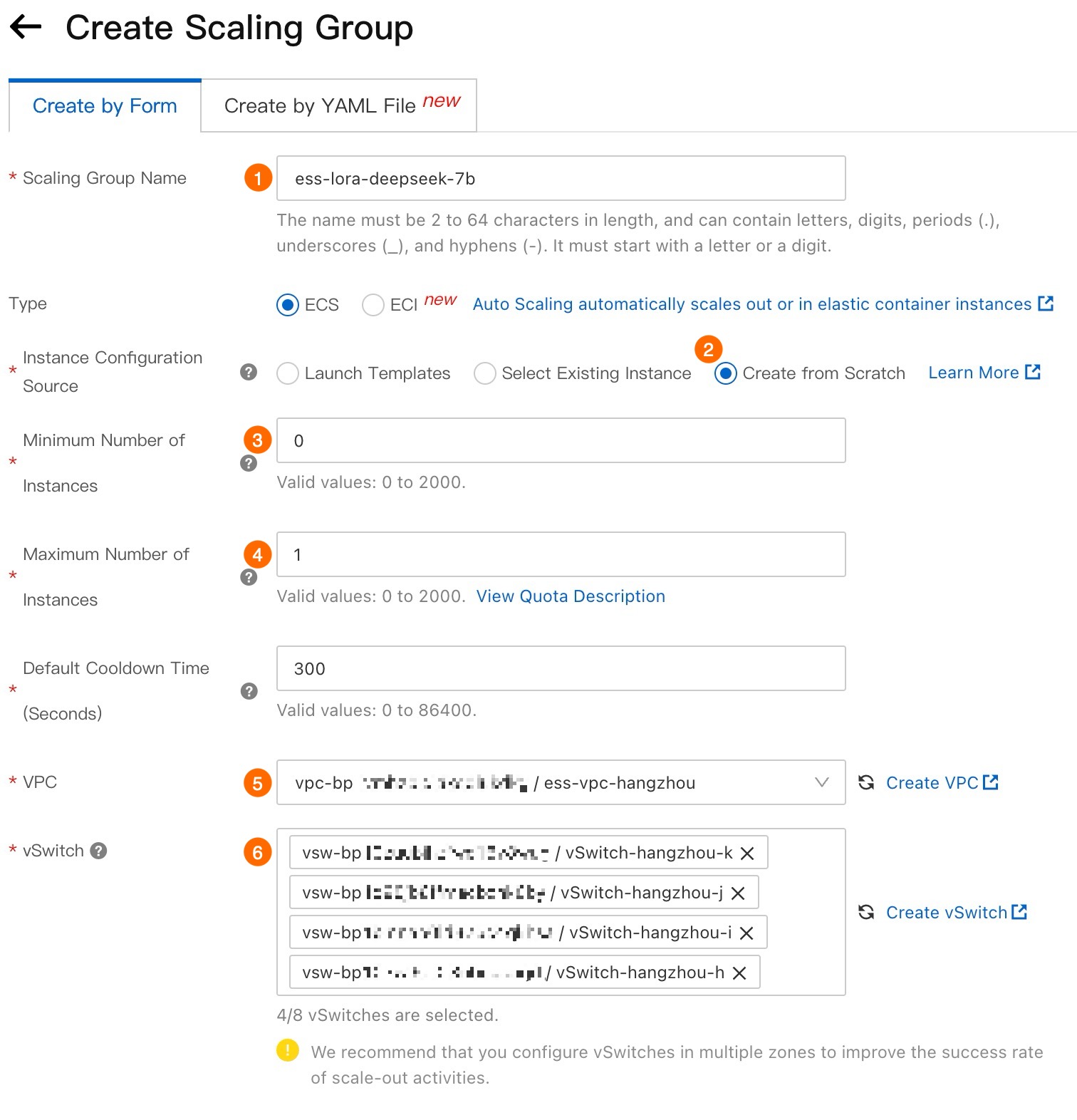
下の図に示す手順に従ってスケーリンググループを構成します。スケーリンググループの構成方法の詳細については、「パラメーター」をご参照ください。
 重要
重要VPC (⑤) と [vSwitch] (⑥) を構成する際は、複数のゾーンにわたる vSwitch を選択することをお勧めします。これにより、Auto Scaling はインスタンスを効率的に分散でき、プリエンプティブルインスタンスを利用できる可能性が高くなります。

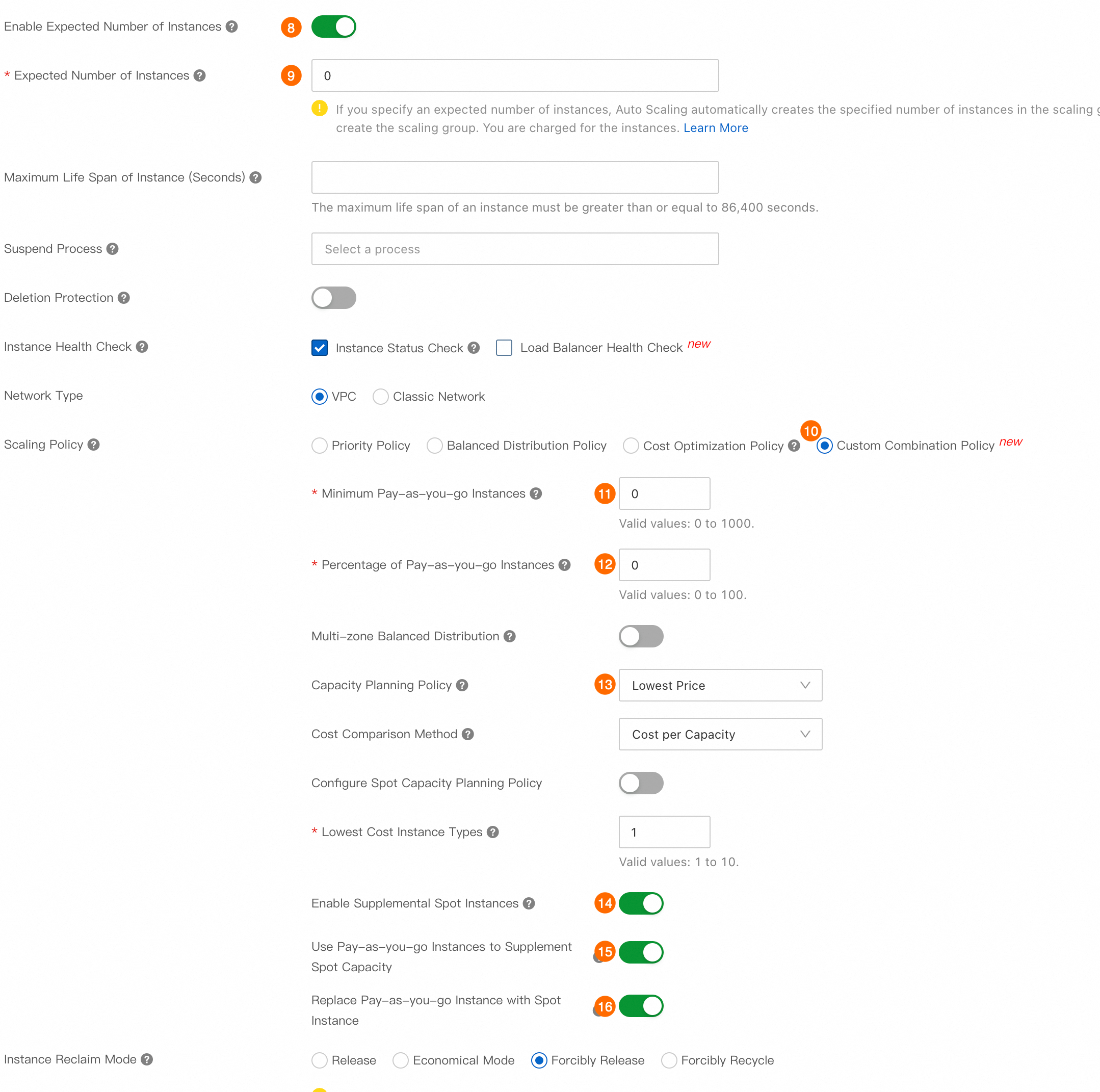 重要
重要プリエンプティブルインスタンスのみを使用してコストを削減するには、プリエンティブルキャパシティを補完するために従量課金インスタンスを使用する (⑮)プリエンプティブルインスタンスで従量課金インスタンスを置き換える (⑯) と オプションを無効にする必要があります。
[作成] をクリックします。次に、画面の指示に従ってスケーリング構成を作成します。
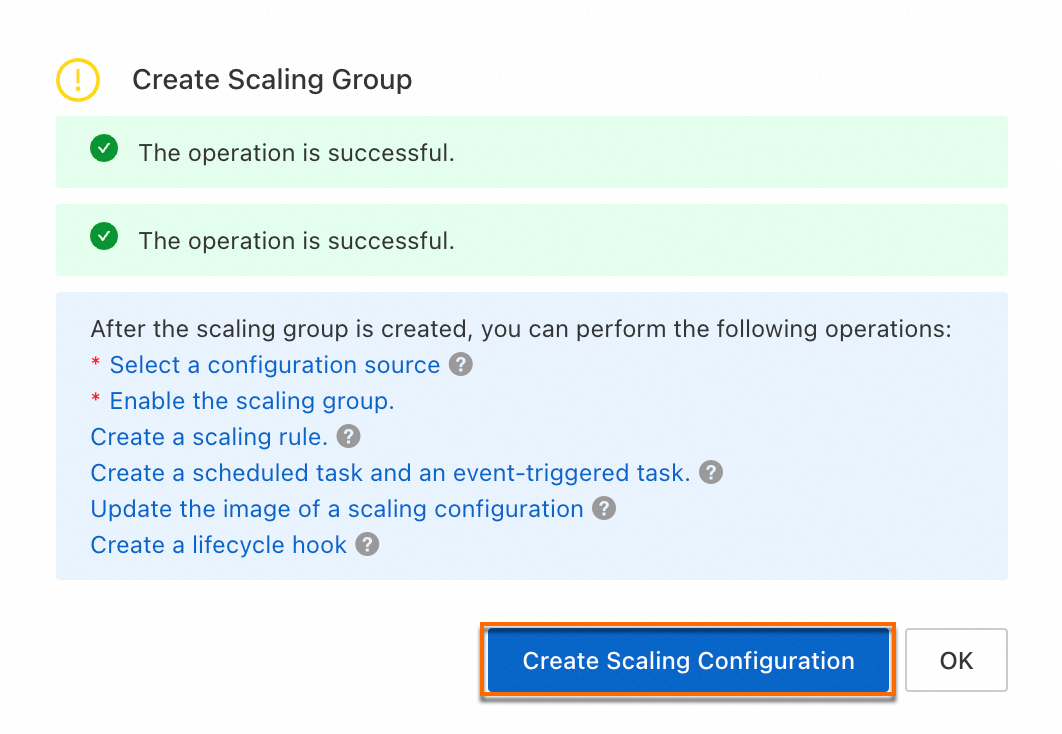
2.2 スケーリング構成を作成する
スケーリング構成は、スケーリンググループのインスタンスの仕様とイメージを定義します。スケーリング構成を作成した後、Auto Scaling はそれを使用して、定義されたインスタンス設定に基づいてスケーリンググループに新しいインスタンスを自動的に起動します。スケーリング構成を作成するには、次の手順を実行します。
[スケーリング構成の作成] ページにアクセスするには、次の手順に従います。
Auto Scaling コンソール に移動します。
重要スケーリング構成は、手順 1.1 で作成したインスタンスと同じリージョンにある必要があります。
[スケーリンググループ] ページで、手順 2.1 で作成したスケーリンググループを見つけて、その ID をクリックして詳細ページに移動します。下の図に示す手順に従って、スケーリング構成の作成 ページに移動します。
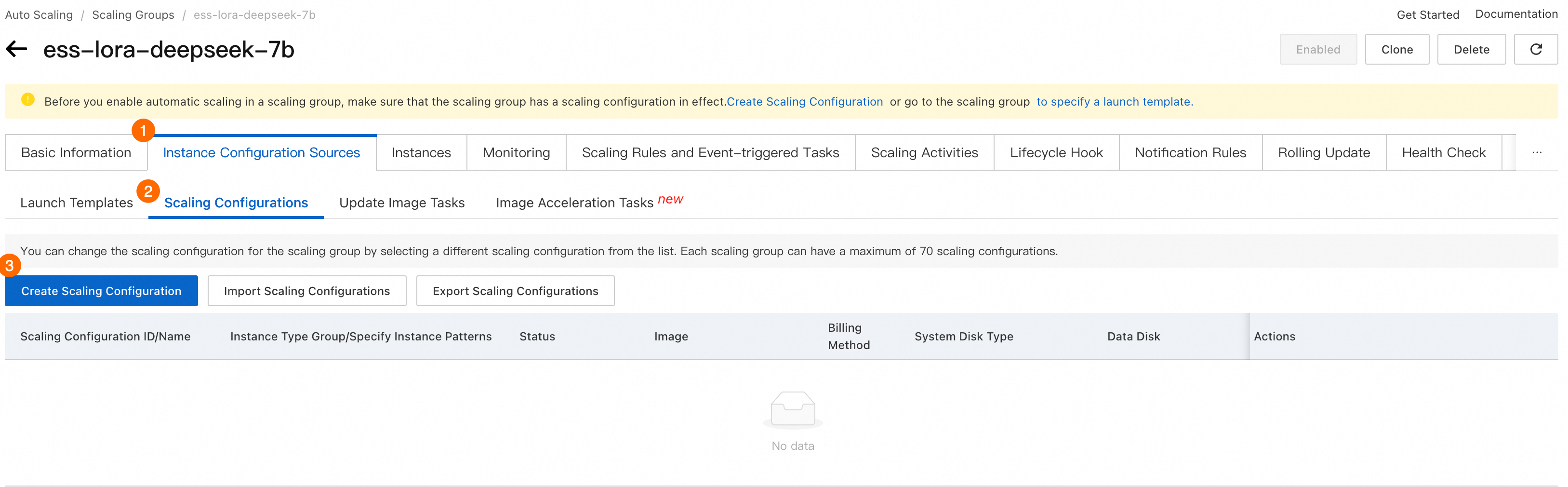
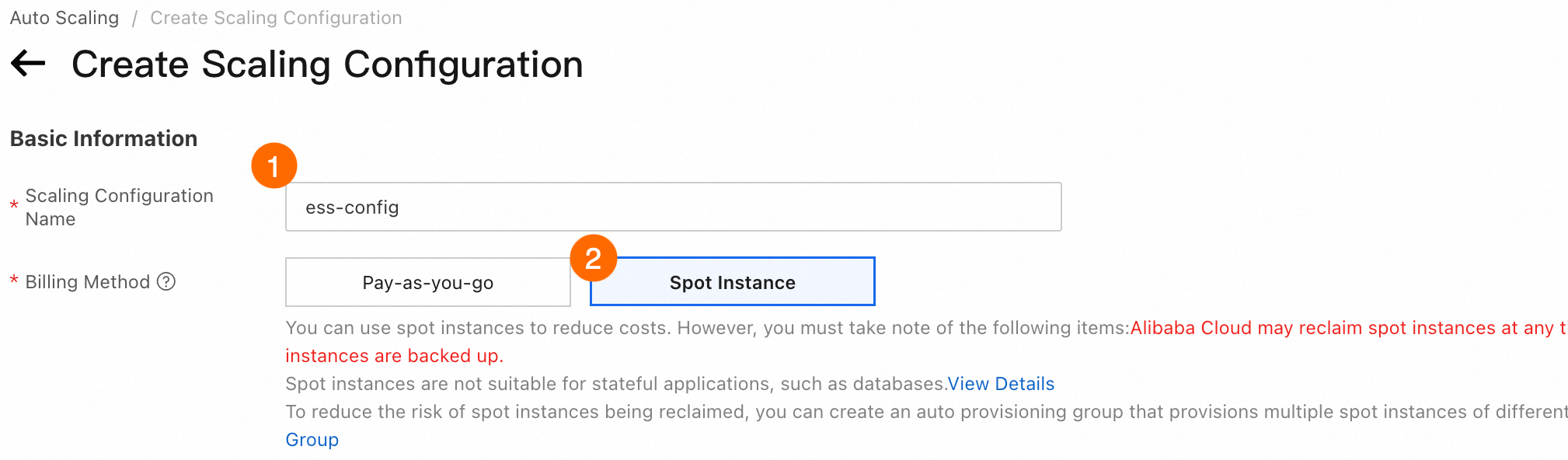
① スケーリング構成名: ② 課金方法:プリエンプティブル インスタンス を選択します。
|
③④ イメージの選択 > カスタムイメージ:[カスタムイメージ] タブをクリックし、手順 1.5 で作成したカスタムイメージを選択します。 ⑤ インスタンス構成モード:[インスタンスタイプを指定] を選択します。 ⑥ インスタンスの使用期間:[1 時間の使用期間] を選択します。このオプションを使用すると、プリエンプティブルインスタンスが 1 時間実行された後、Auto Scaling はインスタンスを中断およびリクレイムするかどうかを評価します。 [使用期間の指定なし] を選択すると、従量課金インスタンスを低コストで使用できる場合があります。ただし、終了およびリクレイムされる可能性が高いため、インスタンスがリクレイムされる前に有効なチェックポイントが作成されない可能性があり、トレーニングの進捗が遅くなる可能性があります。2 つのオプションの違いの詳細については、「プリエンプティブルインスタンスを使用してコストを削減する」をご参照ください。 ⑦ インスタンスあたりの最高価格:[自動入札を使用] を選択します。このオプションを使用すると、Auto Scaling は現在の市場価格に応じて入札価格を自動的に調整します。 ⑧ インスタンスタイプの選択:手順 1.1 で選択したインスタンスタイプ(
|
⑨ セキュリティグループ:手順 1.1 で選択したセキュリティグループを選択します。 この例では、オフラインのトレーニングソリューションを示しています。パブリック IP アドレスの割り当ては必須ではありません。
|
⑩ ログイン資格情報:[イメージプリセットパスワード] を選択します。
|
⑪⑫⑬ 手順 1.2 で作成した RAM ロールを選択します。インスタンスがスケーリンググループに自動的に作成されると、RAM ロールが新しいインスタンスに自動的に割り当てられます。
|
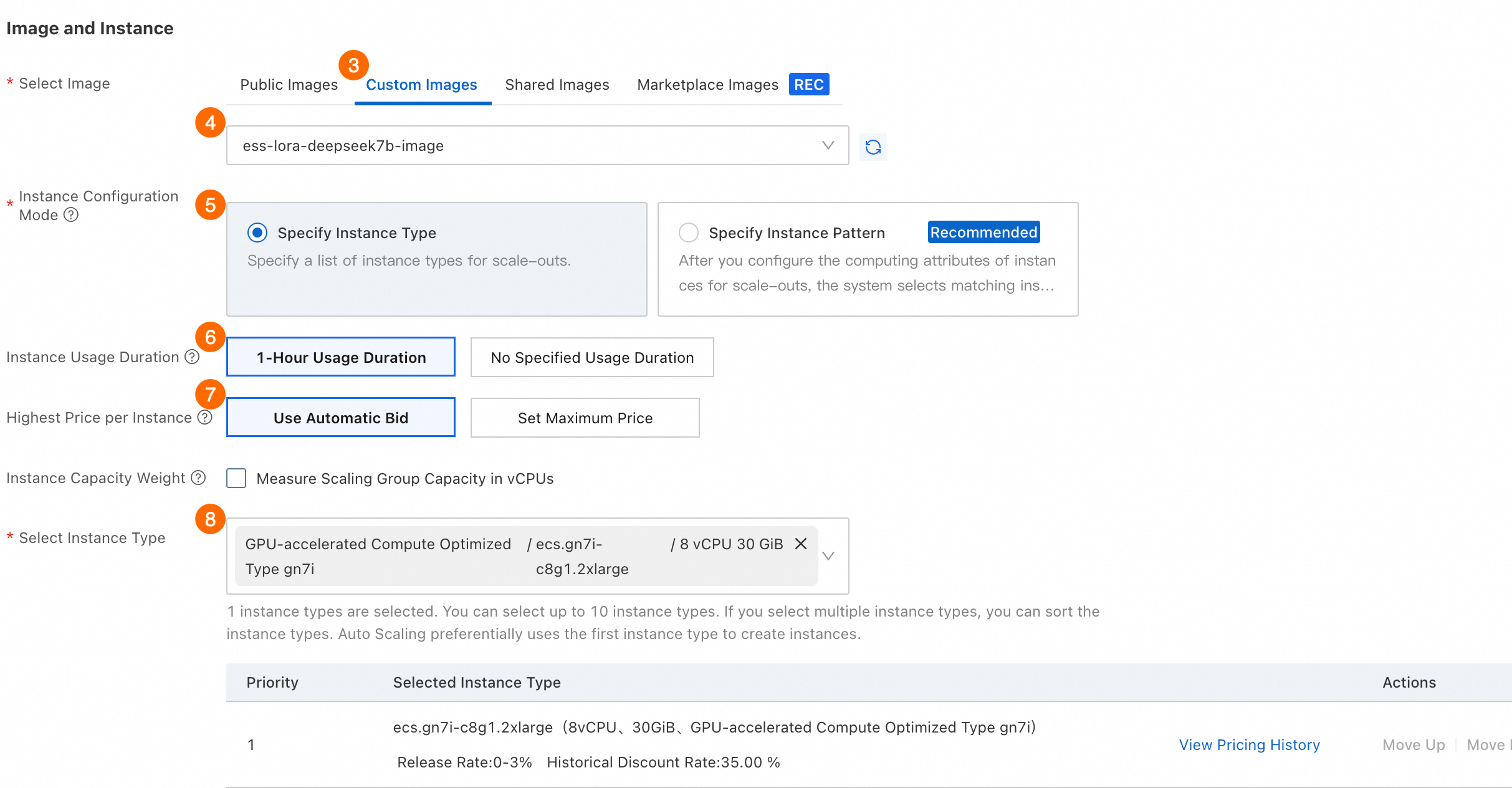


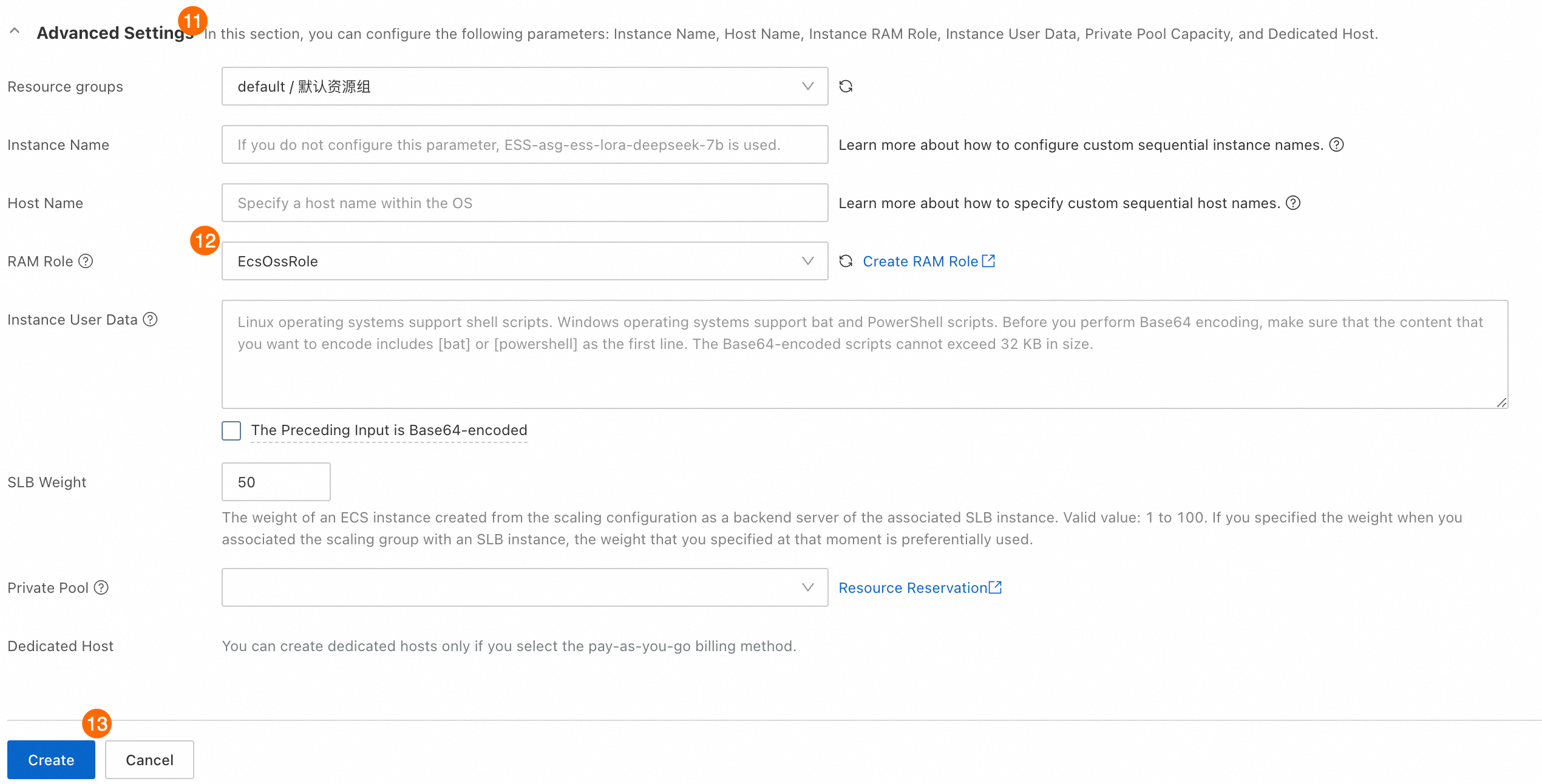
[作成] をクリックします。スケーリング強度が不十分であることを示すメッセージが表示された場合は、[続行] をクリックしてください。
プロンプトに従ってスケーリンググループとスケーリング構成を有効にします。
|
|
|


3. トレーニングを開始する
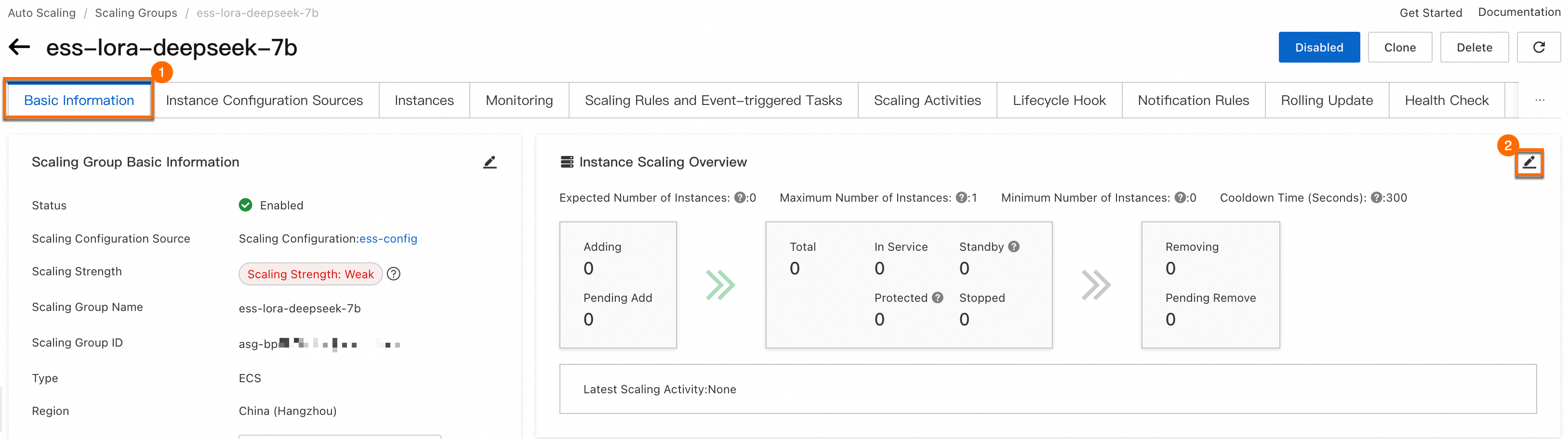
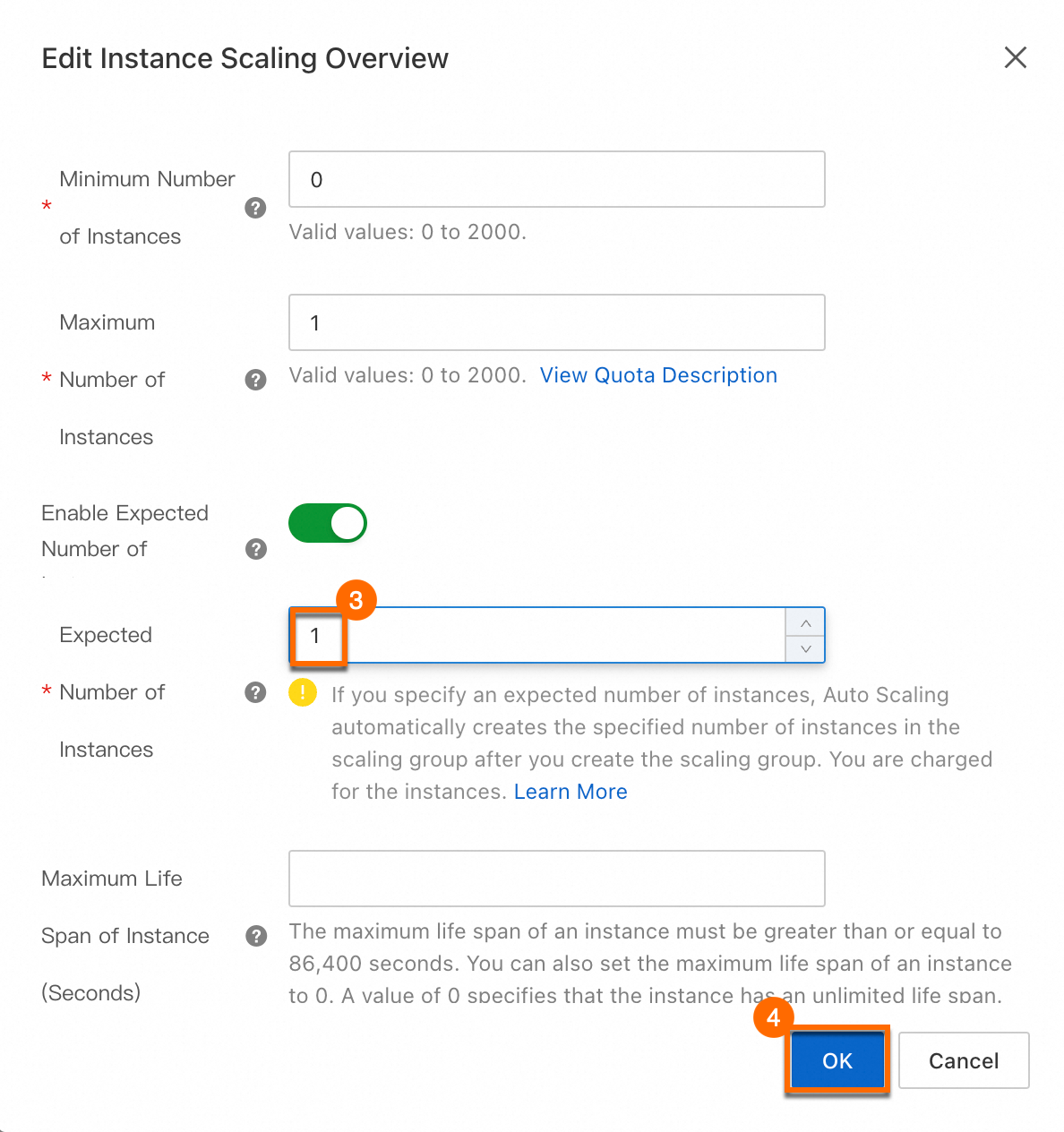
スケーリンググループが構成されたら、必要なインスタンス数を 1 に調整します。プロセスを下の図に示します。
|
|
その後、Auto Scaling はスケーリンググループに新しいインスタンスを自動的にプロビジョニングしてトレーニングを開始します。
Auto Scaling は、スケーリンググループのインスタンス数が予期される数と一致するかどうかを定期的にチェックします。スケーリンググループにインスタンスがない場合(つまり、数が 0 の場合)、スケールアウト操作が自動的にトリガーされて新しいインスタンスが作成されます。
必要なインスタンス数を調整した後、インスタンスの作成が遅れる場合があります。スケーリングアクティビティの進捗状況は、スケーリンググループの [スケーリングアクティビティ] タブで監視できます。
インスタンスが作成されて起動された後、OSS バケットの
outputディレクトリを見つけることができます。このディレクトリには、トレーニング中に生成されたチェックポイントが保存されます。
4. テスト:中断とリクレイムをシミュレートする
インスタンスがトレーニングタスクの実行を開始したら、OSS バケットの output ディレクトリをチェックして、checkpoint-10 などのフォルダーが作成されているかどうかを確認します。チェックポイントが生成されたら、インスタンスを手動でリリースして中断とリクレイムをシミュレートできます。インスタンスを手動でリリースするには、次の手順に従います。
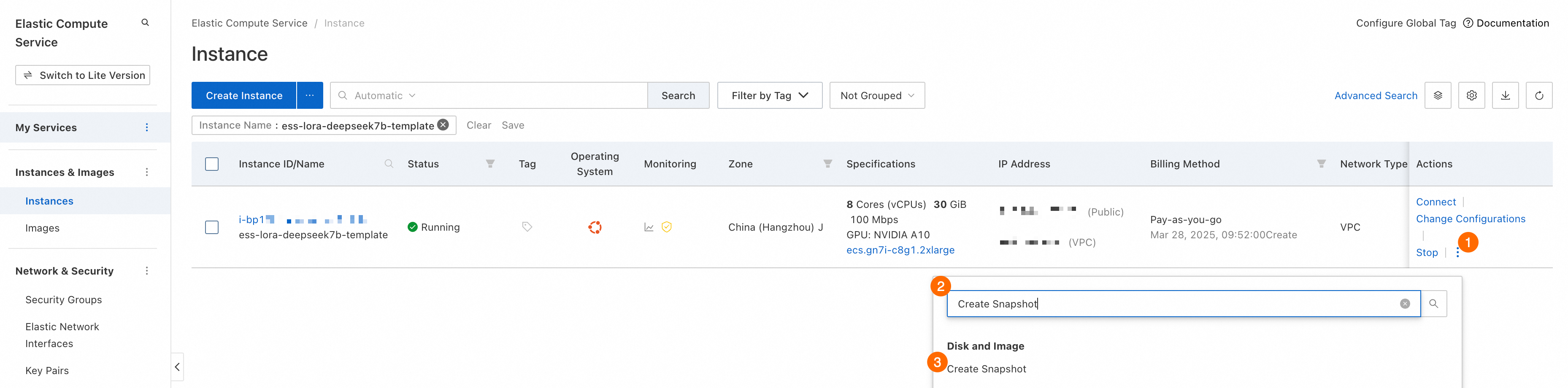
インスタンスを手動でリリースします。
スケーリンググループの [インスタンス] タブに移動します。インスタンス ID をクリックして、インスタンスの詳細ページに移動します。.
[インスタンスの詳細] タブで、右上隅にある を選択します。次に、プロンプトに従ってインスタンスをリリースします。

最新のチェックポイントからトレーニングを再開できることを確認します。
スケーリンググループに新しいインスタンスが作成されるまで待ちます。インスタンスの準備ができたら、接続してトレーニングログを表示します。
スケーリンググループの [インスタンス] タブに移動します。インスタンス ID をクリックして、インスタンスの詳細ページに移動します。.
右上隅にある [接続] をクリックし、プロンプトに従ってインスタンスに接続します。
モデルのトレーニングログを表示するには、次のコマンドを実行します。ログパスは、手順 1.4 で指定したものです。
cat /root/train-service-log/train.logコマンド出力は、トレーニングタスクが最新のチェックポイントから再開されたことを示しています。

次のステップ
ファインチューニングされたモデルを推論に使用する
ファインチューニングトレーニングタスクを完了すると、OSS バケットの output ディレクトリに checkpoint-93 という名前のフォルダーが生成されます。インスタンスに接続し、次のコマンドを実行して、ファインチューニングされたモデルと対話できます。
# バケットのマウントディレクトリ。
BUCKET_MOUNT_PATH="/mnt/oss-data"
# 出力ディレクトリを設定します。
OUTPUT_DIR="$BUCKET_MOUNT_PATH/output"
# 最新のチェックポイントを見つけます
LATEST_CHECKPOINT=$(ls -dt $OUTPUT_DIR/checkpoint-* 2>/dev/null | head -1)
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters $LATEST_CHECKPOINT \
--stream true \
--temperature 0 \
--max_new_tokens 2048
このトピックで使用されているリソースをリリースする
このソリューションを実稼働環境に適用するための推奨事項
このソリューションを実稼働環境に適用する前に、次の推奨事項を確認し、特定のビジネスニーズに合わせてソリューションを調整してください。
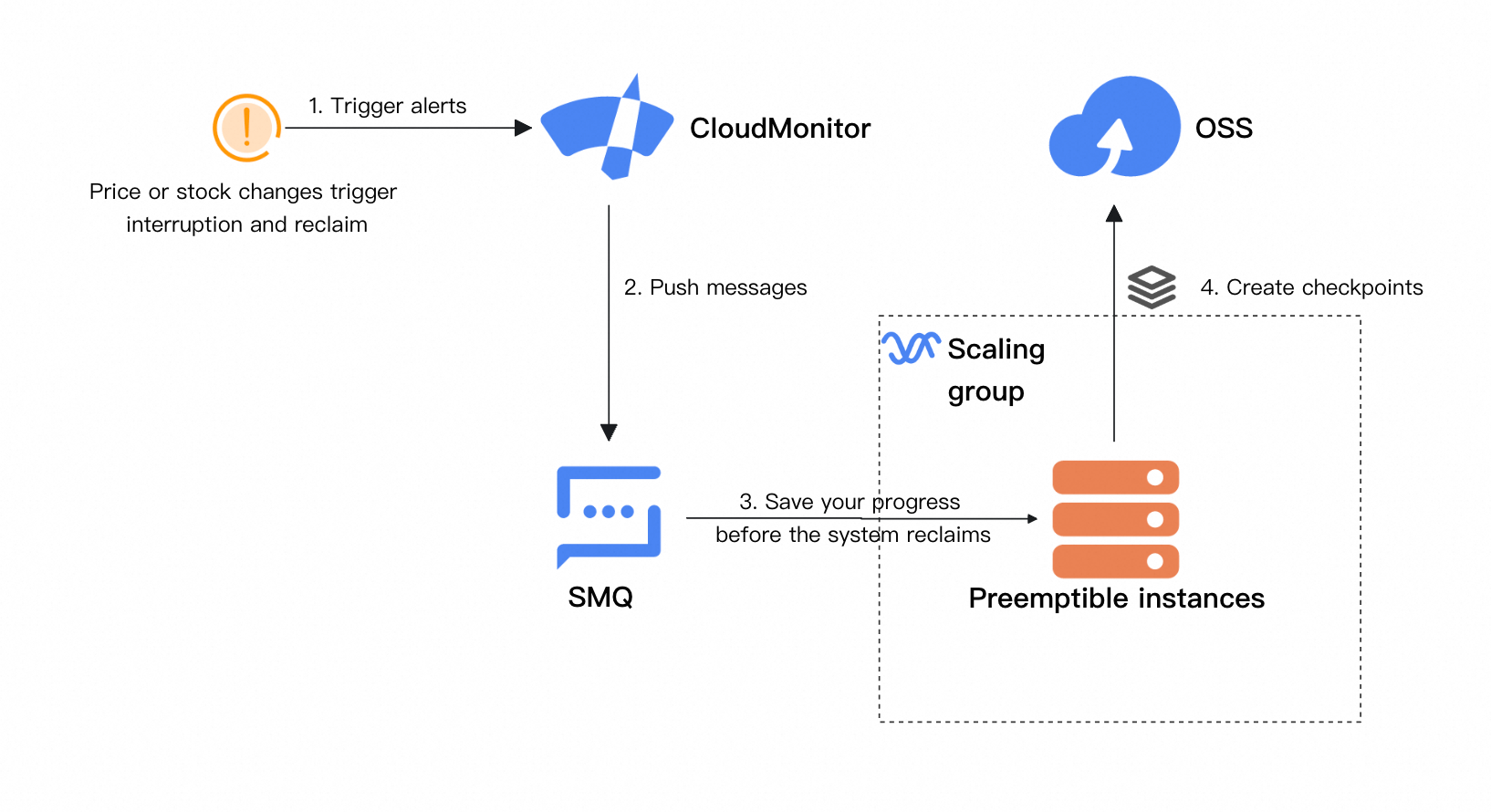
CloudMonitor を統合して中断とリクレイムを検出する
実稼働環境では、CloudMonitor をトレーニングコードに統合して、プリエンプティブルインスタンスの中断とリクレイムを検出して処理する ことをお勧めします。中断またはリクレイムの 5 分前にチェックポイントを保存することで、トレーニングの再開時の進捗の損失を最小限に抑えることができます。更新されたソリューションアーキテクチャは次のとおりです。
包括的なタスク復旧メカニズムを作成する
このトピックの例では、トレーニングの再開は最新のチェックポイントから自動的に開始されます。ただし、チェックポイントの有効性は自動的に検証されません。実際のアプリケーションでは、無効なチェックポイントを除外して、トレーニングが最新の有効なチェックポイントから再開されるように、異常検出メカニズムを実装することをお勧めします。
トレーニングタスクの終了を強化する
トレーニングの終了を判断するためのロジックをトレーニングコードに統合できます。トレーニングが完了したら、CLI または SDK を使用して API 操作 を呼び出し、必要なインスタンス数を 0 に設定します。その後、Auto Scaling はスケーリンググループの過剰なインスタンスを自動的にリリースし、リソースの無駄による不要なコストを回避します。
トレーニングが完了したら、カスタムイベントを CloudMonitor に報告する こともできます。その後、CloudMonitor はメール、ショートメッセージ、または DingTalk チャットボットを介してトレーニング結果を通知します。
より効率的なストレージモデルに切り替える
多数のパラメーターでモデルをトレーニングする場合、OSS はシステムのボトルネックにつながる可能性があります。システム全体の効率を高めるには、CPFS などの高スループット、低レイテンシのファイルシステムをマウントに使用することをお勧めします。
マルチゾーン vSwitch を構成する
1 つのゾーンにのみ vSwitch を構成すると、Auto Scaling はスケーリンググループのそのゾーンにのみインスタンスを作成できます。そのゾーンで利用可能なリソースが不足している場合、スケールアウトが失敗する可能性があります。複数のゾーンにわたる vSwitch を構成することをお勧めします。プリエンプティブルインスタンスがリクレイムされると、Auto Scaling は別のゾーンに新しいプリエンプティブルインスタンスを自動的に起動します。これにより、プリエンプティブルインスタンスが使用される可能性が高くなります。