モデルのファインチューニングコストを削減するために、スケーリンググループを使用してスポットインスタンスを自動的にプロビジョニングできます。このソリューションでは、スポットインスタンスが中断および回収された場合に、新しいインスタンスを自動的に作成し、最新のチェックポイントから再開することで、トレーニングの継続性を確保します。
ソリューションの概要
このソリューションでは、スケーリンググループを使用して、低コストで大規模モデルのファインチューニングを実現します。スポットインスタンス優先戦略を採用し、Object Storage Service (OSS) を使用してチェックポイントを永続化します。トレーニングプロセス中:
スポットインスタンスの優先: スケーリンググループは、トレーニングタスクにスポットインスタンスを優先的に使用し、OSS を使用してチェックポイントファイルを保存します。
スポットインスタンスが中断および回収された場合: スケーリンググループは、まず他のアベイラビリティゾーンの利用可能な在庫からスポットインスタンスをプロビジョニングしようとします。スポットインスタンスの在庫が不足している場合は、自動的に従量課金インスタンスをプロビジョニングし、最新のチェックポイントからトレーニングを再開します。
スポットインスタンスの在庫が回復した後: スケーリンググループは、自動的に従量課金インスタンスをスポットインスタンスに置き換え、最新のチェックポイントからトレーニングを再開します。
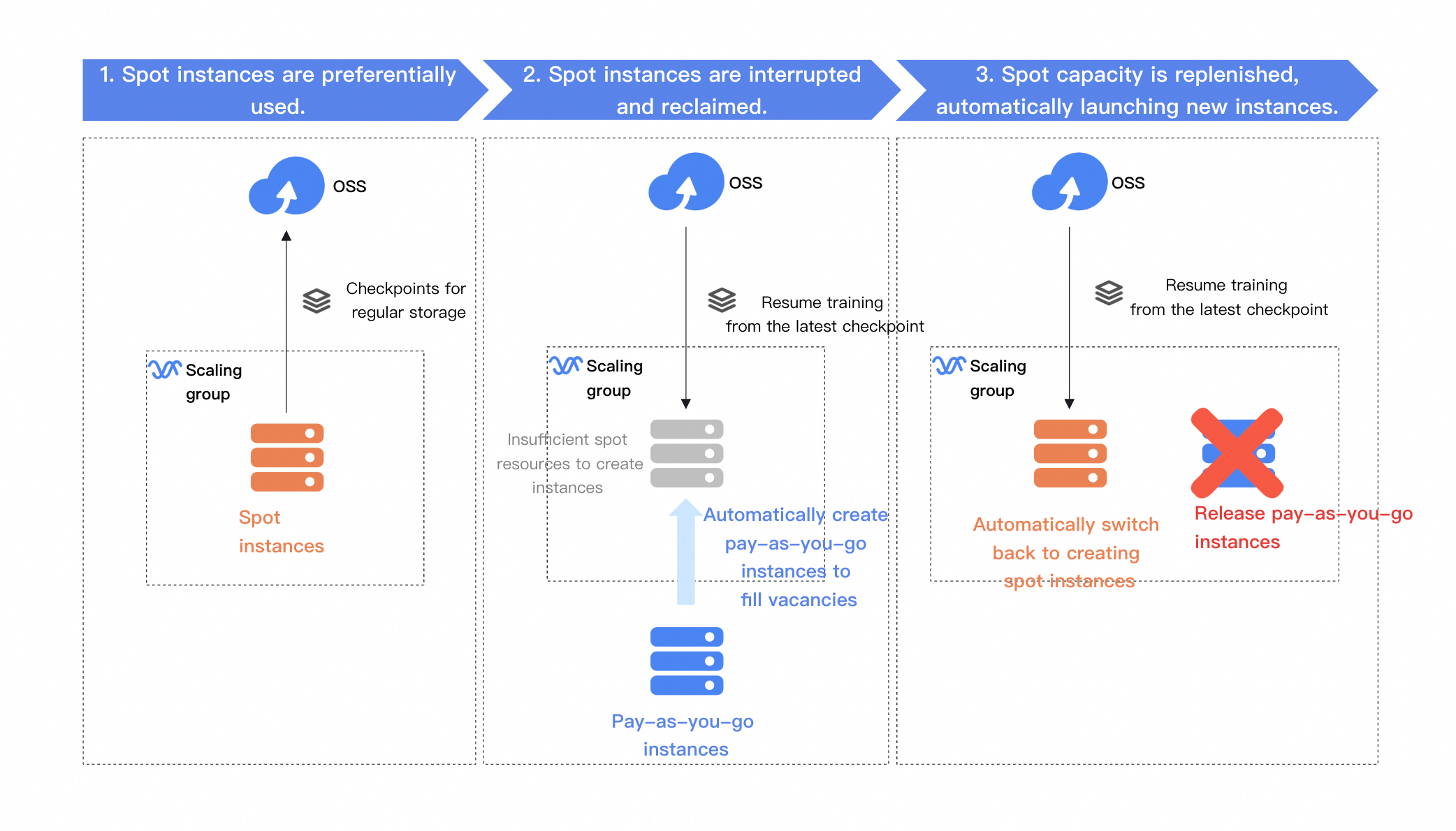
コストを重視し、トレーニング時間が長くなっても許容できる場合は、スケーリンググループをスポットインスタンスのみを使用するように設定できます。この設定では、スポットインスタンスが利用できない場合にトレーニングが一時停止し、在庫が回復すると自動的に再開されるため、コスト削減を最大化できます。スケーリンググループとスポットインスタンスの組み合わせに関する詳細をご参照ください。
コスト比較
以下のコスト比較は参考用です。実際の削減額は、ランタイム条件によって異なる場合があります。
総トレーニング時間が 12 時間、スポットインスタンスの価格が 3.5/時間、従量課金インスタンスの価格が 10/時間であると仮定します。コスト比較は次のとおりです。
モード | スポットインスタンスのみ | ハイブリッド (スポットインスタンスと従量課金) | 従量課金のみ |
説明 | スポットインスタンスが中断および回収されると、トレーニングは一時停止します。容量が回復した後、新しいスポットインスタンスが自動的に起動され、トレーニングが継続されます。 | 合計 12 時間のトレーニング時間のうち、8 時間はスポットインスタンスで、中断により 4 時間は従量課金インスタンスで実行されると仮定します。 | すべてのトレーニングは従量課金インスタンスで実行されます。 |
コスト | 12h * 3.5/h = 42 | 8h * 3.5/h + 4h * 10/h = 68 | 12h * 10/h = 120 |
従量課金のみの場合との比較 | 65% | 43.33% | 0% |
操作手順
基本トレーニング環境を含むカスタムイメージのビルド。
このイメージは、スケーリンググループ内のインスタンスの起動イメージとして機能します。トレーニングを自動的に再開する起動スクリプトが含まれており、新しいインスタンスがタスクを迅速に開始し、手動介入なしで実行できるようにします。
スケーリンググループの作成と設定。
スケーリンググループは、中断後に新しいスポットインスタンスまたは従量課金インスタンスを自動的に作成し、トレーニングタスクの継続を保証します。
トレーニングタスクの開始。
スケーリンググループを有効にすると、スケールアウトイベントがトリガーされ、トレーニングタスクを自動的に開始するインスタンスが作成されます。
中断のシミュレーション (検証)。
インスタンスを手動でリリースして、中断または回収のシナリオをシミュレートします。新しいインスタンスが起動され、トレーニングタスクが自動的に再開されることを確認して、安定性と信頼性を確保します。
1. カスタムトレーニングイメージのビルド
このトピックでは、単一マシン、単一 GPU のセットアップで Swift トレーニングフレームワークを使用して、DeepSeek-R1-Distill-Qwen-7B モデルの自己認識ファインチューニングを実行する方法を説明します。
まず、必要なトレーニング環境と依存関係を持つインスタンスを作成します。次に、このインスタンスからカスタムイメージを作成し、スケーリンググループの起動イメージとして使用することで、起動効率を向上させます。このイメージには、自動トレーニングスクリプトと起動サービスが含まれており、ワークフローを自動化します。このイメージの作成に使用される Elastic Compute Service (ECS) インスタンスのアーキテクチャを次の図に示します。
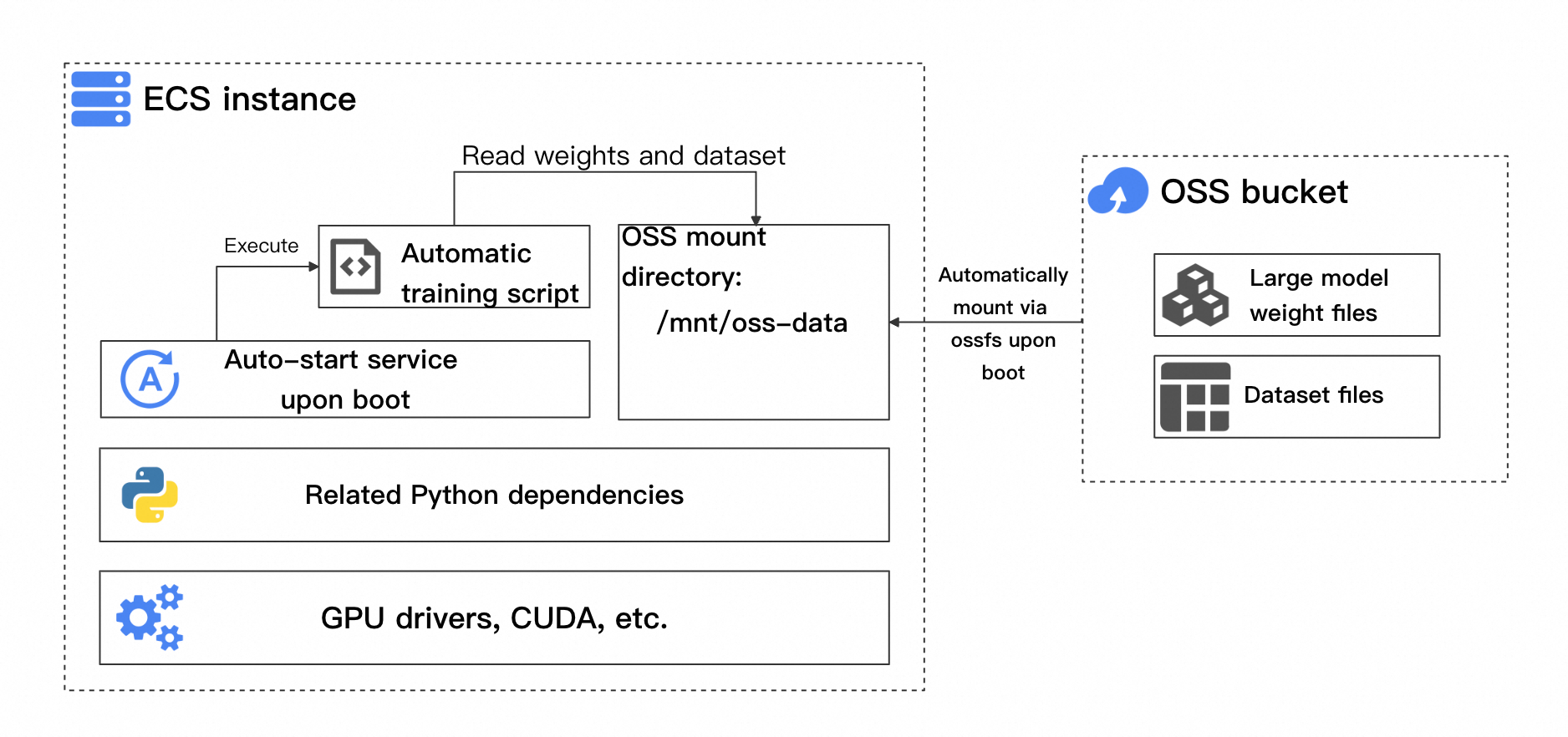
主なコンポーネントは次のとおりです:
基本トレーニング環境の依存関係: GPU ドライバー、CUDA、および関連する Python の依存関係が含まれます。これらはトレーニングフレームワークによって異なります。
自動トレーニングスクリプト: このスクリプトは、最新のチェックポイントから再開するかどうか、およびトレーニングが完了したかどうかを自動的に確認する必要があります。
起動時のバケット自動マウント: トレーニングスクリプトが開始されると、モデルの重み、データセット、および生成されたチェックポイントファイルを OSS バケットから読み取ります。
起動サービス: このサービスは、インスタンスの起動後にトレーニングスクリプトが自動的に実行され、バケットから必要なファイルを読み取ってトレーニングを開始または継続することを保証します。
これらのコンポーネントを理解したら、以下の手順に従ってイメージをビルドします。
1.1 インスタンスの作成と環境の構築
このインスタンスは、カスタムイメージを作成するためのテンプレートとして機能します。後で、スケーリンググループはこのイメージを使用して新しいインスタンスを自動的に作成します。
ECS コンソール に移動して GPU インスタンスを作成します。
まず、従量課金の GPU インスタンスを作成して、ベース環境をセットアップします。このチュートリアルでは、中国 (杭州) リージョンのアベイラビリティーゾーン J にある
ecs.gn7i-c8g1.2xlargeインスタンスを使用します。インスタンスを以下のように設定します。1. チャージタイプ:従量課金。
②:リージョン。中国 (杭州)。
③④: ネットワーク & ゾーン。 VPC と vSwitch を選択します。 これらが存在しない場合は、画面の指示に従って作成できます。
⑤⑥: インスタンスタイプの選択。
ecs.gn7i-c8g1.2xlargeを選択します。⑦⑧⑨: イメージ: Ubuntu 22.04 64 ビット。
⑩: GPU ドライバーの自動インストール。 バージョン: CUDA バージョン 12.4.1、ドライバーバージョン 550.127.08、および CUDNN バージョン 9.2.0.82 を選択します。
⑪: 。 60 GiB。
⑫⑬⑭: パブリック IPv4 アドレスを割り当て、インスタンスがインターネットにアクセスしてモデルファイルをダウンロードできるようにします。帯域幅課金方法 には トラフィック課金 を、ピーク帯域幅 には 100 Mbps を選択します。
⑮⑯⑰: 新しい基本セキュリティグループを作成します。リモート接続を許可するために、少なくとも SSH (TCP: 22) および ICMP (IPv4) ポートを開きます。
⑱⑲⑳: ログインクレデンシャル。インスタンスへのログインに使用する認証情報です。キーペアまたはパスワードを選択できます。画面のプロンプトに従って構成を完了します。
21:インスタンス名。インスタンスを容易に識別および検索できるように、名前を指定します。このトピックでは、
ess-lora-deepseek7b-templateを例として使用します。構成が完了したら、注文の確認 をクリックし、インスタンスが作成されるまでお待ちください。
インスタンスの作成後、インスタンスに接続し、GPU ドライバーのインストールを待ちます。
[ECS コンソール - インスタンス] に移動します。
前のステップで作成したインスタンスを見つけ、操作 列の接続 をクリックします。ワークベンチを使用してインスタンスに接続し、プロンプトに従ってログインします。
インスタンスが見つからない場合、現在のリージョンがインスタンスのリージョンと一致していない可能性があります。左上隅でリージョンを切り替えることができます。
インスタンスが停止している場合は、ページを更新して起動するのを待ちます。
インスタンスに接続した後、GPU ドライバーのインストールが完了するのを待ちます。インストール後、再接続するように求められます。
インターフェイスがフリーズした場合は、ページを更新してインスタンスに再接続してみてください。
Welcome to Alibaba Cloud Elastic Compute Service ! Last login: Tue Mar 18 21:12:39 2025 from xxx % Total % Received % Xferd Average Speed Time Time Current Dload Upload Total Spent Left Speed 100 21 100 21 0 0 875 0 --:--:-- --:--:-- --:--:-- 913 ドライバー xxx をインストールしています。0 分かかります。残りのインストール時間は 11~15 分です! [cuda-12.4.1. インストール中、2~5 分かかります。残りのインストール時間は 9~12 分です!
Python の依存関係をインストールします。
次のコマンドを実行して、トレーニングに必要な依存関係をインストールします。
このチュートリアルで使用されている Ubuntu 22.04 64-bit イメージには、すでに Python 3.10 が含まれているため、別途 Python をインストールする必要はありません。
# Ubuntu 22.04 イメージには Python 3.10 が含まれているため、追加のインストールは不要です。 python3 -m pip install --upgrade pip # Alibaba Cloud 内部の PyPI ミラーに切り替えます。 pip config set global.index-url http://mirrors.cloud.aliyuncs.com/pypi/simple/ pip install modelscope==1.22.3 pip install openai==1.61.0 pip install tqdm==4.67.1 pip install "vllm>=0.5.1" -U pip install "lmdeploy>=0.5,<0.6.5" -U --no-deps pip install autoawq -U --no-deps pip install auto_gptq optimum bitsandbytes -U pip install ms-swift[all] pip install timm -U pip install deepspeed==0.14.* -U pip install qwen_vl_utils decord librosa pyav icecream -U
依存関係のインストールを待っている間に、右上隅のアイコンをクリックして マルチターミナル を開き、ステップ 1.2 を同時に進めることができます。
1.2 OSS バケットの作成とマウント
このステップでは、OSS にバケットを作成し、データディスクとして ECS インスタンスにマウントします。このバケットには、モデルの重みファイル、データセット、およびトレーニング中に生成されるチェックポイントが保存されます。
OSS コンソール に移動してバケットを作成します。
以下は主要な設定パラメーターです。記載されていないパラメーターについては、デフォルト値のままにしてください。
2. バケット名。後でバケットをマウントするときに、このバケット名を使用します。
3. リージョン。 [リージョン固有] を選択します。 リージョンは、ECS インスタンスのリージョンと同じである必要があります。 この例では、リージョンは 中国東部1 (杭州) です。
ECS インスタンスは、同じリージョン内の OSS バケットに内部ネットワーク経由でアクセスでき、トラフィック料金はかかりません。詳細については、「ECS インスタンスから内部ネットワーク経由で OSS リソースにアクセスする」をご参照ください。
RAM ロールの作成とアタッチ。
RAM ロールは、ECS インスタンスがご利用の OSS バケットにアクセスすることを承認します。RAM ロールを作成してアタッチするには、次の手順に従います:
RAM コンソールで、RAM ロールを作成します。 主要な設定パラメーターは以下のとおりです。
Resource Access Management (RAM) コンソールの [ロール] ページに移動し、[ロールの作成] をクリックします。
②: プリンシパルタイプ。 [クラウドサービス] を選択します。
③: プリンシパル名。ECS を選択します。これは、ロールが ECS インスタンスに付与されることを指定します。
④: OK をクリックし、プロンプトに従って RAM ロールの名前を設定します。
RAM コンソールで、次のカスタムポリシーを作成します。
Resource Access Management (RAM) コンソールの [ポリシー] ページに移動し、[ポリシーの作成] をクリックします。
[スクリプトエディター] タブを選択し、次のポリシースクリプトを入力します。
③: このポリシーは、特定のバケットへのフルアクセスを許可します。ポリシースクリプトは次のとおりです。
重要ポリシーを設定する際は、
<bucket_name>をお使いの バケット名 に置き換えてください。{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": "oss:*", "Resource": [ "acs:oss:*:*:<bucket_name>", "acs:oss:*:*:<bucket_name>/*" ] } ] }構成後、OK をクリックし、プロンプトに従ってポリシーの名前を設定します。
RAM コンソールで、RAM ロールに権限を付与します。
⑥: 権限付与の対象。先ほど作成した RAM ロールを選択します。
⑦: 権限付与ポリシー。先ほど作成したカスタムポリシーを選択します。
構成後、Grant permissions をクリックします。
[ECS コンソール] に移動し、RAM ロールをインスタンスにアタッチします。
インスタンスが見つからない場合、現在のリージョンがインスタンスのリージョンと一致していない可能性があります。左上隅でリージョンを切り替えることができます。
ECS コンソールのインスタンスリストで、ターゲットインスタンスを見つけ、[操作] 列からステップ 1.2 で作成した RAM ロールをアタッチします。
バケットを ECS インスタンスにマウントします。
ステップ 1.1 で作成したインスタンスに接続し、次のコマンドを実行して ossfs ツールをインストールします。
wget https://gosspublic.alicdn.com/ossfs/ossfs_1.91.5_ubuntu22.04_amd64.deb apt-get update DEBIAN_FRONTEND=noninteractive apt-get install gdebi-core DEBIAN_FRONTEND=noninteractive gdebi -n ossfs_1.91.5_ubuntu22.04_amd64.deb次のコマンドを実行してマウント操作を完了します。コマンド内の次のプレースホルダーを必ず置き換えてください:
<bucket_name>は、作成したバケットの バケット名 に置き換えます。<ecs_ram_role>: 作成した RAM ロールの名前に置き換えます。<internal_endpoint>:oss-cn-hangzhou-internal.aliyuncs.comに置き換えます。重要このチュートリアルでは、中国東部1 (杭州) リージョン内のバケットを使用するため、VPC 内部エンドポイントは
oss-cn-hangzhou-internal.aliyuncs.comです。
# バケット名、内部エンドポイント、RAM ロールに置き換えます。 BUCKET_NAME="<bucket_name>" ECS_RAM_ROLE="<ecs_ram_role>" INTERNAL_ENDPOINT="<internal_endpoint>" # バケットのマウントパス BUCKET_MOUNT_PATH="/mnt/oss-data" # 1. マウントする前に fstab ファイルをバックアップします。 cp /etc/fstab /etc/fstab.bak # 2. マウントディレクトリを作成します。 mkdir $BUCKET_MOUNT_PATH # 3. バケットをインスタンスにマウントします。 ossfs $BUCKET_NAME $BUCKET_MOUNT_PATH -ourl=$INTERNAL_ENDPOINT -oram_role=http://100.100.100.200/latest/meta-data/ram/security-credentials/$ECS_RAM_ROLE # 4. 起動時の自動マウントを設定します。 echo "ossfs#$BUCKET_NAME $BUCKET_MOUNT_PATH fuse _netdev,url=http://$INTERNAL_ENDPOINT,ram_role=http://100.100.100.200/latest/meta-data/ram/security-credentials/$ECS_RAM_ROLE,allow_other 0 0" | sudo tee -a /etc/fstab
(検証) ストレージスペースが利用可能かテストします。
任意のファイルを OSS バケットにアップロードします。
OSS コンソールで、バケットの [ファイル] ページに移動します。[ファイルのアップロード] をクリックし、テストファイルをアップロードしてマウントを検証します。
インスタンスで次のコマンドを実行し、ディレクトリ内で OSS バケットのファイルが表示されるか確認します。
ls /mnt/oss-data/ファイルが表示されれば、マウントは成功です。
root@ixxx:~# ls /mnt/oss-data/ test.txt
1.3 モデルとデータセットの準備
このチュートリアルで使用するモデルの重みとデータセットは、ModelScope コミュニティからダウンロードされます。インスタンスに接続した後、以下の手順に従ってください。OSS バケットがマウントされているディレクトリにモデルとデータセットをダウンロードし、ダウンロードが完了するのを待ちます。
データセットのダウンロード
# バケットのマウントパス BUCKET_MOUNT_PATH="/mnt/oss-data" # ModelScope コミュニティからファインチューニングデータセットをダウンロード # ステップ 1.1 でインストールした modelscope ツールを使用 modelscope download --dataset swift/self-cognition --local_dir $BUCKET_MOUNT_PATH/self-cognition modelscope download --dataset AI-ModelScope/alpaca-gpt4-data-zh --local_dir $BUCKET_MOUNT_PATH/alpaca-gpt4-data-zh modelscope download --dataset AI-ModelScope/alpaca-gpt4-data-en --local_dir $BUCKET_MOUNT_PATH/alpaca-gpt4-data-enダウンロードの進行が止まった場合は、Enter キーを数回押してください。
モデルの重みのダウンロード
重要モデルの重みファイルはサイズが大きいです。ダウンロードに失敗した場合や、
please try againというメッセージが表示された場合は、コマンドを再試行してダウンロードを再開してください。# バケットのマウントパス BUCKET_MOUNT_PATH="/mnt/oss-data" # ModelScope コミュニティから DeepSeek-R1-Distill-Qwen-7B モデルをダウンロード modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir $BUCKET_MOUNT_PATH/DeepSeek-R1-Distill-Qwen-7Bダウンロードの進行が止まった場合は、Enter キーを数回押してください。
モデルの重みのテスト
ダウンロードが完了したら、次のコマンドを実行してモデルで推論テストを行い、モデルの重みファイルが完全であることを確認できます。
# バケットのマウントパス BUCKET_MOUNT_PATH="/mnt/oss-data" CUDA_VISIBLE_DEVICES=0 swift infer \ --model $BUCKET_MOUNT_PATH/DeepSeek-R1-Distill-Qwen-7B \ --stream true \ --infer_backend pt \ --max_new_tokens 2048モデルがロードされた後、大規模言語モデルとの対話を開始できます。モデルの重みのロードに失敗した場合は、再度ダウンロードしてください。
[INFO:swift] Start time of running main: 2025-03-26 13:35:50.564493 [INFO:swift] request_config: RequestConfig(max_tokens=2048, temperature=None, top_k=None, top_p=None, repetition_penalty=None, num_beams=1, stop=[], seed=None, stream=True, logprobs=False, top_logprobs=None, n=1, best_of=None, presence_penalty=0.0, frequency_penalty=0.0, length_penalty=1.0) [INFO:swift] Input 'exit' or 'quit' to exit the conversation. [INFO:swift] Input 'multi-line' to switch to multi-line input mode. [INFO:swift] Input 'reset-system' to reset the system and clear the history. [INFO:swift] Input 'clear' to clear the history. <<< 你是谁?テストが完了したら、
exitと入力して対話を終了できます。
1.4 自動トレーニングスクリプトの作成
自動トレーニングスクリプトを作成します。
次のコマンドを実行して、自動トレーニングスクリプトを作成し、実行権限を付与します。このスクリプトは、最新のチェックポイントからトレーニングを自動的に再開し、トレーニングがいつ完了したかを判断します。
# 自動トレーニングスクリプトを作成します。 cat <<EOF > /root/train.sh #!/bin/bash # バケットのマウントパス BUCKET_MOUNT_PATH="/mnt/oss-data" # モデルの重みとデータセットの保存ディレクトリ MODEL_PATH="\$BUCKET_MOUNT_PATH/DeepSeek-R1-Distill-Qwen-7B" DATASET_PATH="\$BUCKET_MOUNT_PATH/alpaca-gpt4-data-zh#500 \$BUCKET_MOUNT_PATH/alpaca-gpt4-data-en#500 \$BUCKET_MOUNT_PATH/self-cognition#500" # 出力ディレクトリを設定 OUTPUT_DIR="\$BUCKET_MOUNT_PATH/output" mkdir -p "\$OUTPUT_DIR" # トレーニングが既に完了しているか確認するロジック if [ -f "\$OUTPUT_DIR/logging.jsonl" ]; then last_line=\$(tail -n 1 "\$OUTPUT_DIR/logging.jsonl") if echo "\$last_line" | grep -q "last_model_checkpoint" && echo "\$last_line" | grep -q "best_model_checkpoint"; then echo "Training already completed. Exiting." exit 0 fi fi # 再開引数を初期化 RESUME_ARG="" # 最新のチェックポイントを検索 LATEST_CHECKPOINT=\$(ls -dt \$OUTPUT_DIR/checkpoint-* 2>/dev/null | head -1) if [ -n "\$LATEST_CHECKPOINT" ]; then RESUME_ARG="--resume_from_checkpoint \$LATEST_CHECKPOINT" echo "Resume training from: \$LATEST_CHECKPOINT" else echo "No checkpoint found. Starting new training." fi # トレーニングコマンドを開始 CUDA_VISIBLE_DEVICES=0 swift sft \\ --model \$MODEL_PATH \\ --train_type lora \\ --dataset \$DATASET_PATH \\ --torch_dtype bfloat16 \\ --num_train_epochs 1 \\ --per_device_train_batch_size 1 \\ --per_device_eval_batch_size 1 \\ --learning_rate 1e-4 \\ --lora_rank 8 \\ --lora_alpha 32 \\ --target_modules all-linear \\ --gradient_accumulation_steps 16 \\ --eval_steps 50 \\ --save_steps 10 \\ --save_total_limit 5 \\ --logging_steps 5 \\ --max_length 2048 \\ --output_dir "\$OUTPUT_DIR" \\ --add_version False \\ --overwrite_output_dir True \\ --system 'You are a helpful assistant.' \\ --warmup_ratio 0.05 \\ --dataloader_num_workers 4 \\ --model_author swift \\ --model_name swift-robot \\ \$RESUME_ARG EOF # 実行権限を付与 chmod +x /root/train.shLinux サービスを作成し、起動時に開始するように設定します。
次のコマンドを実行してサービスを作成し、起動時にトレーニングスクリプトが自動的に開始されるように設定します。
# ログ保存ディレクトリを作成 mkdir -p /root/train-service-log # サービス設定ファイルを書き込む cat <<EOF > /etc/systemd/system/train.service [Unit] Description=Train AI Model Script After=network.target local-fs.target remote-fs.target Requires=local-fs.target remote-fs.target [Service] ExecStart=/root/train.sh WorkingDirectory=/root/ User=root Environment="PATH=/usr/bin:/usr/local/bin" Environment="CUDA_VISIBLE_DEVICES=0" StandardOutput=append:/root/train-service-log/train.log StandardError=append:/root/train-service-log/train_error.log [Install] WantedBy=multi-user.target EOF # systemd 設定をリロード systemctl daemon-reload # train.service を起動時に開始するように設定 systemctl enable train.serviceコマンドが完了すると、次の出力が返されます:
Created symlink /etc/systemd/system/multi-user.target.wants/train.service → /etc/systemd/system/train.service.
1.5 カスタムイメージのビルド
これまでのすべての手順を完了したら、設定済みのインスタンスからカスタムイメージを作成します。このイメージは、スケールアウト時に新しいインスタンスの起動イメージとして機能し、依存関係を再インストールする必要がなくなります。
ECS コンソールの [インスタンス] ページに移動します。
以下に説明するようにイメージを作成します。
ECS コンソールのインスタンスリストで、ターゲットインスタンスを見つけます。[操作] 列で、[その他] > [ディスクとイメージ] > [カスタムイメージの作成] をクリックします。プロンプトに従ってイメージの作成を完了します。
イメージが作成されるのを待ちます。このプロセスには約 5 分かかります。ECS コンソールの [イメージ] ページで作成の進捗状況を確認できます。
イメージが作成された後、ステップ 1.1 で作成したインスタンスを リリース できます。
2. スケーリンググループの作成
インスタンス管理を自動化するためにスケーリンググループを設定します。スケーリンググループは、インスタンスが中断された後、新しいスポットインスタンスまたは従量課金インスタンスが自動的に作成され、トレーニングタスクが継続されることを保証します。スポットインスタンスが利用可能になると、コストを節約するために自動的に従量課金インスタンスを置き換えます。
2.1 スケーリンググループの作成
まず、スケーリンググループを作成する必要があります。次の手順に従ってください。
Auto Scaling コンソール に移動してスケーリンググループを作成します。
重要スケーリンググループが ステップ 1.1 で作成したインスタンスと同じリージョンにあることを確認してください。
スケーリンググループを次のように設定します。 詳細なパラメーターの説明については、「パラメーター」をご参照ください。
次のパラメーターを設定します: [スケーリンググループ名] を ess-lora-deepseek-7b に、[タイプ] を ECS に、[インスタンス設定のソース] を [既存のインスタンス] に設定します。[最小インスタンス数] を 0 に、[最大インスタンス数] を 1 に設定し、[デフォルトのクールダウンタイム] は 300 秒のままにします。
重要`⑤⑥` で VPC と [vSwitch] を選択する際は、複数のアベイラビリティゾーンの vSwitch を選択することをお勧めします。これにより、スケーリンググループがゾーンをまたいでリソースをプロビジョニングできるようになり、スポットインスタンスの作成成功率が高まります。
重要コスト削減を最大化するためにトレーニングにスポットインスタンスのみを使用する場合は、[従量課金インスタンスを使用してスポット容量を補完] と [従量課金インスタンスをスポットインスタンスに置き換える] の両方を無効にする必要があります。
構成後、作成 をクリックします。その後、プロンプトに従ってスケーリング設定を作成できます。
2.2 スケーリング設定の作成
スケーリング設定は、スケーリンググループ内のインスタンスの仕様、イメージ、その他の情報を定義します。設定後、スケーリンググループはこれらの設定に基づいて新しいインスタンスを自動的に作成します。[スケーリング設定の作成] ページで、次の設定を完了します:
1. スケーリング設定名: ②: 課金方法: スポットインスタンス。 |
③ と ④: イメージ。 カスタムイメージ を選択し、ステップ 1.5 で作成したカスタムイメージを選択します。 ⑤: 設定方法。 インスタンスタイプの指定 を選択します。 6. インスタンスの使用期間。最低 1 時間 を選択します。インスタンスが 1 時間実行されると、システムはインスタンスを中断して回収するかどうかの確認を開始します。 [指定された使用期間なし] を選択すると、より低コストでスポットインスタンスを使用できますが、中断される可能性が高くなります。これにより、有効なチェックポイントが作成される前にインスタンスが回収され、トレーニングの進行が遅くなる可能性があります。これら 2 つのオプションの違いの詳細については、「スケーリンググループでスポットインスタンスを使用してコストを削減する」をご参照ください。 ⑦: インスタンスあたりの最高価格。 自動入札 を選択して、市場価格に基づいて自動的に入札します。 8. インスタンスタイプを選択。 ステップ 1.1 でインスタンスの作成時に設定したインスタンスタイプである |
9. セキュリティグループ。 ステップ 1.1でインスタンスを作成したときに設定したセキュリティグループを選択します。 このチュートリアルはオフライントレーニングソリューションであるため、パブリック IP アドレスを割り当てる必要はありません。 |
⑩:ログインクレデンシャル。 事前設定されたパスワードを使用 を選択します。 |
⑪⑫⑬: で、ステップ 1.2 で作成した RAM ロールを選択します。スケーリンググループがインスタンスを自動的に作成すると、この RAM ロールは新しいインスタンスに自動的にアタッチされます。 |
[作成] をクリックすると、スケーリング設定の強度が不十分である旨のプロンプトが表示されることがあります。続行 をクリックします。
スケーリング設定を作成した後、プロンプトに従ってスケーリング設定を有効にし、スケーリンググループを有効にします。
スケーリング設定が正常に作成された後、表示されるダイアログボックスで [設定を有効にする] をクリックします。 | [スケーリング設定の選択] 確認ダイアログボックスで、[OK] をクリックします。 | [スケーリンググループの有効化] 確認ダイアログボックスで、[OK] をクリックしてスケーリンググループを有効にします。 |
3. トレーニングタスクの開始
スケーリンググループが設定された後、予想インスタンス数を 1 に調整します。手順は次のとおりです。
スケーリンググループの詳細ページに移動し、[インスタンススケーリングの概要] を表示します。現在のインスタンス数はすべて 0 です。 | [インスタンススケーリングの概要] セクションの [変更] をクリックします。[予想インスタンス数] スイッチを有効にし、値を 1 に設定して [OK] をクリックします。スケーリンググループは自動的にスポットインスタンスを作成します。 |
その後、スケーリンググループは自動的に新しいインスタンスを作成し、トレーニングタスクを開始します。
スケーリンググループは、グループ内のインスタンス数が予想インスタンス数と一致するかを定期的に確認します。現在の数が 0 であるため、新しいインスタンスを作成するためにスケールアウトが自動的にトリガーされます。
予想インスタンス数を調整した後、インスタンスの作成に遅延が発生する場合があります。進行中のアクティビティは、スケーリングアクティビティ タブで確認できます。
インスタンスが作成されて起動した後、OSS バケットに
outputフォルダが見つかります。このフォルダには、トレーニング中に生成されたチェックポイントファイルが保存されます。
4. 中断のシミュレーション (検証)
インスタンスがトレーニングタスクを開始した後、OSS バケットの output ディレクトリをチェックして、checkpoint-10 のようなフォルダが作成されているか確認します。チェックポイントが生成されたら、トレーニングインスタンスを手動でリリースして中断をシミュレートできます。インスタンスを手動でリリースする手順は次のとおりです:
インスタンスを手動でリリースします。
まず、スケーリンググループの インスタンス タブに移動し、[インスタンス ID] をクリックして、対応する [インスタンスの詳細] ページに移動します。
「インスタンス詳細」ページで、右上隅にあるをクリックし、プロンプトに従ってインスタンスをリリースします。
トレーニングが最新のチェックポイントから再開されるか確認します。
スケーリンググループが新しいインスタンスを作成するのを待ちます。インスタンスが作成されたら、それに接続してタスクログを表示します。
スケーリンググループのインスタンス タブに移動し、[インスタンス ID] をクリックして、対応する [インスタンスの詳細] ページに移動します。
右上隅の 接続 をクリックし、プロンプトに従ってインスタンスに接続します。
次のコマンドを実行して、モデルトレーニングログを表示します。このログ出力パスは、ステップ 1.4 で起動サービス用に設定されました。
cat /root/train-service-log/train.logご覧のとおり、トレーニングタスクは最新のチェックポイントから再開されます。
root@ixxx:~# cat train-service-log/train.log Resume training from: /mnt/oss-data/output/checkpoint-10 run sh: /usr/bin/python3 /usr/local/lib/python3.10/dist-packages/xxx s-data/self-cognition#500 --torch_dtype bfloat16 --num_train_epochs xxx --eval_steps 50 --save_steps 10 --save_total_limit 5 --logging_steps xxx --num_workers 4 --model_author swift --model_name swift-robot --resume xxx
次のステップ
ファインチューニング済みモデルを推論に使用する
リソースのリリース
本番環境向けの推奨事項
このソリューションを本番環境で使用する前に、ビジネスニーズと以下の推奨事項に基づいて調整してください。
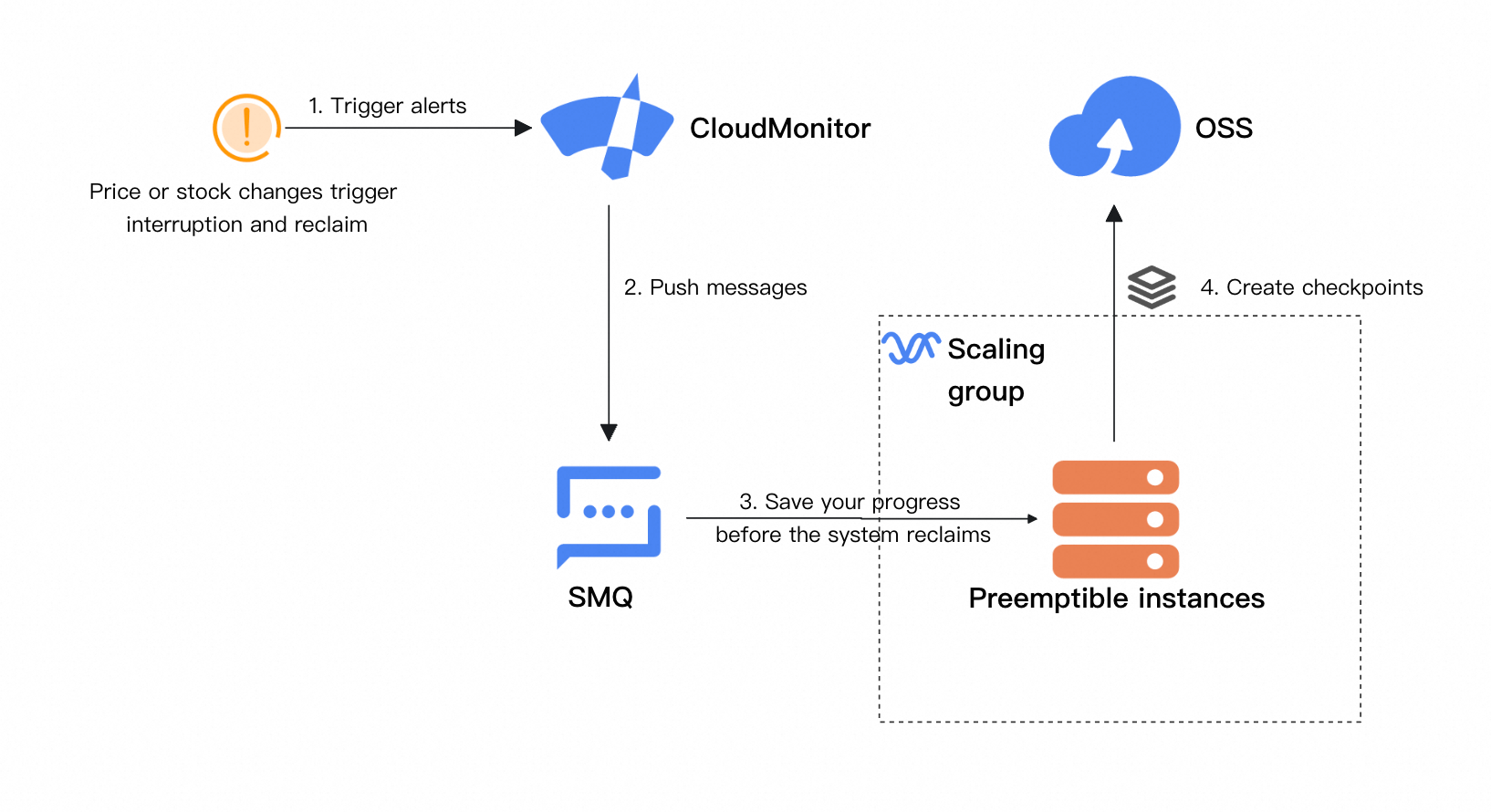
中断処理のための CloudMonitor の統合
このソリューションを本番環境で適用する場合、トレーニングコードに CloudMonitor を統合して、スポットインスタンスの中断イベントを検出して対応することを推奨します。中断の 5 分前にチェックポイントを保存することで、トレーニング再開時の進捗の損失を減らすことができます。改善されたアーキテクチャは次のとおりです:
タスク回復メカニズムの確立
このチュートリアルの例では、トレーニングは有効性を確認せずに最新のチェックポイントから自動的に再開されます。本番アプリケーションでは、異常検知メカニズムを実装して無効なチェックポイントを除外し、最新の有効なチェックポイントから自動的にトレーニングを再開することを推奨します。
タスク完了プロセスの改善
タスクがいつ完了したかを判断するためのロジックをトレーニングコードに追加できます。完了時に、CLI または SDK を使用してスケーリンググループの API を呼び出し、予想インスタンス数を 0 に変更します。その後、スケーリンググループは余分なインスタンスを自動的にリリースし、不要なコストを回避します。
さらに、タスクが完了したときに、CloudMonitor にカスタムイベントを報告できます。これにより、メール、SMS、または DingTalk チャットボットでトレーニング結果に関する通知を受け取ることができます。
高性能ファイルシステムの使用
多数のパラメーターを持つモデルをトレーニングする場合、OSS がシステムのボトルネックになる可能性があります。パフォーマンスを向上させるために、マウントされたファイルシステムとして CPFS のような高スループット、低レイテンシーのファイルシステムを使用することを推奨します。
可用性を高めるためのマルチ AZ vSwitch の設定
単一のアベイラビリティゾーンにのみ vSwitch を設定した場合、スケーリンググループはそのゾーンでのみインスタンスを作成できるため、容量不足によるスケールアウトの失敗につながりやすくなります。複数のアベイラビリティゾーンに vSwitch を設定することを推奨します。スポットインスタンスが回収されると、システムは自動的に他のゾーンで新しいインスタンスを作成しようとし、スポットインスタンスの可用性を高めます。