MySQL データソースを使用すると、MySQL からのデータの読み取りと MySQL へのデータの書き込みが可能になります。このトピックでは、DataWorks データ統合の MySQL データ同期機能について説明します。
サポートされている MySQL のバージョン
バッチ同期
MySQL 5.5.x、5.6.x、5.7.x、および 8.0.x をサポートし、Amazon RDS for MySQL、Azure Database for MySQL、および Amazon Aurora MySQL と連携します。
ビューからのデータ読み取りをサポートします。
リアルタイム同期
データ統合は、リアルタイムサブスクリプションを使用して、MySQL 5.5.x、5.6.x、5.7.x、および 8.0.x のリアルタイム同期をサポートします。また、Amazon RDS for MySQL、Azure Database for MySQL、および Amazon Aurora MySQL とも連携します。ただし、関数インデックスなど、MySQL 8.0.x で導入された機能はサポートしていません。
重要DRDS データベースからデータを同期する必要がある場合は、MySQL データソースとして設定しないでください。代わりに、DRDS データソースとして直接設定してください。手順については、「DRDS データソースの設定」をご参照ください。
制限事項
リアルタイム同期
バージョン 5.6.x より前の MySQL 読み取り専用インスタンスからのデータ同期はサポートされていません。
関数インデックスを含むテーブルの同期はサポートされていません。
XA ROLLBACK はサポートされていません。
リアルタイム同期は、XA PREPARE 状態のデータを送信先に書き込みますが、XA ROLLBACK が発生した場合、準備されたデータはロールバックされません。このシナリオに対処するには、影響を受けるテーブルをリアルタイム同期タスクから手動で削除し、再度追加して同期を再開する必要があります。
MySQL サーバーのバイナリログ (binlog) の設定では、ROW フォーマットを使用する必要があります。
リアルタイム同期では、カスケード削除操作によって削除された関連テーブルのレコードは同期されません。
Amazon Aurora MySQL データベースの場合、AWS は Aurora MySQL 読み取り専用レプリカで binlog を有効にすることを許可していないため、プライマリ/ライターデータベースに接続する必要があります。リアルタイム同期タスクでは、増分更新を実行するために binlog が必要です。
オンライン DDL 変更の場合、リアルタイム同期は、Data Management (DMS) を使用して MySQL テーブルに列を追加 (Add Column) することにのみ対応しています。
MySQL からのストアドプロシージャの読み取りはサポートされていません。
オフライン同期
MySQL Reader プラグインを使用して複数のテーブルを同期する場合 (たとえば、データベースシャーディングのシナリオ)、同時実行タスクの数がテーブルの数を超えた場合にのみ、システムはテーブルを分割して並列処理を行います。それ以外の場合、システムはテーブルごとに 1 つのタスクを作成します。
MySQL からのストアドプロシージャの読み取りはサポートされていません。
サポートされているデータ型
すべての MySQL バージョンのデータ型の完全なリストについては、MySQL の公式ドキュメントをご参照ください。次の表は、MySQL 8.0.x を例として、主要なデータ型のサポート状況を示しています。
型 | オフライン読み取り | オフライン書き込み | リアルタイム読み取り | リアルタイム書き込み |
TINYINT | ||||
SMALLINT | ||||
INTEGER | ||||
BIGINT | ||||
FLOAT | ||||
DOUBLE | ||||
DECIMAL/NUMERIC | ||||
REAL | ||||
VARCHAR | ||||
JSON | ||||
TEXT | ||||
MEDIUMTEXT | ||||
LONGTEXT | ||||
VARBINARY | ||||
BINARY | ||||
TINYBLOB | ||||
MEDIUMBLOB | ||||
LONGBLOB | ||||
ENUM | ||||
SET | ||||
BOOLEAN | ||||
BIT | ||||
DATE | ||||
DATETIME | ||||
TIMESTAMP | ||||
TIME | ||||
YEAR | ||||
LINESTRING | ||||
POLYGON | ||||
MULTIPOINT | ||||
MULTILINESTRING | ||||
MULTIPOLYGON | ||||
GEOMETRYCOLLECTION |
前提条件
DataWorks で MySQL データソースを追加する前に、このトピックの説明に従って MySQL 環境を準備し、同期タスクが正しく実行されるようにしてください。
MySQL バージョンの確認
データ統合は特定の MySQL バージョンをサポートしています。詳細については、「サポートされている MySQL のバージョン」セクションを参照して、ご利用のバージョンがサポートされていることを確認してください。次のステートメントを実行して、MySQL データベースのバージョンを確認します。
SELECT version();アカウント権限の設定
DataWorks がデータソースにアクセスするために、専用の MySQL アカウントを作成することを推奨します。
任意:アカウントの作成
詳細については、「MySQL アカウントの作成」をご参照ください。
権限の設定
バッチ同期
MySQL からデータを読み取るには、アカウントに同期対象テーブルに対する
SELECT権限が必要です。MySQL にデータを書き込むには、アカウントに同期対象テーブルに対する
INSERT、DELETE、およびUPDATE権限が必要です。
リアルタイム同期
アカウントには、データベースに対する
SELECT、REPLICATION SLAVE、およびREPLICATION CLIENT権限が必要です。
次のコマンドを実行して、必要な権限を付与します。または、アカウントに
SUPER権限を付与することもできます。次のステートメントでは、'sync_account'をご利用の同期アカウントに置き換えてください。-- CREATE USER 'sync_account'@'%' IDENTIFIED BY ''; // 同期アカウントを作成し、パスワードを設定して、任意のホストからのログインを許可します。'%' ワイルドカードは任意のホストを表します。 GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'sync_account'@'%'; // 同期アカウントに SELECT、REPLICATION SLAVE、REPLICATION CLIENT 権限を付与します。*.*構文は、すべてのデータベースにあるすべてのテーブルに、指定された権限を付与します。testデータベースのuserテーブルなど、特定のテーブルに権限を付与するには、次の文を実行します:GRANT SELECT, REPLICATION CLIENT ON test.user TO 'sync_account'@'%';。説明REPLICATION SLAVE権限はグローバル権限であり、特定のデータベースやテーブルに付与することはできません。
MySQL Binlog の有効化 (リアルタイム同期のみ)
データ統合は、MySQL Binlog をサブスクライブすることで、増分データをリアルタイムで同期します。リアルタイム同期タスクを設定する前に、Binlog サービスを有効にする必要があります。
データベースは、Binlog ファイルがアクティブに使用されている間は削除できません。リアルタイム同期タスクで高いレイテンシーが発生した場合、ソースの Binlog が長期間保持され、大量のディスク領域を消費する可能性があります。タスクにレイテンシーアラートを設定し、データベースのディスク領域を監視することを推奨します。
Binlog ファイルは少なくとも 72 時間保持してください。これにより、タスクが失敗し、必要な Binlog ファイルが消去されたために障害点から再開できない場合のデータ損失を防ぎます。このような場合、完全バッチ同期タスクを使用して、欠落したデータをバックフィルする必要があります。
Binlog が有効になっているか確認します。
次のステートメントを実行して、Binlog が有効になっているか確認します。
SHOW variables LIKE "log_bin";戻り値が
ONの場合、Binlog が有効であることを示します。データ同期にスタンバイデータベースを使用している場合は、次のステートメントを実行して Binlog が有効になっているか確認します。
SHOW variables LIKE "log_slave_updates";戻り値が
ONの場合、スタンバイデータベースで Binlog が有効であることを示します。
返された結果が上記の結果と一致しない場合:
セルフマネージド MySQL の場合は、「MySQL 公式ドキュメント」を参照して Binlog を有効にしてください。
RDS for MySQL の場合は、「RDS for MySQL のログバックアップ」を参照して Binlog を有効にしてください。
PolarDB for MySQL の場合は、「Binlog の有効化」を参照して Binlog を有効にしてください。
Binlog のフォーマットを確認します。
次のステートメントを実行して、Binlog のフォーマットを確認します。
SHOW variables LIKE "binlog_format";戻り値は次のいずれかになります:
ROW:Binlog のフォーマットは
ROWです。STATEMENT:Binlog のフォーマットは
STATEMENTです。MIXED:Binlog のフォーマットは
MIXEDです。
重要DataWorks のリアルタイム同期は、ROW Binlog フォーマットの MySQL サーバーのみをサポートします。戻り値が ROW でない場合は、Binlog のフォーマットを変更する必要があります。
Binlog の完全行ロギングが有効になっているか確認します。
次のステートメントを実行して、Binlog の完全行ロギングが有効になっているか確認します。
SHOW variables LIKE "binlog_row_image";戻り値は次のいずれかになります:
FULL:Binlog の完全行ロギングが有効になっています。
MINIMAL:最小行ロギングが有効で、完全行ロギングは有効になっていません。
重要DataWorks のリアルタイム同期は、Binlog の完全行ロギングが有効になっている MySQL サーバーのみをサポートします。戻り値が FULL でない場合は、binlog_row_image の設定を変更する必要があります。
OSS Binlog アクセスの権限付与
MySQL データソースを追加する際、設定モード が ApsaraDB for RDS に設定されており、RDS for MySQL インスタンスと DataWorks ワークスペースが同じリージョンにある場合、[OSS Binlog 読み取りを有効にする] を有効にできます。このオプションが有効な場合、データ統合は RDS Binlog にアクセスできないときに OSS から Binlog を読み取ろうとします。これにより、リアルタイム同期タスクの中断を防ぐことができます。
[OSS Binlog アクセス ID] を Alibaba Cloud RAM User または Alibaba Cloud RAM Role に設定した場合は、次のセクションで説明するように権限付与も設定する必要があります。
RAM ユーザー
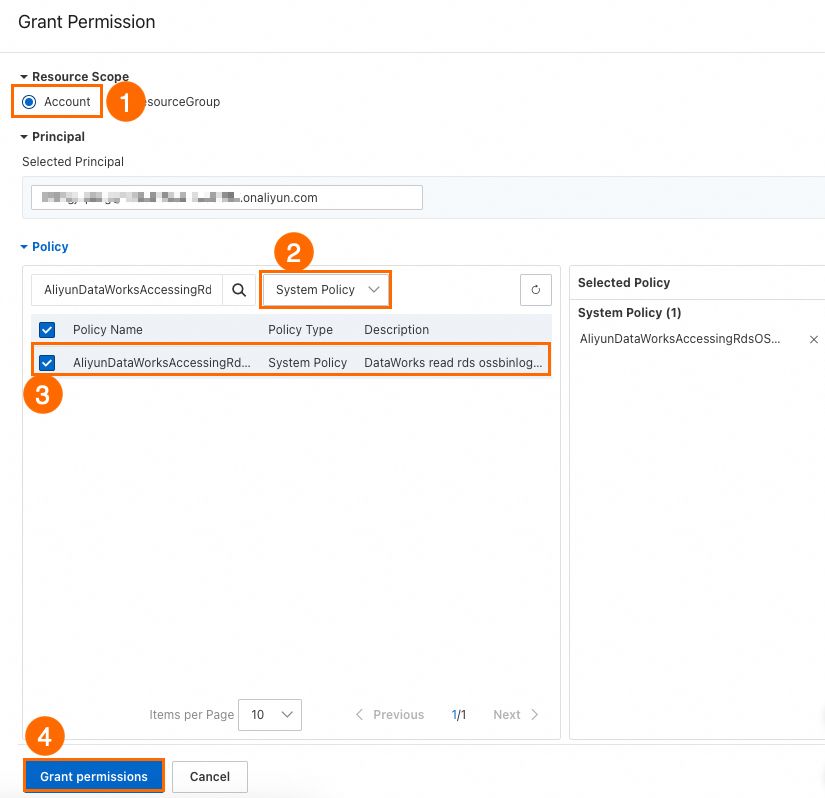
Resource Access Management コンソールにログインし、[ユーザー] ページに移動します。次に、権限を付与する RAM ユーザーを見つけます。
Operations 列で、[権限の追加] をクリックします。
次のパラメーターを設定し、[OK] をクリックします。
[スコープ]:Alibaba Cloud アカウント。
Permission Policy:システムポリシー。
Policy Name:
AliyunDataWorksAccessingRdsOSSBinlogPolicy。
RAM ロール
Resource Access Management コンソールにログインし、RAM ロールを作成します。詳細については、「信頼できる Alibaba Cloud アカウントの RAM ロールを作成する」をご参照ください。
主要なパラメーター:
[信頼できるエンティティの選択]:Alibaba Cloud アカウント。
[アカウントの選択]:他の Alibaba Cloud アカウント。DataWorks ワークスペースを所有する Alibaba Cloud アカウントの ID を入力します。
ロール名:カスタム名を入力します。
RAM ロールに権限を付与します。詳細については、「RAM ロールに権限を付与する」をご参照ください。
主要なパラメーター:
Permission Policy:システムポリシー。
Policy Name:
AliyunDataWorksAccessingRdsOSSBinlogPolicy。
RAM ロールの信頼ポリシーを変更します。詳細については、「RAM ロールの信頼ポリシーを変更する」をご参照ください。
{ "Statement": [ { "Action": "sts:AssumeRole", "Effect": "Allow", "Principal": { "Service": [ "@di.dataworks.aliyuncs.com",
データソースの追加
Alibaba Cloud インスタンスモード
MySQL データベースが Alibaba Cloud RDS インスタンスで実行されている場合は、Alibaba Cloud インスタンスモードでデータソースを作成することを推奨します。次の表にパラメーターを示します。
パラメーター | 説明 |
Data Source Name | データソース名は、ワークスペース内で一意である必要があります。ビジネスと環境を明確に識別できる名前を使用することを推奨します。例: |
設定モード | Alibaba Cloud インスタンスモードを選択します。設定モードの説明については、「シナリオ 1:インスタンスモード (現在のクラウドアカウント)」および「シナリオ 2:インスタンスモード (他のクラウドアカウント)」をご参照ください。 |
Alibaba Cloud Account | インスタンスを所有するクラウドアカウントを選択します。 Another Alibaba Cloud Account を選択した場合は、クロスアカウント権限を設定する必要があります。 詳細については、「クロスアカウント権限付与 (RDS、Hive、または Kafka)」をご参照ください。 他のクラウドアカウントを選択した場合は、次の情報を提供する必要があります:
|
Region | インスタンスが配置されているリージョン。 |
Instance | 接続するインスタンスを選択します。 |
Standby library settings | このデータソースに 読み取り専用インスタンス (スタンバイデータベース) がある場合、そこから読み取るようにジョブを設定できます。これにより、プライマリデータベースへのパフォーマンスへの影響を軽減できます。 |
Instance Address | 正しいインスタンスを選択した後、[最新のエンドポイントを取得] をクリックして、インスタンスのパブリックネットワークまたはプライベートネットワークのエンドポイント、VPC、および vSwitch 情報を表示します。 |
Database | データソースがアクセスするデータベースの名前。指定されたユーザーがこのデータベースにアクセスする権限を持っていることを確認してください。 |
[ユーザー名/パスワード] | MySQL データベースのユーザー名とパスワード。RDS インスタンスを使用する場合、インスタンスの [アカウント管理] セクションでこれらの認証情報を作成および管理できます。 |
[OSS binlog 読み取りをサポート] | このオプションが有効な場合、DataWorks は RDS binlog にアクセスできないときに OSS から binlog を読み取ろうとします。これにより、リアルタイム同期ジョブの中断を防ぎます。詳細については、「OSS からの binlog 読み取り権限の設定」をご参照ください。また、権限付与の設定に基づいて [OSS binlog アクセス ID] を設定する必要があります。 |
Authentication Method | [認証なし] または [SSL 認証] を選択します。[SSL 認証] を選択した場合は、インスタンスで SSL 認証を有効にし、証明書ファイルを Authentication File Management にアップロードします。 |
Version | MySQL サーバーにログインし、 |
接続文字列モード
より柔軟性のある接続文字列モードでデータソースを作成することもできます。このモードのパラメーターを次の表に示します。
パラメーター | 説明 |
Data Source Name | データソース名は、ワークスペース内で一意である必要があります。ビジネスと環境を明確に識別できる名前を使用することを推奨します。例: |
設定モード | User-created Data Store with Public IP Addresses を選択します。このモードでは、DataWorks は JDBC URL を使用してデータベースに接続します。 |
[接続文字列プレビュー] | 接続エンドポイントとデータベース名を入力すると、DataWorks は対応する JDBC URL を自動的に生成します。 |
Connection Address | ホスト:データベースサーバーの IP アドレスまたはドメイン名を入力します。データベースが Alibaba Cloud RDS インスタンスの場合、インスタンスの詳細の [データベース接続] ページでエンドポイントを見つけることができます。 ポート:データベースのポート番号。デフォルトは 3306 です。 |
Database Name | データソースがアクセスするデータベースの名前。指定されたユーザーがこのデータベースにアクセスする権限を持っていることを確認してください。 |
[ユーザー名/パスワード] | MySQL データベースのユーザー名とパスワード。RDS インスタンスを使用する場合、インスタンスの [アカウント管理] セクションでこれらの認証情報を作成および管理できます。 |
Version | MySQL サーバーにログインし、 |
Authentication Method | [認証なし] または [SSL 認証] を選択します。[SSL 認証] を選択した場合は、インスタンスで SSL 認証を有効にし、証明書ファイルを Authentication File Management にアップロードします。 |
Advanced Parameters | パラメーター:パラメーターのドロップダウンリストをクリックし、 値:選択したパラメーターの値を入力します。例:3000。 URL は自動的に次のように組み立てられます: |
データソースがネットワーク経由でリソースグループに到達できることを確認してください。そうでない場合、後続のジョブは失敗します。データソースのネットワーク環境と選択した接続モードに基づいてネットワーク接続を設定してください。詳細については、「接続性のテスト」をご参照ください。
MySQL データ同期タスク
同期タスクの設定のエントリポイントと手順については、以下の設定ガイドをご参照ください。
単一テーブルのオフライン同期
詳細な手順については、「ウィザードモードでのタスクの設定」および「スクリプトモードでのタスクの設定」をご参照ください。
すべてのパラメーターとスクリプトのデモについては、「付録:MySQL スクリプトのデモとパラメーターの説明」をご参照ください。
単一テーブルのリアルタイム同期
詳細な手順については、「リアルタイム同期タスクの設定 (レガシー)」をご参照ください。
データベース全体の同期
詳細な手順については、「データベース全体のリアルタイム同期タスクの設定」をご参照ください。
よくある質問
その他の一般的な問題については、「データ統合のよくある質問」をご参照ください。
付録:MySQL スクリプトのデモとパラメーター
コードエディタを使用したバッチ同期タスクの設定
コードエディタを使用してバッチ同期タスクを設定する場合、統一されたスクリプト形式の要件に基づいて、スクリプト内の関連パラメーターを設定する必要があります。詳細については、「コードエディタの使用」をご参照ください。以下の情報は、コードエディタを使用してバッチ同期タスクを設定する際に、データソースに対して設定する必要があるパラメーターについて説明しています。
Reader スクリプトのデモ
このトピックでは、1 つのデータベース内の単一テーブルとシャーディングの設定例を示します:
以下の JSON 例のコメントはデモンストレーション用であり、スクリプトを実行する前に削除する必要があります。
単一データベース内の単一テーブル
{ "type": "job", "version": "2.0",//バージョン番号。 "steps": [ { "stepType": "mysql",//プラグイン名。 "parameter": { "column": [//列名。 "id" ], "connection": [ { "querySql": [ "select a,b from join1 c join join2 d on c.id = d.id;" ], "datasource": ""//データソース名。 } ], "where": "",//フィルター条件。 "splitPk": "",//シャードキー。 "encoding": "UTF-8"//エンコーディング形式。 }, "name": "Reader", "category": "reader" }, { "stepType": "stream", "parameter": {}, "name": "Writer", "category": "writer" } ], "setting": { "errorLimit": { "record": "0"//エラーレコード数。 }, "speed": { "throttle": true,//throttle が false に設定されている場合、mbps パラメーターは効果がなく、速度制限は無効になります。throttle が true に設定されている場合、速度制限は有効になります。 "concurrent": 1,//ジョブの同時実行数。 "mbps": "12"//速度制限レート。1 mbps = 1 MB/s。 } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }シャーディング
説明MySQL Reader はシャーディングをサポートしており、異なるデータソースにまたがる同じスキーマを持つ複数のテーブルからデータを読み取り、単一の送信先テーブルに書き込むことができます。データベース全体のシャーディングを設定するには、データ統合でタスクを作成し、全データベースシャーディング機能を選択する必要があります。
{ "type": "job", "version": "2.0", "steps": [ { "stepType": "mysql", "parameter": { "indexes": [ { "type": "unique", "column": [ "id" ] } ], "envType": 0, "useSpecialSecret": false, "column": [ "id", "buyer_name", "seller_name", "item_id", "city", "zone" ], "tableComment": "テスト注文テーブル", "connection": [ { "datasource": "rds_dataservice", "table": [ "rds_table" ] }, { "datasource": "rds_workshop_log", "table": [ "rds_table" ] } ], "where": "", "splitPk": "id", "encoding": "UTF-8" }, "name": "Reader", "category": "reader" }, { "stepType": "odps", "parameter": {}, "name": "Writer", "category": "writer" }, { "name": "Processor", "stepType": null, "category": "processor", "copies": 1, "parameter": { "nodes": [], "edges": [], "groups": [], "version": "2.0" } } ], "setting": { "executeMode": null, "errorLimit": { "record": "" }, "speed": { "concurrent": 2, "throttle": false } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }
Reader スクリプトのパラメーター
パラメーター | 説明 | 必須 | デフォルト |
datasource | データソースの名前。この名前は、スクリプトモードで追加したデータソースの名前と一致する必要があります。 | はい | なし |
table | データの読み取り元となるテーブルの名前。1 つのデータ統合タスクで読み取れるのは、1 つの論理テーブルのみです。
説明 タスクは、 | はい | なし |
column | テーブルから同期する列を JSON 配列として指定します。すべての列を選択するには、
| はい | なし |
splitPk | MySQL Reader がデータを抽出する際に
| いいえ | なし |
splitFactor | シャーディング係数。このパラメーターはデータシャードの数を制御します。シャードの総数は 説明 1 から 100 の値を使用することを推奨します。値が大きすぎると、メモリ不足 (OOM) エラーが発生する可能性があります。 | いいえ | 5 |
where | フィルター条件。多くのビジネスシナリオでは、
| いいえ | なし |
querySql (詳細モード;このパラメーターはコードレス UI ではサポートされていません) | 一部のシナリオでは、 説明
| いいえ | なし |
useSpecialSecret | 複数のソースデータソースが設定されている場合に、各データソースの個別のパスワードを使用するかどうかを指定します。有効な値:
異なる認証情報を持つ複数のソースデータソースを設定している場合は、このパラメーターを true に設定して、各個別のデータソースの認証情報を使用します。 | いいえ | false |
Writer スクリプトのデモ
{
"type": "job",
"version": "2.0",//バージョン番号。
"steps": [
{
"stepType": "stream",
"parameter": {},
"name": "Reader",
"category": "reader"
},
{
"stepType": "mysql",//プラグイン名。
"parameter": {
"postSql": [],//実行後 SQL ステートメント。
"datasource": "",//データソース。
"column": [//列名。
"id",
"value"
],
"writeMode": "insert",//書き込みモード。insert、replace、または update に設定できます。
"batchSize": 1024,//バッチサイズ。
"table": "",//テーブル名。
"nullMode": "skipNull",//NULL 値の処理ポリシー。
"skipNullColumn": [//NULL 値がスキップされる列。
"id",
"value"
],
"preSql": [
"delete from XXX;"//実行前 SQL ステートメント。
]
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {//エラーレコード数。
"record": "0"
},
"speed": {
"throttle": true,//throttle が false に設定されている場合、mbps パラメーターは効果がなく、速度制限は無効になります。throttle が true に設定されている場合、速度制限は有効になります。
"concurrent": 1,//ジョブの同時実行数。
"mbps": "12"//速度制限レート。ソース/送信先データベースへの過剰な読み取り/書き込み圧力を防ぐために、最大同期速度を制御します。1 mbps = 1 MB/s。
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}Writer スクリプトのパラメーター
パラメーター | 説明 | 必須 | デフォルト |
datasource | データソースの名前。この名前は、スクリプトモードで追加したデータソースの名前と一致する必要があります。 | はい | なし |
table | データが書き込まれる送信先テーブルの名前。 | はい | なし |
writeMode | 書き込みモード。このパラメーターは
| いいえ | insert |
nullMode | NULL 値の処理ポリシー。有効な値:
重要 skipNull を設定すると、タスクは送信先のデフォルト値をサポートするために SQL ステートメントを動的に生成します。これにより、FLUSH 操作の数が増加し、同期速度が低下します。最悪の場合、各行に対して FLUSH 操作が実行されます。 | いいえ | writeNull |
skipNullColumn | nullMode が skipNull に設定されている場合、このパラメーターは、 フォーマット: | いいえ | タスクに設定されたすべての列。 |
column | 書き込む送信先列を、フィールドのカンマ区切りリストとして指定します。例: | はい | なし |
preSql | データ同期タスクが開始される前に実行される 1 つ以上の実行前 SQL ステートメント。コードレス UI は単一のステートメントのみをサポートしますが、スクリプトモードは複数をサポートします。たとえば、実行前に 説明 複数の SQL ステートメントにまたがるトランザクションはサポートされていません。 | いいえ | なし |
postSql | データ同期タスクが完了した後に実行される 1 つ以上の実行後 SQL ステートメント。コードレス UI は単一のステートメントのみをサポートしますが、スクリプトモードは複数をサポートします。たとえば、 説明 複数の SQL ステートメントにまたがるトランザクションはサポートされていません。 | いいえ | なし |
batchSize | 1 回のバッチでコミットするレコード数。バッチサイズを大きくすると、MySQL とのネットワークインタラクションが減少し、スループットが向上する可能性があります。ただし、値を高く設定しすぎると、メモリ不足 (OOM) エラーが発生する可能性があります。 | いいえ | 256 |
updateColumn |
| いいえ | なし |