このトピックでは、バッチ同期に関する一般的な質問について説明します。
概要
キーワードを照合することで、一般的な問題とその解決策を見つけることができます。
ネットワーク接続の問題
タスク接続の失敗
タスクの断続的な失敗
リソース設定の問題
[TASK_MAX_SLOT_EXCEED]:Unable to find a gateway that meets resource requirements. 20 slots are requested, but the maximum is 16 slots.
OutOfMemoryError: Java heap space
インスタンスの同時実行の競合
バッチタスクエラー:Duplicate entry 'xxx' for key 'uk_uk_op'
タイムアウトエラー
MongoDB ソースのタイムアウトエラー
MySQL をデータソースとして使用するバッチ同期タスクが接続タイムアウトエラーを報告します:Communications link failure
長時間実行タスク
インデックス未設定の WHERE 句
リソースグループの切り替え
バッチ同期用のリソースグループ
ダーティデータ
ダーティデータのトラブルシューティング
ダーティデータの表示
ダーティデータに関する情報を見つけるには、ログ詳細ページに移動し、[Detail log url] の横にあるリンクをクリックしてバッチ同期ログを表示します。
上限を超えた場合のデータ保持
エンコーディングと文字化け
デフォルト値の保持
デフォルト値とプロパティ
シャードキー
複合主キー
データ損失
データ不整合
SSRF 攻撃
Task have SSRF attacks
日付と時刻データの書き込み
カスタム日付形式
同期タスクをスクリプトモードに切り替え、タスク設定ページの common キーの下に次の設定を追加します。
"common": {
"column": {
"dateFormat": "yyyyMMdd",
"datetimeFormatInNanos": "yyyyMMdd HH:mm:ss.SSS"
}
}
パラメーター:
dateFormat:時、分、秒を含まないソースDATE値のテキスト形式を指定します。datetimeFormatInNanos:ソースDATETIMEまたはTIMESTAMP値のテキスト形式を指定します。この形式はミリ秒の精度をサポートします。
MaxCompute
ソースフィールドマッピング
パーティションキー列の同期
フィールドマッピングリストのソースフィールド列で、Add または Create Field をクリックします。パーティションキー列の名前 (例: pt) を入力し、送信先フィールドにマップします。

複数のパーティションからのデータ同期
列のフィルタリング、並べ替え、パディング
列設定エラー
パーティション設定
タスクの再実行とフェイルオーバー
読み取りエラー:The download session is expired.
書き込みエラー:Error writing request body to server
MySQL
シャーディングされたテーブルの同期
文字化けの修正
読み取り/書き込みエラー:Application was streaming results when the connection failed. Consider raising value of 'net_write_timeout/net_read_timeout' on the server.
原因:
net_read_timeout:Data Integration が ApsaraDB RDS for MySQL からデータを読み取る際、シャードキー (splitPk) に基づいてクエリを複数のSELECTステートメントに分割します。これらのステートメントのいずれかの実行時間が ApsaraDB RDS インスタンスで許可されている最大実行時間を超えると、このエラーが発生します。net_write_timeout:このエラーは、クライアントへのデータブロックの送信時間が設定されたタイムアウトを超えた場合に発生します。
解決策:
データソースの JDBC URL にパラメーターを追加するか、ApsaraDB RDS コンソールで変更できます。
推奨事項:
タスクが安全に再実行できる場合は、タスクの自動再実行を有効にします。
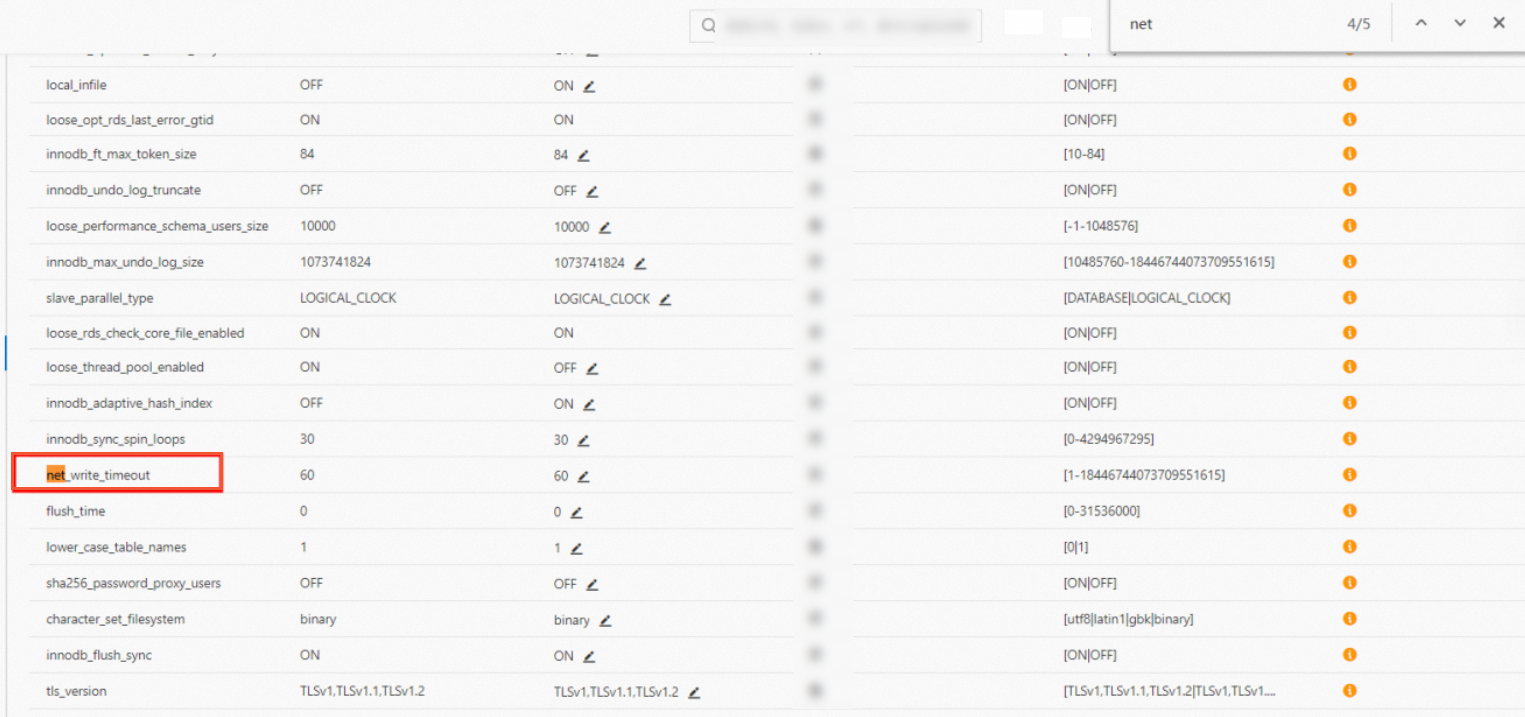
例:jdbc:mysql://192.168.1.1:3306/lizi?useUnicode=true&characterEncoding=UTF8&net_write_timeout=72000
MySQL へのバッチ同期中のエラー:[DBUtilErrorCode-05]ErrorMessage: Code:[DBUtilErrorCode-05]Description:[Failed to write data to the destination table that you configured.]. - com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: No operations allowed after connection closed
読み取りエラー:The last packet successfully received from the server was 902,138 milliseconds ago
PostgreSQL
PostgreSQL 読み取りエラー:org.postgresql.util.PSQLException: FATAL: terminating connection due to conflict with recovery
RDS
Host is blocked エラー
MongoDB
root ユーザー使用時のエラー
タイムスタンプによる増分同期
同期後の時刻の不一致
ソースの更新が同期されない
MongoDB Reader の大文字と小文字の区別
MongoDB Reader のタイムアウト設定
読み取りエラー:no master
読み取りエラー:MongoExecutionTimeoutException: operation exceeded time limit
バッチ同期エラー:DataXException: operation exceeded time limit
同期タスクエラー:no such cmd splitVector
考えられる原因:
デフォルトでは、同期タスクはタスクスライシングに
splitVectorコマンドを使用します。ただし、一部のバージョンの MongoDB はsplitVectorコマンドをサポートしていないため、no such cmd splitVectorエラーが発生します。解決策:
同期タスク設定ページで、上部のツールバーにあるスクリプトに変換アイコン
 をクリックしてスクリプトモードに入ります。
をクリックしてスクリプトモードに入ります。MongoDB パラメーター設定で、パラメーターを追加します。
"useSplitVector" : falsesplitVectorの使用を避けるため。
不変の _id フィールド変更エラー
症状:
この問題は、バッチ同期タスクで Write Mode (Overwrite) が Yes に設定され、設定された Business Key が
_idフィールドではない場合に発生します。
考えられる原因:
書き込むデータには、_id が設定済みの Business Key と一致しないエントリ (前の設定例の
my_idなど) が含まれています。解決策:
解決策 1: ソースデータで、Business Key フィールドの値が _id フィールドの値と一致するようにしてください。
解決策 2:タスク設定を変更して、_id フィールドをビジネスキーとして使用します。
Redis
ハッシュモード書き込みエラー:Code:[RedisWriter-04], Description:[Dirty data]. - source column number is in valid!
OSS
CSV の複数文字区切り文字
OSS ファイル制限
ファイル名のランダムな文字列の削除
OSS エラー:AccessDenied
Hive
エラー:Could not get block locations
DataHub
ペイロードサイズ超過による失敗
LogHub
同期後の空のフィールド
同期後のデータ欠落
マッピングにおける予期しないフィールド
読み取られた __time__ の値が設定された時間範囲外である、またはコンソールのレコード数が同じ時間範囲の同期タスクによって読み取られたエントリ数と一致しないのはなぜですか?
同期後の空のフィールド
Lindorm
バルク書き込みデータの置換
Elasticsearch
インデックス内のすべてのフィールドのクエリ
動的インデックス名による同期
インデックス設定で日付ベースのスケジューリング変数を使用できます。これにより、システムは実行日に基づいてインデックス名を動的に生成できます。このプロセスには、日付変数の定義、インデックス変数の設定、タスクのデプロイと実行の 3 つのステップが含まれます。
日付変数の定義:同期タスクのスケジューリング設定で、新しいパラメーターを追加して日付変数を定義します。次の例では、
var1はタスク実行時間 (当日) を表し、var2は業務日 (前日) を表します。
インデックス変数の設定:スクリプトモードに切り替え、Elasticsearch Reader のインデックスを設定します。次の図に示すように、
${variable_name}形式を使用します。
タスクのデプロイと実行:タスクを確認した後、コミットしてオペレーションセンターにデプロイします。その後、スケジュールに基づいて実行するか、データ補填機能を使用して実行できます。
Running with Parameters をクリックしてタスクを実行し、テストします。この操作により、構成内のスケジューリングパラメーターが実際の値に置き換えられます。タスクの実行後、ログを確認して、正しいインデックスが使用されたことを確認します。
説明[パラメーター付きで実行] を使用する場合は、パラメーター値を直接入力してテストします。


テスト結果が期待どおりの場合、タスク構成は完了です。SaveとCommitを順にクリックして、同期タスクを本番環境にコミットします。

プロジェクトが標準モードの場合、Deploy をクリックしてデプロイメントセンターを開き、同期タスクを本番環境にデプロイする必要があります。

結果:次の例は、設定とランタイムで使用される実際のインデックス名を示しています。
スクリプトモードでのインデックス設定:
"index": "esstress_1_${var1}_${var2}"。ランタイムで使用されるインデックス名:
esstress_1_20230106_20230105。
オブジェクトまたはネストされたフィールドのプロパティの同期
文字列の引用符と JSON からネストへの同期の処理
文字列の周りの二重引用符は Kibana の表示上のアーティファクトです。Elasticsearch の実際のデータにはこれらの余分な引用符はありません。
curlコマンドや Postman などのツールを使用して生のデータを表示できます。データを取得するためのcurlコマンドは次のとおりです。// ES 7.x の場合 curl -u username:password --request GET 'http://esxxx.elasticsearch.aliyuncs.com:9200/indexname/_search' // ES 6.x の場合 curl -u username:password --request GET 'http://esxxx.elasticsearch.aliyuncs.com:9200/indexname/typename/_search'
はい、送信先 ES フィールドの型を
nestedに設定して、MaxCompute の JSON 文字列を ES のnestedオブジェクトに同期できます。次の例は、nameフィールドを ES のnested形式に同期する方法を示しています。同期設定:
nameフィールドのtypeをnestedに設定します。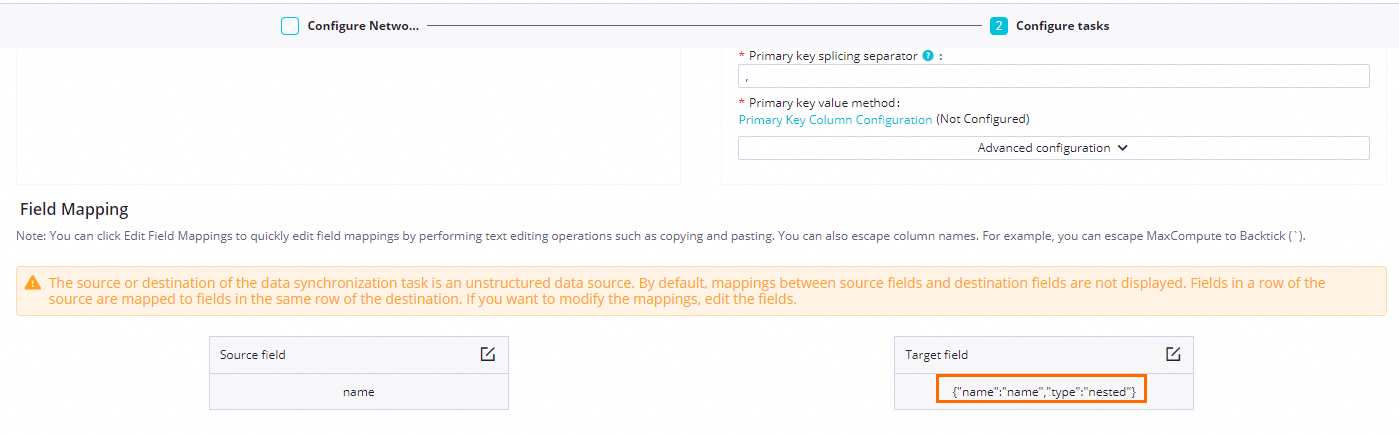
同期結果:
nameフィールドはnestedオブジェクトです。
ソースデータが 文字列「[1,2,3,4,5]」 の場合、ES に配列として保存するにはどうすればよいですか?
データを ES に配列として書き込むには、ソースデータの形式に基づいて 2 つの方法のいずれかを使用できます。
ソースデータを JSON 配列として解析します。ソースデータが
"[1,2,3,4,5]"の場合は、json_array=trueを設定してソースデータを解析します。これにより、データが ES フィールドに配列として書き込まれます。列設定でjson_array=trueを設定します。コードレス UI での設定:

スクリプトモードでの設定:
"column":[ { "name":"docs", "type":"keyword", "json_array":true } ]
区切り文字を使用してソースデータを解析します。ソースデータが「1,2,3,4,5」の場合は、
splitter=","を設定して文字列を解析し、ES フィールドに配列として書き込みます。制限事項:
各タスクは 1 つの splitter (区切り文字) のみをサポートします。異なる配列フィールドに異なる区切り文字を設定することはできません。たとえば、ソース列
col1="1,2,3,4,5"とcol2="6-7-8-9-10"がある場合、各列に異なるsplitterを指定することはできません。splitterは正規表現にすることができます。たとえば、ソース列の値が「6-,-7-,-8+,*9-,-10」の場合、splitterを"[-,*+]"に設定できます。これはコードレス UI でサポートされています。
コードレス UI での設定:
 デフォルトの
デフォルトの splitterは"-,-"です。スクリプトモードでの設定:
"parameter" : { "column": [ { "name": "col1", "array": true, "type": "long" } ], "splitter":"," }
認証失敗と過剰なログの防止
日付型としてのデータ同期
外部バージョンによる書き込み失敗の処理
エラー:ES_MISSING_DATE_FORMAT
エラー:DataXException
エラー:version_conflict_engine_exception
エラー:illegal_argument_exception
原因:
similarityやpropertiesなどの高度なプロパティを列に設定する場合、プラグインがそれらを認識できるように、other_paramsオブジェクト内に配置する必要があります。
解決策:
Columnでother_paramsを設定し、other_paramsで次のように similarity を追加します。{"name":"dim2_name",...,"other_params":{"similarity":"len_similarity"}}
配列フィールド同期エラー:dense_vector
ライター設定が有効にならない
自己構築インデックスのキーワード型ネスト属性が、自動生成 (cleanup=true で同期タスクを実行) 後にキーワードに変わるのはなぜですか?
Kafka
データが endDateTime を超える
タスクが完了しない
RestAPI
RestAPI Writer エラー:The JSON data at path:[] is not an array
RestAPI Writer は 2 つの書き込みモードを提供します。複数のデータレコードを同期するには、dataMode パラメーターを multiData に設定し、RestAPI Writer スクリプトに dataPath:"data.list" を追加します。詳細については、「RestAPI Writer」をご参照ください。
列を設定する際には、「data.list」プレフィックスを追加しないでください。
Tablestore Writer の設定
自動採番主キー
時系列モデルの設定
_tags と is_timeseries_tag
たとえば、データレコードには phone=xiaomi、RAM=8G、camera=LEICA の 3 つのタグがあります。
データエクスポートの例 (Tablestore Reader)
これらのタグを結合して単一の列としてエクスポートするには、次の設定を使用します。
"column": [ { "name": "_tags", } ],DataWorks は、次の形式でタグを単一の列としてエクスポートします。
["phone=xiaomi","camera=LEICA","RAM=8G"]phoneタグとcameraタグを別々の列としてエクスポートするには、次の設定を使用します。"column": [ { "name": "phone", "is_timeseries_tag":"true", }, { "name": "camera", "is_timeseries_tag":"true", } ],DataWorks は、次の形式で 2 つの列をエクスポートします。
xiaomi, LEICA
データインポートの例 (Tablestore Writer)
上流のデータソースに 2 列のデータが含まれていると仮定します。
1 つの列には
["phone=xiaomi","camera=LEICA","RAM=8G"]が含まれています。もう 1 つの列には 6499 が含まれています。
両方の列のデータをタグフィールドに追加するには、
 この設定を使用します。
この設定を使用します。"column": [ { "name": "_tags", }, { "name": "price", "is_timeseries_tag":"true", }, ],最初の列の設定では、
["phone=xiaomi","camera=LEICA","RAM=8G"]配列全体をタグフィールドにインポートします。2 番目の列の設定では、
price=6499を別のタグとしてタグフィールドにインポートします。
カスタムテーブル名
カスタムテーブル名
テーブル名が orders_20170310、orders_20170311、orders_20170312 のような日次テーブルなどのパターンに従い、同じテーブルスキーマを共有している場合は、スクリプトモード設定でスケジューリングパラメーターを使用してカスタムテーブル名を指定できます。これにより、タスクは毎朝ソースデータベースの前日のテーブルから自動的にデータを読み取ることができます。
たとえば、タスクが 2017 年 3 月 15 日に実行される場合、orders_20170314 テーブルからデータを読み取ります。
スクリプトモードでは、ソーステーブル名を orders_${tablename} などの変数に置き換えます。前日のデータを読み取る必要があるため、タスクのパラメーター設定で tablename=${yyyymmdd-1} を設定します。
スケジューリングパラメーターの使用方法の詳細については、「スケジューリングパラメーターの形式」をご参照ください。
テーブル列の変更
ソース列の変更
タスク設定の問題
不完全なテーブルリスト
テーブル名または列名のキーワード
キーワード関連のタスクの失敗
原因:列名が予約キーワードであるか、数字で始まる場合にタスクが失敗します。
解決策:Data Integration 同期タスクをスクリプトモードに切り替え、列設定の特殊なフィールドにエスケープ文字を使用します。詳細については、「スクリプトモードでのタスクの設定」をご参照ください。
MySQL の場合は、キーワードをバッククォートで囲みます (例:
`keyword`)。Oracle および PostgreSQL の場合は、キーワードを二重引用符で囲みます (例:
"keyword")。SQL Server の場合は、キーワードを角括弧で囲みます (例:
[keyword])。
以下は MySQL を使用した例です。
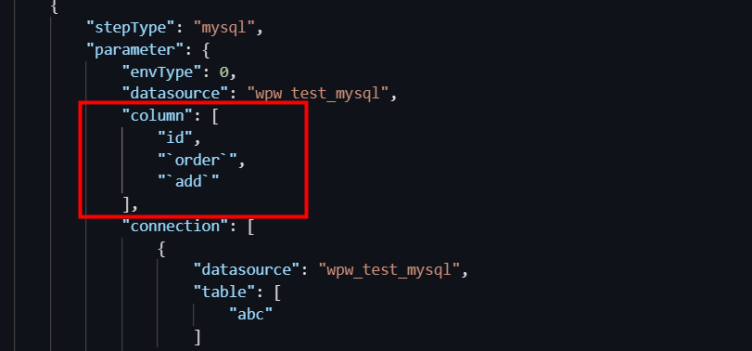
次の例では、MySQL データソースを使用しています。
次のステートメントを実行して、
aliyunという名前のテーブルを作成します。create table aliyun (`table` int ,msg varchar(10));次のステートメントを実行してビューを作成し、
table列にエイリアスを割り当てます。create view v_aliyun as select `table` as col1,msg as col2 from aliyun;説明tableという単語は MySQL のキーワードです。その結果、生成された SQL ステートメントはデータ同期中に失敗します。これを防ぐには、ビューを作成し、table列にエイリアスを割り当てます。ベストプラクティスとして、キーワードを列名として使用しないでください。
同期タスクを設定する際、キーワード列に割り当てたエイリアスを使用するために、
aliyunテーブルの代わりにv_aliyunビューを選択します。
フィールドマッピング
バッチタスクエラー:plugin xx does not specify column
非構造化データマッピングの失敗
症状:
Preview Data をクリックすると、フィールドのサイズがバイト制限を超えているというメッセージが表示されます。

原因:メモリ不足 (OOM) エラーを防ぐため、データソースサービスはデータプレビューリクエストを処理する際に各フィールドの長さをチェックします。単一の列が 1,000 バイトを超えると、このメッセージが表示されます。このメッセージはタスクの通常の操作には影響しません。エラーを無視してバッチ同期タスクを実行できます。
説明ソースファイルが存在し、ネットワーク接続が正常な場合、次の理由でデータプレビューが失敗することもあります。
ファイルの 1 行のデータが 10 MB の制限を超えています。この場合、データは表示されず、同様のメッセージが表示されます。
1 行の列数が 1,000 列の制限を超えています。この場合、最初の 1,000 列のみが表示され、1,001 番目の列にメッセージが表示されます。