リアルタイム全データベース同期機能は、1 回限りのフル移行と継続的な増分キャプチャを組み合わせ、MySQL や Oracle などのソースデータベース全体を低レイテンシーでターゲットシステムに同期します。このタスクは、ソースデータベースの履歴データの完全同期を行い、ターゲットテーブルのスキーマとデータを自動的に初期化します。その後、タスクは自動的にリアルタイム増分モードに切り替わり、変更データキャプチャ (CDC) などの技術を使用して、後続の変更を継続的にキャプチャして同期します。この機能は、リアルタイムデータウェアハウスやデータレイクの構築などのシナリオに適しています。このトピックでは、MySQL データベースのデータを MaxCompute にリアルタイムで同期する例を挙げ、同期タスクを設定する方法を説明します。
前提条件
データソースの準備
ソースデータソースと宛先データソースを作成します。詳細については、「データソース管理」をご参照ください。
データソースがリアルタイムデータベース全体の同期をサポートしていることを確認してください。詳細については、「サポートされているデータソースと同期ソリューション」をご参照ください。
MySQL、Hologres、Oracle などの特定のデータソースでは、ログ記録を有効にする必要があります。方法はデータソースによって異なります。詳細については、「データソース一覧」をご参照ください。
MaxCompute: Decimal 型は MaxCompute 2.0 でのみサポートされています。同期を実行する前に、MaxCompute 2.0 データ型を有効にする必要があります。詳細については、「MaxCompute V2.0 データ型エディション」をご参照ください。
リソースグループ:設定済みのサーバーレスリソースグループが必要です。
ネットワーク接続:リソースグループとデータソース間のネットワーク接続を設定してください。
使用上の注意
DataWorks は、リアルタイム全データベース同期 と 全量 & 増分 (ニアリアルタイム) の2種類の全データベース同期をサポートしています。いずれも、ソースデータベース内の履歴データを完全同期した後、自動的にリアルタイム増分モードに切り替わります。ただし、両者ではレイテンシーと送信先テーブルの要件が異なります。
鮮度:リアルタイム全データベース同期機能では、レイテンシーは数秒から数分です。全量 & 増分 (ニアリアルタイム) 機能では、鮮度は T+1 です。
送信先テーブル (MaxCompute):
主キー Delta テーブル:リアルタイム全データベース同期のすべての機能に対応しています。
標準テーブルおよび追加 Delta テーブル:リアルタイム全データベース同期タスクで増分同期モードを選択した場合にのみ、[Append] モードを使用できます。
全量 & 増分 (ニアリアルタイム) 機能は、上記のすべてのテーブルタイプに対応しています。
リアルタイム全データベース同期タスクは、相互に連携する [DataStudio] および [Data Integration] モジュールで設定できます。
一貫した構成:DataStudio と Data Integration のどちらでタスクを作成しても、設定UI、パラメータ設定、基盤となる機能は同一です。
双方向同期:Data Integration で作成したタスクは、自動的に DataStudio の
data_integration_jobsディレクトリに同期され、表示されます。これらのタスクは管理しやすいように、ソースタイプ-送信先タイプのフォーマットでチャネル別に分類されます。
タスクの設定
ステップ1:同期タスクの作成
DataWorks コンソールにログインします。 左側のナビゲーションウィンドウで、[Data Integration] をクリックします。 表示されるページで、ドロップダウンリストから目的のワークスペースを選択し、[Data Integrationに移動] をクリックします。
左側のナビゲーションバーで Synchronization Task をクリックし、次にページの上部にある Create Synchronization Task をクリックして、タスク情報を設定します。
Source Type:
MySQL。Destination Type:
MaxCompute。Specific Type:
Entire Database Real-time。Synchronization Mode:
[Schema Migration]:ソースと一致するデータベースオブジェクト (テーブル、フィールド、データ型など) を宛先に自動的に作成しますが、データは含まれません。
[Full Synchronization] (オプション):テーブルなどの指定されたオブジェクトのすべての履歴データを、ソースから宛先へ 1 回限りで完全にコピーします。このプロセスは通常、初期データ移行またはデータ初期化に使用されます。
[Incremental Sync] (オプション):フル同期の完了後、ソースからの変更データ (追加、変更、削除) を継続的にキャプチャし、宛先に同期します。
ステップ2:データソースとコンピューティングリソースの設定
[Source Data Source] 領域で、ワークスペースに追加済みの
MySQLデータソースを選択し、[Destination] 領域でMaxComputeデータソースを選択します。[Running Resources] セクションで、同期タスクの [Resource Group] を選択し、タスクに [Resource Group] [CU] を割り当てます。
説明タスクログに
Please confirm whether there are enough resources…などのリソース不足に関するメッセージが表示される場合、現在のリソースグループにタスクを開始または実行するための十分な利用可能な CU がないことを示しています。[Configure Resource Group] パネルで、タスクの CU 数を増やして、より多くのコンピューティングリソースを割り当てることができます。推奨されるリソース設定の詳細については、「Data Integrationの推奨CU」をご参照ください。ビジネス要件に基づいて設定を調整する必要があります。
ソースと宛先の両方のデータソースが [接続チェック] に合格していることを確認します。
ステップ3:同期ソリューションの設定
1. ソースの設定
このステップでは、[ソーステーブル] セクションでソースデータソースから同期するテーブルを選択し、
 アイコンをクリックして右側の [選択済みテーブル] セクションに移動できます。テーブルが多数ある場合は、[Database Filtering] または [Table filtering] を使用して、正規表現を設定してテーブルを選択できます。
アイコンをクリックして右側の [選択済みテーブル] セクションに移動できます。テーブルが多数ある場合は、[Database Filtering] または [Table filtering] を使用して、正規表現を設定してテーブルを選択できます。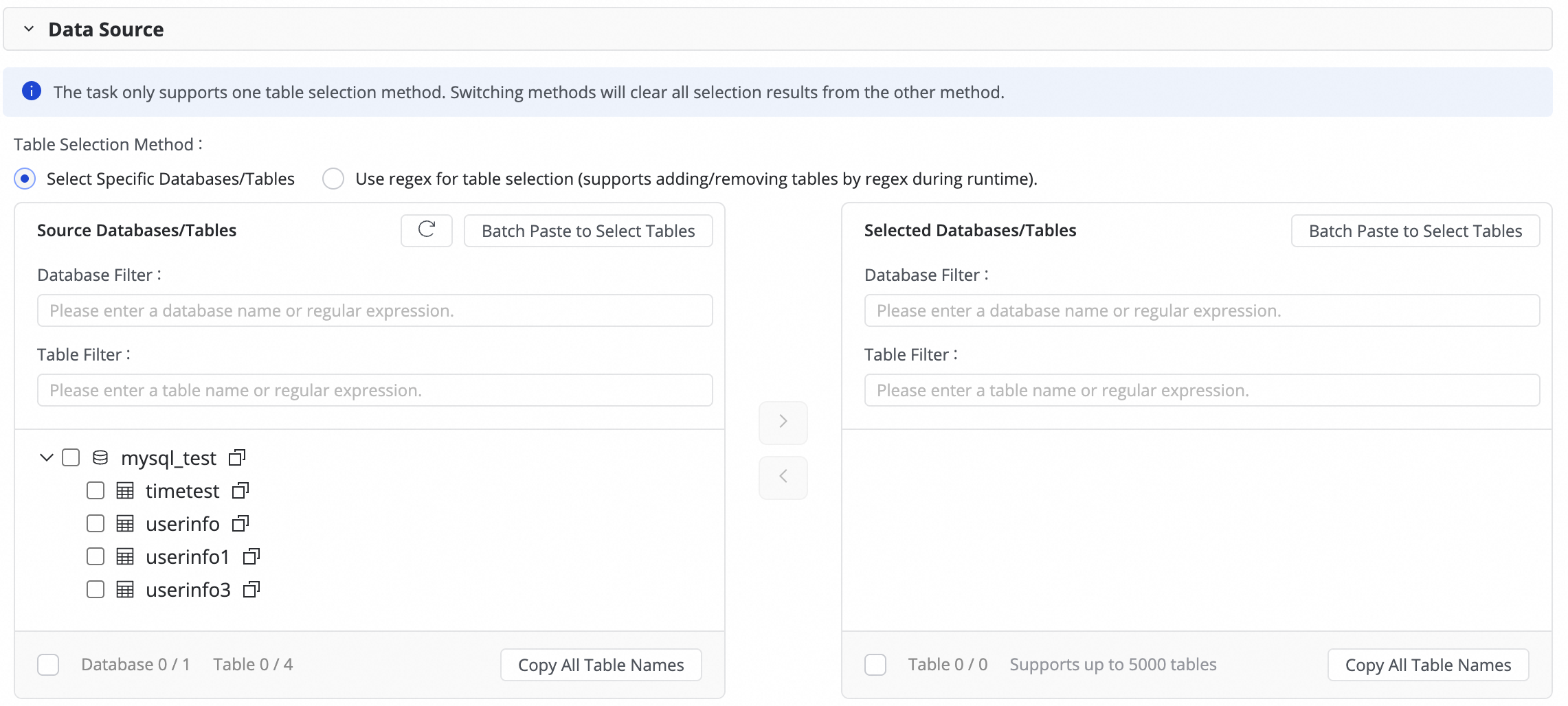
複数のシャードデータベースとテーブル (同じ構造) を同じ宛先テーブルに書き込む必要がある場合は、[正規表現でテーブルを選択] を使用できます。
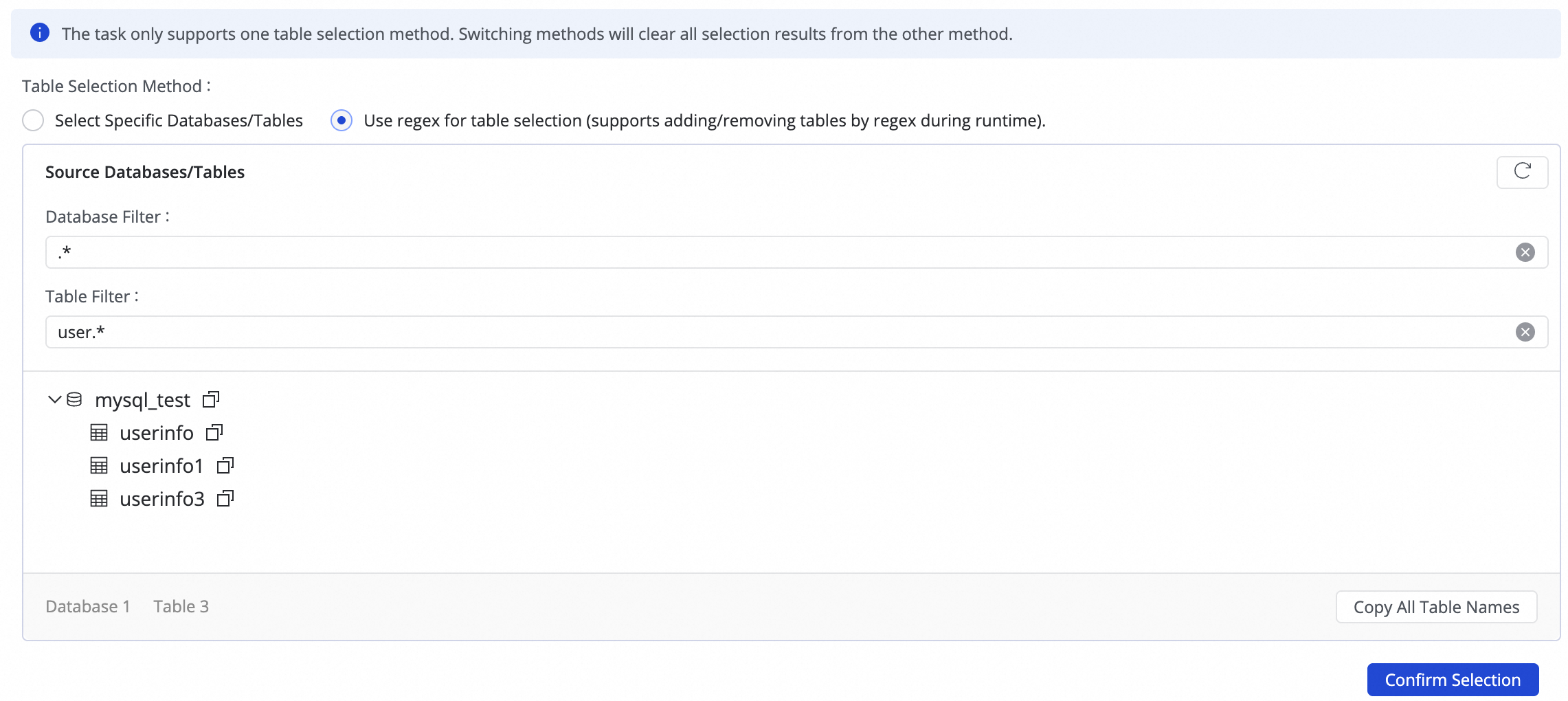
ソーステーブルの設定に正規表現を入力します。DataWorks は、一致するすべてのソーステーブルを自動的に識別して収集し、式によってマッピングされた宛先テーブルにデータを書き込みます。説明この方法は、シャードテーブルをマージして同期するシナリオに適しており、シャードデータベースとテーブルの同期に似ています。この方法では、複数の多対一同期ルールを繰り返し追加する必要がないため、設定効率が向上します。
2. 宛先の設定
リアルタイム全データベース同期タスクで [Incremental Sync] のみを選択した場合、宛先テーブルへの書き込みにおける増分同期モードを設定できます。
リプレイ:このモードは PK Delta Tables でのみサポートされます。通常の同期と同様に、このモードはデータフィールドのみを同期します。
増分ストリーム:このモードは標準テーブルと Append Delta Tables でサポートされます。このモードは、ソーステーブルからのリアルタイムデータと、挿入、更新、削除などのメタデータを宛先テーブルに書き込みます。増分ストリームテーブルのフォーマットの詳細については、「付録:増分ストリームテーブルのフォーマット」をご参照ください。
3. 宛先テーブルのマッピング
このステップでは、ソーステーブルと宛先テーブル間のマッピングルールを定義し、プライマリキー、動的パーティション、DDL/DML 設定などのパラメータに関するルールを指定する必要があります。これらのルールによって、データの書き込み方法が決まります。
操作 | 説明 | ||||||||||||
[Refresh] | システムは、選択したソーステーブルを自動的にリストアップします。ただし、宛先テーブルのプロパティを反映させるには、更新して確認する必要があります。
| ||||||||||||
[Customize Mapping Rules for Destination Table Names] (オプション) | システムには、テーブル名を生成するためのデフォルトルールがあります:
次のシナリオを実装できます。
| ||||||||||||
フィールドデータ型マッピングの編集 (オプション) | システムは、ソースと宛先のフィールドタイプ間のデフォルトマッピングを提供します。このマッピングをカスタマイズするには、テーブルの右上隅にある [Edit Mapping of Field Data Types] をクリックします。設定が完了したら、[Apply and Refresh Mapping] をクリックします。 フィールドタイプマッピングを編集する際は、型変換ルールが有効であることを確認してください。そうしないと、型変換が失敗し、ダーティデータが生成され、タスクの実行に影響を与える可能性があります。 | ||||||||||||
宛先テーブルスキーマの編集 (オプション) | カスタムテーブル名マッピングルールに基づいて、システムは新しい宛先テーブルを作成するか、一致する名前の既存のテーブルを再利用します。 DataWorks は、ソーステーブルスキーマに基づいて宛先テーブルスキーマを自動的に生成します。ほとんどの場合、手動での介入は必要ありません。次の方法でテーブルスキーマを変更することもできます。
既存のテーブルの場合、フィールドの追加のみが可能です。新しいテーブルの場合、フィールドとパーティションフィールドを追加し、テーブルタイプまたはテーブルプロパティを設定できます。詳細については、UI の編集可能な領域をご参照ください。 | ||||||||||||
[Value assignment] | ネイティブフィールドは、ソーステーブルと宛先テーブルの一致するフィールド名に基づいて自動的にマッピングされます。[新しく追加されたフィールドとパーティションフィールド] には、手動で値を割り当てる必要があります。値を割り当てるには、次の操作を実行します。
割り当ては定数と変数の両方をサポートしており、[Value Type] 設定でタイプを切り替えることができます。サポートされている方法は次のとおりです。
説明 パーティション数が過剰になると、同期効率に影響します。1 日に 1,000 を超える新しいパーティションが作成されると、パーティション作成が失敗し、タスクが終了します。そのため、パーティションフィールドに値を割り当てる際は、生成される可能性のあるパーティション数を見積もる必要があります。秒またはミリ秒レベルでパーティションを作成する場合は注意してください。 | ||||||||||||
[ソース分割列] | ソース分割列では、ソーステーブルからフィールドを選択するか、[Not Split] を選択できます。同期タスクが実行されると、このフィールドに基づいて複数のタスクに分割され、データを並列かつバッチで読み取ります。 テーブルのプライマリキーをソース分割列として使用することを推奨します。STRING、FLOAT、DATE 型のフィールドはサポートされていません。 現在、ソース分割列は、ソースが MySQL データソースの場合にのみサポートされています。 | ||||||||||||
[フル同期をスキップしますか?] | ステップ 3 でフル同期を設定した場合、特定のテーブルのフル同期をスキップできます。これは、他の方法を使用して既に宛先に全データを同期している場合に便利です。 | ||||||||||||
[Full condition] | このパラメータを使用すると、フル同期フェーズ中にソースデータをフィルタリングできます。WHERE キーワードなしで WHERE 句の内容のみを入力する必要があります。 | ||||||||||||
[Configure DML Rule] | DML メッセージ処理は、データが宛先に書き込まれる前に、ソースからの変更データ ( | ||||||||||||
その他 | [Table Type]:MaxCompute は、標準テーブル、
Delta テーブルの詳細については、「Delta Table」をご参照ください。 |
 ボタンをクリックし、Manually enter と Built-in Variable を組み合わせることで生成できます。サポートされている変数には、ソースデータソース名、ソースデータベース名、およびソーステーブル名が含まれます。
ボタンをクリックし、Manually enter と Built-in Variable を組み合わせることで生成できます。サポートされている変数には、ソースデータソース名、ソースデータベース名、およびソーステーブル名が含まれます。





 ボタンをクリックします。
ボタンをクリックします。 ツールチップで各変数の意味を確認できます。
ツールチップで各変数の意味を確認できます。ステップ4:詳細パラメータの設定
詳細パラメータの設定
カスタム同期要件を満たすためにタスクのきめ細かい設定を行う必要がある場合は、[Advanced Parameters] タブに移動して詳細パラメータを変更できます。
UI の右上隅にある [詳細設定] をクリックして、詳細パラメータ設定ページに移動します。
ツールチップに基づいてパラメータ値を変更します。各パラメータの説明は、その名前の横に表示されます。
AI を活用した設定機能を使用することもできます。タスクの同時実行性の調整など、自然言語の指示を入力します。大規模言語モデル (LLM) が推奨されるパラメータ値を生成します。ビジネス要件に基づいて、生成された値を受け入れるかどうかを決定できます。
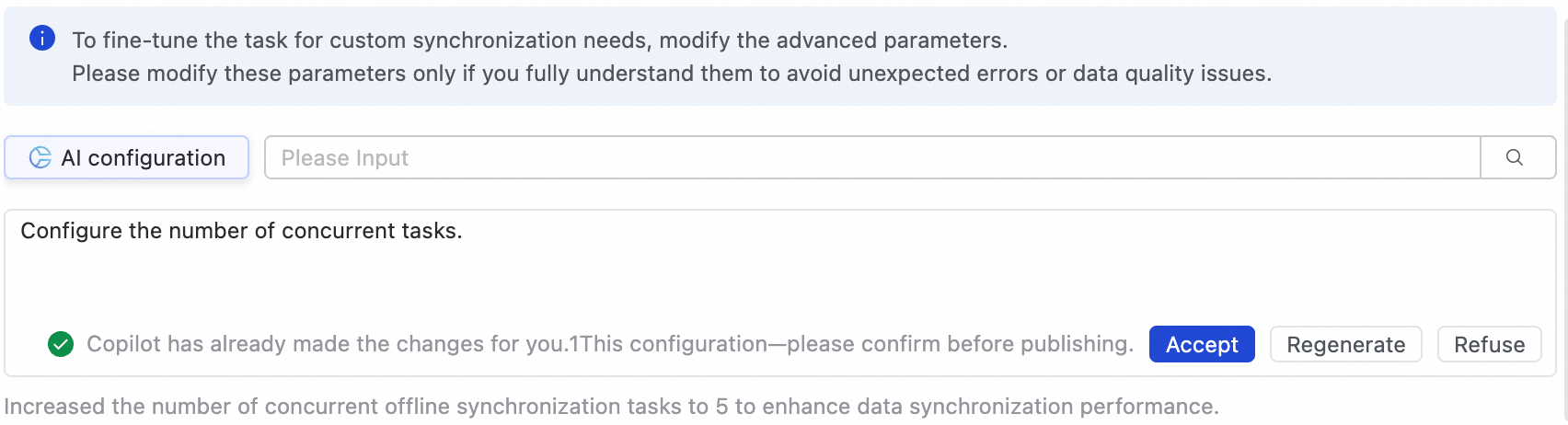
これらのパラメータを変更するのは、その意味を完全に理解している場合のみにしてください。そうしないと、タスクの遅延、他のタスクをブロックする過剰なリソース消費、データ損失などの予期しない問題が発生する可能性があります。
DDL 機能の設定
一部のリアルタイム同期リンクは、ソーステーブルスキーマのメタデータ変更を検出し、宛先に通知できます。これにより、宛先は更新を同期したり、アラートの送信、変更の無視、タスクの終了などの他のアクションを実行したりできます。
インターフェースの右上隅にある [Configure DDL Capability] をクリックして、各変更タイプに対応する処理ポリシーを設定できます。異なるチャネルは異なる処理ポリシーをサポートしています。
通常処理:宛先は、ソースからの DDL 変更情報を処理します。
無視:変更メッセージは無視され、宛先では変更は行われません。
エラー:リアルタイム全データベース同期タスクが終了し、そのステータスが [エラー] に設定されます。
アラート:ソースでこのタイプの変更が発生したときにアラートを送信します。[Configure Alert Rule] で DDL 通知ルールを設定する必要があります。
ソースに新しい列が追加され、DDL 同期によって宛先に作成される場合、システムは宛先テーブルの既存の行にあるその列のデータをバックフィルしません。
ステップ5:タスクのデプロイと実行
すべての設定が完了したら、ページ下部の [Save] をクリックして、タスク設定を完了します。
全データベース同期タスクは直接デバッグをサポートしておらず、実行するには [Operation Center] に公開する必要があります。そのため、新しいタスクまたは編集されたタスクは、[Deploy] 後にのみ有効になります。
タスクを公開する際、[Start immediately after deployment] を選択すると、タスクは自動的に開始されます。それ以外の場合、タスクが公開された後、 ページに移動し、対象タスクの [操作] 列でタスクを手動で開始します。
[Name/ID] でタスクの [Tasks] をクリックして、詳細な実行プロセスを表示します。
ステップ 6:アラートの設定
1. アラートルールの追加
リストで、対応する全データベースのリアルタイムタスクを見つけ、[操作] 列で をクリックしてタスクのアラートポリシーを設定します。
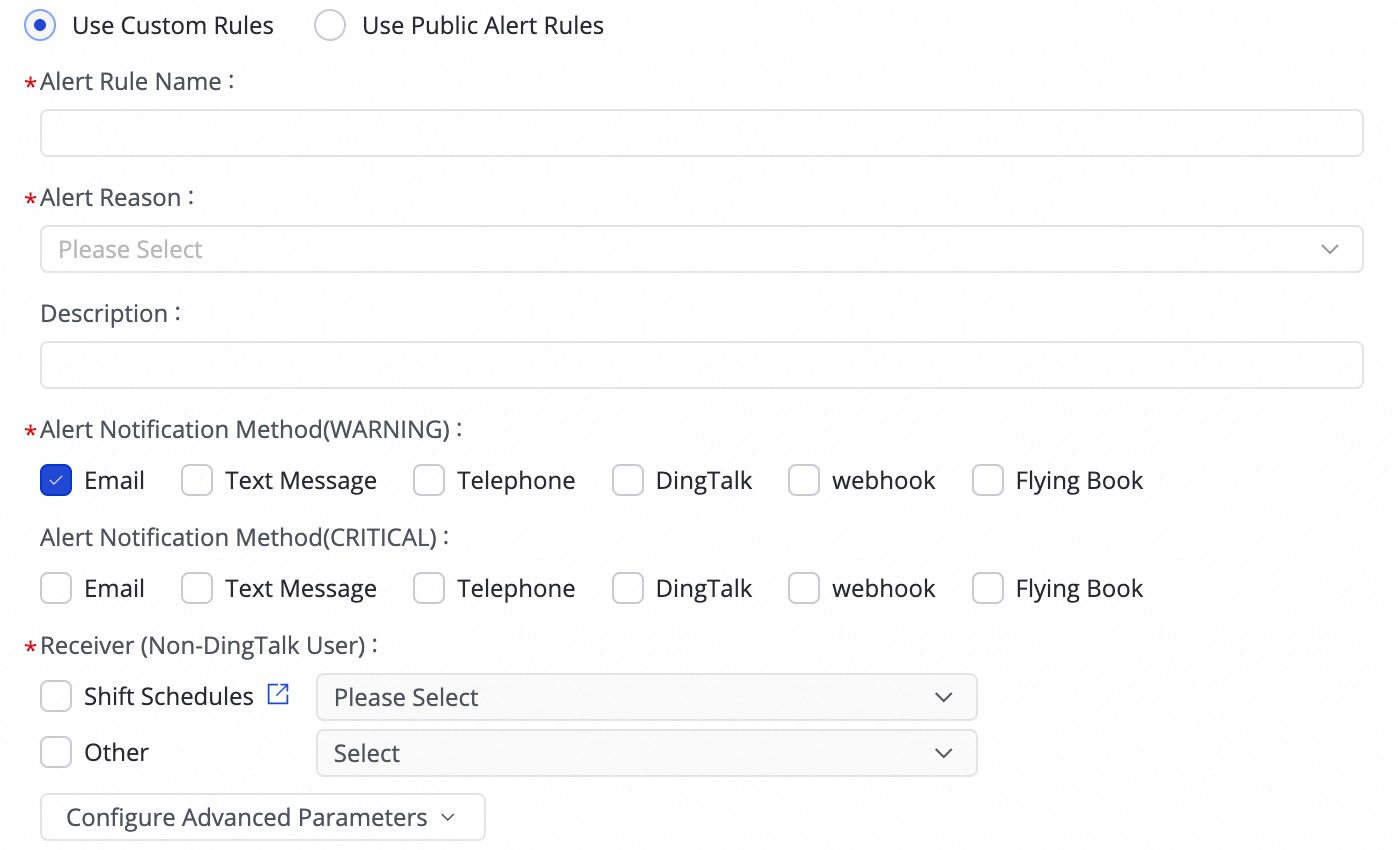
(1) Create Rule をクリックしてアラートルールを設定します。
Alert Reason を設定して、Business delay、[フェールオーバー]、Task status、DDL Notification、Task Resource Utilization などのタスクメトリックを監視し、指定したしきい値に基づいて CRITICAL または WARNING アラートを設定できます。
Configure Advanced Parameters で、アラートメッセージの送信間隔を制御し、一度に多くのメッセージを送信することによる無駄やメッセージのバックログを防ぐことができます。
アラート理由として Business delay、Task status、または Task Resource Utilization を選択した場合、復旧通知を有効にすることで、タスクが正常に戻った後に受信者へ通知することもできます。
(2) アラートルールの管理。
既存のアラートルールは、アラートスイッチを使用して有効または無効にできます。また、アラートレベルに基づいて異なる担当者にアラートを送信することもできます。
2. アラートの表示
展開されたタスク リストで をクリックして [アラートイベント] ページを開くと、発生したアラートを表示できます。
タスクの管理
タスクの編集
ページで、作成した同期タスクを見つけ、More 列の Operation をクリックし、次に Edit をクリックします。タスク情報を変更できます。手順はタスク設定と同じです。
実行中でないタスクについては、設定を変更して保存し、タスクを本番環境にデプロイすると変更が有効になります。
[Running]のタスクでは、Start immediately after deployment オプションを選択せずに編集して公開すると、元の操作ボタンが Apply Updates に変わります。変更をオンライン環境に反映させるには、このボタンをクリックする必要があります。
[更新を適用] をクリックすると、システムはタスクを停止、デプロイ、再起動することで変更を反映します。
テーブルを追加するか、既存のテーブルに切り替える場合:
更新を適用する際にチェックポイントを選択することはできません。[OK] をクリックすると、システムは新しいテーブルに対してスキーマ移行と完全同期を実行します。完全同期が完了すると、新しいテーブルの増分同期が元のテーブルと並行して開始されます。
他の情報を変更する場合:
更新を適用する際にチェックポイントを選択できます。[OK] をクリックすると、タスクは指定されたチェックポイントから再開します。チェックポイントを指定しない場合、タスクは最後に停止した時点から再開します。
変更されていないテーブルは影響を受けません。更新と再起動の後、最後に停止した時点から再開します。
タスクの表示
同期タスクを作成した後、同期タスクページでタスクのリストとその基本情報を表示できます。

[操作] 列では、同期タスクを Start または 停止 でき、[More] では [編集] や View などの他の操作を実行できます。
実行中のタスクについては、Execution Overview で基本的な実行ステータスを確認できます。該当の概要領域をクリックして、実行の詳細を表示することもできます。

ブレークポイントからの再開
シナリオ
タスクを開始または再起動する際にチェックポイントを手動でリセットする操作は、次のシナリオに適しています。
タスクの復旧とデータの再開:タスクが中断された場合、中断した時点に開始チェックポイントを手動で設定することで、正確なデータ復旧を保証できます。
データ問題のトラブルシューティングとバックトラッキング:同期されたデータに損失や異常が見つかった場合、問題が発生する前の時点にチェックポイントをロールバックして、問題のあるデータをリプレイし、修正することができます。
タスク設定の主な変更:宛先テーブルスキーマやフィールドマッピングなど、タスク設定に大幅な調整を行った後は、新しい設定におけるデータの正確性を確保するために、特定の時点にチェックポイントをリセットすることを推奨します。
手順
Start をクリックし、ダイアログボックスで、[Whether to reset the site] を選択します:

チェックポイントをリセットせずにタスクを直接実行する:タスクは最後に停止した時点 (最後のチェックポイント) から続行されます。
チェックポイントをリセットして時間を選択する:タスクは指定した時刻のチェックポイントから開始されます。選択する時間が、ソースのバイナリログで利用可能な最も早い時点以降であることを確認してください。
同期タスクの実行中に、無効なチェックポイントまたは存在しないチェックポイントを示すエラーが発生した場合は、次の解決策をお試しください。
チェックポイントをリセットする:タスクを開始する際に、ソースデータベースで利用可能な最も早いチェックポイントを選択してください。
ログ保持期間を調整する:データベースのチェックポイントが期限切れになった場合は、データベースのログ保持期間を 7 日間に増やすことを検討してください。
データを同期する:データが失われた場合は、完全同期を再度実行するか、オフライン同期タスクを設定して失われたデータを手動で同期することを検討してください。
タスクの運用と保守およびチューニング
タスクの開始後、データ消費の遅延、タスクのストール、またはパフォーマンスの低下などの問題が発生した場合は、「全データベースのリアルタイム同期の運用と保守およびチューニング」をご参照ください。
よくある質問
リアルタイム全データベース同期に関するよくある問題の詳細については、「リアルタイム全データベース同期に関するよくある質問」をご参照ください。
付録:インクリメンタルストリームテーブルのフォーマット
フラット化されたソーステーブルのフィールド
パラメーター | 説明 |
sequence_id | インクリメンタルイベントのレコード ID です。値は一意で、単調増加します。 |
operation_type | オペレーションタイプ です。有効な値: I、D、U。 |
execute_time | データに対応するタイムスタンプ です。 |
before_image | 変更前のイメージがキャプチャされたかどうかを示します。有効な値: Y、N。 |
after_image | 変更後のイメージがキャプチャされたかどうかを示します。有効な値: Y、N。 |
src_datasource | ソースデータソース です。 |
src_database | ソースデータベース です。 |
src_table | ソーステーブル です。 |
フィールド 1 | 実際のデータフィールド 1 です。 |
フィールド 2 | 実際のデータフィールド 2 です。 |
フィールド 3 | 実際のデータフィールド 3 です。 |
JSON にマージされたソースフィールド
パラメーター | 説明 |
sequence_id | インクリメンタルイベントのレコード ID です。値は一意で、単調増加します。 |
operation_type | オペレーションタイプ です。有効な値: I、D、U。 |
execute_time | データに対応するタイムスタンプ です。 |
before_image | 変更前のイメージがキャプチャされたかどうかを示します。有効な値: Y、N。 |
after_image | 変更後のイメージがキャプチャされたかどうかを示します。有効な値: Y、N。 |
src_datasource | ソースデータソース です。 |
src_database | ソースデータベース です。 |
src_table | ソーステーブル です。 |
ddl_sql | オペレーションが DDL タイプの場合、このフィールドに DDL ステートメントが書き込まれます。 |
data_columns | JSON オブジェクトにマージされた実際のデータフィールド です。 |