Microsoft SQL Server 出力コンポーネントは、データを Microsoft SQL Server データソースに書き込みます。他のデータソースから取得したデータを Microsoft SQL Server データソースへ同期するシナリオでは、まずソースデータソース情報を構成した後、Microsoft SQL Server 出力コンポーネントのターゲットデータソースを構成する必要があります。本トピックでは、Microsoft SQL Server 出力コンポーネントの構成手順について説明します。
前提条件
Microsoft SQL Server データソースが作成されました。詳細については、「Microsoft SQL Server データソースの作成」をご参照ください。「」をご参照ください。
Microsoft SQL Server 出力コンポーネントのプロパティを構成する際に使用するアカウントには、対象データソースに対するライトスルー権限が必要です。該当の権限がない場合は、データソース権限の付与をリクエストする必要があります。詳細については、「データソース権限のリクエスト、更新、返却」をご参照ください。
操作手順
Dataphin ホームページの上部ナビゲーションバーで、[開発] > [データ統合] を選択します。
統合ページの上部ナビゲーションバーで、[プロジェクト] を選択します(Dev-Prod モードの場合は、環境を選択する必要があります)。
左側のナビゲーションウィンドウで、[バッチパイプライン] をクリックし、右側の [バッチパイプライン] リストから開発対象の [オフラインパイプライン] をクリックして、オフラインパイプラインの構成ページを開きます。
ページ右上隅の [コンポーネントライブラリ] をクリックして、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネルの左側ナビゲーションウィンドウで、[出力] を選択し、右側の出力コンポーネント一覧から [Microsoft SQL Server] コンポーネントを見つけ、キャンバスへドラッグします。
対象の入力コンポーネントの
 アイコンをクリック・ドラッグして、現在の Microsoft SQL Server 出力コンポーネントと接続します。
アイコンをクリック・ドラッグして、現在の Microsoft SQL Server 出力コンポーネントと接続します。Microsoft SQL Server 出力コンポーネント上で
 アイコンをクリックして、[Microsoft SQL Server 出力構成] ダイアログボックスを開きます。
アイコンをクリックして、[Microsoft SQL Server 出力構成] ダイアログボックスを開きます。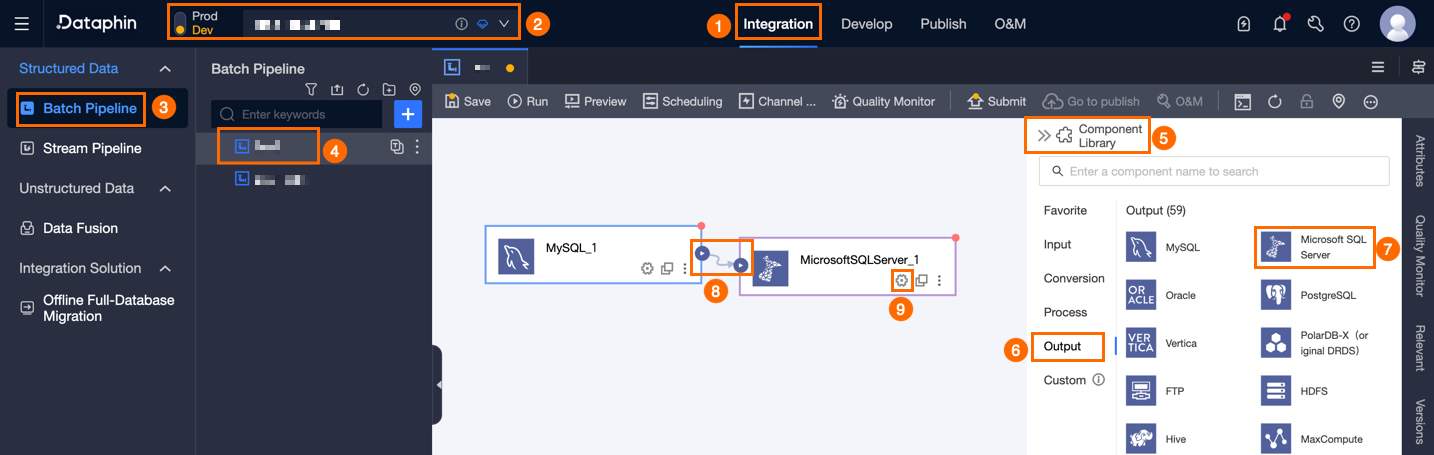
[Microsoft SQL Server 出力構成] ダイアログボックスで、パラメーターを構成します。
パラメーター
説明
[基本設定]
[ステップ名]
Microsoft SQL Server 出力コンポーネントの名称です。Dataphin が自動的にステップ名を生成しますが、ビジネス要件に応じて変更可能です。以下の要件を満たす必要があります:
使用可能な文字は、漢字、英字、アンダースコア (_)、数字のみです。
最大長は 64 文字です。
[データソース]
ドロップダウンリストには、ライトスルー権限を持つものおよび持たないすべての Microsoft SQL Server データソースが表示されます。現在のデータソース名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。ライトスルー権限を持たないデータソースについては、データソース名の後に [リクエスト] をクリックして権限をリクエストできます。詳細については、「データソース権限のリクエスト、更新、返却」をご参照ください。
Microsoft SQL Server データソースが存在しない場合は、[データソースの作成] をクリックして新規作成できます。詳細については、「Microsoft SQL Server データソースの作成」をご参照ください。
タイムゾーン
時刻形式のデータは、現在のタイムゾーンに基づいて処理されます。デフォルト値は選択されたデータソースで構成されたタイムゾーンであり、変更できません。
説明V5.1.2 より前のバージョンで作成されたタスクの場合、[データソースのデフォルト構成] または [チャネル構成のタイムゾーン] のいずれかを選択できます。デフォルトは [チャネル構成のタイムゾーン] です。
[データソースのデフォルト構成]:選択されたデータソースのデフォルトタイムゾーンです。
[チャネル構成のタイムゾーン]:現在の統合タスクの [プロパティ] > [チャネル構成] で構成されたタイムゾーンです。
[スキーマ](任意)
クロススキーマテーブル選択をサポートします。テーブルが配置されているスキーマを選択します。未指定の場合は、データソースで構成されたデフォルトスキーマが使用されます。
テーブル
出力データの対象テーブルを選択してください。 キーワードを入力してテーブルを検索するか、正確なテーブル名を入力して [完全一致] をクリックできます。テーブルを選択すると、システムが自動的にテーブルの状態チェックを実行します。現在選択中のテーブル名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。読み込みポリシー
ターゲットテーブルへのデータ書き込みポリシーを選択します。[ロードポリシー] には以下のオプションがあります:
[データ追加 (INSERT INTO)]:プライマリキー/制約の競合が発生した場合、ダーティデータエラーが表示されます。
[プライマリキー競合時の更新 (MERGE INTO)]:プライマリキー/制約の競合が発生した場合、対応するフィールドのデータが既存レコード上で更新されます。
[同期書き込み]
プライマリキー更新構文は原子操作ではありません。書き込み対象のデータに 重複するプライマリキー が含まれる場合は、有効化 する必要があります。それ以外の場合は並列書き込みが使用されます。同期書き込みのパフォーマンスは並列書き込みより低くなります。
説明このオプションは、ロードポリシーが [プライマリキー競合時の更新] に設定されている場合のみ利用可能です。
バッチ書き込みデータサイズ
一度に書き込むデータのサイズです。また、[バッチ書き込みレコード数] も設定できます。書き込み時には、どちらかの制限値(バッチ書き込みデータサイズまたはレコード数)に先に到達した方を優先して書き込みが実行されます。デフォルト値は 32 MB です。
レコードの一括書き込み
デフォルト値は 2048 レコード です。データ同期ではバッチ書き込み戦略が採用され、そのパラメーターには [バッチ書き込みレコード数] および [バッチ書き込みデータサイズ] が含まれます。
累積データが設定されたいずれかの制限値(バッチ書き込みデータサイズまたはレコード数)に達すると、システムはそのバッチを「満杯」と判断し、即座にターゲットへ一括書き込みを行います。
バッチ書き込みデータサイズは、推奨値として 32 MB を設定することを推奨します。バッチ挿入レコード数の上限については、単一レコードの実際のサイズに応じて柔軟に調整可能です。通常は、バッチ書き込みの利点を十分に活用するために大きな値を設定します。例えば、単一レコードのサイズが約 1 KB の場合、バッチ挿入バイトサイズを 16 MB とし、この条件に基づきバッチ挿入レコード数を 16 MB ÷ 1 KB = 16384 より大きい値(例: 20000 レコード)に設定します。この構成では、システムはバッチ挿入バイトサイズに基づいてバッチ書き込みをトリガーし、累積データが 16 MB に達するごとに書き込み操作を実行します。
プリペアドステートメント
(任意)データインポート前にデータベース上で実行される SQL スクリプトです。
例:サービスの継続的可用性を確保するため、現在のステップによるデータ書き込み前に、まずターゲットテーブル Target_A を作成し、Target_A への書き込みを実行します。その後、現在のステップによる書き込み完了時に、継続的に稼働中のテーブル Service_B を Temp_C にリネームし、Target_A を Service_B にリネームし、最後に Temp_C を削除します。
終了ステートメント
(任意)データインポート後にデータベース上で実行される SQL スクリプトです。
フィールド マッピング
入力フィールド
上流コンポーネントの出力に基づいて入力フィールドが表示されます。
出力フィールド
出力フィールドが表示されます。以下の操作が可能です:
フィールド管理: [フィールド管理] をクリックして、出力フィールドを選択します。

 アイコンをクリックして、[選択済み入力フィールド] を [未選択入力フィールド] に移動します。
アイコンをクリックして、[選択済み入力フィールド] を [未選択入力フィールド] に移動します。 アイコンをクリックして、[未選択の入力フィールド] を [選択済みの入力フィールド] に移動します。
アイコンをクリックして、[未選択の入力フィールド] を [選択済みの入力フィールド] に移動します。
一括追加: [一括追加] をクリックして、JSON、プレーンテキスト、DDL 形式での一括構成をサポートします。
JSON 形式の一括構成の例:
// 例: [{"name":"id","type":"String"}, {"name":"aaasa","type":"String"}, {"name":"creator","type":"String"}, {"name":"modifier","type":"String"}, {"name":"creator_nickname","type":"String"}, {"name":"modifier_nickname","type":"String"}, {"name":"create_time","type":"Date"}, {"name":"modify_time","type":"Date"}, {"name":"qbi_system_upload_id","type":"Long"}]説明name はインポート対象のフィールド名、type はインポート後のフィールド型を表します。例:
"name":"user_id","type":"String"は、user_id というフィールドをインポートし、そのフィールド型を String に設定することを意味します。プレーンテキスト形式の一括構成の例:
// 例: id,String aaasa,String creator,String modifier,String creator_nickname,String modifier_nickname,String create_time,Date modify_time,Date qbi_system_upload_id,Long行区切り文字は各フィールドの情報区切りに使用されます。デフォルトは改行 (\n) ですが、改行 (\n)、セミコロン (;)、ピリオド (.) をサポートします。
列区切り文字はフィールド名とフィールド型の区切りに使用されます。デフォルトはカンマ (,) です。
DDL 形式の一括構成の例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
新しい出力フィールドの作成: [+新しい出力フィールドの作成] をクリックし、[カラム] を入力し、プロンプトに従って [型] を選択します。現在の行の構成を完了したら、
 アイコンをクリックして保存します。
アイコンをクリックして保存します。
クイックマッピング
上流入力とターゲットテーブルのフィールドに基づき、手動でフィールドマッピングを選択できます。[クイックマッピング] には [同一行マッピング] および [同名マッピング] が含まれます。
[同名マッピング]:名前が一致するフィールドをマッピングします。
[同一行マッピング]:ソーステーブルとターゲットテーブルのフィールド名が一致しませんが、対応する行のフィールドデータをマッピングする必要があります。同一行のフィールドのみをマッピングします。
[OK] をクリックして、[Microsoft SQL Server] 出力コンポーネントのプロパティ構成を完了します。