アドホッククエリを使用して、クエリ文をカスタマイズして実行し、その結果をダウンロードできます。 たとえば、ジョブを開発した後、アドホッククエリを使用して、ジョブが期待どおりに実行されることを確認できます。 このトピックでは、アドホッククエリを作成し、クエリ結果をダウンロードする方法について説明します。
背景情報
アドホッククエリジョブは、現在のプロジェクトに設定されているコンピュートエンジンを使用します。 Hadoop コンピュートエンジンを使用する場合、Impala ジョブを有効にすることで、Hive SQL と Impala SQL の両方のアドホッククエリジョブを作成できます。 Impala はインメモリコンピューティングを実行するため、Impala SQL アドホッククエリは Hive SQL アドホッククエリよりも応答時間が短くなります。 また、Dataphin を使用すると、過去のジョブのクエリを書き換えることなく、Impala SQL と Hive SQL のジョブタイプをすばやく切り替えることができます。 詳細については、「付録:ジョブタイプの切り替え」をご参照ください。
前提条件
Impala SQL アドホッククエリを作成するには、Hadoop コンピュートエンジンで Impala ジョブ を有効にする必要があります。 詳細については、「Hadoop コンピュートエンジンの作成」をご参照ください。
アドホッククエリの結果をダウンロードするには、プロジェクトからデータをダウンロードする権限があることを確認してください。 また、プロジェクトで完全データとサンプルデータの両方のダウンロードが有効になっていることを確認してください。 詳細については、「プロジェクトの権限とコンピュートエンジンの管理」、「」、および「データダウンロードの設定」、「」をご参照ください。
制限事項
クエリ高速化機能を購入していない場合、アドホッククエリではクエリ高速化はサポートされません。
アドホッククエリを作成する
Dataphin のホームページの上部のメニューバーで、[開発] > [データ開発] を選択します。
上部のメニューバーで [プロジェクト] を選択します。 Dev-Prod モードを使用している場合は、[環境] も選択します。
左側のナビゲーションウィンドウで、[アドホッククエリ] を選択します。 アドホッククエリリストで、
 アイコンをクリックして、[コンピュートエンジンアドホッククエリ] または [データベース SQL アドホッククエリ] を作成します。
アイコンをクリックして、[コンピュートエンジンアドホッククエリ] または [データベース SQL アドホッククエリ] を作成します。[アドホッククエリの作成] ダイアログボックスで、次のパラメーターを設定します。
説明コンピュートエンジンが Hadoop で、[Impala] ノードを有効にしている場合は、[Hive SQL アドホッククエリ] と Impala SQL アドホッククエリを作成できます。
パラメーター
説明
名前
アドホッククエリの名前を入力します。
名前は最大 256 文字で、縦棒 (|)、スラッシュ (/)、バックスラッシュ (\)、コロン (:)、疑問符 (?)、山括弧 (<>)、アスタリスク (*)、二重引用符 (") は使用できません。
説明
アドホッククエリの簡単な説明を入力します。
ディレクトリの選択
ジョブが保存されるディレクトリを選択します。 デフォルトのディレクトリは [一時コード] です。
ディレクトリが作成されていない場合は、次のように [新しいフォルダを作成] します:
ページの左側にあるコンピューティングジョブのリストの上にある
 アイコンをクリックして、[フォルダの作成] ダイアログボックスを開きます。
アイコンをクリックして、[フォルダの作成] ダイアログボックスを開きます。[新しいフォルダ] ダイアログボックスで、フォルダの [名前] を入力し、必要に応じて [ディレクトリの選択] フィールドで場所を選択します。
[OK] をクリックします。
データソースタイプ
SQL ジョブのデータソースタイプを選択します。 サポートされているデータソースタイプの詳細については、「Dataphin がサポートするデータソース」、「」をご参照ください。
説明このパラメーターは、[データベース SQL アドホッククエリ] を作成する場合にのみ使用できます。
データソース
アドホッククエリのデータソースを選択します。利用可能なデータソースがない場合は、[+ 新しいデータソース] をクリックして作成します。
説明このパラメーターは、[データベース SQL アドホッククエリ] を作成する場合にのみ使用できます。
カタログ
データソースタイプが Presto または Trino の場合、データソースを設定した後にカタログも設定する必要があります。
データベース/スキーマ
データソースタイプが [MySQL]、[PostgreSQL]、[AnalyticDB for PostgreSQL]、[Oracle]、[Presto]、[GaussDB (DWS)]、[Microsoft SQL Server]、[ClickHouse]、[Hologres]、[Doris]、[openGauss]、[StarRocks]、[DM]、[OceanBase (Oracle テナントモード)]、[SelectDB]、[Trino]、または [PolarDB-X 2.0] の場合は、データソースを設定した後にスキーマも設定する必要があります。
[OK] をクリックして、アドホッククエリファイルを作成します。
(任意) クエリ高速化を設定して有効にし、高速化メソッドを選択します。
MCQA: このメソッドは MaxCompute Query Acceleration (MCQA) を使用します。各テナントには、MCQA のジョブ数と同時実行数に制限があります。これらの制限により、アクセラレーションの失敗や実行エラーが発生する可能性があります。詳細については、「クエリアクセラレーション (MCQA)」をご参照ください。MCQA アクセラレーションは、管理センター > システム設定 > 開発プラットフォーム > クエリアクセラレーションで無効にできます。
サポートされているアクセラレーションメソッドは、コンピュートエンジンとシナリオによって異なります。
現在のテナントが MaxCompute コンピュートエンジンを使用している場合:
クエリ高速化を購入していないが、開発プラットフォームでクエリ高速化を有効にしている場合、高速化メソッドは MCQA です。
クエリ高速化を購入し、開発プラットフォームでクエリ高速化を有効にしており、現在のプロジェクトのコンピュートエンジンが高速化ソースにアタッチされていない場合、高速化メソッドは MCQA です。
クエリ高速化を購入し、プロジェクトのコンピュートエンジンが高速化ソースにアタッチされている場合、高速化メソッドとして高速化ソースまたは MCQA のいずれかを選択できます。
現在のテナントが Hadoop コンピュートエンジンを使用している場合:クエリ高速化を購入し、プロジェクトのコンピュートエンジンのクラスターが高速化ソースにアタッチされている場合、Hive SQL、Impala SQL、および Spark SQL アドホッククエリジョブの高速化メソッドは [高速化ソース] です。
プロジェクトのコンピュートエンジン、データベース SQL タイプ、に基づいてクエリコードを記述します。
コードを記述した後、エディターの上部にある [実行] をクリックします。
クエリ文が正常に実行された後、[コンソール] で結果を表示します。
結果データのダウンロード
クエリ文が正常に実行された後、コンソールの右上隅にある
 アイコンをクリックして結果をダウンロードします。
アイコンをクリックして結果をダウンロードします。[データダウンロード] ダイアログボックスで、[ダウンロードデータ範囲] と [ダウンロードデータ形式] を選択します。
ダウンロードデータ範囲:[完全な結果セット] または [制限付き結果セット] をダウンロードできます。
[完全データダウンロード]:完全なデータセットのダウンロードには時間がかかる場合があります。 メッセージセンターまたは実行ログを表示して、ダウンロードの進行状況をモニターできます。
重要完全データダウンロードでは、クエリ文に基づいて一時テーブルが作成されます。 Hadoop コンピュートエンジン上の Spark SQL アドホッククエリの場合、完全データダウンロード用の一時テーブルは、[管理センター] > [システム設定] > [開発プラットフォーム] > [テーブル管理設定] で指定されたデフォルトのストレージ形式を使用して作成されます。
たとえば、テーブル管理設定のデフォルトのストレージ形式が [hudi] の場合、一時テーブルの作成時に
using hudi文が追加されます。 デフォルトのストレージ形式が [エンジンのデフォルト] の場合、一時テーブルの作成時にストレージ形式は 指定されません。[サンプルデータダウンロード]:デフォルトでは、すべてのクエリ文はデータのサブセットのみを返します。 返すレコード数は、[管理センター] > [標準設定] > [データダウンロード] で設定できます。 詳細については、「データダウンロードの設定」、「」をご参照ください。
[ダウンロードデータ形式]:ダウンロード範囲として [サンプルデータ] を選択した場合、ダウンロード形式として [CSV] または [Excel] を選択できます。 [完全データ] を選択した場合は、[CSV] のみ選択できます。
[OK] をクリックしてダウンロードを開始します。
ダウンロード範囲として [完全データ] を選択した場合は、[OK] をクリックしてデータ準備を開始します。 データが準備されたら、再度 [OK] をクリックして完全データダウンロードを開始します。
ダウンロード承認が有効になっている場合は、承認のために [データダウンロードリクエスト] を送信する必要があります。 リクエストが承認されると、承認タスクの表示、現在の実行結果の確認、または実行ログへのアクセスによってデータをダウンロードできます。 詳細については、「データダウンロード承認の設定」、「」をご参照ください。
データダウンロード承認でウォーターマーク機能が有効になっている場合、ダウンロードされた Excel ファイルにウォーターマークが自動的に追加されます。 ダウンロードされたデータファイルは、クエリ日から 30 日間保持されます。 たとえば、データが 2023 年 4 月 12 日にクエリされ、ダウンロードリクエストが 2023 年 4 月 13 日に行われた場合、ファイルは 2023 年 5 月 12 日に有効期限切れになります。 詳細については、「データダウンロード承認の設定」、「」をご参照ください。
付録:ジョブタイプの切り替え
このセクションは、プロジェクトがオフラインエンジンとして Hadoop コンピュートエンジンを使用し、Impala ジョブが有効になっている場合に適用されます。 Impala SQL と Hive SQL のジョブタイプを切り替えることができます。
アドホッククエリリストで、変更する Impala SQL または Hive SQL ジョブを見つけ、ジョブ名の横にある
 アイコンをクリックし、[タイプの変更] を選択します。
アイコンをクリックし、[タイプの変更] を選択します。[タイプの変更] ダイアログボックスで、新しいタイプを選択します。 次の図は、Impala SQL ジョブから Hive SQL ジョブに切り替える例を示しています。
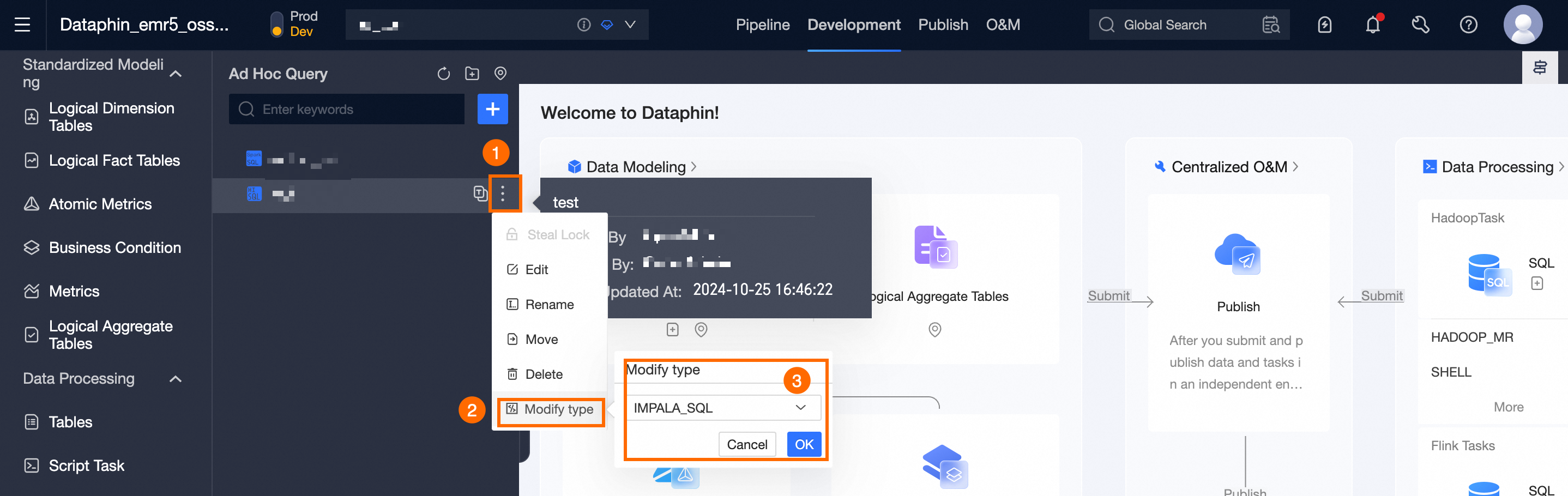
[OK] をクリックしてジョブタイプを切り替えます。