PostgreSQL 出力コンポーネントは、データを PostgreSQL データソースに書き込みます。ソースデータを構成した後、別のデータソースから PostgreSQL へデータ同期を行う際に、PostgreSQL 出力コンポーネントでターゲットの PostgreSQL データソースを構成します。本トピックでは、PostgreSQL 出力コンポーネントの構成方法について説明します。
前提条件
PostgreSQL データソースを作成しました。詳細については、「PostgreSQL データソースの作成」をご参照ください。
PostgreSQL 出力コンポーネントを構成するアカウントには、データソースに対するライトスルー権限が必要です。この権限がない場合は、申請してください。詳細については、「Request, renew, and return data source permissions」をご参照ください。
操作手順
Dataphin ホームページの上部メニューバーで、[Development] をクリックし、次に [Data Integration] をクリックします。
統合ページの上部メニューバーで、[project] を選択します。Dev-Prod モードの場合は、環境も選択します。
左側のナビゲーションウィンドウで、[Offline Integration] をクリックします。[Offline Integration] リストで、開発対象のオフラインパイプラインをクリックして、その構成ページを開きます。
ページ右上隅で、[Component Library] をクリックして、[Component Library] パネルを開きます。
[Component Library] パネルの左側ナビゲーションウィンドウで、[Output] をクリックします。右側の出力コンポーネントリストで、[PostgreSQL] コンポーネントを見つけ、キャンバス上にドラッグします。
入力ウィジェットのターゲットから
 アイコンをクリックしてドラッグし、PostgreSQL 出力ウィジェットに接続します。
アイコンをクリックしてドラッグし、PostgreSQL 出力ウィジェットに接続します。PostgreSQL 出力コンポーネントカードで、
 アイコンをクリックして、[PostgreSQL Output Configuration] ダイアログボックスを開きます。
アイコンをクリックして、[PostgreSQL Output Configuration] ダイアログボックスを開きます。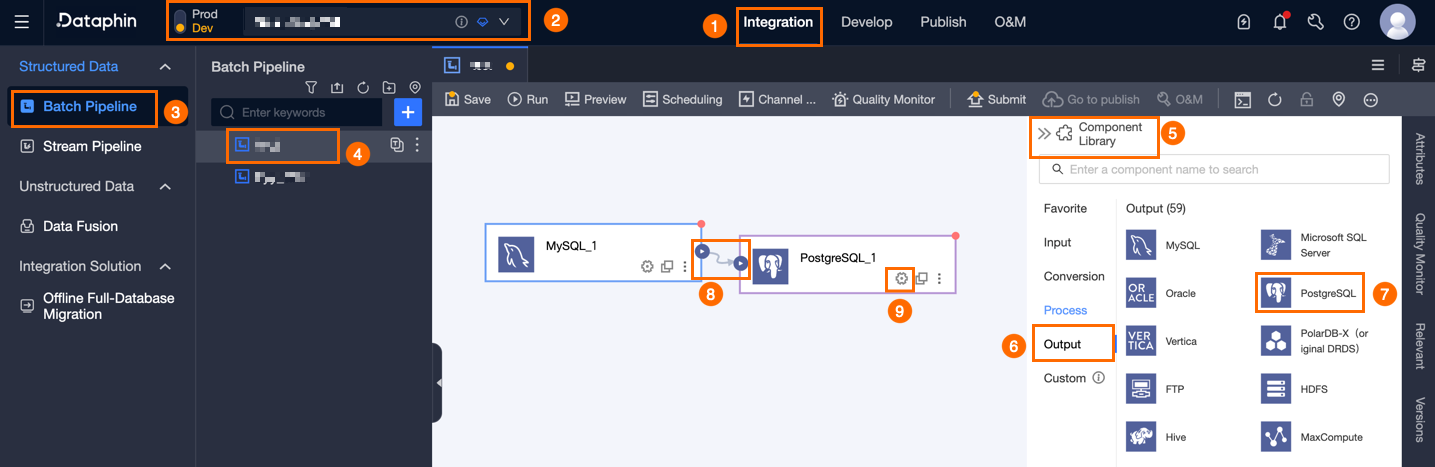
[PostgreSQL Output Configuration] ダイアログボックスで、以下のパラメーターを構成します。
パラメーター
説明
基本設定
ステップ名
PostgreSQL 出力コンポーネントの名前です。Dataphin は自動的にステップ名を生成しますが、ビジネスシナリオに応じて変更できます。命名規則は以下のとおりです。
英字、数字、アンダースコア (_)、および漢字のみ使用可能です。
64 文字以内である必要があります。
データソース
データソースのドロップダウンリストには、ライトスルー権限があるものとないものを含む、すべての PostgreSQL タイプのデータソースが表示されます。現在のデータソース名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。ライトスルー権限がないデータソースについては、その横にある [Request] をクリックして、ライトスルー権限を申請できます。詳細については、「Request data source permissions」をご参照ください。
PostgreSQL タイプのデータソースがない場合は、
 [New] アイコンをクリックして新規作成できます。詳細については、「Create a PostgreSQL data source」をご参照ください。
[New] アイコンをクリックして新規作成できます。詳細については、「Create a PostgreSQL data source」をご参照ください。
タイムゾーン
Dataphin は、現在のタイムゾーンに基づいて時刻形式のデータを処理します。デフォルトでは、選択されたデータソースに設定されているタイムゾーンが使用され、変更できません。
説明V5.1.2 より前のバージョンで作成されたタスクでは、[Data Source Default Configuration] または [Channel Configuration Time Zone] のいずれかを選択できます。デフォルトの選択肢は [Channel Configuration Time Zone] です。
データソースのデフォルト設定:選択されたデータソースのデフォルトのタイムゾーンです。
[Channel Configuration Time Zone]:現在の統合タスクの [Properties] > [Channel Configuration] で設定されたタイムゾーンです。
スキーマ(任意)
テーブルが存在するスキーマを選択すると、スキーマをまたいだテーブル選択が可能になります。指定しない場合、データソースに設定されたスキーマがデフォルトで使用されます。
テーブル
出力データのターゲットテーブルを選択します。 キーワードを入力してテーブルを検索するか、正確なテーブル名を入力して [Exact Search] をクリックできます。テーブルを選択すると、Dataphin は自動的にそのステータスをチェックします。選択したテーブル名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。MySQL データソース内にターゲットテーブルが存在しない場合、ワンクリックテーブル作成機能を使用して、ターゲットテーブルを迅速かつ簡単に作成できます。手順は以下のとおりです。
[One-Click Table Creation] をクリックします。Dataphin は、ターゲットテーブルを作成するための SQL コード(テーブル名はデフォルトでソーステーブル名、フィールドの型は Dataphin フィールドに基づいて事前に変換)を自動生成します。
ビジネスシナリオに応じて SQL スクリプトを必要に応じて修正し、[Create] をクリックします。正常に作成されると、Dataphin は自動的に新しいテーブルを出力先として設定します。
説明開発環境にすでに同じ名前のテーブルが存在する場合、[Create] をクリックするとエラーが返されます。
一致するテーブルが見つからない場合でも、手動でテーブル名を入力して続行できます。
本番テーブル不在時のポリシー
本番テーブルが存在しない場合の動作を指定します。オプションは [Do Nothing] または [Automatic Creation] です。デフォルトは [Automatic Creation] です。[Do Nothing] を選択すると、タスク公開時にテーブル作成をスキップします。[Automatic Creation] を選択すると、公開時にターゲット環境に同名のテーブルが作成されます。
[Do Nothing]:ターゲットテーブルが存在しない場合、提出時に警告が表示されますが、公開は許可されます。タスク実行前に、本番環境で手動でターゲットテーブルを作成する必要があります。
[Automatic Creation]:必ず [Edit Table Creation Statement] を実行する必要があります。システムは選択されたテーブルに基づいて文を事前に入力しますが、これを調整できます。テーブル名にはプレースホルダー
${table_name}を使用してください。これは唯一サポートされる形式です。実行時に、システムはこれを実際のテーブル名に置き換えます。ターゲットテーブルが存在しない場合、システムは提供された文を使用してテーブルの作成を試みます。作成に失敗すると、公開も失敗するため、文を修正して再公開する必要があります。テーブルがすでに存在する場合は、作成は行われません。
説明この設定は、Dev-Prod モードのプロジェクトでのみ利用可能です。
ローディングポリシー
ターゲットテーブルへのデータ書き込み方法を選択します。[Loading Policy] のオプションは以下のとおりです。
[Append Data (INSERT INTO)]:プライマリキーまたは制約違反が発生した場合、ダーティデータエラーを報告します。
[Update on Primary Key Conflict (ON CONFLICT DO UPDATE SET)]:プライマリキーまたは制約違反が発生した場合、既存レコードのマッピング済みフィールドを更新します。
同期書き込み
プライマリキー更新の構文はアトミック操作ではありません。データに重複するプライマリキーが含まれる場合は、同期書き込みを有効にしてください。それ以外の場合は、並列書き込みを使用します。同期書き込みは並列書き込みよりもパフォーマンスが低くなります。
説明このオプションは、ローディングポリシーとして [Update on Primary Key Conflict] が選択されている場合にのみ利用可能です。
バッチ書き込みデータ量(任意)
1 回のバッチで書き込まれるデータ量です。[Batch Write Record Count] も設定できます。いずれかの上限に達すると、システムはすぐにデータを書き込みます。デフォルト値は 32 MB です。
バッチ書き込みレコード数(任意)
デフォルト: 2,048 レコード。データ同期中に、Dataphin は、[バッチ書き込みレコード数] および [バッチ書き込みデータ量] の 2 つのパラメーターによって制御されるバッチ書き込み戦略を使用します。
蓄積されたデータがいずれかの上限(レコード数またはデータ量)に達すると、システムはバッチが満杯と判断し、直ちにターゲットに書き込みます。
バッチデータ量を 32 MB に設定することを推奨します。平均レコードサイズに応じてレコード数を調整し、バッチ効率を最大化してください。たとえば、各レコードが約 1 KB の場合、バッチデータ量を 16 MB、レコード数を 16,384(16 MB ÷ 1 KB)以上に設定します。20,000 レコードに設定すると、データ量に基づいて書き込みがトリガーされ、16 MB が蓄積されるたびに書き込みが実行されます。
準備文(任意)
データインポート前にデータベースで実行される SQL スクリプトです。
たとえば、サービス可用性を維持するために、データ書き込み前に一時テーブル Target_A を作成し、Target_A に書き込んだ後、稼働中のテーブル Service_B を Temp_C にリネームし、Target_A を Service_B にリネームし、最後に Temp_C を削除するといった操作が可能です。
完了文(任意)
データインポート後にデータベースで実行される SQL スクリプトです。
フィールドマッピング
入力フィールド
上流の出力に基づいて入力フィールドを表示します。
出力フィールド
出力フィールドを表示します。以下の操作が可能です。
フィールド管理: [フィールド管理] をクリックして、出力フィールドを選択します。

 アイコンをクリックして、[Selected Input Field] を [Unselected Input Fields] に移動します。
アイコンをクリックして、[Selected Input Field] を [Unselected Input Fields] に移動します。 アイコンをクリックして、[Unselected Input Field] を [Selected Input Fields] に移動します。
アイコンをクリックして、[Unselected Input Field] を [Selected Input Fields] に移動します。
一括追加: [一括追加] をクリックして、JSON、TEXT、またはDDLフォーマットでフィールドを設定します。
JSON 形式で一括構成を行います。例:
// 例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]説明nameはインポートするフィールドの名前を、typeはインポート後のフィールドのデータの型を指定します。たとえば、"name":"user_id","type":"String"は、user_idという名前のフィールドをインポートし、そのデータの型をStringに設定します。TEXT 形式の例:
// 例: user_id,String user_name,String行区切り文字はフィールドエントリを区切ります。デフォルト:改行 (\n)。サポートされるデリミタ:改行 (\n)、セミコロン (;)、ピリオド (.)。
列区切り文字はフィールド名と型を区切ります。デフォルト:カンマ (,)。
DDL 形式で複数のオブジェクトを一度に構成します。例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
出力フィールドの作成:[+ Create Output Field] をクリックし、[Column] 名を入力して、[Type] を選択します。行の構成後、
 アイコンをクリックして保存します。
アイコンをクリックして保存します。
マッピング
アップストリーム入力およびターゲットテーブルのフィールドに基づいて、フィールドを手動でマップします。[クイックマッピング]には、[行ベースのマッピング]および[名前ベースのマッピング]が含まれます。
[Name-Based Mapping]:名前が同一のフィールドをマッピングします。
[Row-Based Mapping]:ソースとターゲットのフィールド名が異なる場合、同じ行位置にあるフィールドをマッピングします。
[Confirm] をクリックして、[PostgreSQL] 出力コンポーネントのプロパティ構成を完了します。