Oracle 出力コンポーネントは、データを Oracle データソースに書き込みます。他のデータソースから Oracle データソースへデータを同期する場合、ソースデータの設定後に、Oracle 出力コンポーネントのターゲットデータソースを設定する必要があります。本トピックでは、Oracle 出力コンポーネントの設定手順について説明します。
前提条件
Oracle データソースを作成しました。詳細については、「Oracle データソースの作成」および「」をご参照ください。
Oracle 出力コンポーネントのプロパティを設定する際に使用するアカウントには、データソースに対するライトスルー権限が必要です。該当の権限が付与されていない場合は、権限の付与を依頼してください。詳細については、「データソース権限のリクエスト、更新、または返却」をご参照ください。
操作手順
Dataphin のホームページ上部のメニューバーで、R&D > データ統合 を選択します。
統合ページ上部のメニューバーで、プロジェクト を選択します。Dev-Prod モードの場合は、さらに 環境 も選択する必要があります。
左側のナビゲーションウィンドウで、オフライン統合 をクリックします。オフライン統合 一覧から、開発対象の オフラインパイプライン をクリックし、その構成ページを開きます。
ページ右上隅の コンポーネントライブラリ をクリックして、コンポーネントライブラリ パネルを開きます。
コンポーネントライブラリ パネル左側のナビゲーションウィンドウで、出力 を選択します。右側の出力コンポーネント一覧から Oracle コンポーネントを見つけ、キャンバスにドラッグします。
対象となる入力・変換・フローコンポーネントの
 アイコンをクリックしてドラッグし、Oracle 出力コンポーネントと接続します。
アイコンをクリックしてドラッグし、Oracle 出力コンポーネントと接続します。Oracle 出力コンポーネントのカード上の
 アイコンをクリックして、Oracle 出力構成 ダイアログボックスを開きます。
アイコンをクリックして、Oracle 出力構成 ダイアログボックスを開きます。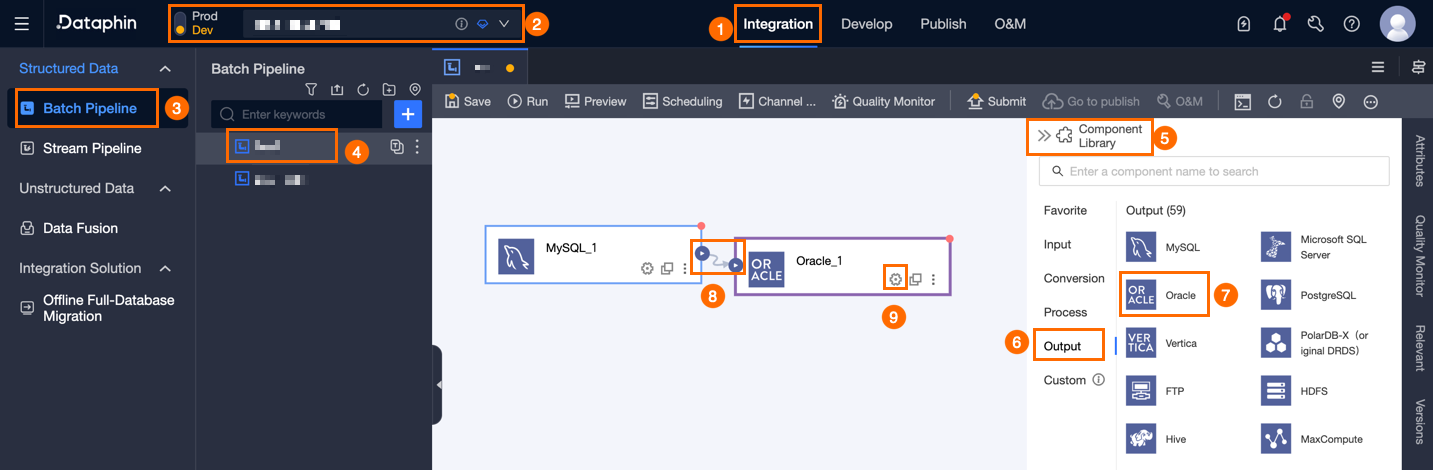
Oracle 出力構成 ダイアログボックスで、以下のパラメーターを設定します。
パラメーター
説明
基本設定
ステップ名
Oracle 出力コンポーネントの名称です。Dataphin が自動的にステップ名を生成しますが、必要に応じて変更可能です。名称は以下のルールに従う必要があります:
漢字、英字、アンダースコア (_ )、数字のみを使用できます。
最大文字数は 64 文字です。
データソース
データソースのドロップダウンリストから、データソースを選択します。このリストには、ライトスルー権限を持つものおよび持たないすべての Oracle データソースが表示されます。
 アイコンをクリックすると、現在のデータソース名をコピーできます。
アイコンをクリックすると、現在のデータソース名をコピーできます。データソースに対してライトスルー権限がない場合は、データソース横の リクエスト をクリックして権限を依頼してください。詳細については、「データソース権限のリクエスト」をご参照ください。
Oracle データソースが存在しない場合は、データソースの作成 をクリックして新規作成します。詳細については、「Oracle データソースの作成」をご参照ください。
タイムゾーン
時刻形式のデータは、現在のタイムゾーンに基づいて処理されます。デフォルトでは、選択したデータソースで設定されたタイムゾーンが適用され、変更できません。
説明バージョン 5.1.2 より前のノードで作成された場合、データソースのデフォルト設定 または チャネル構成のタイムゾーン を選択できます。デフォルトは チャネル構成のタイムゾーン です。
データソースのデフォルト設定:選択したデータソースのデフォルトタイムゾーン。
チャネル構成のタイムゾーン:プロパティ > チャネル構成 で設定された、現在の統合ノードのタイムゾーン。
スキーマ(任意)
複数のスキーマにまたがるテーブルを選択できます。テーブルが配置されているスキーマを選択します。スキーマを指定しない場合、データソースで設定されたスキーマがデフォルトで使用されます。
テーブル
出力データの対象テーブルを選択します。キーワードを入力してテーブルを検索するか、正確なテーブル名を入力して 完全一致検索 をクリックできます。テーブルを選択後、システムが自動的にそのステータスを確認します。
 アイコンをクリックすると、選択したテーブル名をコピーできます。
アイコンをクリックすると、選択したテーブル名をコピーできます。データ同期の対象テーブルが Oracle データソースに存在しない場合、ワンクリックテーブル作成機能を使用して迅速に生成できます。手順は以下のとおりです:
ワンクリックテーブル作成 をクリックします。Dataphin が対象テーブル作成用のコードを自動生成します。これには、デフォルトでソーステーブル名が採用される対象テーブル名および、Dataphin フィールドの初期変換に基づくフィールド型が含まれます。
必要に応じて SQL スクリプトを修正し、作成 をクリックします。
重要CREATE TABLEの後にテーブル名を変更しない場合、システムはデフォルトで大文字のテーブル名を生成します。CREATE TABLEの後のテーブル名を二重引用符で囲むと、テーブル名は大文字小文字を区別するようになります。
対象テーブルが作成されると、Dataphin は自動的にそれを出力データの対象テーブルとして使用します。
説明開発環境に同名のテーブルが既に存在する場合、[作成] をクリックすると「テーブルは既に存在します」というエラーが報告されます。
本番テーブルが存在しない場合のポリシー
本番テーブルが存在しない場合に適用するポリシーです。何もしない または 自動作成 を選択できます。デフォルトは 自動作成 です。何もしない を選択した場合、ノードを公開しても本番テーブルは作成されません。自動作成 を選択した場合、ノードを公開すると、ターゲット環境に同名のテーブルが作成されます。
何もしない:対象テーブルが存在しない場合、ノードを送信時にメッセージが表示されますが、公開は可能です。この場合、ノードを実行する前に、本番環境で対象テーブルを手動で作成する必要があります。
自動作成:必ず テーブル作成文の編集 を行ってください。選択したテーブルのテーブル作成文がデフォルトで入力されていますが、これを必要に応じて修正できます。テーブル作成文内のテーブル名にはプレースホルダー
${table_name}のみがサポートされています。実行時に、このプレースホルダーは実際のテーブル名に置き換えられます。対象テーブルが存在しない場合、テーブル作成文に従ってテーブルが作成されます。テーブル作成に失敗した場合、公開時のチェックでエラーが発生します。エラーメッセージに基づいてテーブル作成文を修正し、再度公開を試行できます。対象テーブルが既に存在する場合、テーブル作成文は実行されません。
説明このパラメーターは、Dev-Prod モードのプロジェクトでのみサポートされます。
読み込みポリシー
ターゲットテーブルへのデータ書き込みポリシーを選択します。
データ追加 (INSERT INTO):プライマリキーまたは制約違反が発生した場合、ダーティデータエラーが報告されます。
プライマリキー衝突時の更新 (MERGE INTO):プライマリキーまたは制約違反が発生した場合、マップされたフィールドのデータが既存レコード上で更新されます。
ライトスルー
Oracle データベースにおけるプライマリキー更新構文は原子操作ではありません。書き込み対象のデータに重複するプライマリキーが含まれる場合、ライトスルーを有効にする必要があります。それ以外の場合は並列書き込みが使用されます。ライトスルーのパフォーマンスは並列書き込みよりも低くなります。
説明このパラメーターは、ロードポリシー が プライマリキー衝突時の更新 に設定されている場合にのみサポートされます。
バッチ書き込みデータ量(任意)
1 回の操作で書き込むデータ量です。バッチ書き込み件数 も設定できます。書き込み時には、いずれかの上限に達した時点でデータが書き込まれます。デフォルト値は 32 MB です。
バッチ書き込み件数(任意)
デフォルト値は 2048 件です。データ書き込み時はバッチ書き込み戦略が採用されます。関連するパラメーターには バッチ書き込み件数 および バッチ書き込みデータ量 があります。
累積データがいずれかの設定上限に達すると、システムはバッチが満杯と判断し、即座に宛先へ書き込みます。
バッチ書き込みデータ量は 32 MB を推奨します。バッチ書き込み件数は、1 件あたりのレコードサイズに応じて調整してください。一般的に、値が大きいほど効率的です。たとえば、1 件あたりのレコードサイズが約 1 KB で、バッチ書き込みデータ量を 16 MB に設定した場合、バッチ書き込み件数は 16,384(16 MB ÷ 1 KB)より大きい値に設定することを推奨します。バッチ書き込み件数を 20,000 件に設定した場合、データ量が 16 MB に達するごとにバッチ書き込みが実行されます。
準備文(任意)
データインポート前にデータベースで実行する SQL スクリプトです。
たとえば、サービスの可用性を継続的に確保するために、現在のステップがデータを書き込む前に、ターゲットテーブル Target_A をあらかじめ作成できます。このステップでは Target_A へデータを書き込み、完了後にサービステーブル Service_B を Temp_C にリネームし、Target_A を Service_B にリネームした後、Temp_C を削除します。
終了文(任意)
データインポート後にデータベースで実行する SQL スクリプトです。
高度な構成
ログインタイムアウト
ログイン時間が指定時間以上になると、システムが自動的に切断し、エラーを報告します。単位は 秒 (s) です。デフォルト値は 600 s です。
クエリタイムアウト
クエリ時間が指定時間以上になると、システムが自動的に切断し、エラーを報告します。単位は 秒 (s) です。デフォルト値は 1800 s です。
フィールドマッピング
入力フィールド
上流コンポーネントの出力に基づいて入力フィールドが表示されます。
出力フィールド
出力フィールドが表示されます。以下の操作が可能です:
フィールドの管理:フィールドの管理 をクリックして、出力フィールドを選択します。

 アイコンをクリックすると、選択済み入力フィールド から 未選択入力フィールド へフィールドを移動できます。
アイコンをクリックすると、選択済み入力フィールド から 未選択入力フィールド へフィールドを移動できます。 アイコンをクリックすると、未選択入力フィールド から 選択済み入力フィールド へフィールドを移動できます。
アイコンをクリックすると、未選択入力フィールド から 選択済み入力フィールド へフィールドを移動できます。
一括追加:一括追加 をクリックして、JSON、TEXT、または DDL 形式でフィールドを構成します。
JSON 形式で構成する場合の例:
// 例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]説明name はインポート対象のフィールド名、type はインポート後のフィールド型を示します。たとえば、
"name":"user_id","type":"String"は、user_id という名前のフィールドをインポートし、その型を String に設定します。TEXT 形式で構成する場合の例:
// 例: user_id,String user_name,String行区切り文字は各フィールドの情報を区切ります。デフォルトは改行 (\n) ですが、セミコロン (;) やピリオド (.) もサポートされます。
列区切り文字はフィールド名とフィールド型を区切ります。デフォルトはカンマ (,) です。
DDL 形式で構成する場合の例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
出力フィールドの作成:+ 出力フィールドの作成 をクリックし、列 名を入力して、型 を選択します。現在の行の設定を完了したら、
 アイコンをクリックして保存します。
アイコンをクリックして保存します。
マッピング
上流の入力フィールドとターゲットテーブルのフィールドに基づいて、手動でフィールドをマップできます。クイックマッピング には、行単位マッピング および 名前単位マッピング があります。
名前単位マッピング:名前が一致するフィールドをマップします。
行単位マッピング:同じ行にあるフィールドをマップします。ソーステーブルとターゲットテーブルのフィールド名が異なるが、対応する行のデータをマップする必要がある場合に使用します。
確認 をクリックして、Oracle 出力コンポーネント の構成を完了します。