MySQL 出力コンポーネントは、MySQL データソースにデータを書き込みます。他のデータソースから MySQL にデータを同期する場合、ソースデータソースを設定した後に、MySQL 出力コンポーネントのターゲットデータソースを設定する必要があります。このトピックでは、MySQL 出力コンポーネントの設定方法について説明します。
前提条件
MySQL データソースが作成されていること。詳細については、「MySQL データソースの作成」をご参照ください。
MySQL 出力コンポーネントのプロパティを設定するために使用するアカウントには、データソースへのライトスルー権限が必要です。この権限がない場合は、リクエストしてください。詳細については、「データソース権限のリクエスト、更新、返却」をご参照ください。
操作手順
Dataphin のホームページで、メニューバーから [開発] > [データ統合] を選択します。
統合ページのメニューバーで、[プロジェクト] を選択します。本番・開発モードの場合は、[環境] を選択します。
左側のナビゲーションウィンドウで、[バッチパイプライン] をクリックします。[バッチパイプライン] リストで、開発したいオフラインパイプラインをクリックして、その設定ページを開きます。
ページの右上隅にある [コンポーネントライブラリ] をクリックして、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネルの左側のナビゲーションウィンドウで、[出力] を選択します。右側の出力コンポーネントのリストから [MySQL] コンポーネントを見つけ、キャンバスにドラッグします。
ターゲットの入力、変換、またはフローコンポーネントの
 アイコンをクリックしてドラッグし、MySQL 出力コンポーネントに接続します。
アイコンをクリックしてドラッグし、MySQL 出力コンポーネントに接続します。MySQL 出力コンポーネントカードの
 アイコンをクリックして、[MySQL 出力設定] ダイアログボックスを開きます。
アイコンをクリックして、[MySQL 出力設定] ダイアログボックスを開きます。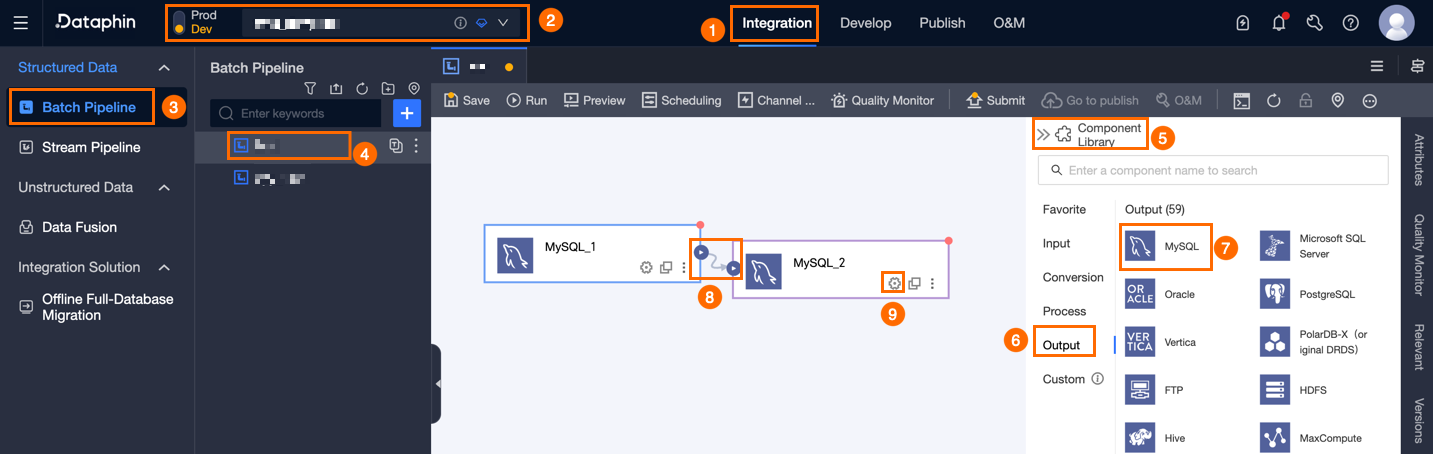
[MySQL 出力設定] ダイアログボックスで、パラメーターを設定します。
パラメーター
説明
[基本設定]
[ステップ名]
MySQL 出力コンポーネントの名前です。Dataphin は自動的にステップ名を生成しますが、必要に応じて変更することもできます。命名規則は次のとおりです:
名前には、漢字、英字、アンダースコア (_)、および数字のみ使用できます。
名前の長さは 64 文字を超えることはできません。
[データソース]
データソースのドロップダウンリストには、すべての MySQL データソースが表示されます。これには、ライトスルー権限があるものとないものの両方が含まれます。
 アイコンをクリックすると、現在のデータソース名をコピーできます。
アイコンをクリックすると、現在のデータソース名をコピーできます。ライトスルー権限がないデータソースの場合は、データソースの横にある [リクエスト] をクリックして権限をリクエストします。詳細については、「データソース権限のリクエスト、更新、返却」をご参照ください。
MySQL データソースがない場合は、[データソースの作成] をクリックして作成します。詳細については、「MySQL データソースの作成」をご参照ください。
[タイムゾーン]
時間形式のデータは、現在のタイムゾーンに基づいて処理されます。デフォルトでは、選択したデータソースで設定されているタイムゾーンが使用され、変更することはできません。
説明V5.1.2 より前に作成されたタスクでは、[デフォルトのデータソース設定] または [チャネル設定タイムゾーン] を選択できます。デフォルトの選択は [チャネル設定タイムゾーン] です。
[デフォルトのデータソース設定]:選択したデータソースのデフォルトのタイムゾーン。
[チャネル設定タイムゾーン]:[プロパティ] > [チャネル設定] で現在の統合タスクに設定されているタイムゾーン。
[データベース] (任意)
テーブルが配置されているデータベースを選択します。これを空白のままにすると、データソース登録時に指定されたデータベースが使用されます。
テーブル
データ出力のターゲットテーブルを選択します。テーブル名のキーワードを入力して検索するか、正確なテーブル名を入力して [完全一致検索] をクリックします。テーブルを選択すると、システムは自動的にテーブルの状態をチェックします。
 アイコンをクリックすると、現在選択されているテーブルの名前をコピーできます。
アイコンをクリックすると、現在選択されているテーブルの名前をコピーできます。データ同期のターゲットテーブルが MySQL データソースに存在しない場合は、ワンクリックテーブル作成機能を使用して、ターゲットテーブルを迅速に生成できます。手順は次のとおりです:
[ワンクリック DDL] をクリックします。Dataphin は、ターゲットテーブルを作成するためのコードを自動的に生成します。これには、デフォルトでソーステーブル名となるターゲットテーブル名と、Dataphin フィールドに基づいて初期変換されたフィールドタイプが含まれます。
必要に応じて、ターゲットテーブルを作成するための SQL スクリプトを変更し、[作成] をクリックします。ターゲットテーブルが作成されると、Dataphin はそれをデータ出力のターゲットテーブルとして自動的に使用します。
説明開発環境に同じ名前のテーブルが存在する場合、[作成] をクリックすると、Dataphin はテーブルが既に存在するというエラーを報告します。
一致する項目がない場合でも、手動で入力したテーブル名に基づいて統合を実行することもできます。
[本番テーブルが存在しない場合のポリシー]
本番テーブルが存在しない場合の処理ポリシーです。[何もしない] または [自動作成] を選択できます。デフォルトは [自動作成] です。[何もしない] を選択した場合、タスクが公開されても本番テーブルは作成されません。[自動作成] を選択した場合、タスクが公開されると、ターゲット環境に同じ名前のテーブルが作成されます。
[何もしない]:ターゲットテーブルが存在しない場合、タスクを送信する際にメッセージが表示されますが、タスクは引き続き公開できます。この場合、タスクを実行する前に、本番環境でターゲットテーブルを手動で作成する必要があります。
[自動作成]:[DDL 文の編集] を行う必要があります。選択したテーブルの DDL 文がデフォルトで入力され、これを調整できます。DDL 文内のテーブル名は、プレースホルダー
${table_name}を使用します。このプレースホルダーのみがサポートされており、実行時に実際のテーブル名に置き換えられます。ターゲットテーブルが存在しない場合、まず DDL 文に従って作成されます。テーブルの作成に失敗した場合、公開時のチェックに失敗します。エラーメッセージに基づいて DDL 文を修正し、再度公開することができます。ターゲットテーブルが既に存在する場合、DDL 文は実行されません。
説明このパラメーターは、本番・開発モードのプロジェクトでのみサポートされます。
読み込みポリシー
ターゲットテーブルへのデータ書き込みポリシーを選択します。[書き込みポリシー] には次のものが含まれます:
[データの追加 (insert into)]:ターゲットテーブルの既存データにデータを追加し、既存データは変更しません。プライマリキーまたは制約違反が発生した場合は、ダーティデータエラーが報告されます。
[プライマリキー競合時に上書き (replace into)]:プライマリキーまたは制約違反が発生した場合、重複するプライマリキーを持つ古いデータの行全体を削除してから、新しいデータを挿入します。
[プライマリキー競合時に更新 (on duplicate key update)]:プライマリキーまたは制約違反が発生した場合、既存のレコード上でマッピングされたフィールドのデータを更新します。
[バッチ書き込みデータ量] (任意)
1 回の操作で書き込むデータ量です。[バッチ書き込みレコード数] も設定できます。書き込み時、いずれかの制限に達するとシステムはデータを書き込みます。デフォルトは 32 MB です。
レコードのバッチ書き込み (任意)
デフォルトは [2,048] レコードです。データが同期される際、バッチ書き込みポリシーが使用されます。このポリシーのパラメーターには、[バッチ書き込みレコード数] と [バッチ書き込みデータ量] があります。
蓄積されたデータが、バッチ書き込みのデータ量またはレコード数のいずれかの設定上限に達すると、システムはバッチが満たされたと判断し、直ちにそのバッチをターゲットに書き込みます。
バッチ書き込みデータ量を 32 MB に設定します。単一レコードの実際のサイズに基づいて、一括挿入のレコード数の上限を調整できます。バッチ書き込みを最大限に活用するために、この値を大きく設定します。たとえば、単一レコードが約 1 KB の場合、一括挿入サイズを 16 MB に設定できます。次に、一括挿入のレコード数を 16 MB を 1 KB で割った値、つまり 16,384 レコードより大きい値に設定します。この例では、[20,000] レコードに設定します。この設定により、システムは一括挿入サイズに基づいてバッチ書き込み操作をトリガーします。蓄積されたデータが 16 MB に達するたびに書き込み操作が実行されます。
[準備文] (任意)
データインポート前にデータベースで実行する SQL スクリプトです。
たとえば、継続的なサービスの可用性を確保するために、現在のステップがデータを書き込む前にターゲットテーブル Target_A を作成できます。その後、ステップは Target_A にデータを書き込みます。現在のステップの書き込みが完了した後、継続的なサービスを提供しているテーブル Service_B の名前を Temp_C に変更します。次に、Target_A の名前を Service_B に変更し、最後に Temp_C を削除します。
[完了文] (任意)
データインポート後にデータベースで実行する SQL スクリプトです。
フィールド マッピング
[入力フィールド]
上流コンポーネントの出力に基づいて入力フィールドを表示します。
[出力フィールド]
出力フィールドを表示します。次の操作がサポートされています:
フィールドの管理:[フィールドの管理] をクリックして出力フィールドを選択します。

 アイコンをクリックして、[選択された入力フィールド] から [選択されていない入力フィールド] にフィールドを移動します。
アイコンをクリックして、[選択された入力フィールド] から [選択されていない入力フィールド] にフィールドを移動します。 アイコンをクリックして、[選択されていない入力フィールド] から [選択された入力フィールド] にフィールドを移動します。
アイコンをクリックして、[選択されていない入力フィールド] から [選択された入力フィールド] にフィールドを移動します。
バッチ追加:[バッチ追加] をクリックして、JSON、TEXT、または DDL 形式を使用してフィールドを一括で設定します。
JSON 形式で一括設定する場合の例:
// 例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]説明name はインポートされるフィールドの名前を示し、type はインポート後のフィールドタイプを示します。たとえば、
"name":"user_id","type":"String"は user_id という名前のフィールドをインポートし、そのタイプを String に設定します。TEXT 形式で一括設定する場合の例:
// 例: user_id,String user_name,String行区切り文字は、各フィールドの情報を区切ります。デフォルトは改行 (\n) です。セミコロン (;) とピリオド (.) もサポートされています。
列区切り文字は、フィールド名とフィールドタイプを区切ります。デフォルトはカンマ (,) です。
DDL 形式で一括設定する場合の例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
出力フィールドの作成:[+ 出力フィールドの作成] をクリックし、プロンプトに従って [列] 名を入力し、[型] を選択します。現在の行を設定した後、
 アイコンをクリックして保存します。
アイコンをクリックして保存します。
マッピング
フィールド マッピングは、上流入力とターゲット テーブルのフィールドに基づいて手動で選択できます。[マッピング]には、[行ごと]および[名前ごと]が含まれます。
名前単位:同じ名前を持つフィールドをマッピングします。
行単位:ソーステーブルとターゲットテーブルのフィールド名は異なりますが、対応する行のデータをマッピングする必要があります。同じ行のフィールドのみがマッピングされます。
[確認] をクリックして、[MySQL] 出力コンポーネントのプロパティ設定を完了します。