MaxCompute 出力コンポーネントは、データを MaxCompute データソースに書き込みます。他のデータソースから MaxCompute へデータを同期する際は、ソースデータソースの設定後にこのコンポーネントを設定します。
操作手順
Dataphin ホームページの上部のメニューバーで、[開発] > [データ統合] をクリックします。
[Integration] ページで、上部メニューバーから [Project] を選択します。Dev-Prod モードの場合は、環境も選択します。
左側のナビゲーションウィンドウで [Batch Pipeline] をクリックします。[Batch Pipeline] リストで、開発対象のオフラインパイプラインをクリックすると、パイプライン構成ページが開きます。
ページ右上隅の [Component Library] をクリックして、[Component Library] パネルを開きます。
[Component Library] パネルの左側ナビゲーションウィンドウで [Output] をクリックします。右側の出力コンポーネントリストで [MaxCompute] コンポーネントを見つけ、キャンバス上にドラッグします。
入力コンポーネントの
 アイコンをクリックしてドラッグし、MaxCompute 出力コンポーネントに接続します。
アイコンをクリックしてドラッグし、MaxCompute 出力コンポーネントに接続します。MaxCompute 出力コンポーネントカード内の
 アイコンをクリックして、[MaxCompute Output Configuration] ダイアログボックスを開きます。
アイコンをクリックして、[MaxCompute Output Configuration] ダイアログボックスを開きます。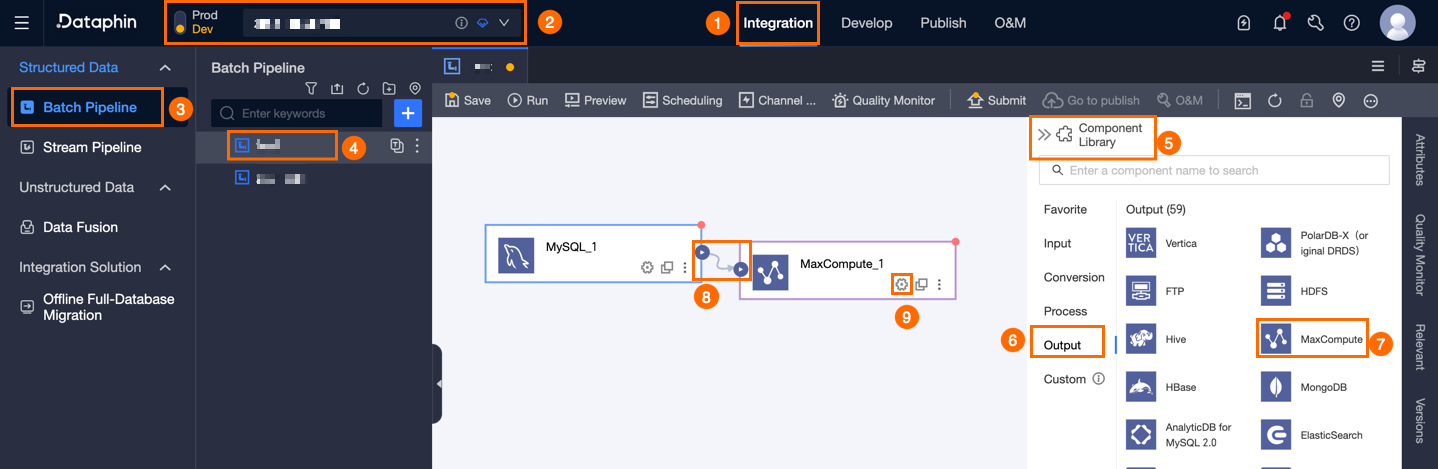
[MaxCompute Output Configuration] ダイアログボックスで、パラメーターを設定します。
パラメーター
説明
基本設定
ステップ名
MaxCompute 出力コンポーネントの名前です。Dataphin によりデフォルト名が生成されます。ビジネス要件に応じて変更できます。命名ルールは以下のとおりです。
中国語文字、英字、アンダースコア (_)、数字のみ使用可能です。
名前の長さは 64 文字以内にしてください。
データソース
このドロップダウンリストには、すべての MaxCompute データソースが表示されます。同期書き込み権限があるものとないものが含まれます。
 アイコンをクリックすると、現在のデータソース名をコピーできます。
アイコンをクリックすると、現在のデータソース名をコピーできます。データソースに対する同期書き込み権限がない場合は、そのデータソースの横にある [Request] をクリックして、同期書き込み権限をリクエストしてください。詳細については、「データソース権限のリクエスト、更新、または解放」をご参照ください。
MaxCompute データソースが存在しない場合は、[Create Data Source] をクリックして作成してください。詳細については、「MaxCompute データソースの作成」をご参照ください。
テーブル
出力データのターゲットテーブルを選択します。MaxCompute データソース内にターゲットテーブルが存在しない場合は、[One-click Generate Target Table] 機能を使用して迅速に作成できます。手順は以下のとおりです。
[ワンクリックでテーブルを作成] をクリックします。
[Standard Table] または [Delta Table] を選択します。デフォルトでは [Standard Table] が選択されています。テーブル形式を切り替えると、下記のコードエリア内の DDL が更新されます。
Dataphin はターゲットテーブルを作成する SQL スクリプトを自動生成します。これにはテーブル名(デフォルトはソーステーブル名)およびフィールドタイプ(Dataphin フィールドから変換)が含まれます。必要に応じてスクリプトを調整し、[Create] をクリックします。作成後、Dataphin は新しいテーブルを出力先として使用します。
[Production Table Missing Policy]
本番テーブルが存在しない場合のポリシーを指定します。[Take No Action] または [Automatic Creation] を選択できます。デフォルトは [Automatic Creation] です。[Take no action] を選択した場合、タスク公開時に本番テーブルは作成されません。[Automatic creation] を選択した場合、タスク公開時にターゲット環境に同名のテーブルが作成されます。
[No Action]:ターゲットテーブルが存在しない場合、システムは送信時に警告を表示しますが、公開は許可されます。タスク実行前に、本番環境で手動でターゲットテーブルを作成する必要があります。
[Automatic Creation]:事前に [Edit Table Creation Statement] が必要です。ステートメントには選択したテーブルのテーブル作成文が事前に入力されており、調整可能です。ステートメント内のテーブル名にはプレースホルダー
${table_name}を使用し、サポートされるプレースホルダーはこれのみです。実行時に実際のテーブル名に置き換えられます。ターゲットテーブルが存在しない場合、Dataphin はまずテーブル作成ステートメントを実行します。作成に失敗した場合は、公開も失敗します。エラーメッセージをもとにステートメントを修正し、再度公開してください。ターゲットテーブルがすでに存在する場合は、作成処理は行われません。
説明この設定は、Dev-Prod モードのプロジェクトにのみ適用されます。
読み込みポリシー
ターゲット MaxCompute データソースへのデータ書き込み方法を選択します。オプションは上書きと追加です。ユースケースは以下のとおりです。
[Overwrite]:ターゲットテーブル内の既存データを、現在のソーステーブルからのデータで置き換えます。
[Append]:既存データを変更せずに、ターゲットテーブルに新しいデータを追加します。標準テーブルでのみ利用可能です。
[Update]:プライマリキーの競合が発生した場合、既存レコードのマッピングされたフィールドを更新します。Delta テーブルでのみ利用可能です。
パーティション
パーティションテーブルを選択した場合、パーティションを入力します。例:
ds=20230101またはds=${bizdate}。パーティションの前にキーワード
/*dynamic*/を追加すると、各行のデータについてソースフィールドに基づいて書き込みパーティションを動的に指定できます。例:/*dynamic*/ds=$date(dateはソースフィールド名)、または/*dynamic*/ds=${bizdate},hh = $hour(bizdateはパラメーター、hourはソーステーブルのフィールド名)。重要動的パーティションの上限は 10,000 です。実行時間の長期化や失敗を避けるため、1,000 以下にすることを推奨します。
[Preparation Statement] (オプション)
データインポート前にデータベースで実行される SQL スクリプトです。
たとえば、サービスの可用性を維持するために、次の手順を実行できます。まず、ターゲットテーブル Target_A を作成します。次に、Target_A にデータを書き込みます。書き込み完了後、稼働中のサービステーブル Service_B を Temp_C にリネームします。その後、Target_A を Service_B にリネームし、最後に Temp_C を削除します。
[Finalization Statement] (オプション)
データインポート後にデータベースで実行される SQL スクリプトです。
フィールドマッピング
入力フィールド
上流コンポーネントからの入力フィールドを表示します。
出力フィールド
選択したテーブルのすべてのフィールドを一覧表示します。一部のフィールドを下流に送信しないようにするには、それらを削除します。
少数のフィールドを削除するには、[アクション] 列の
 アイコンをクリックして、不要なフィールドを削除できます。
アイコンをクリックして、不要なフィールドを削除できます。多数のフィールドを削除する場合は、[Field Management] をクリックします。[Field Management] ページで複数のフィールドを選択し、
 アイコンをクリックして [Selected Input Fields] を [Unselected Input Fields] に移動します。
アイコンをクリックして [Selected Input Fields] を [Unselected Input Fields] に移動します。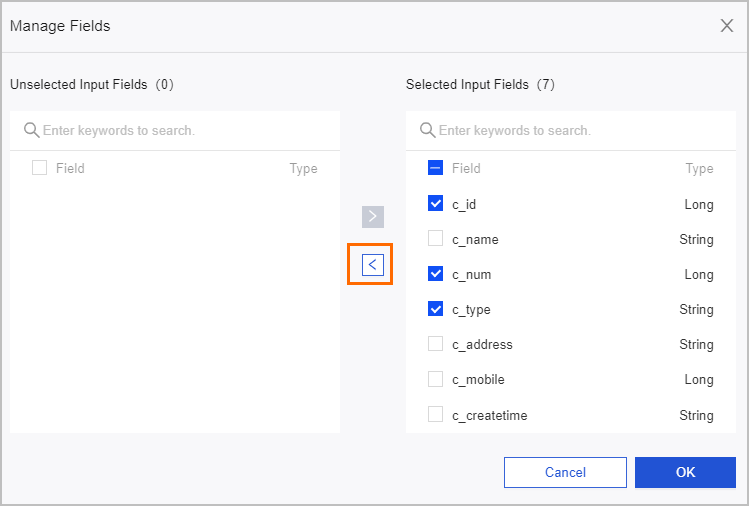
[Mapping]
ソーステーブルの入力フィールドをターゲットテーブルの出力フィールドにマッピングします。以下の 2 種類のマッピングがサポートされています。
名前ベースのマッピング:同じ名前のフィールドをマッピングします。
行ベースのマッピング:ソースとターゲットのフィールド名が異なる場合、位置に基づいてマッピングします。
[Confirm] をクリックして、[MaxCompute] 出力コンポーネントの設定を完了します。