PolarDB 出力コンポーネントは、データを PolarDB データソースに書き込みます。他のデータソースから PolarDB へデータを同期する場合、PolarDB 出力コンポーネントをターゲットとして設定します。本トピックでは、PolarDB 出力コンポーネントの設定方法について説明します。
前提条件
PolarDB データソースが作成されました。詳細については、「PolarDB データソースを作成する」をご参照ください。
PolarDB 出力コンポーネントの設定に使用するアカウントが、該当データソースに対してライトスルー権限を持っている必要があります。権限がない場合は、事前に申請してください。詳細については、「データソース権限の申請・更新・返却」をご参照ください。
操作手順
Dataphin のホームページ上部のメニューバーで、[開発] > [データ統合] を選択します。
「データ統合」ページで、[プロジェクト] を選択します。Dev-Prod モードを使用している場合は、さらに [環境] も選択する必要があります。
左側のナビゲーションウィンドウで、[バッチパイプライン] をクリックします。[バッチパイプライン] リストで、編集するオフラインパイプラインをクリックして、その構成ページを開きます。
ページ右上隅の [コンポーネントライブラリ] をクリックして、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネルの左側ナビゲーションウィンドウで、[出力] を選択します。右側の一覧から [PolarDB] コンポーネントを見つけ、キャンバスにドラッグします。
ソース、変換、またはフローの各コンポーネントの
 アイコンから、PolarDB 出力コンポーネントまで線をドラッグして接続します。
アイコンから、PolarDB 出力コンポーネントまで線をドラッグして接続します。PolarDB 出力コンポーネントのカード上の
 アイコンをクリックして、[PolarDB 出力構成] ダイアログボックスを開きます。
アイコンをクリックして、[PolarDB 出力構成] ダイアログボックスを開きます。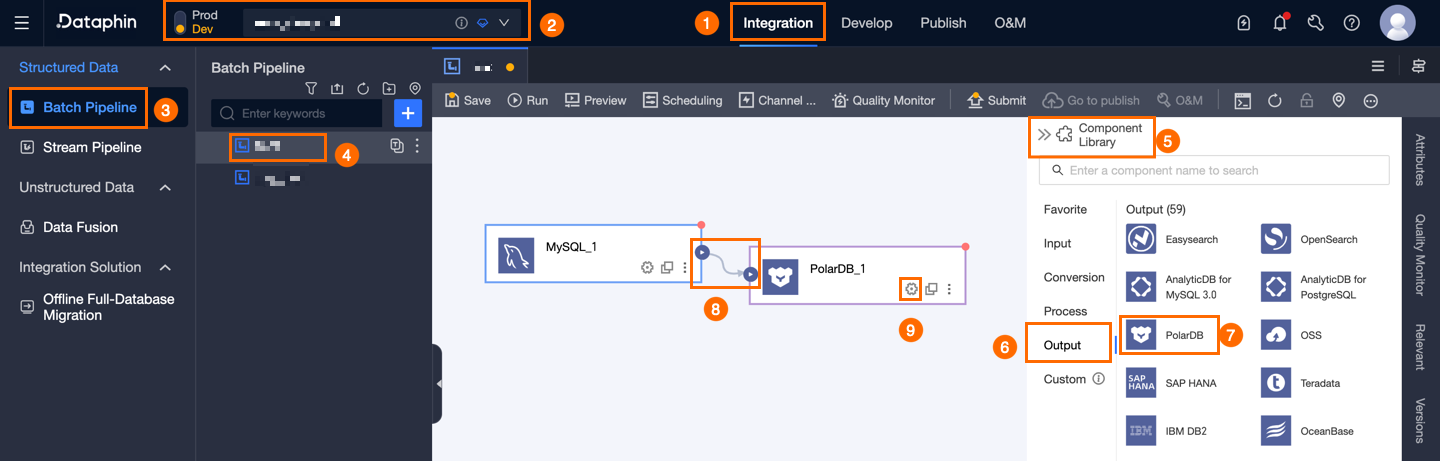
[PolarDB 出力構成] ダイアログボックスで、パラメーターを設定します。
パラメーター
説明
[基本設定]
ステップ名
PolarDB 出力コンポーネントの名称です。Dataphin が自動的にステップ名を生成しますが、必要に応じて変更可能です。命名規則は以下のとおりです:
英字、アンダースコア (_ )、数字のみ使用可能。
最大 64 文字まで。
[データソース]
データソースのドロップダウンリストには、ライトスルー権限を持つ PolarDB データソースおよび権限を持たないデータソースがすべて表示されます。
 アイコンをクリックすると、現在選択中のデータソース名をコピーできます。
アイコンをクリックすると、現在選択中のデータソース名をコピーできます。ライトスルー権限を持たないデータソースについては、該当データソース横の [申請] をクリックして権限を申請してください。詳細については、「データソース権限の申請・更新・返却」をご参照ください。
PolarDB データソースが存在しない場合は、[データソースの作成] をクリックして新規作成してください。詳細については、「PolarDB データソースの作成」をご参照ください。
タイムゾーン
コンポーネントは、現在のタイムゾーンに基づいて時刻形式のデータを処理します。デフォルトでは、選択したデータソースからタイムゾーンを継承し、変更できません。
説明V5.1.2 より前のバージョンで作成されたノードの場合、[データソースのデフォルト構成] または [チャネル構成のタイムゾーン] を選択できます。デフォルトでは [チャネル構成のタイムゾーン] が選択されています。
[データソースのデフォルト構成]:選択したデータソースのデフォルトタイムゾーン。
[チャネル構成のタイムゾーン]:現在の統合ノードの「プロパティ」>「チャネル構成」で設定されたタイムゾーン。
表
出力データのターゲットテーブルを選択します。 キーワードを入力してテーブルを検索するか、正確なテーブル名を入力して [完全一致] をクリックします。テーブルを選択後、システムが自動的にテーブルの状態を確認します。
 アイコンをクリックすると、選択したテーブル名をコピーできます。
アイコンをクリックすると、選択したテーブル名をコピーできます。読み込みポリシー
ターゲットテーブルへのデータ書き込みポリシーを選択します。[ロードポリシー] のオプションは以下のとおりです:
[データ追加]:既存のデータを変更せずに、ターゲットテーブルにデータを追加します。プライマリキーまたは制約違反が発生した場合、ダーティデータエラーが報告されます。
[データ上書き]:プライマリキーまたは制約違反が発生した場合、重複するプライマリキーを持つ既存の行を削除し、新しい行を挿入します。
説明ロードポリシーは PostgreSQL プロトコルでは適用されません。
[バッチ書き込みサイズ](任意)
単一バッチで書き込むデータ量です。[バッチ書き込みレコード数] も設定可能です。いずれかの上限に達した時点で、システムがデータを書き込みます。デフォルト値は 32 MB です。
一括書き込みレコード (任意)
デフォルト値は 2048 レコードです。データはバッチ単位で書き込まれ、バッチサイズは [バッチ書き込みレコード数] および [バッチ書き込みサイズ] によって決定されます。
累積データがレコード数上限またはサイズ上限のいずれかに達した時点で、バッチが宛先に書き込まれます。
パフォーマンス向上のため、大きなバッチサイズを設定することを推奨します。たとえば、1 レコードあたり約 1 KB の場合、バッチサイズを 16 MB に設定し、バッチレコード数を 16,384(16 MB ÷ 1 KB)より大きい値(例:20,000)に設定します。この構成では、累積データが 16 MB に達するごとにバッチが書き込まれます。
[プリペアドステートメント](任意)
データインポート前にデータベース上で実行する SQL スクリプトです。
たとえば、サービスの可用性を確保するために、書き込みステップの前に一時的なターゲットテーブル `Target_A` を作成できます。データは `Target_A` に書き込まれます。書き込みステップ完了後、本番テーブル `Service_B` を `Temp_C` にリネームし、`Target_A` を `Service_B` にリネームしてから `Temp_C` を削除します。
投稿ステートメント (オプション)
データインポート後にデータベース上で実行する SQL スクリプトです。
フィールド マッピング
入力フィールド
上流ソースからの入力フィールドを表示します。
[出力フィールド]
出力フィールドを表示します。以下の操作がサポートされています:
フィールド管理: [フィールド管理] をクリックして出力フィールドを選択します。

 アイコンをクリックして、[選択済み入力フィールド] から [未選択入力フィールド] へフィールドを移動します。
アイコンをクリックして、[選択済み入力フィールド] から [未選択入力フィールド] へフィールドを移動します。 アイコンをクリックして、[未選択の入力フィールド] から [選択済みの入力フィールド] へフィールドを移動します。
アイコンをクリックして、[未選択の入力フィールド] から [選択済みの入力フィールド] へフィールドを移動します。
一括追加: [一括追加] をクリックして、JSON、TEXT、DDL 形式でフィールドを一括設定します。
JSON 形式で設定する場合、以下の例を参考にしてください:
// 例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]説明`name` はインポート対象のフィールド名、`type` はインポート後のデータの型を指定します。たとえば、
"name":"user_id","type":"String"は、`user_id` という名前のフィールドをインポートし、そのデータ型を String に設定します。TEXT 形式で設定する場合、以下の例を参考にしてください:
// 例: user_id,String user_name,String各行はフィールドごとの情報を区切ります。デフォルトの行区切り文字は改行 (\n) ですが、セミコロン (;) やピリオド (.) も使用可能です。
列区切り文字はフィールド名とフィールド型を区切ります。デフォルトはカンマ (,) です。
DDL 形式で設定する場合、以下の例を参考にしてください:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
出力フィールドの作成: [+出力フィールドの作成] をクリックします。[列] 名を入力し、プロンプトに従って [型] を選択します。行の設定が完了したら、
 アイコンをクリックして保存します。
アイコンをクリックして保存します。
マッピング
上流ソースとターゲットテーブル間のフィールドを手動でマッピングします。[マッピング] のオプションは [同一行マッピング] および [同一名称マッピング] です。
同一名称マッピング:名称が一致するフィールドをマッピングします。
同一行マッピング:フィールドの行位置に基づいてマッピングします。ソースとターゲットのフィールド名が異なるが、順序が同じ場合に使用します。
[確認] をクリックして、[PolarDB] 出力コンポーネントの構成を保存します。