OceanBase 出力コンポーネントは、データを OceanBase データソースに書き込むことを目的として設計されています。他のデータソースから OceanBase データソースへデータを同期する場合、ソースデータ情報の設定後に、OceanBase 出力コンポーネント内でターゲットデータソースのプロパティを構成する必要があります。本トピックでは、OceanBase 出力コンポーネントの構成手順について説明します。
前提条件
OceanBase データソースが既に作成済みである必要があります。詳細については、「OceanBase データソースの作成」をご参照ください。
OceanBase 出力コンポーネントのプロパティを構成するには、データソースに対するライトスルー権限を持つアカウントが必要です。必要な権限が付与されていない場合は、データソース管理者から権限を取得してください。詳細については、「データソース権限の申請・更新・返却」をご参照ください。
操作手順
Dataphin のホームページで、上部メニューバーから 開発 > データ統合 を選択します。
統合ページの上部のメニューバーで、[プロジェクト] (Dev-Prod モードでは [環境]) を選択します。
左側のナビゲーションウィンドウで、[Batch Pipeline] をクリックします。次に、[Batch Pipeline] リストで、開発する オフラインパイプライン を選択して、その構成ページにアクセスします。
右上隅にある コンポーネントライブラリ をクリックして、コンポーネントライブラリ パネルを開きます。
コンポーネントライブラリ パネルの左側ナビゲーションウィンドウで 出力 を選択します。その後、右側の出力コンポーネント一覧から OceanBase コンポーネントを探し、キャンバス上にドラッグ&ドロップします。
対象の入力コンポーネント、変換コンポーネント、またはフローコンポーネントと OceanBase 出力コンポーネントを接続するには、
 アイコンをクリックしてドラッグします。
アイコンをクリックしてドラッグします。「[OceanBase 出力設定]」ダイアログボックスを開くには、OceanBase 出力コンポーネントカードの
 アイコンをクリックします。
アイコンをクリックします。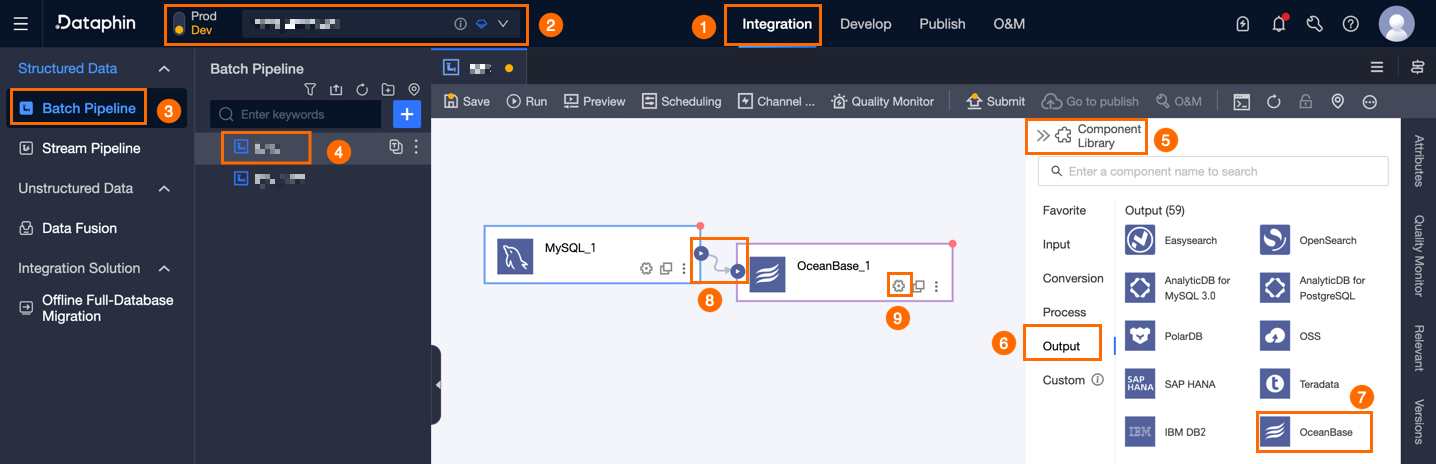
OceanBase 出力構成 ダイアログボックスで、必要なパラメーターを設定します。
パラメーター
説明
基本設定
ステップ名
OceanBase 出力コンポーネントの名前です。Dataphin が自動的にステップ名を生成しますが、ビジネスシナリオに応じて変更することもできます。命名規則は以下のとおりです:
使用可能な文字は、漢字、英字、アンダースコア (_)、数字のみです。
最大長は 64 文字です。
データソース
データソースのドロップダウンリストには、ライトスルー権限を持つ OceanBase 型データソースおよび権限を持たないデータソースがすべて表示されます。現在のデータソース名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。ライトスルー権限を持たないデータソースの場合、データソース名の横にある 申請 をクリックして、ライトスルー権限を申請できます。詳細については、「データソース権限の申請」をご参照ください。
OceanBase 型のデータソースが存在しない場合は、データソースの作成 をクリックして新規作成します。詳細については、「OceanBase データソースの作成」をご参照ください。
テーブル
出力データの対象テーブルを選択します。 テーブル名のキーワードを入力して検索するか、正確なテーブル名を入力して 完全一致検索 をクリックします。テーブルを選択すると、システムが自動的にテーブルの状態をチェックします。現在選択中のテーブル名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。OceanBase のロードポリシーはモードによって異なります。各モードのポリシーは以下のとおりです:
Oracle モードでは、追加モード のみがサポートされます。プライマリキーまたは制約違反が発生した場合、ダーティデータエラーが通知されます。プライマリキーまたは制約違反が発生しない場合は、新規データが直接追加されます。
OceanBase の MySQL モード。
追加ポリシー:プライマリキーまたは制約違反が発生しない場合、新規データが直接追加されます。
上書きポリシー:プライマリキーまたは制約違反が発生した場合、新規値が旧値を上書きします(フィールド単位の上書きであり、書き込み対象のフィールドのみが上書きされます)。
バッチ書き込みデータ量(任意)
一度に書き込まれるデータ量です。バッチ書き込み件数 も設定できます。書き込み処理中は、この 2 つの設定のうち、先に達成された制限値に基づいて書き込みが実行され、デフォルト値は 32 MB です。
バッチ書き込み件数(任意)
デフォルト値は 2048 行 です。データ同期書き込みでは、バッチ書き込み件数 および バッチ書き込みデータ量 のパラメーターを含むバッチ書き込み戦略が採用されます。
累積データ量がいずれかの設定値(バッチ書き込みデータ量またはバッチ書き込み件数)に達すると、そのバッチが満了と見なされ、即座にターゲット先へ一括書き込みされます。
バッチ書き込みデータ量は、推奨値として 32 MB を設定することを推奨します。バッチ挿入件数の上限については、単一レコードの実際のサイズに応じて柔軟に調整できます。通常は、バッチ書き込みの利点を十分に活用するために大きな値を設定します。たとえば、単一レコードのサイズが約 1 KB の場合、バッチ挿入バイト数を 16 MB に設定できます。この条件を踏まえて、バッチ挿入件数は「16 MB ÷ 1 KB(=16384 行)」より大きい値に設定します。ここでは、20000 行 に設定したものと仮定します。この構成により、システムはバッチ挿入バイト数に基づいてバッチ書き込みをトリガーし、累積データ量が 16 MB に達するごとに書き込み処理を実行します。
Prepare Statement(任意)
データインポート前にデータベース上で実行される SQL スクリプトです。
たとえば、サービスの継続的な可用性を確保するため、現在のステップによるデータ書き込み前に、まずターゲットテーブル Target_A を作成し、Target_A への書き込みを実行します。現在のステップによるデータ書き込み後、データベース内で継続的にサービスを提供しているテーブル Service_B を Temp_C にリネームします。その後、Target_A を Service_B にリネームし、最後に Temp_C を削除します。
End Statement(任意)
データインポート後にデータベース上で実行される SQL スクリプトです。
フィールドマッピング
入力フィールド
入力フィールドは、上流コンポーネントの出力に基づいて表示されます。
出力フィールド
出力フィールドが表示されます。以下の操作が可能です:
フィールド管理: [フィールド管理] をクリックして、出力フィールドを選択します。

 アイコンを クリックして、[選択済み入力フィールド] を [未選択入力フィールド] へ移動します。
アイコンを クリックして、[選択済み入力フィールド] を [未選択入力フィールド] へ移動します。 アイコンを クリックして、[未選択入力フィールド] を [選択済み入力フィールド] へ移動します。
アイコンを クリックして、[未選択入力フィールド] を [選択済み入力フィールド] へ移動します。
一括追加: 一括追加 をクリックします。JSON、TEXT、DDL 形式の一括構成がサポートされます。
JSON 形式の一括構成の例:
// 例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]説明`name` はインポート対象フィールドの名前を指定し、`type` はインポート後のフィールドのデータの型を指定します。たとえば、
"name":"user_id","type":"String"は、`user_id` という名前のフィールドをインポートし、そのデータの型を String に設定します。TEXT 形式の一括構成の例:
// 例: user_id,String user_name,String行区切り文字は、各フィールドの情報を区切るために使用されます。デフォルトは改行 (\n) ですが、改行 (\n)、セミコロン (;)、またはピリオド (.) を使用できます。
列区切り文字は、フィールド名とフィールドの型を区切るために使用され、デフォルトはカンマ (,) です。
DDL 形式の一括構成の例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
出力フィールドの作成: +出力フィールドの作成 をクリックし、画面の指示に従って カラム を入力し、型 を選択します。現在の行の構成を完了したら、
 アイコンをクリックして保存します。
アイコンをクリックして保存します。
マッピング
上流からの入力とターゲットテーブルのフィールドに基づき、手動でフィールドマッピングを選択できます。マッピング には 行マッピング と 同名マッピング があります。
同名マッピング:フィールド名が同一のフィールドをマッピングします。
行マッピング:ソーステーブルとターゲットテーブルのフィールド名が一致しないものの、対応する行のデータをマッピングする必要がある場合に使用します。同一行内のフィールドのみをマッピングします。
確認 をクリックして、OceanBase 出力コンポーネント のプロパティ構成を確定します。