SAP HANA 出力コンポーネントは、SAP HANA データソースへのデータ書き込みを可能にします。他のデータソースから SAP HANA へデータを同期する場合、SAP HANA 出力コンポーネントのターゲットデータソース設定を構成する必要があります。本トピックでは、この構成手順について説明します。
前提条件
SAP HANA データソースが作成されました。詳細については、「SAP HANA データソースの作成」をご参照ください。
SAP HANA 出力コンポーネントのプロパティを構成するには、アカウントが当該データソースに対してライトスルー権限を有している必要があります。必要な権限がない場合は、データソース管理者から権限を取得してください。詳細については、「データソース権限のリクエスト、更新、返却」をご参照ください。
操作手順
Dataphin のホームページ上部のメニューバーから、[開発] > [データ統合] を選択します。
統合ページ上部のメニューバーで、[プロジェクト] を選択します(Dev-Prod モードの場合は、環境を選択する必要があります)。
左側のナビゲーションウィンドウで、[バッチパイプライン] をクリックします。[バッチパイプライン] の一覧から、開発対象の [オフラインパイプライン] を選択し、その構成ページにアクセスします。
[コンポーネントライブラリ] パネルを開くには、ページ右上隅にある [コンポーネントライブラリ] をクリックします。
[コンポーネントライブラリ] パネル左側のナビゲーションウィンドウで、[出力] を選択します。右側の一覧から [SAP HANA] コンポーネントを見つけ、キャンバスにドラッグします。
入力コンポーネントと SAP HANA 出力コンポーネントを接続するには、
 アイコンをクリックしてドラッグします。
アイコンをクリックしてドラッグします。SAP HANA 出力コンポーネント上で
 アイコンをクリックし、[SAP HANA 出力構成] ダイアログボックスを開きます。
アイコンをクリックし、[SAP HANA 出力構成] ダイアログボックスを開きます。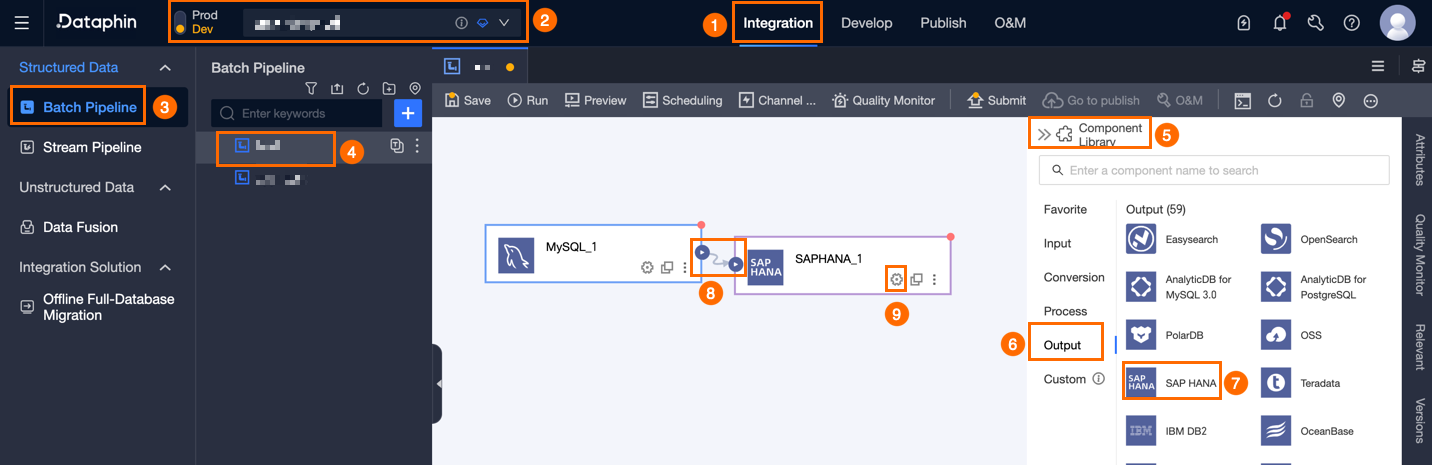
[SAP HANA 出力構成] ダイアログボックスで、必要なパラメーターを設定します。
パラメーター
説明
[基本設定]
ステップ名
これは SAP HANA 出力コンポーネントの名称です。Dataphin が自動的にステップ名を生成しますが、ビジネスシナリオに応じて変更することもできます。命名規則は以下のとおりです:
使用可能な文字は、漢字、英字、アンダースコア (_)、数字のみです。
最大長は 64 文字です。
[データソース]
データソースのドロップダウンリストには、ライトスルー権限を持つものおよび持たないものを含むすべての SAP HANA 型データソースが表示されます。現在のデータソース名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。ライトスルー権限を持たないデータソースの場合は、データソース名の後に [リクエスト] をクリックして、当該データソースのライトスルー権限をリクエストできます。具体的な操作方法については、「データソース権限のリクエスト」をご参照ください。
SAP HANA 型データソースが存在しない場合は、
 新規作成アイコンをクリックしてデータソースを作成します。具体的な操作方法については、「SAP HANA データソースの作成」をご参照ください。
新規作成アイコンをクリックしてデータソースを作成します。具体的な操作方法については、「SAP HANA データソースの作成」をご参照ください。
[スキーマ](任意)
スキーマを選択できます。未選択の場合、デフォルトでユーザー名と同じ名前のスキーマが使用されます。
テーブル
出力データのターゲットテーブルを選択します。 テーブル名のキーワードを入力して検索するか、正確なテーブル名を入力して [完全一致検索] をクリックできます。テーブルを選択すると、システムが自動的にテーブルの状態をチェックします。現在選択中のテーブル名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。読み込みポリシー
フィールドのローディングポリシーを選択します。システムでは、[データ追加] および [データ上書き] のポリシーがサポートされています。
[データ追加]:プライマリキーまたは制約違反が発生した場合、システムがダーティデータエラーを通知します。
[データ上書き]:プライマリキーまたは制約違反が発生した場合、システムはまず既存のデータを削除し、その後新しいデータ行全体を挿入します。
[バッチ書き込みデータ量](任意)
一度に書き込むデータ量です。また、[バッチ書き込み件数] も設定できます。書き込み処理中は、両方の設定値のうち、先に達成された制限に基づいて書き込みが実行されます。デフォルト値は 32 MB です。
[バッチ書き込み件数](任意)
デフォルト値は 2048 件 です。データ同期書き込みでは、バッチ書き込み戦略が採用されます。設定可能なパラメーターには、[バッチ書き込み件数] および [バッチ書き込みデータ量] があります。
累積データ量がいずれかの設定上限(すなわち、バッチ書き込みデータ量またはバッチ書き込み件数の上限)に達した場合、システムはその時点でバッチを完了と見なし、即座に一括でターゲット先に書き込みます。
バッチ書き込みデータ量は、推奨値として 32 MB を設定することを推奨します。バッチ挿入件数の上限については、単一レコードの実際のサイズに応じて柔軟に調整できます。バッチ書き込みの利点を十分に活用するため、通常は大きな値を設定します。たとえば、単一レコードのサイズが約 1 KB の場合、バッチ挿入データ量を 16 MB に設定できます。この条件を踏まえ、バッチ挿入件数は「16 MB ÷ 1 KB(=16384 件)」より大きい値に設定することを推奨します。ここでは、例として 20000 件 に設定したものと仮定します。この設定により、システムはバッチ挿入データ量に基づいてバッチ書き込みをトリガーします。累積データ量が 16 MB に達するごとに、書き込み操作が実行されます。
[準備ステートメント](任意)
データインポート前にデータベース上で実行される SQL スクリプトです。
たとえば、サービスの継続的な可用性を確保するために、現在のステップによるデータ書き込み前に、まずターゲットテーブル Target_A を作成し、Target_A への書き込みを実行します。その後、データベース内で継続的にサービスを提供しているテーブル Service_B を Temp_C にリネームし、Target_A を Service_B にリネームし、最後に Temp_C を削除します。
[終了ステートメント](任意)
データインポート後にデータベース上で実行される SQL スクリプトです。
フィールドマッピング
入力フィールド
上流コンポーネントの出力に基づいて入力フィールドが表示されます。
[出力フィールド]
出力フィールドが表示されます。以下の操作が可能です:
フィールド管理:[フィールド管理] をクリックして出力フィールドを選択します。

 アイコンをクリックして、選択済み入力フィールドを未選択入力フィールドに移動します。
アイコンをクリックして、選択済み入力フィールドを未選択入力フィールドに移動します。 アイコンをクリックして、未選択入力フィールドを選択済み入力フィールドに移動します。
アイコンをクリックして、未選択入力フィールドを選択済み入力フィールドに移動します。
一括追加: [一括追加] をクリックすると、JSON、プレーンテキスト、DDL 形式での一括構成が可能です。。
JSON 形式での一括構成の例:
// 例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]説明name はインポート対象フィールドの名称を指定し、type はインポート後のフィールドのデータの型を指定します。たとえば、
"name":"user_id","type":"String"は、user_id という名前のフィールドをインポートし、そのデータの型を String に設定します。プレーンテキスト形式での一括構成の例:
// 例: user_id,String user_name,String行区切り文字は、各フィールドの情報を区切るために使用されます。デフォルトは改行 (\n) ですが、改行 (\n)、セミコロン (;)、またはピリオド (.) をサポートします。
列区切り文字は、フィールド名とフィールドの型を区切るために使用されます。デフォルトはカンマ (,) です。
DDL 形式での一括構成の例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
出力フィールドの作成: [+出力フィールドの作成] をクリックし、画面の指示に従って [列] を入力し、[型] を選択します。現在の行の構成を完了したら、
 アイコンをクリックして保存します。
アイコンをクリックして保存します。
クイックマッピング
上流からの入力とターゲットテーブルのフィールドに基づき、手動でフィールドマッピングを選択できます。[クイックマッピング] には、[行マッピング] および [名前マッピング] が含まれます。
[名前マッピング]:フィールド名が同一のフィールドをマッピングします。
[行マッピング]:ソーステーブルとターゲットテーブルのフィールド名が一致しませんが、対応する行のフィールドデータをマッピングする必要があります。同一行のフィールドのみがマッピングされます。
[SAP HANA 出力コンポーネント] のプロパティ構成を確定するには、[確認] をクリックします。