TDH Inceptor 出力コンポーネントは、データを TDH Inceptor データソースに書き込みます。他のデータソースから TDH Inceptor データソースへデータを同期する場合、まず入力コンポーネントを構成した後、この出力コンポーネントを構成する必要があります。本トピックでは、TDH Inceptor 出力コンポーネントの設定方法について説明します。
制限事項
TDH Inceptor 出力コンポーネントは、ORC、Parquet、テキストファイル形式の TDH Inceptor テーブルへのデータ書き込みをサポートしています。ただし、ORC 形式のトランザクションテーブルに対するデータ統合はサポートされていません。
前提条件
TDH Inceptor データソースが作成済みである必要があります。詳細については、「TDH Inceptor データソースの作成」をご参照ください。
TDH Inceptor 出力コンポーネントのプロパティを設定する際に使用するアカウントには、当該データソースに対するリードスルー権限が必要です。この権限がない場合は、権限の付与をリクエストしてください。詳細については、「データソース権限のリクエスト」をご参照ください。
操作手順
Dataphin のホームページ上部のメニューバーから、[開発者] → [データ統合] を選択します。
統合ページ上部のメニューバーで、[プロジェクト] を選択します。Dev-Prod モードの場合は、さらに [環境] も選択する必要があります。
左側のナビゲーションウィンドウで、[バッチパイプライン] をクリックします。[バッチパイプライン] 一覧から、設定対象の [オフラインパイプライン] をクリックして、その構成ページを開きます。
ページ右上隅の [コンポーネントライブラリ] をクリックし、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネル左側のナビゲーションウィンドウで、[出力] を選択します。右側の出力コンポーネント一覧より、[TDH Inceptor] コンポーネントを見つけ、キャンバス上にドラッグします。
対象となる入力・変換・フロー コンポーネントの
 アイコンをクリックしてドラッグし、現在の TDH Inceptor 出力コンポーネントに接続します。
アイコンをクリックしてドラッグし、現在の TDH Inceptor 出力コンポーネントに接続します。TDH Inceptor 出力コンポーネントのカード上の
 アイコンをクリックして、[TDH Inceptor 出力構成] ダイアログボックスを開きます。
アイコンをクリックして、[TDH Inceptor 出力構成] ダイアログボックスを開きます。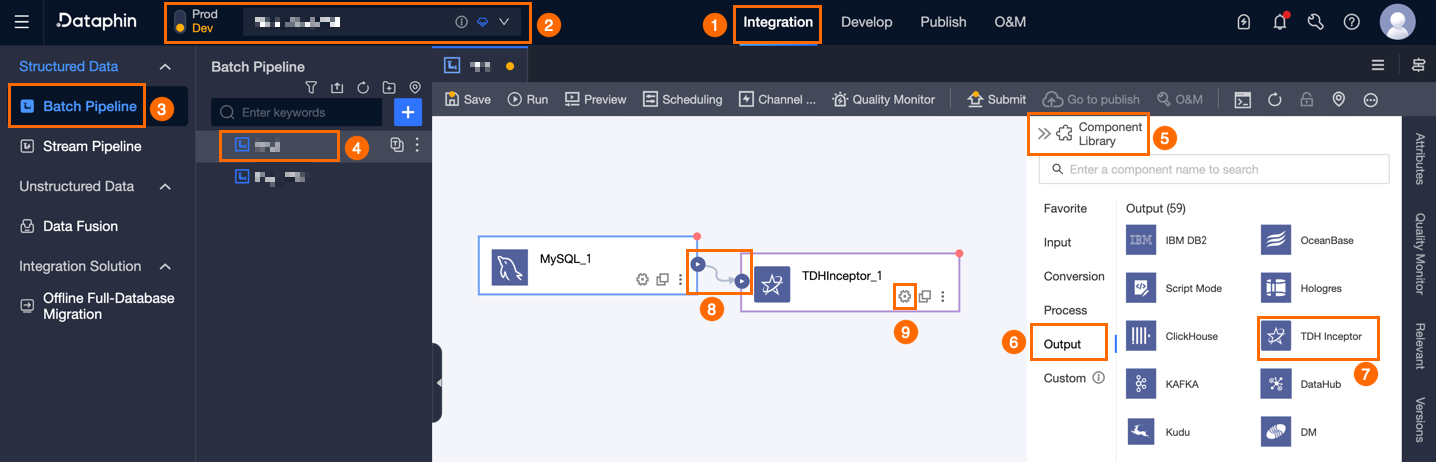
[TDH Inceptor 出力構成] ダイアログボックスで、各パラメーターを設定します。
パラメーター
説明
基本設定
[ステップ名]
TDH Inceptor 出力コンポーネントの名前です。Dataphin が自動的にステップ名を生成しますが、必要に応じて変更可能です。命名規則は以下のとおりです:
中国語文字、英字、アンダースコア(_)、数字のみ使用可能。
最大長は 64 文字です。
データソース
データソースのドロップダウンリストには、すべての TDH Inceptor データソースが表示されます。これは、書き込み権限を持つデータソースおよび持たないデータソースの両方を含みます。現在のデータソース名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。書き込み権限を持たないデータソースについては、データソース横の [リクエスト] をクリックして権限をリクエストしてください。詳細については、「データソースの権限のリクエスト、更新、または解放」をご参照ください。
TDH Inceptor データソースが存在しない場合は、[データソースの作成] をクリックして新規作成してください。詳細については、「」をご参照ください。
テーブル
データ出力先のテーブルを選択します。キーワードを入力してテーブルを検索できます。
 アイコンをクリックすると、選択したテーブル名をコピーできます。
アイコンをクリックすると、選択したテーブル名をコピーできます。データ同期先のテーブルを選択します。TDH Inceptor データソースに当該テーブルが存在しない場合、[ワンクリックテーブル作成] 機能を用いて、迅速にテーブルを生成できます。手順は以下のとおりです:
[ワンクリックテーブル作成] をクリックします。Dataphin が自動的に宛先テーブル作成用のコードを生成します。これには、デフォルトでソーステーブル名が採用される宛先テーブル名および、Dataphin フィールドからの初期変換に基づくフィールド型が含まれます。
必要に応じて、宛先テーブル作成用の SQL スクリプトを編集できます。その後、[作成] をクリックします。宛先テーブルが作成されると、Dataphin は自動的にそれをデータ出力先テーブルとして使用します。
説明開発環境に同名のテーブルが既に存在する場合、[作成] をクリックするとエラーが報告されます。
[本番テーブル未存在時のポリシー]
本番テーブルが存在しない場合に適用するポリシーです。[処理しない] または [自動作成] のいずれかを選択できます。デフォルトは [自動作成] です。[処理しない] を選択した場合、ノード公開時に本番テーブルは作成されません。[自動作成] を選択した場合、ノード公開時に宛先環境に同名のテーブルが作成されます。
[処理しない]:宛先テーブルが存在しない場合、ノード送信時にメッセージが表示されますが、公開は可能です。この場合、ノード実行前に、本番環境に宛先テーブルを手動で作成する必要があります。
[自動作成]:必ず [テーブル作成文の編集] を実行してください。選択されたテーブルの作成文がデフォルトで入力され、必要に応じて調整可能です。作成文内のテーブル名にはプレースホルダー
${table_name}のみがサポートされています。実行時に、このプレースホルダーは実際のテーブル名に置き換えられます。宛先テーブルが存在しない場合、まずテーブル作成文に従ってテーブルが作成されます。作成に失敗した場合、公開時にチェックが失敗します。エラーメッセージに基づいて作成文を修正し、再度公開してください。宛先テーブルが既に存在する場合は、作成文は実行されません。
説明このパラメーターは、Dev-Prod モードのプロジェクトでのみサポートされます。
ファイル エンコーディング
ファイルエンコーディング方式を選択します。システムは UTF-8 および GBK をサポートしています。
[圧縮形式]
ファイル圧縮フォーマットを選択します。サポートされているフォーマットには、[zlib] および [hadoop-snappy] が含まれます。
ロードポリシー
TDH Inceptor データソース内の宛先テーブルへのデータ書き込みポリシーです。追加および上書きの 2 種類があります。各シナリオの説明は以下のとおりです:
[データの追加]:プライマリキーまたは制約違反が発生した場合、ダーティデータエラーが報告されます。
[データの上書き]:プライマリキーまたは制約違反が発生した場合、システムはまず元のデータを削除し、その後新しい全行を挿入します。
[フィールド区切り文字]
ファイルストレージ用のフィールド区切り文字を入力します。空欄のままにした場合、システムはカンマ(,)をデフォルトの [フィールド区切り文字] として使用します。
パーティション
パーティションテーブルを選択した場合、データテーブルのパーティションを指定する必要があります。デフォルトのパーティションは ds=${bizdate} です。
[Hadoop パラメーター構成](任意)
書き込みパラメーターを調整するために使用します。テーブルの種類に応じて異なるパラメーターを入力できます。複数のパラメーターはカンマ(,)で区切ります。書式は
{"key1":"value1", "key2":"value2"}です。たとえば、出力テーブルが ORC 形式で多数のフィールドを持つ場合、メモリサイズに応じて{"hive.exec.orc.default.buffer.size"}パラメーターを調整できます。十分なメモリがある場合は、この値を増加させることで書き込みパフォーマンスを向上させることができます。メモリが不足している場合は、この値を減少させることでガーベジコレクション(GC)時間を短縮し、書き込みパフォーマンスを向上させることができます。デフォルト値は 16384 Byte(16 KB)です。値は 262144 Byte(256 KB)を超えてはなりません。Hudi テーブルに書き込む場合、{"hoodie.parquet.compression.codec":"snappy"}パラメーターを使用して、圧縮形式を snappy に変更できます。プリペアドステートメント
データインポート前にデータベース上で実行する SQL スクリプトです。スクリプトの最大長は 128 文字です。
完了ステートメント
データインポート後にデータベース上で実行する SQL スクリプトです。スクリプトの最大長は 128 文字です。
フィールドマッピング
[入力フィールド]
入力フィールドを表示します。
出力フィールド
出力フィールド領域には、選択したテーブルのすべてのフィールドが表示されます。不要なフィールドを後続コンポーネントに出力したくない場合は、削除できます:
少数のフィールドを削除するには、[操作] 列の
 アイコンをクリックして、不要なフィールドを削除できます。
アイコンをクリックして、不要なフィールドを削除できます。多数のフィールドを削除する場合:[フィールド管理] をクリックします。[フィールド管理] ページで複数のフィールドを選択し、
 アイコンをクリックして、[選択済み入力フィールド] を [未選択入力フィールド] リストに移動します。
アイコンをクリックして、[選択済み入力フィールド] を [未選択入力フィールド] リストに移動します。
クイックマッピング
マッピング関係は、ソーステーブルの入力フィールドと宛先テーブルの出力フィールドを結びつけます。マッピング方法には、名前によるマッピングと行インデックスによるマッピングがあります。各シナリオの説明は以下のとおりです:
[名前によるマッピング]:名前が一致するフィールドをマッピングします。
[行インデックスによるマッピング]:ソーステーブルと宛先テーブルのフィールド名が異なりますが、対応する行のデータをマッピングする必要があります。この方法では、同一行のフィールドのみがマッピングされます。
[確認] をクリックして、[TDH Inceptor] 出力コンポーネントのプロパティ構成を完了します。