このトピックでは、Elasticsearch 出力コンポーネントの設定方法について説明します。
前提条件
Elasticsearch データソースが作成されました。詳細については、「Elasticsearch データソースの作成」をご参照ください。
Elasticsearch 出力コンポーネントのプロパティを設定するには、データソースに対するライトスルー権限が必要です。該当の権限がない場合は、データソースへのアクセス権限を申請してください。詳細については、「データソース権限の申請」をご参照ください。
操作手順
Dataphin のホームページ上部のメニューバーで、[開発] > [データ統合] を選択します。
統合ページ上部のメニューバーで、[プロジェクト] を選択します(Dev-Prod モードの場合は、環境を選択する必要があります)。
左側のナビゲーションウィンドウで、[バッチパイプライン] をクリックします。[バッチパイプライン] 一覧から、開発対象の [オフラインパイプライン] をクリックし、その構成ページを開きます。
ページ右上隅の [コンポーネントライブラリ] をクリックして、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネル左側のナビゲーションウィンドウで、[出力] を選択し、右側の入力コンポーネント一覧から [Elasticsearch] コンポーネントを見つけ、キャンバスにドラッグします。
対象の入力コンポーネントの
 アイコンをクリックしてドラッグし、現在の Elasticsearch 出力コンポーネントに接続します。
アイコンをクリックしてドラッグし、現在の Elasticsearch 出力コンポーネントに接続します。Elasticsearch 出力コンポーネントのカード内にある
 アイコンをクリックして、[Elasticsearch 出力設定] ダイアログボックスを開きます。
アイコンをクリックして、[Elasticsearch 出力設定] ダイアログボックスを開きます。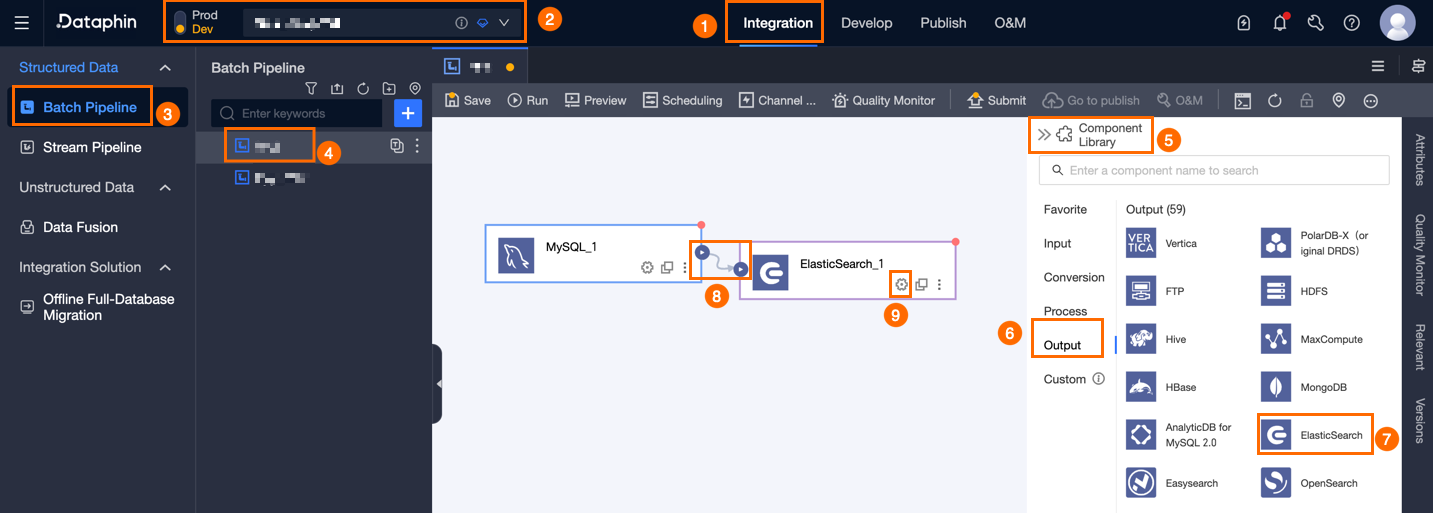
[Elasticsearch 出力設定] ダイアログボックスで、パラメーターを設定します。
パラメーター
説明
ステップ名
Elasticsearch 出力コンポーネントの名称です。Dataphin が自動的にステップ名を生成しますが、ビジネスシナリオに応じて変更可能です。命名規則は以下のとおりです:
漢字、英大文字・小文字、アンダースコア (_)、数字のみ使用可能。
最大文字数は 64 文字です。
[データソース]
データソースのドロップダウンリストには、ライトスルー権限を持つ Elasticsearch 型データソースおよび権限を持たないデータソースがすべて表示されます。
データソースにライトスルー権限がない場合は、該当データソース横の [リクエスト] を選択して必要な権限を申請してください。詳細については、「データソース権限の申請・更新・返却」をご参照ください。
Elasticsearch 型データソースが存在しない場合は、[作成] をクリックしてデータソースを作成してください。詳細については、「Elasticsearch データソースの作成」をご参照ください。
クエリ タイプ
[インデックス] または [エイリアス] を基準として書き込み対象のインデックスドキュメントを選択できます。クエリタイプによって、必要な設定情報が異なります。
重要[インデックスエイリアス] を選択した場合、単一のインデックスを指すエイリアス、または
is_write_indexが設定されたエイリアスにのみ書き込み可能です。それ以外の場合、書き込み操作は失敗します。[インデックス]
[インデックスドキュメント]:Elasticsearch 内の
indexの名称です。[インデックスドキュメントタイプ]:Elasticsearch 内のインデックスのタイプ名です。
説明[インデックスドキュメント] および [インデックスドキュメントタイプ] は、Elasticsearch 6.x および 7.x バージョンでは必須ですが、Elasticsearch 8.x バージョンでは不要です。
[エイリアス]
[インデックスエイリアス]:Elasticsearch 内の
Aliasです(indexのエイリアス)。[インデックスドキュメントタイプ]:Elasticsearch 内のインデックスのタイプ名です。
[フィールド区切り文字]
(任意)フィールド間の区切り文字を入力します。未入力の場合は、システムが自動的にカンマ (,) を区切り文字として設定します。
読み込みポリシー
ターゲットテーブルへのデータ書き込みポリシーを選択します。[ローディングポリシー] には以下の種類があります:
[既存データの上書き]:現在のソーステーブルに基づき、ターゲットテーブル内の既存データを上書きします。
[データの追加]:ターゲットテーブル内の既存データを変更せずに、新しいデータを追加します。
説明[クエリタイプ] を [エイリアス] に設定した場合、[ローディングポリシー] は [データの追加] のみ選択可能です。
入力フィールド
上流の出力に基づいて入力フィールドが表示されます。
[出力フィールド]
出力フィールドが表示されます。
[フィールド情報の取得]
[クエリタイプ] を [インデックス] に設定した場合、選択した [インデックス] のフィールド情報を取得するために [フィールド情報の取得] をクリックできます。
[フィールドの一括追加]
[一括追加] をクリックします。
JSON 形式で一括設定します。例を以下に示します:
[{"name":"col_integer","type":"integer"}, {"name":"col_long","type":"long"}, {"name":"col_double","type":"double"}]説明"name" はインポートするフィールドの名称、"type" はフィールドの型を指定します。例えば、"name":"user_id","type":"String" は、フィールド名 user_id をインポートし、その型を
Stringに設定します。プレーンテキスト形式で一括設定します。例を以下に示します:
col_long,long col_double,double行区切り文字は各フィールド情報の区切りに使用されます。デフォルトは改行 (\n) ですが、改行 (\n)、セミコロン (;)、ピリオド (.) をサポートしています。
列区切り文字はフィールド名とフィールド型の区切りに使用されます。デフォルトはカンマ (,) です。
[確認] をクリックします。
[出力フィールドの作成]
[出力フィールドの作成] をクリックし、画面の指示に従って [列] を入力し、[型] を選択します。
[上流フィールドのコピー]
上流の入力フィールドを出力フィールドとして参照します。
[出力フィールドの管理]
追加済みのフィールドに対して、以下の操作が可能です:
フィールドの位置を変更するには、
 シフトアイコンの横にあるドラッグ用の [列] をクリックします。
シフトアイコンの横にあるドラッグ用の [列] をクリックします。[操作] 列の
 編集アイコンをクリックして、既存のフィールドを編集します。
編集アイコンをクリックして、既存のフィールドを編集します。[操作] 列の
 削除アイコンをクリックして、既存のフィールドを削除します。
削除アイコンをクリックして、既存のフィールドを削除します。
[マッピング]
マッピングは、ソーステーブルの入力フィールドをターゲットテーブルの出力フィールドにマップする機能であり、後続のデータ同期を容易にします。マッピングには同名マッピングと同行マッピングがあります。適用シーンは以下のとおりです:
[同名マッピング]:フィールド名が一致するフィールドをマップします。
[同行マッピング]:ソーステーブルとターゲットテーブルのフィールド名が異なるものの、対応する行のデータをマップする必要がある場合に使用します。同一行のフィールドのみがマップされます。
インデックススキーマ
説明[クエリタイプ] を [インデックス] に、[ローディングポリシー] を [既存データの上書き] に設定した場合のみ、この項目を設定する必要があります。
システムデフォルトの選択またはオンライン再利用が可能です。
[オンライン再利用]:インデックスを再構築するたびに、既存の Elasticsearch インデックススキーマを再利用します。
[システムデフォルト]:インデックスを再構築するたびに、Elasticsearch 出力コンポーネントで設定した出力フィールドに基づき、インデックススキーマを自動生成します。
[確認] をクリックして、[Elasticsearch] 出力コンポーネントのプロパティ設定を完了します。