PolarDB-X 出力ウィジェットは、PolarDB-X データソースへのデータ書き込みを可能にします。他のソースから PolarDB-X にデータを同期する場合、ソースデータを設定した後、PolarDB-X 出力ウィジェットでターゲットデータソースを構成します。このトピックでは、PolarDB-X 出力ウィジェットの構成プロセスについて説明します。
前提条件
PolarDB-X データソースが作成済みであること。詳細については、「PolarDB-X データソースの作成」をご参照ください。
PolarDB-X 出力ウィジェットのプロパティを構成するには、アカウントがデータソースに対する必要なライトスルー権限を持っている必要があります。これらの権限がない場合は、データソースの権限を取得する必要があります。詳細については、「データソース権限のリクエスト、更新、返却」または「」をご参照ください。
操作手順
Dataphin ホームページで、トップメニューバーから [開発] > [データ統合] に移動します。
統合ページで、トップメニューバーから [プロジェクト] を選択します (開発-本番モードでは [環境] を選択します)。
左側のナビゲーションウィンドウで、[バッチパイプライン] をクリックします。[バッチパイプライン] リストから、開発するオフラインパイプラインを選択して、その構成ページにアクセスします。
「[コンポーネントライブラリ]」パネルを開くには、ページの右上隅にある[コンポーネントライブラリ]をクリックします。
「コンポーネントライブラリ」パネルの左側のナビゲーションウィンドウで、[出力] を選択します。次に、右側の出力ウィジェット一覧から [Polardb-x(旧DRDS)] ウィジェットを検索し、キャンバスにドラッグします。
 アイコンをクリックしてドラッグし、ターゲット入力、変換、またはフローウィジェットを PolarDB-X (旧 DRDS) 出力ウィジェットに接続します。
アイコンをクリックしてドラッグし、ターゲット入力、変換、またはフローウィジェットを PolarDB-X (旧 DRDS) 出力ウィジェットに接続します。ウィジェットを設定するには、PolarDB-X (旧 DRDS) 出力ウィジェットカードにある
 アイコンをクリックすると、[Polardb-x (旧 DRDS) 出力設定] ダイアログボックスが開きます。
アイコンをクリックすると、[Polardb-x (旧 DRDS) 出力設定] ダイアログボックスが開きます。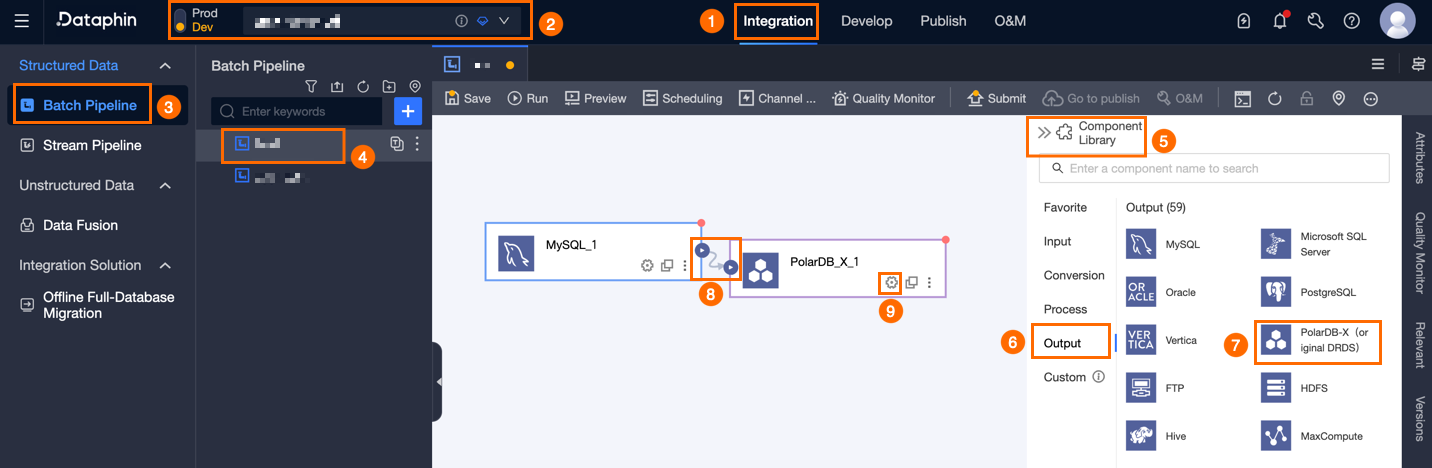
[Polardb-x (旧DRDS) 出力設定] ダイアログボックスで、必要なパラメーターを設定します。
パラメーター
説明
基本設定
ステップ名
これは PolarDB-X 出力ウィジェットの名前です。Dataphin がステップ名を自動的に生成しますが、ビジネスシナリオに応じて変更することもできます。名前は次の要件を満たす必要があります。
中国語の文字、英字、アンダースコア (_)、数字のみを含めることができます。
64 文字を超えることはできません。
データソース
データソースドロップダウンリストには、ライトスルー権限を持つデータソースと持たないデータソースを含む、すべての PolarDB-X タイプのデータソースが表示されます。
 アイコンをクリックして、現在のデータソース名をコピーします。
アイコンをクリックして、現在のデータソース名をコピーします。ライトスルー権限がないデータソースの場合、データソースの後に [要求] をクリックして、ライトスルー権限を要求できます。具体的な操作については、「データソースの権限を要求する」をご参照ください。
PolarDB-X タイプのデータソースがない場合は、[データソースの作成] をクリックしてデータソースを作成します。具体的な操作については、「PolarDB-X データソースの作成」をご参照ください。
テーブル
出力データの対象テーブルを選択します。 検索するにはテーブル名のキーワードを入力するか、正確なテーブル名を入力して [正確な検索] をクリックします。テーブルを選択すると、システムが自動的にテーブル状態の検出を実行します。現在選択されているテーブルの名前をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。読み込みポリシー
ターゲットテーブルへのデータ書き込みに使用するポリシーを選択します。[読み込みポリシー]には、以下のものが含まれます:
[データの上書き] は、現在のソーステーブルに基づいて、ターゲットテーブル内の既存データが上書きされることを意味します。
[データの追加] は、既存データを変更せずに、対象テーブル内の既存のデータにデータを追加することを意味します。
[バッチ書き込みデータ量](オプション)
一度に書き込まれるデータのサイズです。また、[バッチ書き込み件数] も設定できます。システムは、この 2 つの構成設定のうち、最初に達成される制限に従ってデータを書き込みます。デフォルト値は 32M です。
バッチ書き込み数 (任意)
デフォルトは 2048 エントリ です。データの同期および書き込み時に、バッチ書き込み戦略が使用されます。設定されるパラメーターには、[バッチ書き込み数] および [バッチ書き込みデータ量] が含まれます。
蓄積されたデータ量が設定された制限 (つまり、バッチ書き込みデータ量またはカウント制限) のいずれかに達すると、システムはデータのバッチが満杯であると見なし、このデータのバッチを一度にターゲットエンドにすぐに書き込みます。
バッチ書き込みデータ量を 32MB に設定することを推奨します。バッチ挿入数の上限については、単一レコードの実際のサイズに応じて柔軟に調整できます。通常、バッチ書き込みの利点を最大限に活用するために、より大きな値に設定されます。たとえば、単一レコードのサイズが約 1KB の場合、バッチ挿入バイトサイズを 16MB に設定できます。この条件を考慮すると、バッチ挿入数を 16MB を単一レコードのサイズ 1KB で割った結果 (つまり、16384 エントリより大きい) よりも大きく設定します。ここでは、20000 エントリに設定されていると仮定します。このような構成の後、システムはバッチ挿入バイトサイズに基づいてバッチ書き込み操作をトリガーします。蓄積されたデータ量が 16MB に達するたびに、書き込み操作が実行されます。
準備ステートメント (オプション)
データインポート前にデータベースで実行される SQL スクリプトです。
たとえば、サービスの継続的な可用性を確保するために、現在のステップがデータを書き込む前に、まずターゲットテーブル Target_A を作成し、ターゲットテーブル Target_A への書き込みを実行します。そして、現在のステップがデータを書き込んだ後、データベースで継続的にサービスを提供するテーブル Service_B の名前を Temp_C に変更し、次にテーブル Target_A の名前を Service_B に変更し、最後に Temp_C を削除します。
終了ステートメント(任意)
データインポート後にデータベースで実行される SQL スクリプトです。
フィールドマッピング
入力フィールド
入力フィールドは、アップストリームウィジェットの出力に基づいて表示されます。
出力フィールド
出力フィールドが表示されます。次の操作を実行できます。
フィールド管理: 出力フィールドを選択するには、[フィールド管理] をクリックします。

 アイコンをクリックして、[選択済み入力フィールド] を [未選択入力フィールド] に移動します。
アイコンをクリックして、[選択済み入力フィールド] を [未選択入力フィールド] に移動します。 アイコンをクリックして、[未選択入力フィールド] を [選択済み入力フィールド] に移動します。
アイコンをクリックして、[未選択入力フィールド] を [選択済み入力フィールド] に移動します。
一括追加: [一括追加] をクリックすると、JSON、TEXT フォーマット、または DDL フォーマットで一括構成を行うことができます。
JSON 形式でのバッチ構成の例:
// 例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]説明name はインポートされたフィールドの名前を指定し、type はインポート後のフィールドのデータ型を指定します。たとえば、
"name":"user_id","type":"String"は user_id という名前のフィールドをインポートし、そのデータ型を String に設定します。TEXT 形式でのバッチ構成の例:
// 例: user_id,String user_name,String行区切り文字は、各フィールドの情報を区切るために使用されます。デフォルトは改行 (\n) であり、改行 (\n)、セミコロン (;) またはピリオド (.) をサポートできます。
列区切り文字は、フィールド名とフィールドタイプを区切るために使用されます。デフォルトはコンマ (,) です。
DDL 形式でのバッチ構成の例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
新しい出力フィールドを作成: [新しい出力フィールドを作成] をクリックし、[列] を入力し、ページのプロンプトに従って [タイプ] を選択します。現在の行の構成を完了したら、
 アイコンをクリックして保存します。
アイコンをクリックして保存します。
クイックマッピング
上流からの入力とターゲット テーブルのフィールドに基づき、フィールド マッピングを手動で選択できます。クイック マッピングには、行マッピングと名前マッピングが含まれます。
名前マッピング: 同じフィールド名を持つフィールドをマッピングします。
行マッピング: ソーステーブルとターゲットテーブルのフィールド名が一致しませんが、フィールドの対応する行のデータをマッピングする必要があります。同じ行のフィールドのみをマッピングします。
[PolarDB-X] 出力ウィジェットのプロパティ構成を、[確認]をクリックして完了します。