StarRocks 出力コンポーネントは、データを StarRocks データソースに書き込みます。他のデータソースから StarRocks データソースへデータを同期する場合、ソースデータソースの構成を完了した後、ターゲットデータソースへのデータ書き込みを行うために、StarRocks 出力コンポーネントを構成する必要があります。本トピックでは、StarRocks 出力コンポーネントの構成方法について説明します。
前提条件
StarRocks データソースを追加しました。詳細については、「StarRocks データソースを作成する」をご参照ください。
StarRocks 出力コンポーネントのプロパティを構成する際に使用するアカウントには、データソースに対するライトスルー権限が必要です。権限がない場合は、データソースの権限を申請してください。詳細については、「データソース権限の申請、更新、取り消し」をご参照ください。
Stream Load によるデータ同期遅延
Stream Load を使用して StarRocks データベースにデータをインポートする際、返されるステータスは状況に応じて異なります。「publish timeout(公開タイムアウト)」が発生する場合があります。この場合、ジョブ自体は成功していますが、クエリの可視性に遅延が生じる可能性があります。運用ログでステータスを監視してください:
Success(成功):インポートが正常に完了し、データが可視化されています。
Publish Timeout(公開タイムアウト):インポートジョブは正常にコミットされましたが、何らかの理由によりデータが即座に可視化されません。これは成功と見なされます。再インポートは不要です。
Label Already Exists(ラベルが既に存在):別のジョブがすでにこのラベルを使用しています。インポートは成功している可能性があるか、実行中である可能性があります。
Fail(失敗):このインポートは失敗しました。ラベルを指定してジョブを再実行できます。
操作手順
Dataphin のホームページ上部のメニューバーから、開発 > データ統合 を選択します。
統合ページの上部メニューバーから、プロジェクト を選択します(Dev-Prod モードの場合は、環境を選択します)。
左側のナビゲーションウィンドウで、オフライン統合 をクリックします。その後、オフライン統合 リストから、開発対象の オフラインパイプライン をクリックして、その構成ページを開きます。
ページ右上隅の コンポーネントライブラリ をクリックし、コンポーネントライブラリ パネルを開きます。
コンポーネントライブラリ パネルの左側ナビゲーションウィンドウで、出力 を選択します。右側のリストから StarRocks コンポーネントを見つけ、キャンバス上にドラッグします。
対象の入力コンポーネントの
 アイコンをクリック・ドラッグし、現在の StarRocks 出力コンポーネントに接続します。
アイコンをクリック・ドラッグし、現在の StarRocks 出力コンポーネントに接続します。StarRocks 出力コンポーネントカード内の
 アイコンをクリックします。これにより、StarRocks 出力構成 ダイアログボックスが開きます。
アイコンをクリックします。これにより、StarRocks 出力構成 ダイアログボックスが開きます。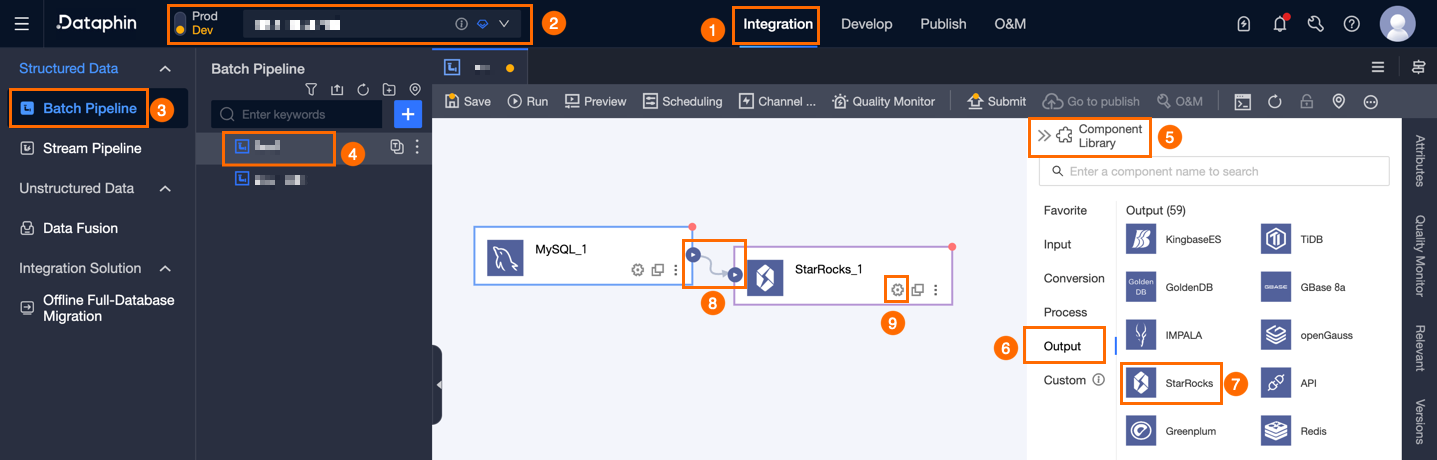
StarRocks 出力構成 ダイアログボックスで、以下のパラメーターを構成します。
パラメーター
説明
基本設定
ステップ名
StarRocks 出力コンポーネントの名称です。Dataphin が自動的にステップ名を生成しますが、必要に応じて変更可能です。命名規則は以下のとおりです:
中国語文字、英字、アンダースコア(_)、数字のみ使用可能です。
長さは最大 64 文字までです。
データソース
データソースのドロップダウンリストには、ライトスルー権限を持つものおよび持たないすべての StarRocks データソースが表示されます。
 アイコンをクリックすると、現在のデータソース名をコピーできます。
アイコンをクリックすると、現在のデータソース名をコピーできます。ライトスルー権限を持たないデータソースの場合は、申請 をクリックして権限を申請できます。詳細については、「データソース権限の申請」をご参照ください。
StarRocks データソースが未登録の場合は、新規データソース をクリックして作成できます。詳細については、「StarRocks データソースの作成」をご参照ください。
テーブル
出力データの対象テーブルを選択します。 テーブル名のキーワードを入力して検索するか、正確なテーブル名を入力して 完全一致検索 をクリックできます。テーブルを選択すると、システムが自動的にテーブルのステータスを確認します。
 アイコンをクリックすると、現在選択中のテーブル名をコピーできます。
アイコンをクリックすると、現在選択中のテーブル名をコピーできます。StarRocks データソースにデータ同期用の対象テーブルが存在しない場合は、ワンクリックテーブル作成機能を使用して、対象テーブルをすばやく生成できます。詳細な手順は以下のとおりです:
ワンクリックテーブル作成 をクリックします。Dataphin が対象テーブル作成に必要な SQL スクリプト(対象テーブル名:デフォルトでソーステーブル名、フィールド型:Dataphin のフィールドに基づく概算変換)を自動生成します。
必要に応じて、対象テーブル作成用の SQL スクリプトを編集し、新規作成 をクリックします。対象テーブルの作成が成功すると、Dataphin が自動的に新しく作成されたテーブルを出力データの対象テーブルとして設定します。
説明開発環境に同名のテーブルが存在する場合、[作成] をクリックすると Dataphin がエラーを報告します。
該当する項目が見つからない場合は、手動で入力したテーブル名に基づいて統合を実行することもできます。
コピーモードではビュー選択はサポートされていません。
本番テーブル未存在時のポリシー
本番テーブルが存在しない場合の処理ポリシーです。処理なし または 自動作成 のいずれかを選択できます。デフォルトは 自動作成 です。処理なし を選択した場合、タスクの公開時に本番テーブルは作成されません。自動作成 を選択した場合、タスクの公開時にターゲット環境に同名のテーブルが作成されます。
処理なし:対象テーブルが存在しない場合、送信時に「対象テーブルが存在しません」というメッセージが表示されますが、公開処理は継続可能です。この場合、タスクを実行する前に、本番環境で対象テーブルを手動で作成する必要があります。
自動作成:必ず テーブル作成文の編集 を実行してください。テーブル作成文は、選択されたテーブルに基づきデフォルトで事前入力され、必要に応じて調整可能です。文内ではテーブル名にプレースホルダー
${table_name}を使用します。このプレースホルダーのみがサポートされており、実行時に実際のテーブル名に置き換えられます。対象テーブルが存在しない場合、システムはまずテーブル作成文に従ってテーブルを作成します。テーブル作成に失敗した場合、公開チェックの結果は「失敗」になります。エラーメッセージに基づいてテーブル作成文を修正し、再度公開してください。対象テーブルがすでに存在する場合は、テーブル作成は実行されません。
説明このオプションは、Dev-Prod モードのプロジェクトでのみサポートされます。
データフォーマット
CSV または JSON のいずれかを選択できます。
CSV を選択した場合、CSV インポート列区切り文字 および CSV インポート行区切り文字 も構成してください。
CSV インポート列区切り文字(任意)
StreamLoad CSV インポートを使用する場合、ここで CSV インポート列区切り文字を構成します。デフォルト値は
_@dp@_です。デフォルト値を使用する場合は、明示的に指定する必要はありません。データに_@dp@_が含まれる場合は、別の文字を区切り文字としてカスタマイズしてください。CSV インポート行区切り文字(任意)
StreamLoad CSV インポートを使用する場合、ここで CSV インポート行区切り文字を構成します。デフォルト値は
_#dp#_です。デフォルト値を使用する場合は、明示的に指定する必要はありません。データに_#dp#_が含まれる場合は、別の文字を区切り文字としてカスタマイズしてください。バッチ書き込みデータ量(任意)
1 回の書き込み操作におけるデータ量を指定します。バッチ書き込み件数 も設定できます。書き込み処理中、システムはデータ量またはバッチ件数のいずれかの制限に先に到達した時点で書き込みを実行します。デフォルト値は 32 MB です。
バッチ書き込みレコード数(任意)
デフォルト値は 2,048 件 です。データ同期中はバッチ書き込みポリシーが適用されます。このポリシーのパラメーターは、1 バッチあたりのレコード数 および 1 バッチあたりのデータ量 です。
累積データが設定されたいずれかの制限(バッチ書き込みデータ量またはレコード数)に達した時点で、システムはバッチが満杯と判断し、直ちに対象データをターゲットに書き込みます。
バッチ書き込みデータ量を 32 MB に設定します。1 レコードあたりの実際のサイズに応じて、バッチ挿入レコード数の上限を調整してください。通常は、バッチ書き込みのメリットを十分に活用できるよう、より大きな値を設定します。たとえば、1 レコードが約 1 KB の場合、バッチ挿入バイトサイズを 16 MB に設定します。この場合、バッチ挿入レコード数は 16 MB ÷ 1 KB(=16,384 件)より大きい値に設定します。ここでは、20,000 件 に設定されていると仮定します。この構成では、システムはバッチ挿入バイトサイズに基づいてバッチ書き込みをトリガーします。累積データが 16 MB に達するごとに書き込みが実行されます。
準備文(任意)
データインポート前にデータベース上で実行される SQL スクリプトです。
たとえば、サービスの可用性を継続的に確保するために、本ステップがデータを書き込む前に、ターゲットテーブル Target_A をあらかじめ作成します。データを Target_A に書き込んだ後、データベース内で継続的にサービス提供中のテーブル Service_B を Temp_C にリネームし、Target_A を Service_B にリネームしてから、Temp_C を削除します。
終了文(任意)
データインポート後にデータベース上で実行される SQL スクリプトです。
フィールドマッピング
入力フィールド
上流コンポーネントの出力に基づいて入力フィールドを表示します。
出力フィールド
出力フィールドを表示します。以下の操作がサポートされています:
フィールド管理: フィールド管理 をクリックして、出力フィールドを選択します。

 アイコンをクリックすると、選択済み入力フィールド を 未選択入力フィールド に移動できます。
アイコンをクリックすると、選択済み入力フィールド を 未選択入力フィールド に移動できます。 アイコンをクリックすると、未選択入力フィールド を 選択済み入力フィールド に移動できます。
アイコンをクリックすると、未選択入力フィールド を 選択済み入力フィールド に移動できます。
一括追加: 一括追加 をクリックします。JSON、TEXT、DDL 形式の一括構成をサポートします。
JSON 形式の一括構成例:
// 例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]説明name はインポート対象のフィールド名、type はインポート後のフィールド型を示します。たとえば、
"name":"user_id","type":"String"は、user_id という名前のフィールドをインポートし、そのフィールド型を String に設定することを意味します。TEXT 形式の一括構成例:
// 例: user_id,String user_name,String行区切り文字は各フィールドの情報を分離します。デフォルトは改行(\n)です。改行(\n)、セミコロン(;)、ピリオド(.)をサポートします。
列区切り文字はフィールド名とフィールド型を分離します。デフォルトはカンマ(,)です。
DDL 形式の一括構成例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
出力フィールドの作成: +出力フィールドの作成 をクリックします。画面上の指示に従い、列 を入力し、型 を選択します。現在の行の構成を完了したら、
 アイコンをクリックして保存します。
アイコンをクリックして保存します。
マッピング
上流の入力およびターゲットテーブルのフィールドに基づき、手動でフィールドマッピングを選択できます。マッピング には 行マッピング および 名前マッピング が含まれます。
名前ベースのマッピング: 同じ名前のフィールドをマッピングします。
行単位のマッピング: ソーステーブルとターゲットテーブルのフィールド名が異なるものの、対応する行のデータをマッピングする必要があります。同一行のフィールドのみをマッピングします。
確認 をクリックして、StarRocks 出力コンポーネントのプロパティ構成を完了します。