openGauss 出力コンポーネントは、データを openGauss データソースに書き込みます。他のデータソースから openGauss データソースへデータを同期する場合、まずソースデータソースの設定を完了した後、openGauss 出力コンポーネントを設定します。本トピックでは、openGauss 出力コンポーネントの設定方法について説明します。
前提条件
openGauss データソースを作成済みである必要があります。詳細については、「openGauss データソースの作成」をご参照ください。
openGauss 出力コンポーネントのプロパティを設定する際に使用するアカウントには、対象データソースに対する sync-write 権限が必要です。権限がない場合は、管理者に権限付与をリクエストしてください。詳細については、「データソースの権限をリクエストする」をご参照ください。
操作手順
Dataphin のホームページ上部のメニューバーで、[開発] > [データ統合] を選択します。
データ統合ページの上部メニューバーで、[プロジェクト] を選択します。Dev-Prod モードの場合は、代わりに [環境] を選択します。
左側のナビゲーションウィンドウで、[オフライン統合] をクリックします。[オフライン統合] の一覧から、開発対象のオフラインパイプラインをクリックし、その構成ページを開きます。
ページ右上隅の [コンポーネントライブラリ] をクリックして、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネルの左側ナビゲーションウィンドウで、[出力] をクリックします。右側の出力コンポーネント一覧から openGauss コンポーネントを見つけ、キャンバス上にドラッグします。
ターゲットの入力・変換・フロー系コンポーネントの
 アイコンをクリックしてドラッグし、openGauss 出力コンポーネントと接続します。
アイコンをクリックしてドラッグし、openGauss 出力コンポーネントと接続します。openGauss 出力コンポーネントカード内の
 アイコンをクリックして、[openGauss 出力構成] ダイアログボックスを開きます。
アイコンをクリックして、[openGauss 出力構成] ダイアログボックスを開きます。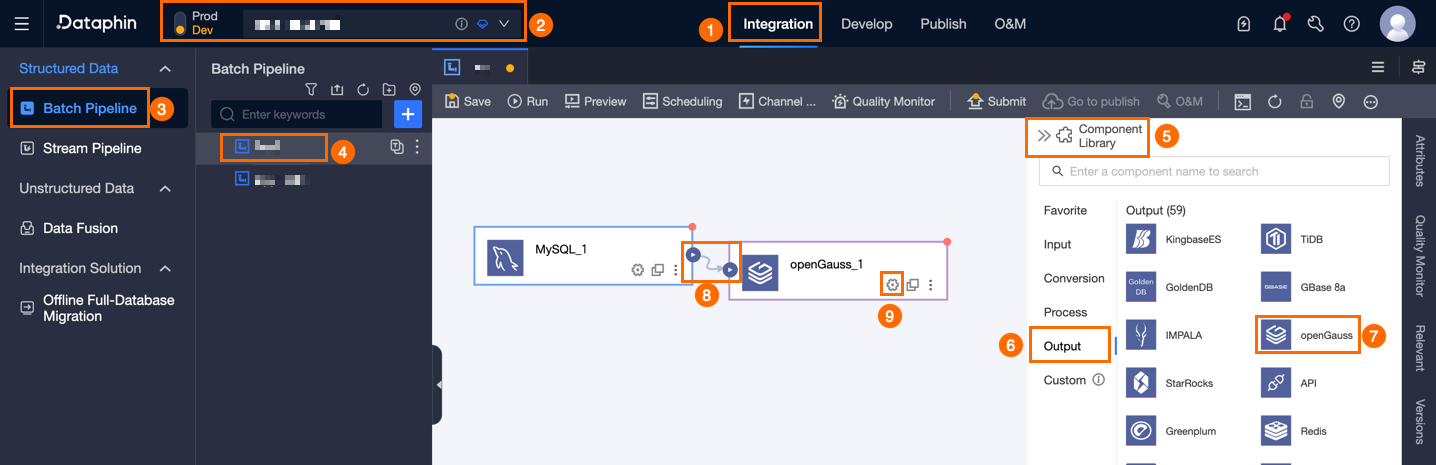
[openGauss 出力構成] ダイアログボックスで、各パラメーターを設定します。
パラメーター
説明
基本設定
[ステップ名]
openGauss 出力コンポーネントの名前です。Dataphin が自動的にステップ名を生成しますが、ビジネスシナリオに応じて任意の名称に変更できます。命名規則は以下のとおりです。
使用可能な文字:漢字、英字、アンダースコア (_ )、数字のみ。
最大文字数:64 文字まで。
データソース
ドロップダウンリストには、sync-write 権限を持つものおよび持たないものを含むすべての openGauss データソースが表示されます。
 アイコンをクリックすると、現在選択中のデータソース名をコピーできます。
アイコンをクリックすると、現在選択中のデータソース名をコピーできます。データソースに対して sync-write 権限がない場合は、該当データソース横の [リクエスト] をクリックして権限をリクエストしてください。詳細については、「データソースの権限をリクエストする」をご参照ください。
openGauss データソースが存在しない場合は、[データソースの作成] をクリックして新規作成してください。詳細については、「openGauss データソースの作成」をご参照ください。
スキーマ
スキーマとは、データソース内でテーブルを論理的にグループ化する単位です。
テーブル
データを書き込む対象テーブルを選択します。
説明コピー(Copy)モードではビュー(View)の選択はサポートされていません。
対象テーブルが openGauss データソースに存在しない場合は、ワンクリックでターゲットテーブルを自動生成する機能を使用して、素早く作成できます。以下の手順で実行してください。
[ターゲットテーブルの生成] をクリックします。Dataphin が自動的にターゲットテーブル作成用の SQL スクリプトを生成します(テーブル名はデフォルトでソーステーブル名、フィールド型は Dataphin のフィールドから変換されます)。下図を参照してください。
必要に応じて生成された SQL スクリプトを編集し、[作成] をクリックします。ターゲットテーブルが作成されると、Dataphin はそれを出力先テーブルとして使用します。
説明開発環境に同名のテーブルが既に存在する場合、[作成] をクリックすると「テーブルが既に存在します」というエラーが返されます。
[本番テーブル未検出時の処理ポリシー]
本番環境のテーブルが存在しない場合の処理方法を選択します。「処理なし」または「自動作成」から選択できます。デフォルト値は「自動作成」です。「処理なし」を選択した場合、タスクの公開時に本番テーブルは作成されません。「自動作成」を選択した場合、タスク公開時にターゲット環境に同名のテーブルが自動的に作成されます。
[処理なし]:対象テーブルが存在しない場合、提出時にエラーが表示されますが、タスクの公開は可能です。タスク実行前に、本番環境で対象テーブルを手動で作成する必要があります。
[自動作成]:事前に [DDL 文の編集] を実行する必要があります(デフォルトで選択済みテーブルの DDL 文が事前入力されています)。必要に応じて内容を調整できます。DDL 文内のテーブル名にはプレースホルダー
${table_name}を使用します。このプレースホルダーのみがサポートされており、実行時に実際のテーブル名に置き換えられます。対象テーブルが存在しない場合、Dataphin はまず CREATE TABLE 文を実行します。テーブル作成に失敗した場合、公開チェックも失敗します。エラーメッセージに基づいて CREATE TABLE 文を修正し、再度公開してください。対象テーブルが既に存在する場合は、テーブル作成はスキップされます。
説明この設定は、Dev-Prod モードのプロジェクトでのみ利用可能です。
読み込みポリシー
ターゲットテーブルへのデータ書き込み方法を選択します。[ローディングポリシー] には以下のオプションがあります。
[上書き]:ターゲットテーブル内の既存データを、現在のソーステーブルからのデータで置き換えます。
[追加]:既存データに新規データを追加し、既存データ(歴史データ)は変更しません。
[コピー]:テーブル間およびファイル間でのデータコピーを行います。競合が発生した場合は、[競合解決ポリシー] を使用して、[競合時は失敗] または [競合時は上書き] のいずれかを選択して処理します。
[バルク書き込みサイズ]
1 回のバッチで書き込まれるデータ量です。[バルク書き込み件数] も併せて設定できます。いずれかの制限値に達した時点で、システムがデータを書き込みます。デフォルト値は 32 MB です。
[バルク書き込み件数]
デフォルト値は 2,048 行 です。データ同期中、Dataphin は書き込み前にデータをバッチ処理します。関連パラメーターには [バルク書き込み件数] および [バルク書き込みサイズ] があります。
累積データ量が設定された制限値(バッチデータ量またはレコード件数)に達した時点で、バッチが満了と見なされ、単一の操作で即座に宛先に書き込まれます。
バルク書き込みサイズは、推奨値の 32 MB を設定することをおすすめします。バルク書き込み件数は、平均レコードサイズに応じて調整してください。バッチ効率を最大化するために、より大きな値を設定してください。たとえば、1 行あたり約 1 KB の場合、バルク書き込みサイズを 16 MB、バルク書き込み件数を 16,384 行以上(16 MB ÷ 1 KB)に設定します。本例では 20,000 行 を使用しています。この設定により、累積データ量が 16 MB に達した時点で Dataphin がバッチ書き込みを実行します。
[フィールドマッピング]
入力フィールド
上流コンポーネントから取得される入力フィールドの一覧です。
出力フィールド
出力フィールドの一覧です。対応する操作は以下のとおりです。
[フィールド管理]: [フィールド管理] をクリックして、出力フィールドを選択します。

 アイコンをクリックすると、[選択済み入力フィールド] から [未選択入力フィールド] に移動します。
アイコンをクリックすると、[選択済み入力フィールド] から [未選択入力フィールド] に移動します。 アイコンをクリックして、[未選択の入力フィールド] を [選択済みの入力フィールド] に移動します。
アイコンをクリックして、[未選択の入力フィールド] を [選択済みの入力フィールド] に移動します。
一括追加: [一括追加] をクリックして、フィールドをJSON、TEXT、またはDDL フォーマットで設定します。
JSON 形式による一括構成の例:
// 例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]説明nameはインポート対象フィールドの名前、typeはそのデータの型を指定します。たとえば、"name":"user_id","type":"String"は、user_idという名前のフィールドをインポートし、そのデータの型をStringに設定することを意味します。TEXT フォーマットの例:
// 例: user_id,String user_name,Stringフィールド項目の区切り文字は改行 (\n) がデフォルトですが、セミコロン (;) やピリオド (.) もサポートされます。
フィールド名とデータの型の区切り文字は、カンマ (,) がデフォルトです。
DDL 形式による一括構成の例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
[出力フィールドの作成]: [+ 出力フィールドの作成] をクリックします。[列] 名を入力し、[型] を選択します。
 アイコンをクリックして、行を保存します。
アイコンをクリックして、行を保存します。
マッピング
上流の入力フィールドとターゲットテーブルのフィールドに基づき、手動でフィールドマッピングを選択できます。[クイックマッピング] には [行単位マッピング] および [名前単位マッピング] があります。
[名前単位マッピング]:フィールド名が一致するフィールドを自動的にマッピングします。
[行単位マッピング]:ソースとターゲットのカラム名が異なる場合でも、同じ行位置にあるフィールドをマッピングします。
[OK] をクリックして、openGauss 出力コンポーネント の構成を完了します。