Lindorm (コンピュートエンジン) 出力コンポーネントは、外部データベースから Lindorm (コンピュートエンジン) にデータを書き込みます。また、ビッグデータプラットフォームに接続されたストレージシステムから Lindorm (コンピュートエンジン) へデータをコピーおよびプッシュし、データ統合や再処理を行うこともできます。本トピックでは、Lindorm (コンピュートエンジン) 出力コンポーネントの構成方法について説明します。
前提条件
Lindorm (コンピュートエンジン) データソースを作成済みである必要があります。詳細については、「Lindorm (コンピュートエンジン) データソースの作成」をご参照ください。
Lindorm (コンピュートエンジン) 出力コンポーネントのプロパティを構成するアカウントには、対象データソースに対するライトスルー権限が必要です。この権限がない場合は、データソースに対して権限をリクエストしてください。詳細については、「データソース権限のリクエスト」をご参照ください。
操作手順
Dataphin ホームページで、上部のメニューバーから [開発] > [データ統合] を選択します。
Data Integration ページの上部メニューバーで、[プロジェクト] を選択します。Dev-Prod モードの場合は、環境も選択する必要があります。
左側のナビゲーションウィンドウで [バッチパイプライン] をクリックします。[バッチパイプライン] リストから構成するオフラインパイプラインをクリックし、構成ページを開きます。
ページ右上隅の [コンポーネントライブラリ] をクリックして、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネルの左側ナビゲーションウィンドウで [出力] を選択します。右側の出力コンポーネント一覧から [Lindorm (コンピュートエンジン)] コンポーネントを見つけ、キャンバス上にドラッグします。
上流コンポーネントの
 アイコンをクリックしてドラッグし、Lindorm (コンピュートエンジン) 出力コンポーネントに接続します。
アイコンをクリックしてドラッグし、Lindorm (コンピュートエンジン) 出力コンポーネントに接続します。Lindorm (コンピュートエンジン) 出力コンポーネントカード上の
 アイコンをクリックして、[Lindorm (コンピュートエンジン) 出力構成] ダイアログボックスを開きます。
アイコンをクリックして、[Lindorm (コンピュートエンジン) 出力構成] ダイアログボックスを開きます。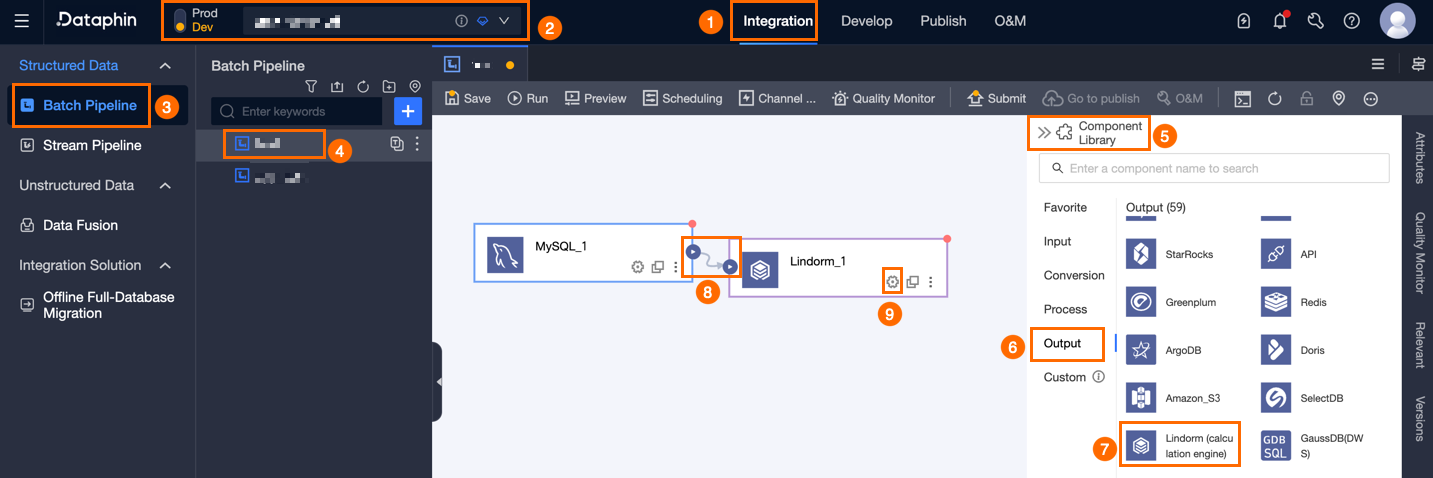
[Lindorm (コンピュートエンジン) 出力構成] ダイアログボックスで、以下のパラメーターを構成します。
パラメーター
説明
基本設定
ステップ名
Lindorm (コンピュートエンジン) 出力コンポーネントの名前です。Dataphin が自動的にステップ名を生成しますが、必要に応じて変更できます。命名規則は以下のとおりです。
使用できる文字は、漢字、英字、アンダースコア (_)、数字のみです。
文字数は 64 文字以内である必要があります。
データソース
「データソース」ドロップダウンリストには、Dataphin 内のすべての Lindorm (コンピュートエンジン) データソースが表示されます。各データソースに対してライトスルー権限があるかどうかも表示されます。
 アイコンをクリックすると、データソース名をコピーできます。
アイコンをクリックすると、データソース名をコピーできます。特定のデータソースに対するライトスルー権限がない場合は、そのデータソースの横にある [リクエスト] をクリックして権限をリクエストしてください。詳細については、「データソース権限のリクエスト」をご参照ください。
Lindorm (コンピュートエンジン) データソースがない場合は、[作成] をクリックして作成してください。詳細については、「Lindorm (コンピュートエンジン) データソースの作成」をご参照ください。
テーブル
出力データのターゲットテーブルを選択します。
 アイコンをクリックすると、選択したテーブル名をコピーできます。重要
アイコンをクリックすると、選択したテーブル名をコピーできます。重要テーブルスキーマが変更された場合、パイプラインノードを再構成する必要があります。
ファイルエンコーディング
UTF-8 および GBK をサポートしています。
ローディングポリシー
データの追加と全データの上書きをサポートしています。
データの追加:ターゲットテーブルに直接データを追加します。
全データの上書き:まずターゲットテーブルまたは構成済みパーティション内のすべてのデータを削除し、その後新しいデータを書き込みます。
圧縮フォーマット
このパラメーターは任意です。ソースファイルが圧縮されている場合、対応する圧縮フォーマットを選択することで、Dataphin がファイルを解凍できるようになります。サポートされるフォーマットは、zlib、hadoop-snappy、lz4、none です。デフォルトでは、ORC テーブルは zlib 圧縮を使用します。他のフォーマットのテーブルにはデフォルトの圧縮フォーマットはありません。
パフォーマンス構成
出力テーブルが ORC フォーマットでフィールド数が多いシナリオでは、この構成を調整できます。メモリが十分にある場合は値を増やすことで書き込みパフォーマンスが向上します。メモリが不足している場合は値を減らすことでガベージコレクション (GC) 時間を短縮し、書き込みパフォーマンスを向上できます。デフォルト値はバイト単位で
{"hive.exec.orc.default.buffer.size":16384}です。262,144 バイト (256 KB) を超える値を設定しないでください。パーティション
Iceberg フォーマット以外のパーティションテーブルの場合、書き込み操作用に固定の静的パーティション(例:
hh=xx,mm=xx)を構成します。Iceberg フォーマットのパーティションテーブルは動的パーティションをサポートしており、パーティションを構成する必要はありませんが、フィールドマッピングにパーティションフィールドを含める必要があります。静的パーティションが構成されている場合は、それが書き込み操作に使用されます。準備ステートメント
データインポート前にデータベースで実行する SQL スクリプトです。
終了ステートメント
データインポート後にデータベースで実行される SQL スクリプトです。
フィールドマッピング
入力フィールド
上流コンポーネントからの入力フィールドを表示します。
出力フィールド
出力フィールドを表示します。[フィールド管理] をクリックして出力フィールドを選択します。
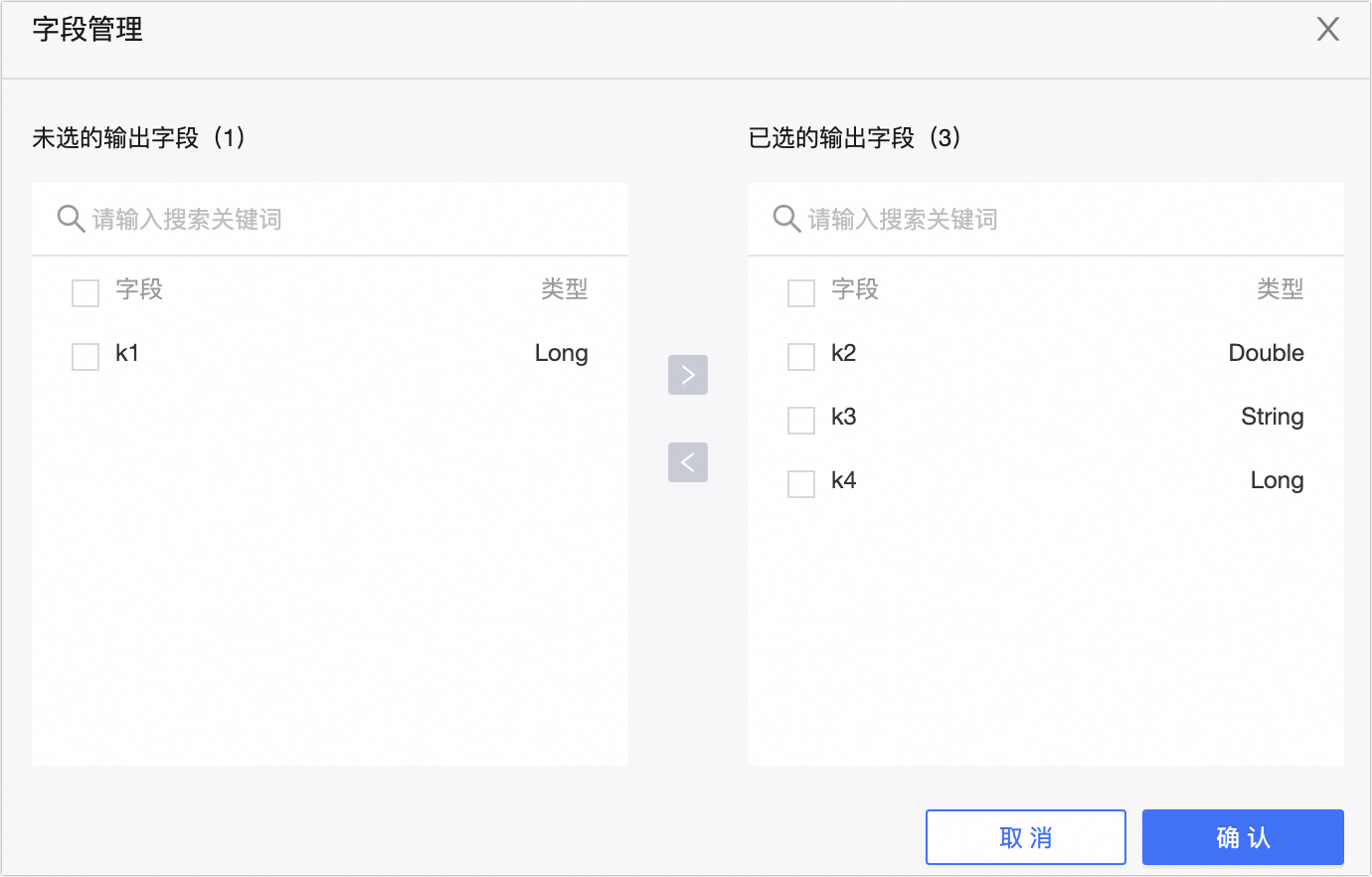
 アイコンをクリックすると、[選択済み入力フィールド] が [未選択入力フィールド] に移動します。
アイコンをクリックすると、[選択済み入力フィールド] が [未選択入力フィールド] に移動します。 アイコンをクリックすると、[未選択入力フィールド] が [選択済み入力フィールド] に移動します。
アイコンをクリックすると、[未選択入力フィールド] が [選択済み入力フィールド] に移動します。
マッピング
マッピングは、ソーステーブルの入力フィールドとターゲットテーブルの出力フィールドを接続します。マッピングには、同名マッピングと同行マッピングがあります。各シナリオは以下のとおりです。
同名マッピング:同じ名前のフィールドをマッピングします。
同行マッピング:ソーステーブルとターゲットテーブルのフィールド名が一致しませんが、対応する行のデータをマッピングする必要があります。同一行のフィールドのみをマッピングします。
[確認] をクリックして、Lindorm (コンピュートエンジン) 出力コンポーネント の構成を保存します。