Greenplum 出力コンポーネントを設定して、外部データベースから Greenplum へデータを書き込んだり、ビッグデータプラットフォームに接続されたストレージシステムから Greenplum へデータをレプリケーションおよびプッシュしたりします。これにより、データ統合および再処理が可能になります。本トピックでは、Greenplum 出力コンポーネントの設定方法について説明します。
前提条件
Greenplum データソースが作成されました。詳細については、「Greenplum データソースの作成」をご参照ください。
Greenplum 出力コンポーネントのプロパティを設定する際に使用するアカウントには、データソースに対するリードスルー権限が必要です。権限がない場合は、データソースの権限を申請してください。詳細については、「データソース権限の申請」をご参照ください。
操作手順
Dataphin のホームページで、上部メニューバーから [開発] > [Data Integration] を選択します。
統合ページの上部メニューバーで、[プロジェクト] を選択します(Dev-Prod モードの場合は、[環境] を選択します)。
左側ナビゲーションウィンドウで、[バッチパイプライン] をクリックします。[バッチパイプライン] の一覧から、開発対象の [オフラインパイプライン] をクリックして、その構成ページを開きます。
ページの右上隅で、[コンポーネントライブラリ] をクリックし、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネルの左側ナビゲーションウィンドウで、[出力] を選択します。その後、右側の出力コンポーネント一覧から [Greenplum] コンポーネントを見つけ、キャンバスにドラッグします。
対象の入力・変換・フローコンポーネントの
 アイコンをクリックしてドラッグし、現在の Greenplum 出力コンポーネントに接続します。
アイコンをクリックしてドラッグし、現在の Greenplum 出力コンポーネントに接続します。Greenplum 出力コンポーネントカード内の
 アイコンをクリックして、[Greenplum 出力構成] ダイアログボックスを開きます。
アイコンをクリックして、[Greenplum 出力構成] ダイアログボックスを開きます。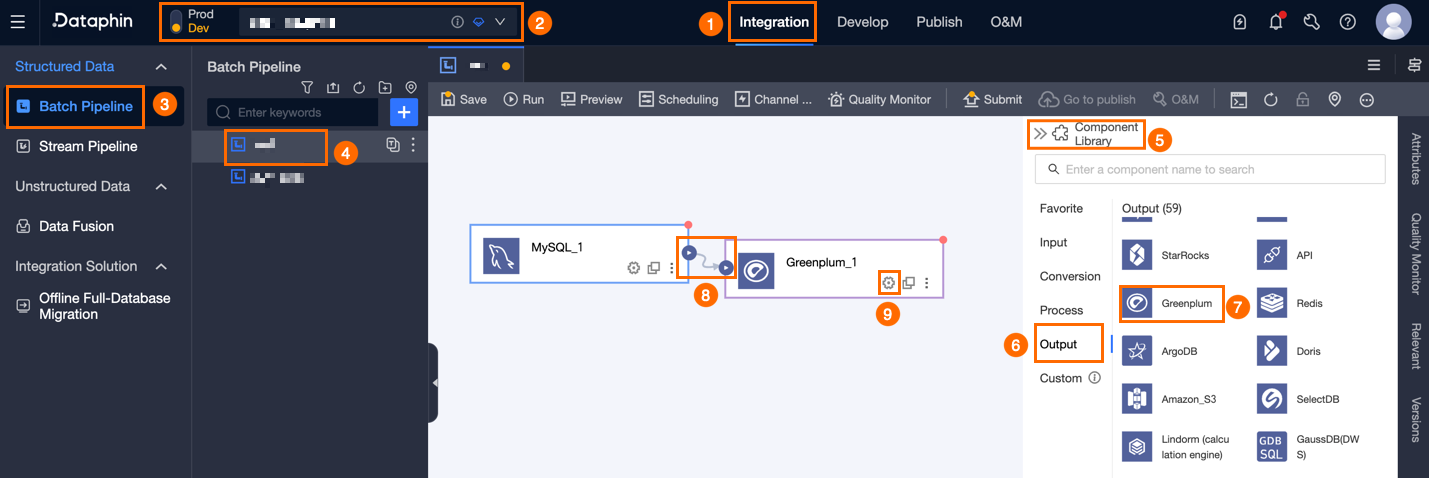
[Greenplum] [出力構成] ダイアログボックスで、パラメーターを設定します。
パラメーター
説明
[基本設定]
[ステップ名]
Greenplum 出力コンポーネントの名前です。Dataphin が自動的にステップ名を生成しますが、必要に応じて変更可能です。命名規則は以下のとおりです:
中国語文字、英字、アンダースコア (_)、数字のみ使用できます。
最大 64 文字までです。
データソース
データソースのドロップダウンリストには、ライトスルー権限を持つ Greenplum データソースおよび権限を持たないデータソースの両方が表示されます。
ライトスルー権限を持たないデータソースの場合、データソース横の [リクエスト] をクリックしてライトスルー権限を申請します。詳細については、「データソース権限の申請」をご参照ください。
Greenplum データソースが存在しない場合は、
 新規アイコンをクリックして作成します。詳細については、「Greenplum データソースの作成」をご参照ください。
新規アイコンをクリックして作成します。詳細については、「Greenplum データソースの作成」をご参照ください。
スキーマ
データベースからスキーマを選択します。このパラメーターは必須です。データソース接続情報に既にスキーマが含まれている場合、設定したスキーマがデフォルトで使用されます。また、権限のある他のスキーマも選択可能です。
テーブル
出力データの対象テーブルを選択します。
Greenplum データソースにデータ同期用の対象テーブルが存在しない場合、ワンクリックテーブル作成機能を使用して、対象テーブルをすばやく生成できます。手順は以下のとおりです:
[ワンクリックテーブル作成] をクリックします。Dataphin が対象テーブル作成用の SQL スクリプトを自動的にマッチングし、対象テーブル名(デフォルトでソーステーブル名)、フィールド型(Dataphin のフィールドに基づいて初期変換)、その他の情報を含めます。下図はその例です:
必要に応じて、対象テーブル作成用の SQL スクリプトを編集し、[新規] をクリックします。対象テーブルが作成されると、Dataphin は自動的に新しい対象テーブルを出力データの対象テーブルとして使用します。
説明開発環境に同名のテーブルが既に存在する場合、[新規] をクリックすると「テーブルが既に存在します」というエラーが表示されます。
[本番テーブル未存在時のポリシー]
本番テーブルが存在しない場合の処理ポリシーです。[処理しない] または [自動作成] を選択します。デフォルト値は [自動作成] です。[処理しない] を選択した場合、タスク公開時に本番テーブルは作成されません。[自動作成] を選択した場合、タスク公開時にターゲット環境に同名のテーブルが作成されます。
[処理しない]:対象テーブルが存在しない場合、タスク送信時に「対象テーブルが存在しません」というメッセージが表示されますが、タスクの公開は可能です。この場合、タスク実行前に本番環境で対象テーブルを作成してください。
[自動作成]:必ず [テーブル作成文の編集] を実行してください。この欄には、選択したテーブルのテーブル作成文が事前に挿入されており、必要に応じて編集可能です。ただし、テーブル名はプレースホルダー
${table_name}のみを指定できます。このプレースホルダーのみがサポートされています。実行時に、実際のテーブル名に置き換えられます。対象テーブルが存在しない場合、システムはテーブル作成文に基づいてテーブルを作成します。テーブル作成に失敗した場合、公開チェック結果は「失敗」になります。エラーメッセージに基づいてテーブル作成文を修正し、再度タスクを公開してください。対象テーブルが既に存在する場合は、テーブルは作成されません。
説明このパラメーターは、Dev-Prod モードのプロジェクトでのみサポートされます。
読み込みポリシー
[データ追加] または [コピー] のいずれかのポリシーを選択します:
[データ追加]:プライマリキー/制約の競合が発生した場合、ダーティデータエラーが通知されます。
[コピーポリシー]:システムは選択した競合解決ポリシーに基づいて処理を行います。このポリシーはテーブルのみをサポートし、ビューには対応していません。
[競合解決ポリシー]
[ロードポリシー] を [コピー] に設定した場合に、競合解決ポリシーを選択します。Greenplum では [競合時にエラーを報告] のみがサポートされています。
[バッチ書き込みデータ量](任意)
一度に書き込むデータ量です。[バッチ書き込みレコード数] も設定可能です。書き込み処理中は、どちらかの上限設定値(バッチ書き込みデータ量またはレコード数)に先に達した時点で書き込みが実行されます。デフォルト値は 32 MB です。
[バッチ書き込みレコード数](任意)
デフォルト値は 2,048 レコード です。データ書き込み時は、バッチ書き込みポリシーが適用されます。関連するパラメーターには [バッチ書き込みレコード数] および [バッチ書き込みデータ量] があります。
累積データ量がいずれかの上限設定値(バッチ書き込みデータ量またはレコード数)に達した時点で、1 バッチ分のデータが満了したものと見なされ、直ちに宛先へ書き込まれます。
バッチ書き込みデータ量を 32 MB に設定します。バルク挿入レコード数の上限は、単一レコードの実際のサイズに応じて柔軟に調整してください。通常は、バッチ書き込みの利点を十分に活用できるよう、より大きな値を設定することを推奨します。例えば、単一レコードのサイズが約 1 KB の場合、バルク挿入バイトサイズを 16 MB に設定します。この条件を踏まえると、バルク挿入レコード数は「16 MB ÷ 単一レコードサイズ(1 KB)=16,384 レコード」を超える値に設定します。ここでは、20,000 レコード に設定したと仮定します。この設定後、システムはバルク挿入バイトサイズに基づいてバッチ書き込み操作をトリガーします。累積データ量が 16 MB に達するたびに、書き込み操作が実行されます。
[準備文](任意)
データインポート前にデータベース上で実行される SQL スクリプトです。
例:サービスの可用性を継続的に確保するために、このステップによるデータ書き込みの前にターゲットテーブル Target_A を作成し、Target_A へデータを書き込み、このステップの書き込み完了後に、データベース内で継続的にサービスを提供しているテーブル Service_B を Temp_C にリネームし、次に Target_A を Service_B にリネームし、最後に Temp_C を削除します。
[終了文](任意)
データインポート後にデータベース上で実行される SQL スクリプトです。
フィールドマッピング
[入力フィールド]
システムは、上流コンポーネントの出力に基づいて入力フィールドを表示します。
[出力フィールド]
システムは出力フィールドを表示します。以下の操作がサポートされています:
フィールド管理:[フィールド管理] をクリックして、出力フィールドを選択します。

 アイコンをクリックして、[選択済み入力フィールド] を [未選択入力フィールド] に移動します。
アイコンをクリックして、[選択済み入力フィールド] を [未選択入力フィールド] に移動します。 アイコンをクリックして、[未選択入力フィールド] を [選択済み入力フィールド] に移動します。
アイコンをクリックして、[未選択入力フィールド] を [選択済み入力フィールド] に移動します。
一括追加:[一括追加] をクリックします。JSON、TEXT、DDL 形式の一括構成をサポートしています。
JSON 形式で一括構成します。例:
// 例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]説明name はインポート対象フィールドの名前、type はインポート後のフィールド型を示します。例えば、
"name":"user_id","type":"String"は、user_id という名前のフィールドをインポートし、そのフィールド型を String に設定することを意味します。TEXT 形式で一括構成します。例:
// 例: user_id,String user_name,String行区切り文字は各フィールドの情報を区切ります。デフォルト値は改行 (\n) です。改行 (\n)、セミコロン (;)、ピリオド (.) をサポートしています。
列区切り文字はフィールド名とフィールド型を区切ります。デフォルト値はカンマ (,) です。
DDL 形式で一括構成します。例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
新規出力フィールド:[+新規出力フィールド] をクリックし、ページに従って [列] を入力し、[型] を選択します。現在の行の設定が完了したら、
 アイコンをクリックして保存します。
アイコンをクリックして保存します。
[フィールドマッピング]
上流の入力フィールドと対象テーブルのフィールドに基づいて、手動でフィールドマッピングを選択します。[クイックマッピング] には [行ベースマッピング] および [名前ベースマッピング] が含まれます。
名前ベースマッピング:フィールド名が一致するフィールドをマッピングします。
行ベースマッピング:ソーステーブルと対象テーブルのフィールド名が異なるものの、対応する行のデータをマッピングする必要があります。同一行のフィールドのみをマッピングします。
[確認] をクリックして、[Greenplum 出力ウィジェット] の構成を完了します。