Doris 出力コンポーネントを使用して、外部データベースから Doris にデータを書き込みます。また、ビッグデータプラットフォームに接続されたストレージシステムから Doris にデータを複製・プッシュして、Data Integration やさらなる処理を行うこともできます。このトピックでは、Doris 出力コンポーネントの設定方法について説明します。
前提条件
Doris データソースが作成されていること。詳細については、「Doris データソースの作成」をご参照ください。
Doris 出力コンポーネントを設定するために使用するアカウントには、データソースに対するライトスルー権限が必要です。この権限がない場合は、権限をリクエストしてください。詳細については、「データソース権限のリクエスト」をご参照ください。
操作手順
Dataphin のホームページで、上部のメニューバーにある [開発] をクリックし、次に [Data Integration] をクリックします。
「データ統合」ページで、上部メニューバーの[プロジェクト]をクリックします。Dev-Prod モードでは、環境も選択します。
左側のナビゲーションウィンドウで、[バッチパイプライン] をクリックします。[バッチパイプライン] リストで、開発したいオフラインパイプラインをクリックします。そのオフラインパイプラインの設定ページが開きます。
ページの右上隅にある [コンポーネントライブラリ] をクリックして、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネルの左側のナビゲーションウィンドウで、[出力] をクリックします。右側の出力コンポーネントリストで [Doris] コンポーネントを見つけ、キャンバスにドラッグします。
ターゲットの入力、変換、またはフローコンポーネントの
 アイコンをクリックしてドラッグし、Doris 出力コンポーネントに接続します。
アイコンをクリックしてドラッグし、Doris 出力コンポーネントに接続します。Doris 出力コンポーネントカードで、
 アイコンをクリックして [Doris 出力設定] ダイアログボックスを開きます。
アイコンをクリックして [Doris 出力設定] ダイアログボックスを開きます。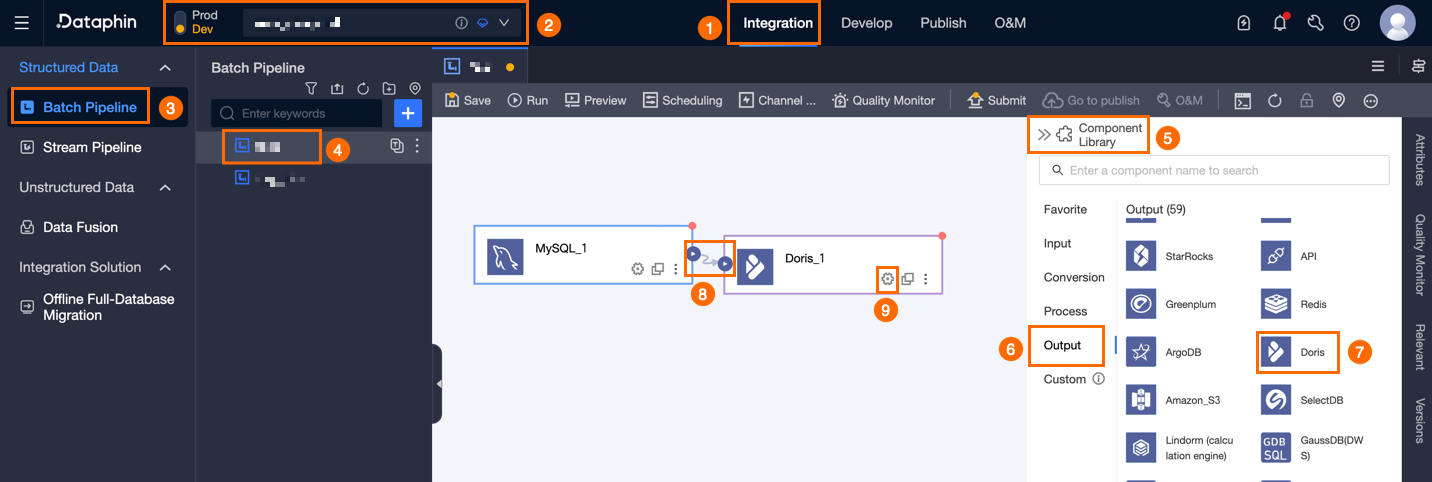
[Doris 出力設定] ダイアログボックスで、次の表のパラメーターを設定します。
パラメーター
説明
[基本設定]
ステップ名
Doris 出力コンポーネントの名前です。Dataphin は自動的にステップ名を生成しますが、ビジネスシナリオに基づいて変更できます。命名ルールは次のとおりです:
漢字、英字、アンダースコア (_)、数字のみを使用します。
名前の長さは 64 文字以内にしてください。
[データソース]
ドロップダウンリストには、ライトスルー権限を持つデータソースと持たないデータソースを含む、すべての Doris データソースが表示されます。
 アイコンをクリックして、現在のデータソース名をコピーします。
アイコンをクリックして、現在のデータソース名をコピーします。データソースに対するライトスルー権限がない場合は、データソースの横にある [リクエスト] をクリックしてライトスルー権限をリクエストします。詳細については、「データソース権限のリクエスト」をご参照ください。
Doris データソースがない場合は、[データソースの作成] をクリックして作成します。詳細については、「Doris データソースの作成」をご参照ください。
テーブル
出力データのターゲットテーブルを選択します。キーワードを入力してテーブルを検索するか、正確なテーブル名を入力して [完全一致] をクリックします。テーブルを選択すると、システムが自動的にそのステータスを確認します。
 アイコンをクリックして、選択したテーブル名をコピーします。
アイコンをクリックして、選択したテーブル名をコピーします。ターゲットテーブルが Doris データソースに存在しない場合は、ワンクリックテーブル作成機能を使用して迅速に生成できます。手順は次のとおりです:
[ワンクリックテーブル作成] をクリックします。Dataphin は、ターゲットテーブルを作成するための SQL スクリプトを自動的に生成します。これには、テーブル名 (デフォルト:ソーステーブル名) とフィールドタイプ (Dataphin フィールドから変換) が含まれます。
必要に応じて SQL スクリプトを修正し、[作成] をクリックします。テーブルが作成されると、Dataphin はそれを出力データのターゲットテーブルとして使用します。
説明同じ名前のテーブルが開発環境に既に存在する場合、[作成] をクリックするとエラーが返されます。
一致するテーブルが見つからない場合でも、手動で入力したテーブル名を使用してデータを統合できます。
[本番テーブルが見つからない場合の戦略]
本番テーブルが見つからない場合の処理方法を選択します。[アクションなし] または [自動作成] を選択できます。デフォルトは [自動作成] です。「[アクションなし]」を選択した場合、タスクは本番テーブルを作成せずに公開されます。「[自動作成]」を選択した場合、タスクは公開時にターゲット環境に同じ名前のテーブルを作成します。
[何もしない]:ターゲットテーブルが存在しない場合、システムは送信時に警告を表示しますが、タスクの公開は許可されます。タスクを実行する前に、本番環境でターゲットテーブルを手動で作成する必要があります。
[自動作成]:[テーブル作成文の編集] を行う必要があります。選択したテーブルのテーブル作成文がデフォルトで事前入力されており、調整することができます。文中のテーブル名はプレースホルダー
${table_name}を使用しており、このプレースホルダーのみがサポートされています。実行時に実際のテーブル名に置き換えられます。ターゲットテーブルが存在しない場合、Dataphin はまず CREATE TABLE 文を実行します。テーブルの作成に失敗した場合、公開は失敗します。エラーメッセージに基づいて文を修正し、再公開してください。ターゲットテーブルが既に存在する場合、操作は行われません。
説明この設定は、開発・本番モードのプロジェクトでのみ利用可能です。
[データフォーマット]
[CSV] または [JSON] を選択します。
[CSV] を選択した場合は、[CSV 列区切り文字] と [CSV 行区切り文字] も設定します。
[CSV 列区切り文字] (任意)
StreamLoad の CSV インポートでは、ここで列区切り文字を設定します。デフォルト:
_@dp@_。デフォルトを使用する場合は、この値を明示的に指定しないでください。データに_@dp@_が含まれている場合は、別の文字を区切り文字として使用してください。[CSV 行区切り文字] (任意)
StreamLoad の CSV インポートでは、ここで行区切り文字を設定します。デフォルト:
_#dp#_。デフォルトを使用する場合は、この値を明示的に指定しないでください。データに_#dp#_が含まれている場合は、別の文字を区切り文字として使用してください。[一括書き込みサイズ] (任意)
1 回のバッチで書き込まれるデータのサイズです。[一括書き込み件数] も設定できます。いずれかの制限に達すると、システムはデータを書き込みます。デフォルト:32 MB。
[一括書き込み件数] (任意)
デフォルト:2,048 行。データ同期中、システムは [一括書き込み件数] と [一括書き込みサイズ] の 2 つの設定を使用して書き込みをバッチ処理します。
蓄積されたデータがいずれかの制限 (サイズまたは件数) に達すると、システムはそれを完全なバッチとして扱い、一度にターゲットに書き込みます。
一括書き込みサイズを 32 MB に設定することを推奨します。平均レコードサイズに基づいて一括書き込み件数を調整してください。バッチ効率を最大化するために高く設定します。たとえば、各レコードが約 1 KB の場合、一括書き込みサイズを 16 MB、一括書き込み件数を 16,384 (16 MB ÷ 1 KB) 以上に設定します。ここでは、20,000 行を使用します。この設定では、蓄積されたデータが 16 MB に達すると、システムはバッチ書き込みをトリガーします。
[事前 SQL 文] (任意)
データをインポートする前にデータベースで実行する SQL スクリプトです。
たとえば、サービスの可用性を維持するために、次のシーケンスを実行します:ターゲットテーブル Target_A を作成し、Target_A にデータを書き込み、サービス中のテーブル Service_B を Temp_C に名前変更し、Target_A を Service_B に名前変更し、Temp_C を削除します。
[事後 SQL 文] (任意)
データのインポート後にデータベースで実行する SQL スクリプトです。
フィールド マッピング
[入力フィールド]
上流コンポーネントからの入力フィールドを一覧表示します。
出力フィールド
出力フィールドを一覧表示します。次の操作が可能です:
フィールドの管理:[フィールド管理] をクリックして出力フィールドを選択します。

 アイコンをクリックして、[選択された入力フィールド] を [未選択の入力フィールド] に移動します。
アイコンをクリックして、[選択された入力フィールド] を [未選択の入力フィールド] に移動します。 アイコンをクリックして、[未選択の入力フィールド] を [選択された入力フィールド] に移動します。
アイコンをクリックして、[未選択の入力フィールド] を [選択された入力フィールド] に移動します。
一括追加:[一括追加] をクリックして、JSON、TEXT、DDL 形式を使用して項目を一括で設定します。
JSON 形式の例:
// 例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]説明nameフィールドはインポートするフィールドの名前を指定し、typeフィールドはインポート後のフィールドタイプを指定します。たとえば、"name":"user_id","type":"String"は、名前がuser_idのフィールドをインポートし、そのフィールドタイプをStringに設定します。TEXT 形式で複数の設定を構成できます。例:
// 例: user_id,String user_name,String行区切り文字はフィールドエントリを区切ります。デフォルト:改行 (\n)。サポートされている区切り文字:\n、セミコロン (;)、ピリオド (.)。
列区切り文字はフィールド名とフィールドタイプを区切ります。デフォルト:カンマ (,)。
DDL 形式での一括設定。例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
出力フィールドの作成:[+ 出力フィールドの作成] をクリックします。[列] 名を入力し、[タイプ] を選択します。
 アイコンをクリックして行を保存します。
アイコンをクリックして行を保存します。
マッピング
入力フィールドをターゲットテーブルのフィールドに手動でマッピングします。[クイックマッピング] には [行マッピング] と [名前マッピング] が含まれます。
名前マッピング:同じ名前のフィールドをマッピングします。
行マッピング:ソースとターゲットのフィールド名が異なるが、行の位置が一致する場合に、位置によってフィールドをマッピングします。
[確認] をクリックして、[Doris 出力コンポーネント] の設定を完了します。