Dameng (DM) 出力コンポーネントは、外部データベースから DM データベースへデータを書き込みます。また、ビッグデータプラットフォームに接続されたストレージシステムから DM データベースへデータをコピーし、統合および再処理を行うこともできます。本トピックでは、DM 出力コンポーネントの設定手順について説明します。
前提条件
Dameng (DM) データソースが作成されました。詳細については、「Dameng (DM) データソースを作成する」をご参照ください。
DM 出力コンポーネントの設定に使用するアカウントが、対象データソースに対してライトスルー権限を有している必要があります。該当の権限がない場合は、事前に権限の付与をリクエストしてください。詳細については、「データソース権限のリクエスト、更新、返却」をご参照ください。
操作手順
Dataphin ホームページで、トップメニューバーから [開発] > [データ統合] を選択します。
統合ページ上部のメニューバーから、**[プロジェクト]** を選択します。Dev-Prod モードの場合は、さらに **[環境]** も選択します。
左側のナビゲーションウィンドウで、[オフライン統合] をクリックします。[オフライン統合] リストで、開発するオフラインパイプラインをクリックして、その構成ページを開きます。
ページの右上隅で、[コンポーネントライブラリ] をクリックして、[コンポーネントライブラリ] パネルを開きます。
左側の[コンポーネント ライブラリ]パネルのナビゲーションウィンドウで、[出力]を選択します。右側の出力コンポーネント一覧から[DM]コンポーネントを見つけ、キャンバスにドラッグします。
ソース入力、変換、またはフローコンポーネントの
 アイコンをクリックしてドラッグし、DM 出力コンポーネントに接続します。
アイコンをクリックしてドラッグし、DM 出力コンポーネントに接続します。DM出力コンポーネントカードの
 アイコンをクリックして、[Dameng出力設定]ダイアログボックスを開きます。
アイコンをクリックして、[Dameng出力設定]ダイアログボックスを開きます。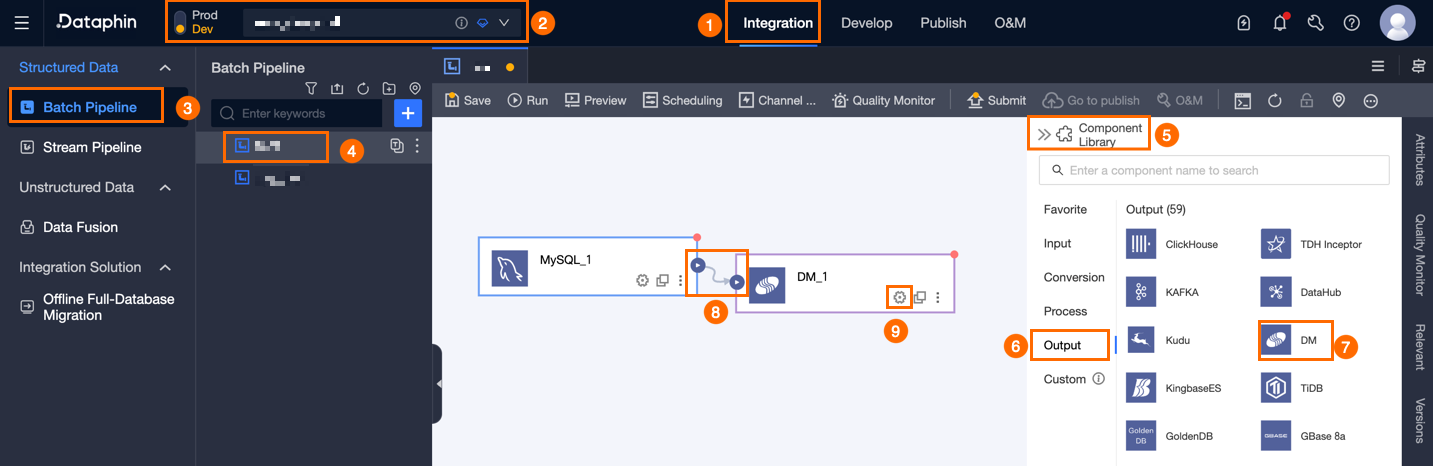
[Dameng Output Configuration] ダイアログボックスで、次の表に示すパラメーターを設定します。
パラメーター
説明
基本設定
ステップ名
DM 出力コンポーネントの名前です。Dataphin が自動的にステップ名を生成しますが、必要に応じて変更可能です。命名規則は以下のとおりです。
使用可能な文字は、漢字、英字、アンダースコア (_ )、数字のみです。
名前の長さは 64 文字以内である必要があります。
データソース
ドロップダウンリストには、すべての DM データソースが表示されます。これは、ライトスルー権限を有するデータソースと、権限を有しないデータソースの両方を含みます。現在のデータソース名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。ライトスルー権限がないデータソースについては、データソースの横にある[リクエスト] をクリックして権限を申請してください。詳細については、「データソース権限の申請、更新、返却」をご参照ください。
DM データソースがない場合は、[データソースの作成] をクリックして作成します。詳細については、「Dameng (DM) データソースを作成する」をご参照ください。
テーブル
出力データの対象テーブルを選択します。テーブルを検索するには、キーワードを入力するか、正確なテーブル名を入力して [完全一致検索] をクリックします。テーブルを選択すると、システムが自動的にそのステータスを確認します。選択したテーブルの名前をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。データ同期のターゲットテーブルが DM データソースに存在しない場合、[ワンクリックテーブル作成] 機能を使用して、すばやく作成できます。手順は次のとおりです:
[One-click Table Creation] をクリックします。Dataphin は、ターゲットテーブルを作成するコードを自動的に生成します。これには、ソーステーブル名をデフォルトとするターゲットテーブル名と、Dataphin のフィールドに基づいて最初に変換されるフィールドタイプが含まれます。
必要に応じて、ターゲットテーブルを作成するためのSQL スクリプトを変更し、次に [作成] をクリックします。ターゲットテーブルが作成されると、Dataphin は自動的にそれを出力データのターゲットテーブルとして設定します。
説明開発環境に同名のテーブルが存在する場合、**[作成]** をクリックするとエラーが報告されます。
本番テーブル欠落時のポリシー
本番テーブルが存在しない場合に適用するポリシーです。[処理しない] または [自動作成] を選択できます。デフォルト値は [自動作成] です。[処理しない] を選択した場合、ノードの公開時に本番テーブルは作成されません。[自動作成] を選択した場合、ノードの公開時にターゲット環境に同じ名前のテーブルが作成されます。
[処理しない]: ターゲットテーブルが存在しない場合、送信時にメッセージが表示されますが、ノードは引き続き公開できます。その後、ノードを実行できるようになる前に、本番環境でターゲットテーブルを手動で作成する必要があります。
自動作成: テーブル作成文を編集する必要があります。選択したテーブルの文はデフォルトで入力され、これを修正することができます。文中のテーブル名には
${table_name}プレースホルダーを使用します。これはサポートされている唯一のプレースホルダーです。実行時に、このプレースホルダーは実際のテーブル名に置き換えられます。対象テーブルが存在しない場合、システムはまずテーブル作成文を用いてテーブルを作成しようと試みます。作成に失敗した場合、公開チェックも失敗します。その後、エラーメッセージに基づいて文を修正し、再度公開を試行できます。対象テーブルがすでに存在する場合は、テーブル作成文は実行されません。
説明このパラメーターは、Dev-Prod モードのプロジェクトでのみサポートされます。
ロードポリシー
ターゲットテーブルへのデータ書き込みのポリシーを選択します。[ローディング ポリシー] includes:
[データを追加 (INSERT INTO)]:プライマリキーまたは制約違反が発生した場合、ダーティデータ エラーが報告されます。
プライマリキーの競合時に更新 (マージ): プライマリキーまたは制約違反が発生した場合、既存のレコードのマップされたフィールドのデータが更新されます。
ライトスルー
プライマリキー更新構文は原子的処理ではありません。書き込むデータに**重複するプライマリキーが含まれる場合**は、必ず**ライトスルーを有効化**してください。それ以外の場合は並列書き込みが使用されます。ライトスルーのパフォーマンスは並列書き込みよりも低くなります。
説明このパラメーターは、[ローディングポリシー] が「**[プライマリキー衝突時の更新]**」に設定されている場合にのみ利用可能です。
バッチ書き込みデータ量(任意)
1 回のバッチで書き込むデータ量です。[バッチ書き込みレコード数] も設定できます。データを書き込む際、2 つの制限のいずれかに達すると、システムは書き込み操作を実行します。デフォルト値は 32 MB です。
一括書き込みレコード数(オプション)
デフォルト値は 2,048 レコードです。データ同期では、バッチ書き込み戦略が使用されます。この戦略のパラメーターには、[バッチ書き込みレコード数] と [バッチ書き込みデータボリューム] が含まれます。
累積データが設定されたいずれかの制限値(データ量またはレコード数)に達した時点で、システムはバッチが満杯と判断し、直ちに宛先へ書き込みを行います。
バッチ書き込みデータ量を 32 MB に設定します。バッチ書き込みレコード数は、1 レコードあたりのサイズに応じて調整してください。大きな値を設定することで、バッチ書き込みのメリットを最大限に活用できます。たとえば、1 レコードが約 1 KB の場合、バッチ書き込みデータ量を 16 MB に設定し、バッチ書き込みレコード数を 16,384(16 MB ÷ 1 KB)より大きい値(例:**20,000**)に設定します。この設定により、累積データが 16 MB に達した時点でバッチ書き込みがトリガーされます。
準備ステートメント (任意)
データインポート前にデータベース上で実行する SQL スクリプトです。
たとえば、サービスの継続的な可用性を確保するために、このステップによるデータ書き込みの前に Target_A という名前の対象テーブルを作成できます。このステップでは、データを Target_A へ書き込みます。書き込み完了後、アクティブなサービステーブル Service_B を Temp_C にリネームし、Target_A を Service_B にリネームしてから、Temp_C を削除します。
実行後文 (任意)
データインポート後にデータベース上で実行する SQL スクリプトです。
フィールドマッピング
入力フィールド
上流コンポーネントからの出力に基づいて入力フィールドが表示されます。
出力フィールド
出力フィールドが表示されます。以下の操作がサポートされます。
フィールド管理: [フィールド管理] をクリックして、出力フィールドを選択します。

 アイコンをクリックして、[選択済み入力フィールド] から [未選択入力フィールド] へフィールドを移動します。
アイコンをクリックして、[選択済み入力フィールド] から [未選択入力フィールド] へフィールドを移動します。 アイコンをクリックして、フィールドを [未選択の入力フィールド] から [選択済みの入力フィールド] に移動します。
アイコンをクリックして、フィールドを [未選択の入力フィールド] から [選択済みの入力フィールド] に移動します。
バッチ追加: [バッチ追加] をクリックして、JSON、TEXT、または DDL フォーマットを使用してフィールドを一括で設定します。
JSON 形式での設定例:
// 例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]説明name はインポート対象フィールドの名前、type はインポート後のフィールドのデータの型を指定します。たとえば、
"name":"user_id","type":"String"は、user_id という名前のフィールドをインポートし、そのデータの型を String に設定します。TEXT 形式での設定例:
// 例: user_id,String user_name,String行区切り文字は各フィールドの情報を区切ります。デフォルトの区切り文字は改行 (\n) ですが、セミコロン (;) やピリオド (.) もサポートされます。
列区切り文字はフィールド名とフィールドの型を区切ります。デフォルトの区切り文字はカンマ (,) です。
DDL 形式での設定例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
出力フィールドの作成: [+ 出力フィールドの作成] をクリックし、[カラム] 名を入力し、[タイプ] を選択します。現在の行を設定した後、
 アイコンをクリックして保存します。
アイコンをクリックして保存します。
マッピング
上流コンポーネントからの入力とターゲットテーブルのフィールドに基づいて、フィールドを手動でマップします。[マッピング] には、[行単位でマップ] と [名前でマップ] が含まれます。
[名前単位マッピング]:名前が一致するフィールドをマッピングします。
[行単位マッピング]:ソーステーブルと対象テーブルで名前が異なっていても、同一行にあるフィールドをマッピングします。同一行に位置するフィールドのみがマッピング対象となります。
「[確認]」をクリックして、[Dameng 出力コンポーネント]の構成を完了します。