オフラインデータベース移行を使用すると、データセンターまたは ECS インスタンス上の自己構築データベースからビッグデータコンピュートサービスにデータを同期できます。サポートされているサービスには、MaxCompute、Hive、TDH Inceptor が含まれます。このトピックでは、データベース移行タスクを作成して設定する方法について説明します。
前提条件
移行に必要なデータソースを作成する必要があります。データベース移行は、MySQL、Microsoft SQL Server、Oracle、OceanBase などのさまざまなソースデータベースからのデータをサポートします。詳細については、「データベース移行でサポートされているデータソース」をご参照ください。
機能紹介
オフラインデータベース移行は、効率を向上させ、コストを削減するツールです。単一のオフラインパイプラインとは異なり、オフラインデータベース移行では、一括操作で複数のオフラインパイプラインを設定できます。これにより、複数のデータベーステーブルを一度に同期できます。
手順
Dataphin のホームページで、トップメニューバーから [開発] > [データ統合] を選択します。
トップメニューバーで、目的の プロジェクト を選択します。
左側のナビゲーションウィンドウで、[データベース移行] > [オフラインデータベース移行] を選択します。
[オフラインデータベース移行] ページで、パラメーターを構成します。次の表にパラメーターを示します。
基本情報の設定
データベース移行フォルダ名: 名前は最大 256 文字です。縦棒 (|)、スラッシュ (/)、バックスラッシュ (\)、コロン (:)、疑問符 (?)、山括弧 (<>)、アスタリスク (*)、または二重引用符 (") を含めることはできません。
データソース情報の設定
同期ソース
パラメータ
説明
データソースタイプ
ソースデータソースのタイプを選択します。サポートされているデータソースとその作成方法の詳細については、「データベース移行でサポートされるデータソース」をご参照ください。
Oracle データソース
スキーマ: テーブルが存在するスキーマを選択します。異なるスキーマにまたがるテーブルを選択できます。スキーマを指定しない場合、デフォルトでデータソースで構成されたスキーマが使用されます。
ファイルエンコーディング: Oracle データソースを選択した場合、[エンコーディング] を選択する必要があります。サポートされているオプションは UTF-8、GBK、および ISO-8859-1 です。
Microsoft SQL Server、PostgreSQL、Amazon Redshift、Amazon RDS for PostgreSQL、Amazon RDS for MySQL、Amazon RDS for SQL Server、Amazon RDS for Oracle、Amazon RDS for DB2、PolarDB-X 2.0、GBase 8C データソース
スキーマ: テーブルが存在するスキーマを選択します。異なるスキーマにまたがるテーブルを選択できます。スキーマを指定しない場合、デフォルトでデータソースで構成されたスキーマが使用されます。
DolphinDB データソース
データベース: テーブルが存在するデータベースを選択します。これを空白のままにすると、データソース登録時に指定されたデータベースが使用されます。
Hive データソース
Hive データソースを選択した場合は、次のパラメーターを構成します。
ファイルエンコーディング: サポートされている値は UTF-8 と GBK です。
ORC テーブル圧縮形式: サポートされている値は zlib、hadoop-snappy、lz4、および none です。
テキストテーブル圧縮形式: サポートされている値は gzip、bzip2、lzo、lzo_deflate、hadoop_snappy、framing-snappy、zip、および zlib です。
Parquet テーブル圧縮フォーマット: サポートされている値は hadoop_snappy、gzip、および lzo です。
フィールド区切り文字: ターゲットテーブルにデータを書き込むために使用されるデリミタ。指定しない場合、デフォルトは
\u0001です。
タイムゾーン
データベースの設定に一致するタイムゾーンを選択します。中国におけるデータ統合のデフォルトタイムゾーンは
GMT+8です。このタイムゾーンは夏時間をサポートしていません。データベースがAsia/Shanghaiのような夏時間をサポートするタイムゾーンで設定されており、同期されるデータが夏時間期間内にある場合は、Asia/Shanghaiなどのタイムゾーンを選択してください。そうしないと、同期されたデータがデータベースのデータと 1 時間ずれてしまいます。サポートされているタイムゾーンには、GMT+1、GMT+2、GMT+3、GMT+5:30、GMT+8、GMT+9、GMT+10、GMT-5、GMT-6、GMT-8、Africa/Cairo、America/Chicago、America/Denver、America/Los_Angeles、America/New York、America/Sao Paulo、Asia/Bangkok、Asia/Dubai、Asia/Kolkata、Asia/Shanghai、Asia/Tokyo、Atlantic/Azores、Australia/Sydney、Europe/Berlin、Europe/London、Europe/Moscow、Europe/Paris、Pacific/Auckland、および Pacific/Honolulu が含まれます。
データソース
ソースデータソースを選択します。必要なデータソースが利用できない場合は、[新しいデータソース] をクリックして作成します。
バッチ読み取り数
ソースデータソースが Oracle、Microsoft SQL Server、OceanBase、IBM DB2、PostgreSQL、Amazon Redshift、Amazon RDS for PostgreSQL、Amazon RDS for MySQL、Amazon RDS for SQL Server、Amazon RDS for Oracle、Amazon RDS for DB2、DolphinDB、または GBase 8C の場合、バッチで読み取るレコード数を設定できます。デフォルトは 1024 です。
同期ターゲット
パラメータ
説明
データソースタイプ
ターゲットデータソースのタイプを選択します。サポートされているデータソースとその作成方法の詳細については、「データベース移行でサポートされるデータソース」をご参照ください。
説明AnalyticDB for PostgreSQL データソースにデータを同期すると、システムはターゲットテーブルに日次パーティションを作成します。
他のパーティションが必要な場合は、パイプラインが生成された後でパーティションの準備ステートメントを変更できます。単一のパイプラインをクリックして変更を加えます。
データソース
ターゲットデータソースを選択します。必要なデータソースが利用できない場合は、[新しいデータソース] をクリックして作成します。サポートされているデータソースとその作成方法の詳細については、「データベース移行でサポートされるデータソース」をご参照ください。
TDH Inceptor および ArgoDB ターゲットデータソースタイプ。
ストレージ形式を構成します。
TDH Inceptor: サポートされているストレージ形式は PARQUET、ORC、および TEXTFILE です。
ArgoDB: サポートされているストレージ形式は PARQUET、ORC、TEXTFILE、および HOLODESK です。
Hive ターゲットデータソースタイプ。
必要な設定項目は、選択したデータレイクテーブルフォーマット (Hudi、Iceberg、またはなし) によって異なります。
説明Iceberg または Hudi をデータレイクテーブル形式として選択できるのは、選択したデータソースまたは現在のプロジェクトのコンピュートエンジンでデータレイクテーブル形式機能が有効になっており、Iceberg または Hudi が選択されている場合のみです。
デフォルトのデータレイクテーブルフォーマットとしての Hive
外部テーブルであるか: このスイッチをオンにすると、テーブルを外部テーブルとして指定できます。このスイッチはデフォルトでオフになっています。
ストレージ形式: サポートされているストレージ形式は PARQUET、ORC、および TEXTFILE です。
ファイルエンコーディング: Hive のストレージフォーマットが ORC の場合、ファイルエンコーディングを構成できます。サポートされている値は UTF-8 と GBK です。
圧縮形式:
ORC ストレージ形式: サポートされている値は zlib、hadoop-snappy、および none です。
PARQUET ストレージフォーマット: サポートされている値は gzip と hadoop-snappy です。
TEXTFILE ストレージフォーマット: gzip、bzip2、lzo、lzo_deflate、hadoop-snappy、および zlib。
パフォーマンス構成: Hive ストレージフォーマットが ORC の場合、パフォーマンス設定を構成できます。出力テーブルが ORC フォーマットで多くのフィールドを持つシナリオでは、十分なメモリが利用可能な場合、この設定を増やすことで書き込みパフォーマンスを向上させることができます。メモリが不足している場合は、この設定を減らすことでガベージコレクション (GC) 時間を短縮し、書き込みパフォーマンスを向上させることができます。デフォルト値はバイト単位で
{"hive.exec.orc.default.buffer.size":16384}です。この値を 262144 バイト (256 KB) より大きく設定しないでください。フィールド区切り文字: TEXTFILE ストレージフォーマットの場合、フィールド区切り文字を構成できます。システムは、ターゲットテーブルへの書き込み時に指定されたデリミタを使用します。指定しない場合、デフォルトは
\u0001です。フィールド区切り文字の処理: TEXTFILE ストレージフォーマットの場合、フィールド区切り文字の処理方法を構成できます。データにデフォルトまたはカスタムのフィールド区切り文字が含まれている場合、書き込みエラーを防ぐために処理ポリシーを選択します。有効な値は保持、削除、および置換です。
行区切り文字の処理: TEXTFILE ストレージフォーマットの場合、行区切り文字の処理を構成できます。データに
\r\nや\nなどの改行が含まれている場合、データ書き込みエラーを防ぐための処理ポリシーを選択できます。ポリシーには保持、削除、および置換が含まれます。開発データソースの場所: Dev-Prod モードのプロジェクトでは、開発データソースの CREATE TABLE 文でテーブルストレージの場所を指定できます。例:
hdfs://path_to_your_extemal_table。本番データソースの場所: Dev-Prod モードのプロジェクトでは、本番データソースの CREATE TABLE 文でテーブルストレージの場所を指定できます。例:
hdfs://path_to_your_extemal_table。説明基本モードのプロジェクトでは、データソースの場所を 1 つだけ指定する必要があります。
データレイクテーブルフォーマット:Hudi
実行エンジン: 選択したデータソースで Spark が有効になっている場合、[Spark] または [Hive] を選択できます。Spark が有効になっていない場合は、[Hive] のみ選択できます。
Hudi テーブルタイプ:[MOR (マージオンリード)] または [COW (コピーオンライト)] を選択できます。デフォルトは MOR (マージオンリード) です。
拡張プロパティ: Hudi でサポートされている構成プロパティを
k=v形式で入力します。
データレイクテーブルフォーマット:Iceberg
実行エンジン: 選択したデータソースが Spark で構成されている場合、[Spark] が表示され、デフォルトで選択されます。それ以外の場合は、[Hive] のみが表示され、選択されます。
外部テーブルであるか: このスイッチをオンにすると、テーブルを外部テーブルとして指定できます。このスイッチはデフォルトでオフになっています。
ストレージ形式: サポートされているストレージ形式は PARQUET、ORC、および TEXTFILE です。
ファイルエンコーディング: Hive のストレージフォーマットが ORC の場合、ファイルエンコーディングを構成できます。サポートされている値は UTF-8 と GBK です。
圧縮形式:
ORC ストレージ形式: サポートされている値は zlib、hadoop-snappy、および none です。
PARQUET ストレージフォーマット: サポートされている値は gzip と hadoop-snappy です。
TEXTFILE ストレージフォーマット: gzip、bzip2、lzo、lzo_deflate、hadoop-snappy、および zlib。
パフォーマンス構成: Hive ストレージフォーマットが ORC の場合、このパフォーマンス設定を構成できます。出力テーブルが ORC フォーマットを使用し、多くのフィールドを持つシナリオでは、十分なメモリが利用可能な場合、この設定を増やすことで書き込みパフォーマンスを向上させることができます。メモリが不足している場合は、設定を減らすことで GC 時間を短縮し、書き込みパフォーマンスを向上させることができます。デフォルト値はバイト単位で
{"hive.exec.orc.default.buffer.size":16384}です。262144 バイト (256 KB) を超える値を設定しないでください。フィールド区切り文字: TEXTFILE ストレージフォーマットの場合、フィールド区切り文字を構成できます。システムは、ターゲットテーブルへの書き込み時に指定されたデリミタを使用します。デリミタを指定しない場合、デフォルトは
\u0001です。フィールド区切り文字の処理: TEXTFILE ストレージフォーマットの場合、フィールド区切り文字の処理方法を構成できます。データにデフォルトまたはカスタムのフィールド区切り文字が含まれている場合、書き込みエラーを防ぐために処理ポリシーを選択します。有効な値は保持、削除、および置換です。
行区切り文字の処理: TEXTFILE ストレージフォーマットの場合、行区切り文字の処理を構成できます。データに改行 (
\r\n、\n) が含まれている場合、データ書き込みエラーを防ぐための処理ポリシーを選択できます。オプションには保持、削除、および置換が含まれます。開発データソースの場所: Dev-Prod モードのプロジェクトでは、開発データソースの CREATE TABLE 文でテーブルストレージの場所を指定できます。例:
hdfs://path_to_your_extemal_table。本番データソースの場所: Dev-Prod モードのプロジェクトでは、本番データソースの CREATE TABLE 文でテーブルストレージの場所を指定できます。例:
hdfs://path_to_your_extemal_table。説明基本モードのプロジェクトでは、データソースの場所を 1 つだけ指定する必要があります。
データレイクテーブルフォーマットが Paimon の場合
実行エンジン: 現在、[Spark] のみがサポートされています。
Paimon テーブルタイプ: [MOR] (merge on read)、[COW] (copy on write)、または [MOW] (merge on write) を選択できます。デフォルトは MOR (merge on read) です。
拡張プロパティ:Hudi がサポートする設定プロパティを
k=v形式で入力します。
AnalyticDB for PostgreSQL および GaussDB (DWS) ターゲットデータソースタイプ。
次のパラメーターを構成します。
重要競合解決ポリシーは、AnalyticDB for PostgreSQL のカーネルバージョンが 4.3 より新しい場合にのみ、コピーモードで有効です。カーネルバージョンが 4.3 以前の場合、またはバージョンが不明な場合は、タスクの失敗を防ぐためにポリシーを慎重に選択してください。
競合解決ポリシー: コピーロードポリシーは競合解決ポリシーをサポートします。有効な値は競合時にエラーを報告と競合時に上書きです。
スキーマ: テーブルが存在するスキーマを選択します。異なるスキーマにまたがるテーブルを選択できます。スキーマを指定しない場合、デフォルトでデータソースで構成されたスキーマが使用されます。
Lindorm ターゲットデータソースタイプ。
次のパラメーターを構成します。
ストレージフォーマット: サポートされているストレージフォーマットは PARQUET、ORC、TEXTFILE、および ICEBERG です。
圧縮形式: 異なるストレージ形式は異なる圧縮形式をサポートします。
ORC ストレージ形式: サポートされている値は zlib、hadoop-snappy、lz4、および none です。
PARQUET ストレージフォーマット: サポートされている値は gzip と hadoop-snappy です。
TEXTFILE ストレージフォーマット: サポートされている値は gzip、gzip2、lzo、lzo_deflate、hadoop-snappy、および zlib です。
開発データソースの場所:Dev-Prod モードのプロジェクトでは、開発環境の CREATE TABLE 文でテーブルストレージのルートパスの場所を指定できます。例:
/user/hive/warehouse/xxx.db。本番データソースの場所:Dev-Prod モードのプロジェクトでは、本番環境の CREATE TABLE 文でテーブルストレージのルートパスの場所を指定できます。例:
/user/hive/warehouse/xxx.db。
MaxCompute データソース
MaxCompute テーブルタイプ: [標準テーブル] または [デルタテーブル] を選択できます。
Databricks データソース
スキーマ: テーブルが存在するスキーマを選択します。異なるスキーマにまたがるテーブルを選択できます。スキーマを指定しない場合、デフォルトでデータソースで構成されたスキーマが使用されます。
読み込みポリシー
Hive (データレイクテーブル形式が Hudi または Paimon の場合)、TDH Inceptor、ArgoDB、StarRocks、Oracle、MaxCompute、および Lindorm (コンピュートエンジン) のターゲットデータソースでは、次のロードポリシーがサポートされています: [データの上書き]、[データの追加]、および [データの更新]。
[データの上書き]: 同期するデータが存在する場合、新しいデータを書き込む前に既存のデータが削除されます。
[データの追加]: 同期するデータが存在する場合、既存のデータは上書きされません。新しいデータが追加されます。
[データの更新]: データはプライマリキーに基づいて更新されます。プライマリキーが存在しない場合、新しいデータが挿入されます。
説明MaxCompute テーブルタイプを標準テーブルに設定した場合、ロードポリシーとしてデータの追加またはデータの上書きを選択できます。MaxCompute テーブルタイプを Delta テーブルに設定した場合、データの更新またはデータの上書きを選択できます。
Hive ターゲットデータソース (データレイクテーブルフォーマットが選択されていない場合) では、サポートされているロードポリシーは [統合タスクによって書き込まれたデータのみを上書き]、[データの追加]、および [すべてのデータを上書き] です。
AnalyticDB for PostgreSQL および GaussDB (DWS) ターゲットデータソースでは、次のロードポリシーがサポートされています: insert および copy。
insert: データはレコードごとに同期されます。このポリシーは小規模なデータ量に適しており、データの正確性と完全性を向上させることができます。
copy: データはファイルを使用して同期されます。このポリシーは大規模なデータ量に適しており、同期速度を向上させることができます。
バッチ書き込みデータ量
Hive (データレイクテーブル形式が Hudi の場合)、AnalyticDB for PostgreSQL、および StarRocks のターゲットデータソースでは、バッチ書き込みデータ量を構成できます。これは一度に書き込まれるデータ量です。バッチ書き込み数を設定することもできます。データは、2 つのしきい値のいずれかに達したときに書き込まれます。
バッチ書き込み数
Hive (データレイクテーブル形式が Hudi の場合)、AnalyticDB for PostgreSQL、および StarRocks のターゲットデータソースでは、バッチ書き込み数を構成できます。これは一度に書き込まれるレコード数です。
データ同期の設定
同期元が FTP ではない場合
ソーステーブルを選択すると、対応するターゲットテーブルが生成されます。デフォルトでは、ターゲットテーブルの名前はソーステーブルの名前と同じです。名前変換ルールを構成している場合は、変換された名前が使用されます。
説明ソースがコレクションタスクが構成されていない外部データソースの場合、そのメタデータを取得できません。この場合、データ同期のメタデータ情報は空になります。メタデータセンターに移動してコレクションタスクを構成できます。
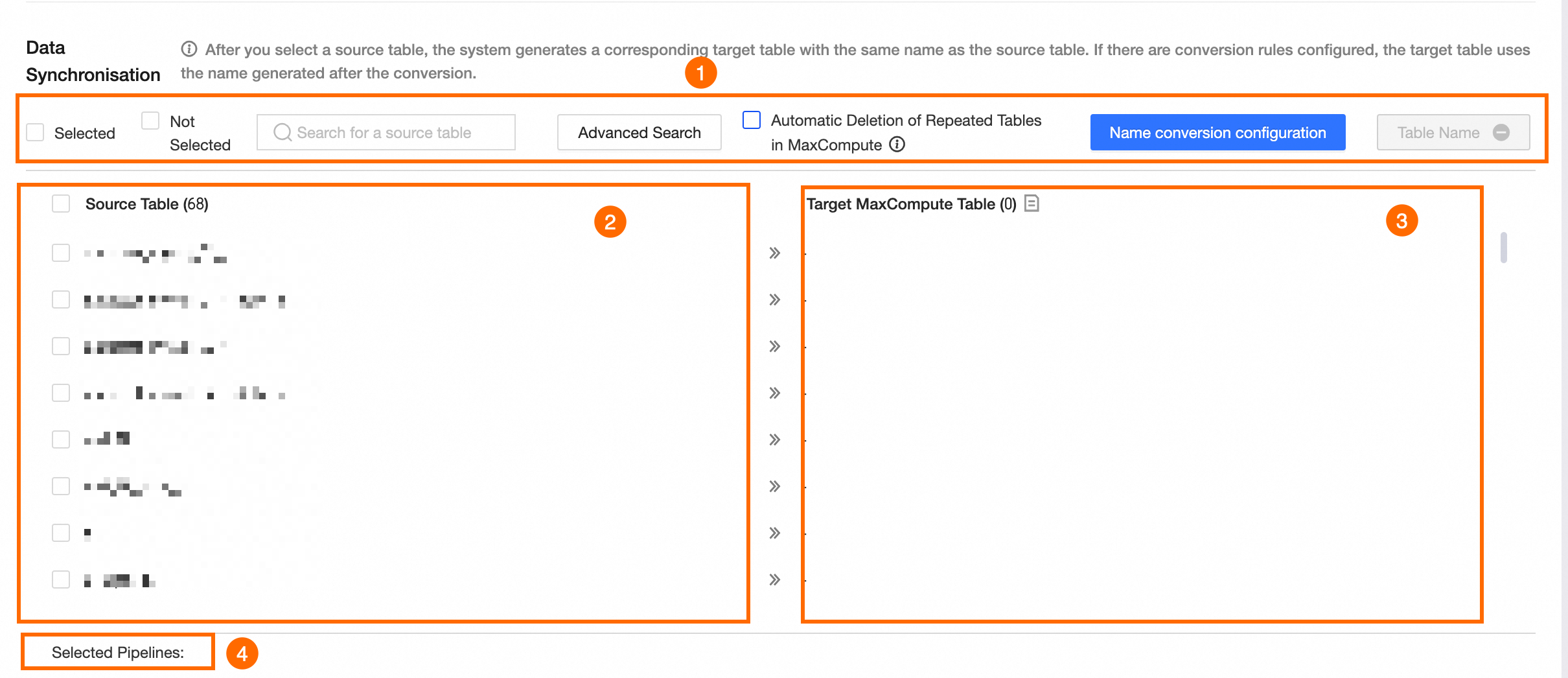
セクション
説明
① 操作エリア
選択済み、未選択: 選択ステータスでソーステーブルをフィルタリングします。
ソーステーブルの検索: 名前でソーステーブルを検索します。検索では大文字と小文字が区別されます。
詳細検索: ページには最大 10,000 テーブルが表示されます。詳細検索機能を使用すると、データベース内のすべてのテーブルから名前でテーブルを検索できます。[詳細検索] をクリックします。[詳細検索] ダイアログボックスで、パラメーターを構成します。
検索方法の設定。
正確なテーブル名入力またはあいまい検索を使用してソーステーブルを検索できます。
正確なテーブル名入力: 検索コンテンツフィールドにテーブル名をバッチで入力します。テーブル名の区切り文字は構成された区切り文字で、デフォルトは
\nです。独自に定義できます。あいまい検索: 検索コンテンツフィールドに、テーブル名からのキーワードを入力します。システムはキーワードに基づいてあいまい検索を実行します。
検索内容の入力。
検索コンテンツは検索方法によって異なります。
完全なテーブル名の入力: テーブルを検索するためにテーブル名をバッチで入力します。構成された区切り文字を使用してテーブル名を区切ります。
あいまい検索: テーブル名からキーワードを入力します。
検索結果。
検索方法と検索コンテンツを構成した後、[検索] をクリックして結果を表示します。結果テーブルで、管理したいテーブルを選択し、操作タイプを選択します。有効な値はバッチ選択とバッチ選択解除です。OK をクリックします。ソーステーブルは操作タイプに基づいて選択または選択解除されます。
データソース内で同じ名前のテーブルを自動的に削除する: このオプションを選択すると、Dataphin はまず、データベース移行によって生成されたテーブルと同じ名前を持つデータソース内の既存のテーブルを削除します。その後、Dataphin は自動的にテーブルを再作成します。
重要データソースがプロジェクトデータソースの場合、本番環境と開発環境の両方で同じ名前のテーブルが削除されます。このオプションは注意して使用してください。
名前変換構成: オプション。名前変換構成を使用すると、同期中にソーステーブル名とフィールド名を置換またはフィルタリングできます。
[名前変換設定] をクリックします。
[名前変換設定] ページで、変換ルールを設定します。
テーブル名変換ルール: [ルールの作成] をクリックします。ルール項目に、置換するソーステーブル文字列とターゲットテーブルの置換文字列を入力します。たとえば、テーブル名
dataworkをdataphinに置換するには、置換する文字列をworkに、置換文字列をphinに設定します。テーブル名プレフィックス: [テーブル名プレフィックス] テキストボックスに、ターゲットテーブル名のプレフィックスを入力します。同期中、プレフィックスは自動的にターゲットテーブル名に追加されます。たとえば、テーブル名プレフィックスが
pre_で、テーブル名がdataphinの場合、生成されるターゲットテーブル名はpre_dataphinです。テーブル名サフィックス: [テーブル名サフィックス] テキストボックスに、ターゲットテーブル名のサフィックスを入力します。同期中、サフィックスは自動的にターゲットテーブル名に追加されます。たとえば、テーブル名サフィックスが
_prodで、テーブル名がdataphinの場合、生成されるターゲットテーブル名はpre_dataphin_prodです。フィールド名ルール: [ルールの追加] をクリックします。ルール項目に、ソースフィールドの置換文字列とターゲットフィールドの置換文字列を入力します。たとえば、フィールド名
dataworkをdataphinに置換するには、置換する文字列をworkに、置換文字列をphinに設定します。
構成が完了したら、[OK] をクリックします。対応するターゲットデータベーステーブル列に、変換されたターゲットテーブル名が表示されます。
説明置換文字列およびテーブル名のプレフィックスとサフィックスの英字は、自動的に小文字に変換されます。
テーブル名の検証: 現在のターゲットテーブル名がターゲットデータベースに存在するかどうかを確認します。
② ソーステーブル
[ソーステーブル] リストで、同期するソーステーブルを選択します。
③ 対応する宛先データベーステーブル
[ソーステーブル] を選択すると、対応するターゲットデータベーステーブルが生成されます。デフォルトでは、ターゲットテーブルの名前はソーステーブルの名前と同じです。名前変換ルールを構成している場合は、変換された名前が使用されます。
説明ターゲットテーブル名には、文字、数字、およびアンダースコア (_) のみを含めることができます。ソーステーブル名に他の文字が含まれている場合は、テーブル名変換ルールを構成します。
④ パイプライン統計
選択されたパイプラインの数。
同期ソースは FTP サーバーです。
[Excel テンプレートのダウンロード] をクリックします。テンプレートの指示に従って入力し、ファイルをアップロードします。解析の失敗を防ぐため、指定されたテンプレート形式に従う必要があります。
説明単一の .xlsx ファイル、または 1 つ以上の .xlsx ファイルを含む圧縮 ZIP パッケージをアップロードできます。ファイルサイズは 50 MB 未満である必要があります。
ファイルがアップロードされたら、[ファイルの解析] をクリックします。
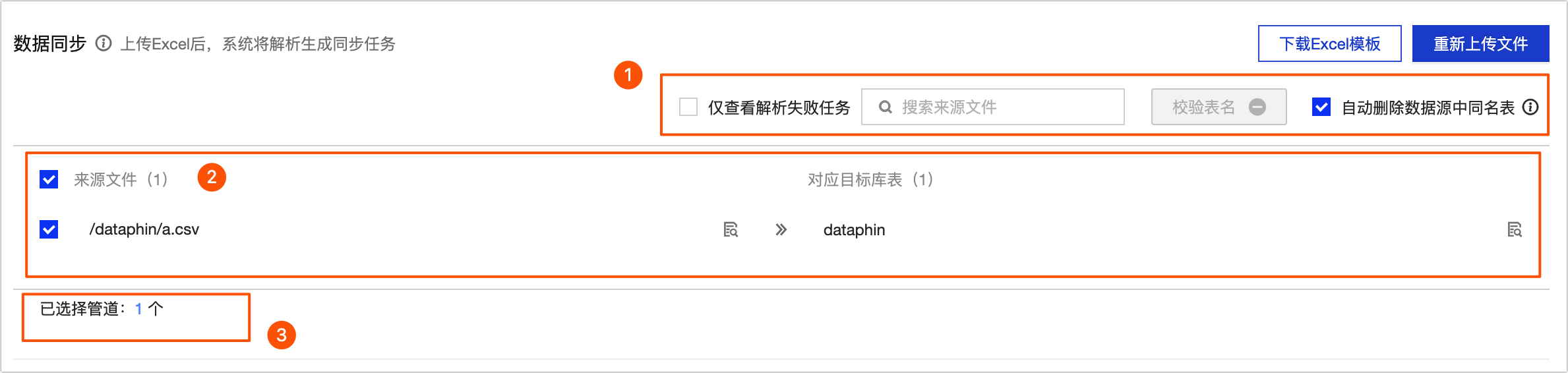
パラメータ
説明
① 操作エリア
ソースファイルの検索: 名前でソースファイルを検索します。
解析に失敗したタスクのみ表示: リストには解析に失敗したタスクのみが表示されます。
データソース内で同じ名前のテーブルを自動的に削除する: このオプションを選択すると、データベース移行によって生成されたターゲットテーブルと同じ名前を持つデータソース内の既存のテーブルが自動的に削除されます。その後、テーブルは自動的に再作成されます。
重要データソースがプロジェクトデータソースの場合、本番環境と開発環境の両方で同じ名前のテーブルが削除されます。このオプションは注意して使用してください。
テーブル名の検証: 現在のターゲットテーブル名がターゲットデータベースに存在するかどうかを確認します。
② ソースファイルと対応するターゲットテーブル
ソースファイル: [ソースファイル] リストで、同期するソースファイルを選択します。
[対応するターゲットテーブル]: ファイルが解析された後、テンプレートファイルに基づいて対応するターゲットデータベーステーブルが生成されます。
③ パイプライン統計
選択されたパイプラインの数。
タスク名の構成
[生成方法] で、オフラインデータベース移行タスクの名前を生成する方法を選択します。[システムのデフォルト] または [カスタムルール] を選択できます。
パラメータ
説明
生成方法
システムデフォルト
タスク名は、システムのデフォルトの命名規則を使用して生成されます。
カスタムルール
重要カスタムタスク命名ルールを構成する前に、同期ソースとターゲットデータソースを選択する必要があります。そうしないと、カスタムタスク命名ルールを構成できません。
デフォルトルール: ソースとターゲットのデータソースを選択し、タスク名の生成方法としてカスタムルールを選択すると、システムはタスク名ルールテキストボックスにデフォルトルールを生成します。タスク名のデフォルトルールは
${source_data_source_type}2${target_data_source_type}_${source_table_name}です。たとえば、現在のデータベース移行タスクのソースデータソースタイプが MySQL、ターゲットデータソースタイプが Oracle、ソーステーブルの最初のテーブルの名前が
source_table_name1の場合、デフォルトのノード命名規則はMySQL2Oracle_${source_table_name}で、ノード名はMySQL2Oracle_source_table_name1としてプレビューされます。説明このデフォルトルールは、システムのデフォルト生成方法とは異なります。
カスタムルール: 左側の [タスク命名ルール] テキストボックスに、命名ルールを入力します。既存のデフォルトルールを削除したり、変更したりできます。
名前は 256 文字を超えることはできません。縦棒 (|)、スラッシュ (/)、バックスラッシュ (\)、コロン (:)、疑問符 (?)、山括弧 (<>)、アスタリスク (*)、または二重引用符 (") を含めることはできません。右側の [利用可能なメタデータ] リストで有効なメタデータ名をクリックしてコピーできます。
説明命名ルールにメタデータを追加した後、タスク名プレビューのメタデータ値はすべて、ソーステーブルリストの最初のテーブルの情報から取得されます。
同期方法とデータフィルタリングの設定
パラメータ
説明
同期方法
同期方法を選択します。有効な値は [毎日同期]、[ワンタイム同期]、および [毎日同期 + ワンタイム同期] です。
[毎日同期]: システムは、毎日実行されるようにスケジュールされた統合パイプラインの自動トリガータスクを生成します。この方法は通常、毎日の増分データまたは完全データを同期するために使用されます。
[ワンタイム同期]: システムは、統合パイプラインのワンタイムタスクを生成します。この方法は通常、履歴の完全データを同期するために使用されます。
[毎日同期 + ワンタイム同期]: システムは、毎日実行されるようにスケジュールされた自動トリガータスクとワンタイムタスクの両方を生成します。この方法は通常、ワンタイムの完全データ同期の後に毎日の増分データまたは完全データ同期が続くシナリオで使用されます。
説明ソースデータベースが FTP の場合、[毎日同期 + ワンタイム同期] はサポートされていません。
宛先テーブルの作成形式
作成するターゲットテーブルのタイプを選択します。有効な値はパーティションテーブルと非パーティションテーブルです。ターゲットテーブルを作成するルールは、同期方法によって異なります。
毎日同期: パーティションテーブルを選択した場合、ターゲットテーブルはパーティションテーブルとして作成され、データはデフォルトで
ds=${bizdate}パーティションに書き込まれます。非パーティションテーブルを選択した場合、ターゲットテーブルは非パーティションテーブルとして作成されます。ワンタイム同期: パーティションテーブルを選択した場合、ターゲットテーブルはパーティションテーブルとして作成されます。ワンタイム同期書き込みパーティションパラメーターを構成する必要があり、これは定数またはパーティションパラメーターをサポートします。たとえば、
20230330などの定数やds=${bizdate}などのパーティションパラメーターを使用できます。非パーティションテーブルを選択した場合、ターゲットテーブルは非パーティションテーブルとして作成されます。毎日同期 + ワンタイム同期: デフォルトはパーティションテーブルで、変更できません。ワンタイム同期書き込みパーティションパラメーターを構成する必要があり、これは定数またはパーティションパラメーターをサポートします。たとえば、定数
20230330またはパーティションパラメーターds=${bizdate}です。説明現在、ワンタイム同期タスクからデータを書き込めるのは、ターゲットテーブルの指定された 1 つのパーティションのみです。完全な履歴データを異なるパーティションに書き込むには、ワンタイム同期の後に SQL ノードを使用してデータを処理し、対応するパーティションに書き込むことができます。または、増分データに対して毎日同期を選択し、その後データバックフィルを実行して履歴パーティションを完了することもできます。
データフィルタリング
ソースデータベースが Hive または MaxCompute ではありません
毎日同期フィルター条件: 同期方法に毎日同期が含まれている場合、毎日同期のフィルター条件を構成できます。
ds=${bizdate}を構成すると、タスクはソースデータベースからds=${bizdate}のすべてのデータを抽出し、指定されたターゲットテーブルパーティションに書き込みます。ワンタイム同期フィルター条件: 同期方法にワンタイム同期が含まれている場合、ワンタイム同期フィルター条件を構成できます。
ds=<${bizdate}を構成すると、タスクはソースデータベースからds=<${bizdate}のすべてのデータを抽出し、指定されたターゲットテーブルまたはパーティションに書き込みます。
ソースデータベースが Hive または MaxCompute です
毎日同期パーティション: ソースデータベースが Hive または MaxCompute の場合、パーティションテーブルから毎日読み取るパーティションを指定する必要があります。単一のパーティション (
ds=${bizdate}など) または複数のパーティション (/*query*/ds>=20230101 and ds<=20230107など) を読み取ることができます。[ワンタイム同期パーティション]: ソースデータベースが Hive または MaxCompute で、同期方法に [ワンタイム同期] が含まれる場合、パーティションテーブルから読み取るパーティションを指定する必要があります。単一のパーティション (
ds=${bizdate}など) や複数のパーティション (/*query*/ds>=20230101 and ds<=20230107など) を指定できます。パーティションが存在しない場合: 指定されたパーティションが存在しない場合の処理ポリシーを選択します。
タスクを失敗させる: タスクは停止され、ステータスは失敗に設定されます。
タスクを成功させる: タスクは正常に実行されますが、データは書き込まれません。
最新の空でないパーティションを使用する: ソースデータベースが MaxCompute の場合、テーブルの最新の空でないパーティション (max_pt) を同期するパーティションとして使用できます。テーブルにデータを含むパーティションがない場合、タスクは失敗し、エラーが報告されます。このオプションは Hive ソースデータベースではサポートされていません。
説明ソースが FTP の場合、データフィルタリングはサポートされていません。
パラメーター設定
ソースが FTP の場合、ソースファイルパスでパラメーターを使用できます。
スケジューリングとランタイム構成
パラメータ
説明
スキャン設定
スケジューリング構成を選択します。有効な値は [同時スケジューリング] と [バッチスケジューリング] です。
[同時スケジューリング]: ソースデータベースで選択されたテーブルの同期タスクは、指定されたスケジューリングタイムゾーンで毎日 00:00 に同時に実行されます。
バッチスケジューリング: ソースデータベースで選択されたテーブルの同期タスクはバッチで実行されます。0 から 23 時間の期間と最大 142 の同期タスクを設定できます。たとえば、100 のテーブルを同期する場合、タスクを 2 時間ごとに 10 テーブル同期するように設定すると、1 サイクルですべての同期タスクを開始するのに 20 時間かかります。同期間隔は 24 時間を超えることはできません。
実行タイムアウト
同期タスクが指定されたしきい値より長く実行された場合、自動的に停止され、ステータスは失敗に設定されます。[システム構成] または [カスタム] を選択できます。
[システム構成]: システムのデフォルトのタイムアウト期間を使用します。詳細については、「ランタイム構成」をご参照ください。
カスタム: カスタムのタイムアウト期間を指定します。0 を除く 0 から 168 までの数値を入力できます。値は小数点以下 2 桁まで正確に指定できます。
失敗時の自動再実行
タスクインスタンスまたはデータバックフィルインスタンスが失敗した場合、システムはこの構成に基づいてインスタンスを自動的に再実行するかどうかを決定します。再実行回数を 0 から 10 までの整数に、再実行間隔を 1 から 60 までの整数に設定できます。
上流依存関係
[依存関係の追加] をクリックして、[物理ノード] または [論理テーブルノード] をこのノードの上流依存関係として追加します。依存関係が設定されていない場合、テナントの仮想ルートノードがデフォルトの上流依存関係になります。また、統合されたデータバックフィルなどのシナリオで役立つ、依存オブジェクトとして仮想ノードを手動で追加することもできます。
リソース構成
[リソースグループ]:データベース移行統合タスクは、スケジューリングリソースを消費する専用タスクです。各データベース移行統合タスクによって生成されるインスタンスのリソースグループを指定できます。インスタンスがスケジュールされると、指定されたリソースグループのリソースクォータを使用します。指定されたリソースグループで利用可能なリソースが不足している場合、インスタンスは [スケジューリングリソースを待機中] 状態になります。リソースは、スケジューリングの安定性を確保するために、異なるリソースグループ間で分離されます。
現在のプロジェクトに関連付けられ、Daily task scheduling シナリオに使用されるリソースグループのみを選択できます。詳細については、「リソースグループの構成」、「」をご参照ください。
説明Basic プロジェクトでは、[リソースグループ] を設定できます。Dev-Prod プロジェクトでは、[開発タスクスケジューリングリソースグループ] と [本番タスクスケジューリングリソースグループ] を設定できます。
プロジェクトのデフォルトリソースグループを選択した場合、構成はプロジェクトのデフォルトリソースグループ設定に基づいて自動的に更新されます。
デフォルトでは、本番環境と開発環境の両方でのタスクスケジューリングは、プロジェクトのデフォルトのスケジューリングリソースグループを使用します。これを、登録済みのスケジューリングクラスターのリソースグループを含む、現在のプロジェクトに関連付けられている別のリソースグループに変更できます。
パラメーターを構成した後、[パイプラインの生成] をクリックして、オフラインデータベース移行パイプラインを作成します。
[実行結果] エリアでは、ソーステーブル、ターゲットテーブル、同期方法、タスクステータス、詳細など、パイプラインタスクの実行結果を表示できます。
パイプラインが生成された後、このオフラインデータベース移行タスクのフォルダがオフライン統合ディレクトリに作成されます。このフォルダには、対応するオフラインパイプラインタスクが含まれています。生成されたオフラインパイプラインタスクを構成および公開できます。詳細については、「オフラインパイプラインタスクのプロパティを構成する」をご参照ください。
一部のテーブルの作成に失敗した場合、または後でテーブルを追加する場合は、失敗したテーブルまたは新しいテーブルに対してオフラインパイプラインまたはスクリプトタスクを手動で作成できます。その後、それらをオフラインデータベース移行フォルダに移動します。次の手順を実行します:
ターゲットのオフライン完全データベース移行フォルダの横にある
 ボタンをクリックし、[新規] [オフラインパイプライン] または [オフラインスクリプト] を選択します。
ボタンをクリックし、[新規] [オフラインパイプライン] または [オフラインスクリプト] を選択します。[オフラインパイプラインの作成] または [オフラインスクリプトの作成] ダイアログボックスで、パラメーターを設定し、[OK] をクリックします。詳細については、「単一パイプラインを使用した統合タスクの作成」および「コードエディタモードでの統合タスクの作成」をご参照ください。
説明作成されたオフラインパイプラインおよびスクリプトタスクは、現在のオフラインデータベース移行フォルダに配置されます。
オフラインデータベース移行フォルダにフォルダを移動したり、フォルダから移動したりすることはできません。
オフライン統合ディレクトリ内のオフラインパイプラインおよびスクリプトタスクを移動するには、名前の横にある
 アイコンをクリックし、[移動] を選択してから、[ファイルの移動] ダイアログボックスで移動先フォルダを選択します。タスクをオフラインデータベース移行フォルダに移動できます。
アイコンをクリックし、[移動] を選択してから、[ファイルの移動] ダイアログボックスで移動先フォルダを選択します。タスクをオフラインデータベース移行フォルダに移動できます。データベース移行フォルダを削除すると、オフラインパイプラインやスクリプトタスクを含む、そのフォルダ内のすべてのタスクも削除されます。
次のステップ
オフラインデータベース移行タスクを作成して公開した後、オペレーションセンターに移動して統合タスクを表示および管理し、期待どおりに実行されることを確認します。詳細については、「オペレーションセンター」をご参照ください。