HDFS 出力ウィジェットを使用すると、HDFS データソースにデータを書き込むことができます。さまざまなデータソースから HDFS データソースへデータを同期する際には、ソースデータの情報を設定した後、HDFS 出力ウィジェットのターゲットデータソースを構成する必要があります。本トピックでは、HDFS 出力ウィジェットの構成手順について説明します。
前提条件
HDFS データソースが作成済みであること。詳細については、「HDFS データソースの作成」をご参照ください。
HDFS 入力ウィジェットのプロパティを構成するには、アカウントにデータソースに対するライトスルー権限が必要です。権限がない場合は、データソースへのアクセスをリクエストする必要があります。詳細については、「Request Data Source Permission」をご参照ください。
操作手順
Dataphin ホームページで、上部メニューバーから 開発 > データ統合 を選択します。
統合ページの上部メニューバーで、プロジェクト を選択します(Dev-Prod モードの場合は 環境 を選択する必要があります)。
左側のナビゲーションウィンドウで バッチパイプライン をクリックします。 バッチパイプライン リストで、開発対象の オフラインパイプライン をクリックして、その構成ページを開きます。
右上隅の コンポーネントライブラリ をクリックして、コンポーネントライブラリ パネルを開きます。
コンポーネントライブラリ パネルの左側ナビゲーションウィンドウで、出力 を選択します。右側の出力ウィジェット一覧から HDFS コンポーネントを見つけ、キャンバス上にドラッグします。
上流コンポーネントの
 アイコンをクリックしてドラッグし、HDFS 出力ウィジェットに接続します。
アイコンをクリックしてドラッグし、HDFS 出力ウィジェットに接続します。HDFS 出力コンポーネント上の
 アイコンをクリックして、HDFS 出力構成 ダイアログボックスを開きます。
アイコンをクリックして、HDFS 出力構成 ダイアログボックスを開きます。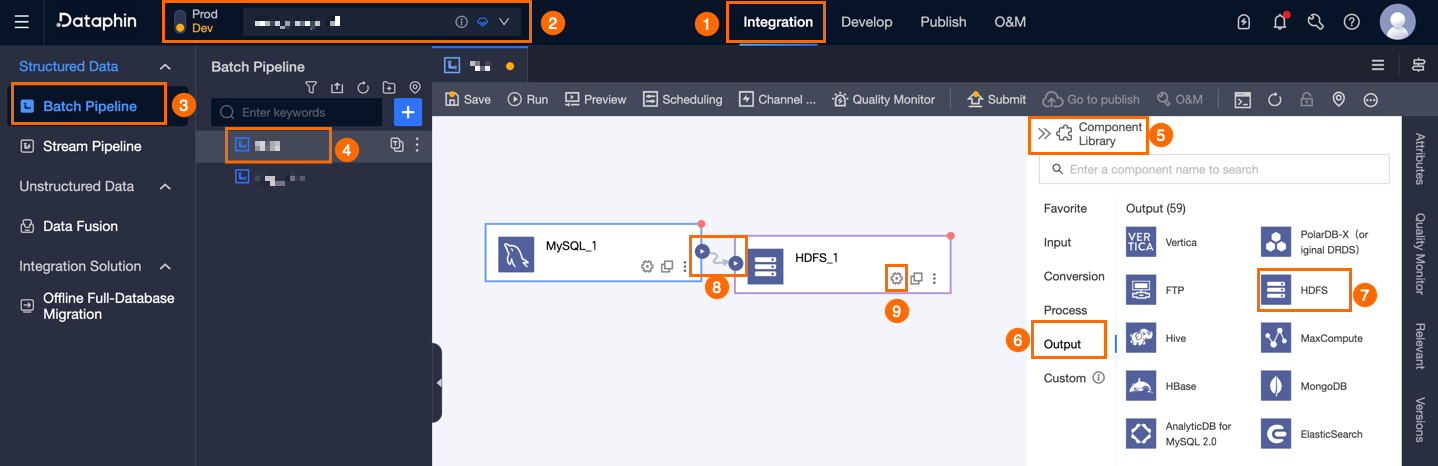
HDFS 出力構成 ダイアログボックスで、パラメーターを設定します。
パラメーター
説明
ステップ名
HDFS 出力ウィジェットの名前です。Dataphin は自動的にステップ名を生成しますが、ビジネスシナリオに応じて変更することも可能です。命名規則は以下のとおりです。
使用できる文字は、漢字、英字、アンダースコア (_)、数字のみです。
64 文字以内である必要があります。
データソース
データソースのドロップダウンリストには、ライトスルー権限があるものとないものを含む、すべての HDFS タイプのデータソースが表示されます。
 アイコンをクリックすると、現在のデータソース名をコピーできます。
アイコンをクリックすると、現在のデータソース名をコピーできます。ライトスルー権限がないデータソースについては、データソース名の横にある リクエスト をクリックして、データソースへのライトスルー権限をリクエストできます。詳細については、「データソース権限のリクエスト、更新、返却」をご参照ください。
HDFS タイプのデータソースをまだ作成していない場合は、データソースの作成 をクリックしてデータソースを作成します。詳細については、「HDFS データソースの作成」をご参照ください。
ファイルパス
ファイルの絶対パスを入力します。データソースにはすでに
NameNodeが構成されているため、hdfs://{namenode}:{port}のプレフィックスを追加する必要はありません。例:/hadoop/input/file.txt。システムは次のパスにアクセスします:hdfs://{データソースに構成された NameNode}:{データソースに構成された IPC ポート}{入力されたファイルパス}。ファイルタイプ
データを保存する際のファイルタイプを選択します。ファイルタイプ には、テキスト、ORC、および Parquet があります。
ファイルエンコーディング
ファイルのエンコーディングを選択します。ファイルエンコーディング には、UTF-8 および GBK があります。
ロードポリシー
ターゲットデータソース(HDFS データソース)にデータを書き込む際のテーブルへの書き込みポリシーです。ロードポリシーには、データの上書きとデータの追加があります。適用されるシナリオは以下のとおりです。
データの上書き:データ上書きポリシーでは、まずターゲットディレクトリ内のファイルが削除され、その後新しいデータファイルが追加されます。
データの追加:データ追加ポリシーでは、新しいデータファイルがターゲットディレクトリに直接追加されます。
行区切り文字
ファイルタイプがテキストの場合、フィールド間の行区切り文字を構成できます。これは任意です。値を入力しない場合、システムは自動的に \n をデリミタとして追加します。
フィールド区切り文字
ファイルタイプがテキストの場合、フィールド間のフィールド区切り文字を構成できます。これは任意です。値を入力しない場合、システムは自動的にカンマ (,) をデリミタとして追加します。
完了ファイルのマーク
完了ファイルのパスとフォーマットを構成します。完了のマーク方法には、タスクレベルとファイルレベルの 2 種類があります。
タスクレベル:例:
/ftpuser/test/SUCCESS。タスク完了後、SUCCESS という名前の空のファイルが 1 つ生成されます。ファイルレベル:アスタリスク (*) をデータファイル名のプレースホルダーとして使用します。例:
/ftpuser/test/.flg。各データファイルに対して、同じ名前の空の .flg ファイルが生成されます。
マージポリシー
データ出力に使用するスレッドを選択します。
マージ:すべてのデータを 1 つのファイルにマージし、単一スレッドで出力します。大規模ファイルの出力速度に影響が出る可能性があります。
重要マージはデータの追加をサポートしていません。
マージしない:マルチスレッドで出力し、複数のファイルを生成します。
圧縮ファイルのエクスポート
ファイルを圧縮形式で宛先データベースにインポートするかどうかをサポートします。圧縮せず、選択したファイルタイプで直接エクスポート、gzip 圧縮形式、または zip 圧縮形式を選択できます。
カラムヘッダーのエクスポート
カラムヘッダーをエクスポートするかどうかを選択します。
エクスポート:各ファイルの最初の行にフィールド名が出力されます。
エクスポートしない:ファイルの最初の行はデータになります。
入力フィールド
上流コンポーネントの出力フィールドが表示されます。
出力フィールド
出力フィールドが表示されます。Dataphin では、一括追加 および 新規出力フィールドの作成 により出力フィールドを構成できます。
一括追加:一括追加 をクリックします。JSON 形式および TEXT 形式での一括構成がサポートされています。
JSON 形式での一括構成例:
// 例: [{"name": "user_id","type": "String"}, {"name": "user_name","type": "String"}]説明name はフィールド名を、type はフィールドのデータの型を指定します。たとえば、
"name":"user_id","type":"String"は user_id フィールドをインポートし、そのデータの型を String に設定します。TEXT 形式での一括構成例:
// 例: user_id,String user_name,String行区切り文字は各フィールドの情報を分離するために使用されます。デフォルトは改行 (\n) です。改行 (\n)、セミコロン (;)、ピリオド (.) がサポートされています。
列区切り文字はフィールド名とフィールドのデータの型を分離するために使用されます。デフォルトはカンマ (,) です。
新規出力フィールドの作成。
+新規出力フィールドの作成 をクリックし、ページの指示に従って カラム に入力し、タイプ を選択します。
先祖テーブルフィールドのコピー。
先祖テーブルフィールドのコピー をクリックします。システムは先祖テーブルのフィールド名に基づいて自動的に出力フィールドを生成します。
出力フィールドの管理。
追加済みのフィールドに対して、以下の操作も実行できます。
操作 列の
 アイコンをクリックして、既存のフィールドを編集します。
アイコンをクリックして、既存のフィールドを編集します。操作 列の
 アイコンをクリックして、既存のフィールドを削除します。
アイコンをクリックして、既存のフィールドを削除します。
マッピング
マッピングは、ソーステーブルの入力フィールドを宛先テーブルの出力フィールドにマッピングし、後続のデータ同期を容易にします。マッピングには、同名マッピングと同行マッピングがあります。適用されるシナリオは以下のとおりです。
同名マッピング:フィールド名が同一のフィールドをマッピングします。
同行マッピング:ソーステーブルと宛先テーブルのフィールド名が一致しませんが、対応する行のフィールドデータをマッピングする必要があります。同じ行のフィールドのみがマッピングされます。
確認 をクリックして、HDFS 出力ウィジェットの構成を確定します。