DataHub 出力ウィジェットを構成すると、外部データベースから DataHub へのデータ書き込み、および接続されたストレージシステムからビッグデータプラットフォームへのデータのコピーとプッシュが可能になり、統合と再処理が行えます。このトピックでは、DataHub 出力ウィジェットを構成する手順について説明します。
前提条件
DataHub データソースが作成されている必要があります。詳細については、「DataHub データソースの作成」をご参照ください。
DataHub 入力ウィジェットのプロパティを構成するには、アカウントがデータソースに対するリードスルー権限を持っている必要があります。権限がない場合は、データソースへのアクセスをリクエストする必要があります。詳細については、「データソース権限のリクエスト、更新、返却」をご参照ください。
操作手順
Dataphin ホームページで、上部のメニューバーから [開発] > [データ統合] を選択します。
統合ページで、トップメニューバーから **[Project]** を選択します (開発-本番パターンでは環境の選択が必要です)。
左側のナビゲーションウィンドウで、[Batch Pipeline] をクリックします。次に、[Batch Pipeline] リストで、開発する Offline Pipeline をクリックしてその構成ページを開きます。
ページの右上隅にある[コンポーネントライブラリ]をクリックして、[コンポーネントライブラリ]パネルを開きます。
[コンポーネントライブラリ] パネルの左側のナビゲーションウィンドウで、[出力] を選択します。右側の出力ウィジェットリストで [DataHub] ウィジェットを見つけ、キャンバスにドラッグします。
ターゲットのアップストリームウィジェットの
 アイコンをクリックしてドラッグし、DataHub 出力ウィジェットに接続します。
アイコンをクリックしてドラッグし、DataHub 出力ウィジェットに接続します。DataHub 出力ウィジェットで、
 アイコンをクリックして、[DataHub 出力設定] ダイアログボックスを開きます。
アイコンをクリックして、[DataHub 出力設定] ダイアログボックスを開きます。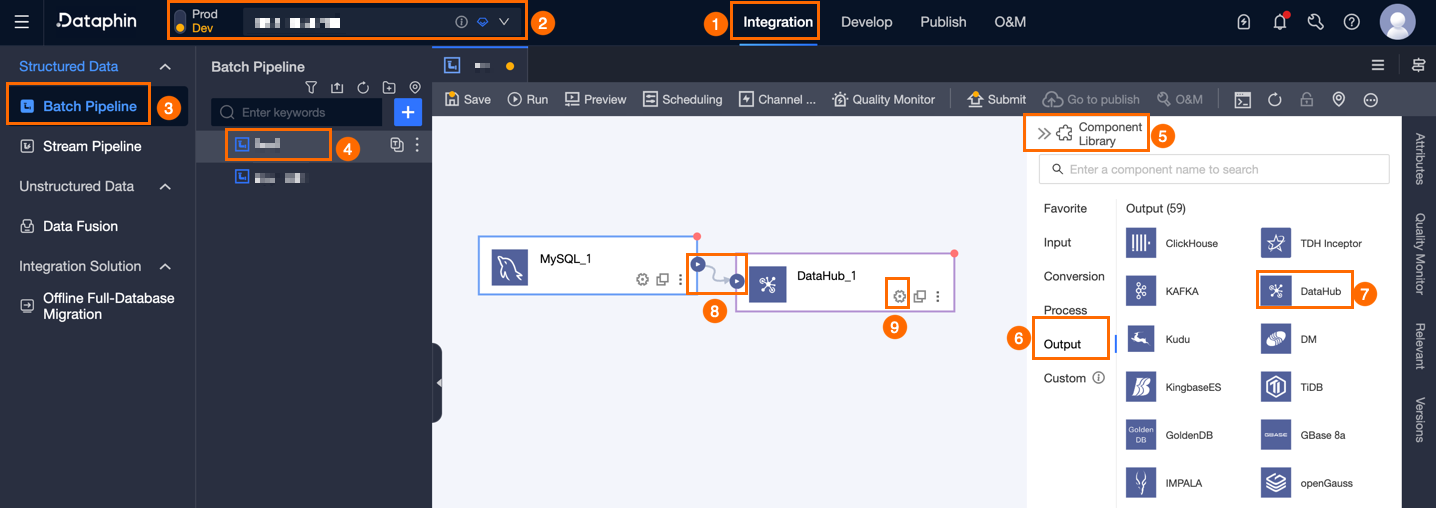
[Datahub 出力設定] ダイアログボックスで、表に従ってパラメーターを設定します。
パラメーター
説明
基本設定
ステップ名
DataHub 出力ウィジェットの名前です。Dataphin がステップ名を自動的に生成しますが、ビジネスシナリオに応じて変更することもできます。名前は次の要件を満たす必要があります。
中国語の文字、文字、アンダースコア (_)、および数字のみを含めることができます。
64 文字を超えることはできません。
データソース
データソースドロップダウンリストには、ライトスルー権限を持つデータソースと持たないデータソースを含む、すべての DataHub タイプのデータソースが表示されます。
 アイコンをクリックして、現在のデータソース名をコピーします。
アイコンをクリックして、現在のデータソース名をコピーします。ライトスルー権限が付与されていないデータソースの場合、データソースの横にある[リクエスト]をクリックしてライトスルー権限を申請できます。 詳細については、「データソース権限の申請、更新、返却」をご参照ください。
DataHub 型のデータソースがない場合は、[データソースの作成] をクリックしてデータソースを作成します。詳細については、「DataHub データソースの作成」をご参照ください。「」をご参照ください。
件名
実際のシナリオに応じて、必要なトピックを選択します。
提出あたりのデータ量
書き込み効率を向上させるため、Data Integration はバッファーデータを蓄積します。蓄積されたデータサイズが提出あたりのデータ量サイズ (MB 単位) に達すると、バッチで宛先に送信されます。デフォルトは 1 (1 MB のデータ) です。
高度な構成
必要に応じて構成します。次のパラメーターがサポートされています。
maxRetryCount: 失敗したノードの最大リトライ回数です。リトライ回数は 3 を超えることはできません。
batchSize: 書き込み効率を向上させるため、Data Integration はバッファーデータを蓄積します。蓄積されたデータレコード数が batchSize (レコード単位) に達すると、バッチで宛先に送信されます。
maxCommitInterval: バッファーデータの最大時間です。単位: ミリ秒。デフォルトは 30,000 (30 秒) です。データ収集ソースが長時間データを生成しない場合、データのタイムリーな配信を確保するために、このパラメーターを設定する必要があります。設定された時間を超えると、配信が強制されます。
説明提出あたりのデータ量、batchSize、および maxCommitInterval の 3 つのパラメーターについては、配信のためにいずれか 1 つのパラメーターが満たされる必要があります。さらに、DataHub は単一のリクエストで書き込まれるデータレコード数を 10,000 に制限しています。10,000 レコードを超えると、ノードが失敗する原因となります。ノードエラーを回避するために、batchSize を 10,000 レコード以下に設定することを推奨します。
フィールドマッピング
入力フィールド
入力フィールドは、アップストリームウィジェットの出力に基づいて表示されます。
出力フィールド
出力フィールド領域には、選択されたテーブルのすべてのフィールドが表示されます。特定のフィールドをダウンストリームウィジェットに出力する必要がない場合は、対応するフィールドを削除できます。
少数のフィールドを削除するには、[操作] 列の
 アイコンをクリックして、不要なフィールドを削除できます。
アイコンをクリックして、不要なフィールドを削除できます。多数のフィールドを削除するには、「[フィールド管理]」をクリックし、[フィールド管理] ページで複数のフィールドを選択してから、
 アイコンをクリックして、「[選択済み入力フィールド]」を「[未選択入力フィールド]」に移動します。
アイコンをクリックして、「[選択済み入力フィールド]」を「[未選択入力フィールド]」に移動します。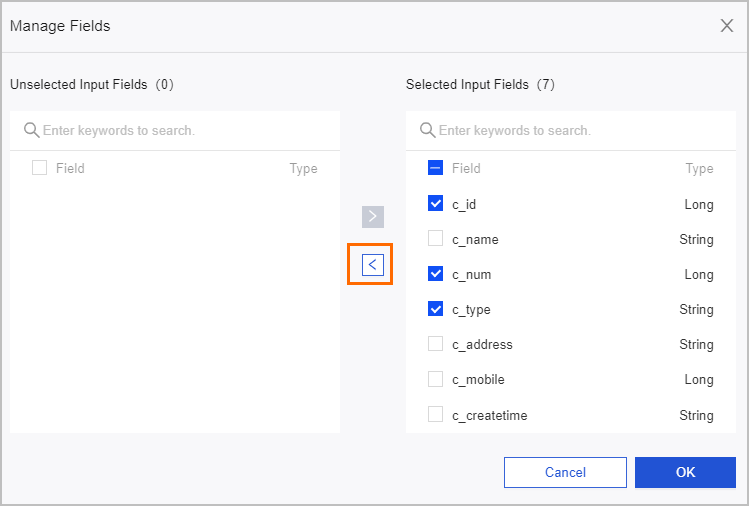
マッピング
マッピング関係は、ソーステーブルの入力フィールドをターゲットテーブルの出力フィールドにマップするために使用されます。マッピング関係には、同名マッピングと同行マッピングが含まれます。シナリオは次のとおりです。
同名マッピング: 同じフィールド名を持つフィールドをマップします。
同行マッピング: ソーステーブルとターゲットテーブルのフィールド名が一致しないが、フィールドの対応する行のデータをマップする必要がある場合です。同じ行のフィールドのみがマップされます。
[OK] をクリックします。