Kafka 出力コンポーネントは、外部データベースから Kafka へのデータ書き込みに加え、接続済みストレージシステムからビッグデータプラットフォームへとデータをコピー・プッシュし、データ統合および再処理を行うための機能を提供します。本トピックでは、Kafka 出力コンポーネントの構成方法について説明します。
前提条件
Kafka データソースが作成済みである必要があります。詳細については、「Kafka データソースの作成」をご参照ください。
Kafka 出力コンポーネントのプロパティを構成するには、対象データソースに対するリードスルー権限が必要です。必要な権限がない場合は、データソースへのアクセス権限を申請してください。詳細については、「データソース権限の申請」をご参照ください。
操作手順
Dataphin のホームページ上部のメニューバーで、[開発] > [Data Integration] を選択します。
統合ページの上部メニューバーで、[プロジェクト] を選択します(Dev-Prod モードの場合は、[環境] を選択します)。
左側ナビゲーションウィンドウで、[バッチパイプライン] をクリックします。[バッチパイプライン] 一覧から、開発対象の [オフラインパイプライン] をクリックして、その構成ページを開きます。
ページ右上隅の [コンポーネントライブラリ] をクリックして、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネルの左側ナビゲーションウィンドウで、[出力] を選択します。その後、右側の出力コンポーネント一覧から [KAFKA] コンポーネントを見つけ、キャンバスにドラッグします。
対象となる入力・変換・フローコンポーネントの
 アイコンをクリックしてドラッグし、KAFKA 出力コンポーネントに接続します。
アイコンをクリックしてドラッグし、KAFKA 出力コンポーネントに接続します。KAFKA 出力コンポーネントカード上の
 アイコンをクリックして、[KAFKA 出力構成] ダイアログボックスを開きます。
アイコンをクリックして、[KAFKA 出力構成] ダイアログボックスを開きます。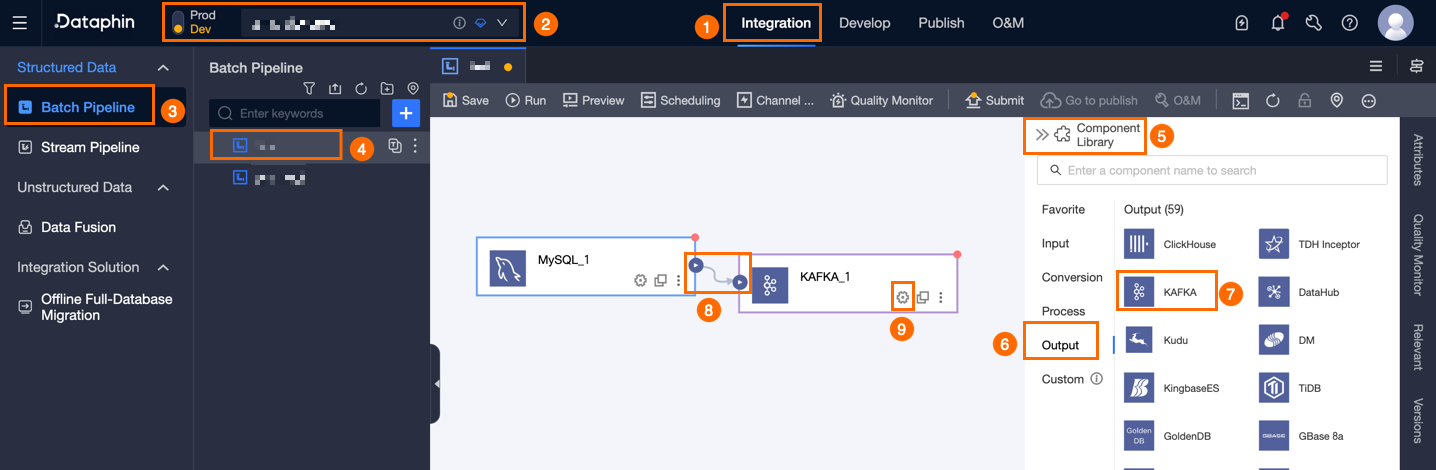
[KAFKA 出力構成] ダイアログボックスで、以下の表に示す通り、各パラメーターを設定します。
パラメーター
説明
基本設定
[ステップ名]
Kafka 出力コンポーネントの名称です。Dataphin が自動的にステップ名を生成しますが、ビジネスシナリオに応じて変更することも可能です。命名規則は以下のとおりです:
使用可能な文字は、漢字、英字、アンダースコア(_)、数字のみです。
最大文字数は 64 文字です。
[データソース]
データソースのドロップダウンリストには、すべての Kafka 型データソース(ライトスルー権限を持つものおよび持たないもの)が表示されます。現在のデータソース名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。ライトスルー権限を持たないデータソースについては、データソース名の後に表示される [リクエスト] をクリックして、該当データソースのライトスルー権限を申請できます。詳細については、「データソース権限の申請・更新・返却」をご参照ください。
Kafka 型データソースが存在しない場合は、[データソースの作成] をクリックして新規作成します。詳細については、「Kafka データソースの作成」をご参照ください。
トピック
必要に応じて Topic を選択します。一致する項目が見つからない場合は、Topic 名を手動で入力することも可能です。選択した Topic 名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。Kafka データソースに必要な Topic が存在しない場合、[Topic の作成] 機能を使用して迅速に作成できます。手順は以下のとおりです:
[Topic の作成] をクリックします。Topic の作成ダイアログボックスで、以下のパラメーターを設定します。
[Topic 名]:Topic の名称を入力します。すべての文字がサポートされます。
[パーティション数]:1 以上の整数を入力します。デフォルト値は 1 です。
[レプリカ数]:1 以上の整数を入力します。デフォルト値は 2 です。
[Topic パラメーター](任意):
key=value形式で Topic 作成用のパラメーターを入力します。複数のパラメーターは改行で区切ります。[本番環境で Topic を作成]:このオプションを選択すると、本番環境にも Topic が作成されます。同名の Topic が既に本番環境に存在する場合は、このオプションを選択する必要はありません。
[作成] をクリックします。
[キー列]
キー列に値を入力してください。
複数の列が選択されている場合、設定された列の序数に対応する値がカンマで連結され、Kafka レコードのキーとして使用されます。
選択されていない場合、Kafka レコードのキーは null となり、データは Topic の各パーティションに順次書き込まれます。
[書き込みモード]
この設定項目は、データソースから読み取られたレコードの全列を、Kafka レコードの Value として連結する際のフォーマットを決定します。「text」と「json」の 2 つのオプションがあり、デフォルト値は「text」です。
[text]:設定項目で指定された区切り文字に従って全列を連結します。
JSON:ターゲットテーブルのフィールド名に従って、すべての列を JSON 文字列に連結します。
説明valueIndex が設定されている場合、この設定項目は無効になります。
例として、ソースレコードに a、b、c の値を持つ 3 つの列がある場合:
書き込みモードが「text」で区切り文字が「#」に設定されている場合、書き込まれる Kafka レコードの Value は文字列 a#b#c となります。
書き込みモードが「JSON」でターゲットテーブルのフィールドが ["col1","col2","col3"] に設定されている場合、書き込まれる Kafka レコードの Value は文字列 {"col1":"a","col2":"b","col3":"c"} となります。
値区切り文字
Value の区切り文字を設定します。
[書き込みモード] が [json] の場合、Value 区切り文字の設定はサポートされません。
[書き込みモード] が [text] の場合、単一または複数の文字を区切り文字として設定できます。Unicode 文字は \u0001 形式で設定可能であり、\t や \n などのエスケープ文字もサポートされます。デフォルト値は \t(水平タブ文字)です。
[キー型] および [Value 型]
Kafka のキーおよび Value の型を選択します。
[キー列] が未選択または複数列が選択されている場合、[キー型] および [Value 型] の選択肢には、[BYTEARRAY]、[STRING]、および [KAFKA AVRO](データソースに schema.registry が設定されている場合に選択可能)があります。
[キー列] で 1 列が選択されている場合、[キー型] および [Value 型] の選択肢には、[BYTEARRAY]、[DOUBLE]、[FLOAT]、[INTEGER]、[LONG]、[SHORT]、[STRING]、および [KAFKA AVRO](データソースに schema.registry が設定されている場合に選択可能)があります。
詳細設定
必要に応じて設定します。以下のパラメーターをサポートします:
keyfieldDelimiter:キーの区切り文字。Kafka キー列が複数列の場合の連結文字で、デフォルト値は空文字です。
valueIndex:Kafka Writer の Value として使用する列を指定します。例:valueIndex=[0,1,2,3]。角括弧内の数字は、入力コンポーネントのフィールドの seqnumber を表します。
書き込みモードが text の場合、デフォルトではすべての列が区切り文字で分割される Value として連結されます。Value 型は BYTEARRAY または STRING のみ指定可能です。
書き込みモードが JSON の場合、キーと値のペアとして JSON に書き込まれます。
partition=0:Kafka Topic の特定のパーティションに書き込むパーティション番号を指定します。0 以上の整数を指定します。デフォルト値は 0 です。
nullKeyFormat=null:キーとして指定されたソース列の値が null の場合、この設定項目で指定された文字列で置き換えます。設定されていない場合は、置き換えを行いません。
nullValueFormat=null:ソース列の値が null の場合、Kafka レコードの Value を構成する際に、この設定項目で指定された文字列で置き換えます。設定されていない場合は、置き換えを行いません。
acks=all:Kafka Producer の初期化時に使用される acks 設定で、書き込み成功の確認方法を決定します。値が 0 の場合、書き込み成功を確認しません。値が 1 の場合、プライマリレプリカへの書き込み成功を確認します。値が all の場合、すべてのレプリカへの書き込み成功を確認します。デフォルト値は acks=all です。
keySchema:Topic に schema.registry が設定されている場合、キーのスキーマを入力します。デフォルト値は空です。
valueSchema:Topic に schema.registry が設定されている場合、Value のスキーマを入力します。デフォルト値は空です。
フィールドマッピング
[入力フィールド]
上流コンポーネントの出力フィールドを表示します。
[出力フィールド]
出力フィールドを表示します。Dataphin では、[一括追加] および [出力フィールドの作成] を使用して出力フィールドを構成できます:
一括追加: [一括追加] をクリックすると、JSON 形式および TEXT 形式での一括構成がサポートされます。
JSON 形式の一括構成の例:
// 例: [{"name": "user_id","type": "String"}, {"name": "user_name","type": "String"}]説明name はインポートするフィールドの名称を指定し、type はインポート後のフィールドのデータの型を指定します。たとえば、
"name":"user_id","type":"String"は、user_id という名称のフィールドをインポートし、そのデータの型を String に設定します。TEXT 形式の一括構成の例:
// 例: user_id,String user_name,String行区切り文字は各フィールドの情報を区切るために使用され、デフォルトは改行(\n)です。改行(\n)、セミコロン(;)、ピリオド(.)をサポートします。
列区切り文字はフィールド名とフィールド型を区切るために使用され、デフォルトはカンマ(,)です。
出力フィールドの作成。
[+出力フィールドの作成] をクリックし、ページの案内に従って [列] を入力し、[型] を選択します。
祖先テーブルのフィールドをコピー。
[祖先テーブルのフィールドをコピー] をクリックすると、システムが上流のフィールド名に基づいて自動的に出力フィールドを生成します。
出力フィールドの管理。
追加したフィールドに対して、以下の操作も実行できます:
既存のフィールドを編集するには、[操作] 列の
 アイコンをクリックします。
アイコンをクリックします。既存のフィールドを削除するには、[操作] 列の
 アイコンをクリックします。
アイコンをクリックします。
マッピング
マッピング関係は、ソーステーブルの入力フィールドをターゲットテーブルの出力フィールドにマップするために使用され、後続のデータ同期を容易にします。マッピング関係には、同名マッピングと同行マッピングがあります。適用されるシナリオは以下のとおりです:
[同名マッピング]:フィールド名が同一のフィールドをマップします。
[同行マッピング]:ソーステーブルとターゲットテーブルのフィールド名が異なりますが、対応する行のデータをマップする必要があります。同一行のフィールドのみをマップします。
[確認] をクリックして、Kafka 出力コンポーネントの構成を確定します。