AnalyticDB for MySQL 2.0 出力コンポーネントは、AnalyticDB for MySQL 2.0 データソースにデータを書き込みます。他のデータソースから AnalyticDB for MySQL 2.0 にデータを同期する場合、ソースデータソース情報を設定した後に、ターゲットデータソースを設定する必要があります。このトピックでは、AnalyticDB for MySQL 2.0 出力コンポーネントの設定方法について説明します。
操作手順
Dataphin ホームページのトップナビゲーションバーで、[開発] > [データ統合] を選択します。
統合ページのトップナビゲーションバーで、プロジェクトを選択します。Dev-Prod モードでは、環境を選択する必要があります。
左側のナビゲーションバーで、[バッチパイプライン] をクリックします。[バッチパイプライン] リストで、開発したいオフラインパイプラインをクリックして、その設定ページを開きます。
ページの右上隅にある [コンポーネントライブラリ] をクリックして、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネルの左側のナビゲーションバーで、[出力] を選択します。右側の出力コンポーネントリストで、[AnalyticDB for MySQL 2.0] コンポーネントを見つけ、キャンバスにドラッグします。
ターゲットの入力、変換、またはフローコンポーネントの
 アイコンをクリックしてドラッグし、現在の AnalyticDB for MySQL 2.0 出力コンポーネントに接続します。
アイコンをクリックしてドラッグし、現在の AnalyticDB for MySQL 2.0 出力コンポーネントに接続します。AnalyticDB for MySQL 2.0 出力コンポーネントカードの
 アイコンをクリックして、[出力設定] ダイアログボックスを開きます。
アイコンをクリックして、[出力設定] ダイアログボックスを開きます。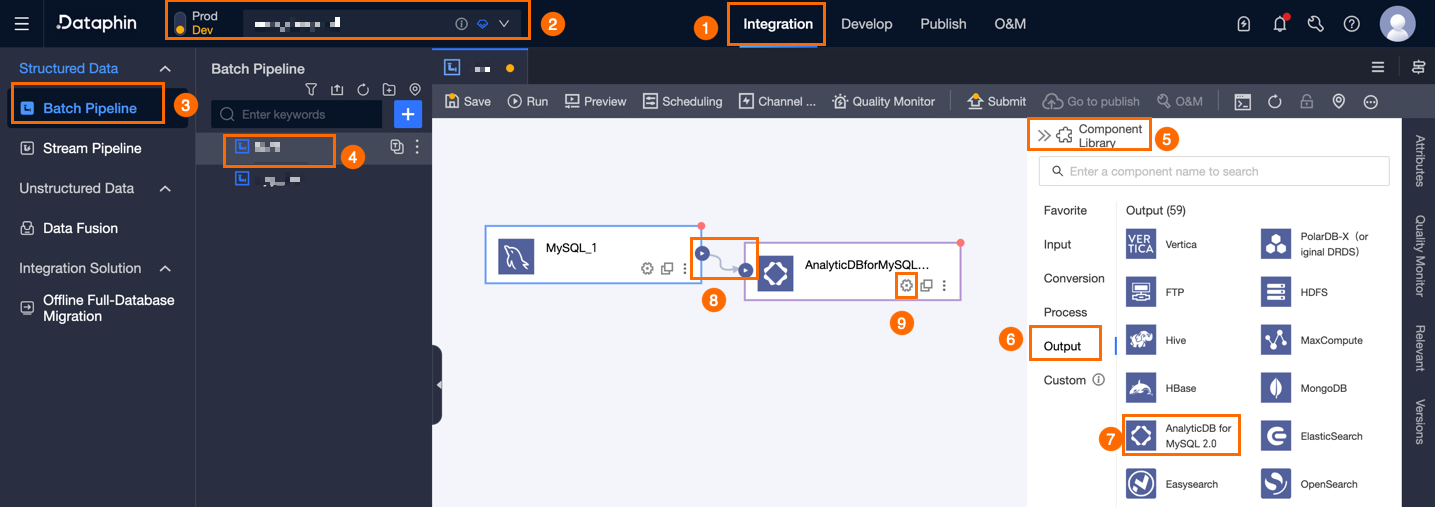
[AnalyticDB For MySQL 2.0 出力設定] ダイアログボックスで、パラメーターを設定します。
パラメーター
説明
[基本設定]
[ステップ名]
AnalyticDB for MySQL 2.0 出力コンポーネントの名前です。Dataphin は自動的にステップ名を生成しますが、ビジネスシナリオに基づいて変更できます。名前は次の要件を満たす必要があります:
中国語の文字、英字、アンダースコア (_)、数字のみを含めることができます。
長さは 64 文字を超えることはできません。
データソース
データソースのドロップダウンリストには、すべての AnalyticDB for MySQL 2.0 データソースが表示されます。これには、ライトスルー権限があるものとないものが含まれます。現在のデータソース名をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。ライトスルー権限がないデータソースについては、データソースの横にある [リクエスト] をクリックしてライトスルー権限をリクエストできます。詳細については、「データソース権限のリクエスト、更新、返却」をご参照ください。
AnalyticDB for MySQL 2.0 データソースがない場合は、[データソースの作成] をクリックして作成します。詳細については、「AnalyticDB for MySQL 2.0 データソースの作成」をご参照ください。
タイムゾーン
時間形式のデータを処理するために使用されるタイムゾーンです。デフォルトは、選択したデータソースで設定されたタイムゾーンであり、変更できません。
説明V5.1.2 より前に作成されたタスクでは、[データソースのデフォルト設定] または [チャネル設定タイムゾーン] を選択できます。デフォルトは [チャネル設定タイムゾーン] です。
[データソースのデフォルト設定]:選択したデータソースのデフォルトのタイムゾーンです。
[チャネル設定タイムゾーン]:現在の統合タスクの [プロパティ] > [チャネル設定] で設定されたタイムゾーンです。
テーブル
出力データのターゲットテーブルを選択します。キーワードを入力してテーブルを検索するか、正確なテーブル名を入力して [完全一致] をクリックします。テーブルを選択すると、システムは自動的にテーブルのステータスを確認します。現在選択されているテーブルの名前をコピーするには、
 アイコンをクリックします。
アイコンをクリックします。モード
データ出力モードを選択します。[モード] には次のものが含まれます:
挿入モード: 少量のデータ (1000 万レコード未満) の書き込みをサポートします。 [準備ステートメント] と [完了ステートメント] を設定する必要があります。
[準備ステートメント]:インポート前に実行する SQL スクリプトです。
[完了ステートメント]:インポート後に実行する SQL スクリプトです。
[ロードモード]:ロードモードは、大量のデータ (1,000 万レコード以上) の書き込みをサポートします。ロードポリシー、ロードパラメーター、および Alibaba Cloud アカウントを設定する必要があります。
[ロードポリシー]:ターゲットテーブルにデータを書き込むためのポリシーを選択します。
[データの上書き] は、現在のソーステーブルに基づいて、ターゲットテーブルの既存データが上書きされることを意味します。
[データの追加] は、ターゲットテーブルの既存データを変更せずに、データが追加されることを意味します。
[ロードパラメーター]:MaxCompute 転送に使用される接続で、JSON 形式で入力します。例:
{"accessid":"XXX","accessKey":"XXX","odpsServer":"XXX","tunnelServer":"XXX","accountType":"aliyun","project":"transfer_project"}[Alibaba Cloud アカウント]:ロードモードで必須です。Alibaba Cloud アカウントは、ロードデータを承認するために使用されます。内容は ALIYUN$****_data@aliyun.com のように入力します。
[バッチ書き込みデータ量] (任意)
一度に書き込まれるデータのサイズです。[バッチ書き込み数] を設定することもできます。システムは、これらの設定のいずれかが上限に達したときにデータを書き込みます。デフォルトは 32 M です。
フィールド マッピング
[入力フィールド]
アップストリームの入力に基づいて入力フィールドを表示します。
出力フィールド
出力フィールドを表示します。次の操作を実行できます:
フィールド管理:[フィールド管理] をクリックして出力フィールドを選択します。

 アイコンをクリックして、[選択された入力フィールド] を [未選択の入力フィールド] に移動します。
アイコンをクリックして、[選択された入力フィールド] を [未選択の入力フィールド] に移動します。 アイコンをクリックして、[未選択の入力フィールド] を [選択された入力フィールド] に移動します。
アイコンをクリックして、[未選択の入力フィールド] を [選択された入力フィールド] に移動します。
一括追加:[一括追加] をクリックして、JSON、TEXT、または DDL 形式で設定します。
JSON 形式での設定例:
// 例: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]説明name はインポートするフィールドの名前を指定し、type はインポート後のフィールドのデータの型を指定します。たとえば、
"name":"user_id","type":"String"は user_id という名前のフィールドをインポートし、そのデータの型を String に設定します。TEXT 形式での設定例:
// 例: user_id,String user_name,String行区切り文字は、各フィールドの情報を区切るために使用されます。デフォルトは改行 (\n) です。サポートされている区切り文字には、改行 (\n)、セミコロン (;)、ピリオド (.) があります。
列区切り文字は、フィールド名とフィールドタイプを区切るために使用されます。デフォルトはカンマ (,) です。
DDL 形式での設定例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
新しい出力フィールドの作成:[+ 出力フィールドの作成] をクリックし、プロンプトに従って [列] を入力し、[タイプ] を選択します。現在の行の設定が完了したら、
 アイコンをクリックして保存します。
アイコンをクリックして保存します。
[マッピング]
アップストリームの入力とターゲットテーブルのフィールドに基づいて、手動でフィールドマッピングを選択できます。[マッピング] には [同行マッピング] と [同名マッピング] があります。
同名マッピング:同じ名前のフィールドをマッピングします。
同行マッピング:ソーステーブルとターゲットテーブルのフィールド名が異なるが、対応する行のデータをマッピングする必要がある場合に、同じ行のフィールドをマッピングします。
[OK] をクリックして、[AnalyticDB for MySQL 2.0] 出力コンポーネントのプロパティ設定を完了します。