Argo ワークフローは、スケジュールされたタスク、機械学習、ETL で広く使用されています。Kubernetes に慣れていない場合、YAML ベースのワークロードの作成は難しい場合があります。Hera は、Python 用の Argo ワークフロー SDK です。Hera は YAML の代替手段であり、Python で複雑なワークフローを簡単にオーケストレートおよびテストする方法を提供します。さらに、Hera は Python エコシステムとシームレスに統合されています。
機能概要
Argo ワークフローは、YAML ファイルを使用してワークフローを構成し、明確さとシンプルさを実現しています。YAML に慣れていない場合、厳密なインデント要件と階層構造により、複雑なワークフロー構成がさらに難しくなります。
Hera は、Argo ワークフローに基づいてワークフローの作成と送信を目的とした、Python 用の Argo ワークフロー SDK です。Hera は、ワークフローの作成と送信の手順を簡素化することを目的としています。Hera は、複雑なワークフローオーケストレーションにおける YAML 構文エラーを排除するのに役立ちます。Hera には、次の利点があります。
シンプルさ: Hera は、直感的で使いやすいコードを提供し、開発効率を大幅に向上させます。
シンプルな Python エコシステム統合: 各関数はテンプレートであり、Python エコシステムのフレームワークとシームレスに統合されています。Python エコシステムは、さまざまな Python ライブラリとツールも提供します。
可観測性: Hera は Python テストフレームワークをサポートしており、コードの品質と保守性を向上させるのに役立ちます。
前提条件
Argo コンポーネントとコンソールがインストールされ、Argo サーバーの認証情報と IP アドレスが取得されていること。詳細については、バッチタスクオーケストレーションの有効化 を参照してください。
Hera がインストールされていること。
pip install hera-workflows
シナリオ 1: シンプルな DAG ダイヤモンド
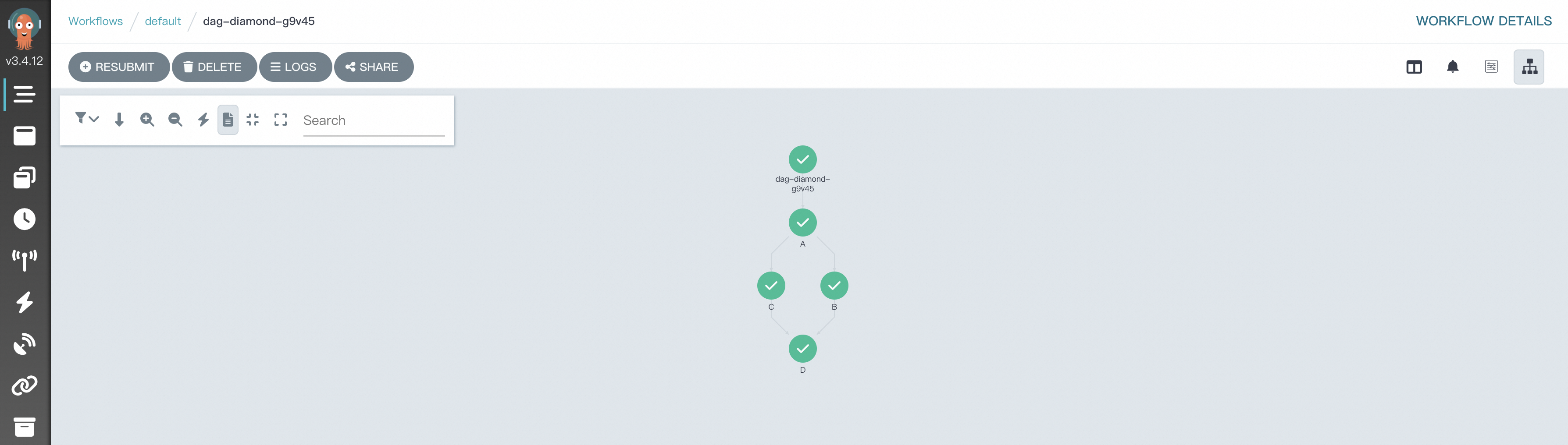
Argo ワークフローは、有向非巡回グラフ (DAG) を使用して、ワークフロー内のタスクの複雑な依存関係を定義します。ダイヤモンド構造は、ワークフローでよく採用されます。ダイヤモンドワークフローでは、複数の並列タスクの実行結果が後続タスクの入力に集約されます。ダイヤモンド構造は、データフローと実行結果を効率的に集約できます。次のサンプルコードは、Hera を使用して、タスク A とタスク B が並列に実行され、タスク A とタスク B の実行結果がタスク C の入力に集約されるダイヤモンドワークフローをオーケストレートする方法を示しています。
simpleDAG.py という名前のファイルを作成し、次の内容をファイルにコピーします。
# 必要なパッケージをインポートします。 from hera.workflows import DAG, Workflow, script from hera.shared import global_config import urllib3 urllib3.disable_warnings() # ワークフロークラスターのエンドポイントとトークンを指定します。 global_config.host = "https://${IP}:2746" global_config.token = "abcdefgxxxxxx" # 取得したトークンを入力します。 global_config.verify_ssl = "" # script デコレータは、Hera を使用して Python のような関数オーケストレーションを有効にするための鍵です。 # Workflow や Steps コンテキストなどの Hera コンテキストマネージャーの下で以下の関数を呼び出すことができます。 # 関数は Hera コンテキスト外でも通常どおり実行されます。つまり、指定された関数で単体テストを作成できます。 # 次のコードは入力例を示しています。 @script() def echo(message: str): print(message) # ワークフローをオーケストレートします。Workflow は Argo の主要なリソースであり、Hera の主要なクラスです。Workflow は、テンプレートの保存、エントリポイントの設定、テンプレートの実行を担当します。 with Workflow( generate_name="dag-diamond-", entrypoint="diamond", namespace="argo", ) as w: with DAG(name="diamond"): A = echo(name="A", arguments={"message": "A"}) # テンプレートを作成します。 B = echo(name="B", arguments={"message": "B"}) C = echo(name="C", arguments={"message": "C"}) D = echo(name="D", arguments={"message": "D"}) A >> [B, C] >> D # 依存関係を定義します。この例では、タスク A はタスク B とタスク C の依存関係です。タスク B とタスク C はタスク D の依存関係です。 # ワークフローを作成します。 w.create()次のコマンドを実行して、ワークフローを送信します。
python simpleDAG.pyワークフローの実行が開始されたら、ワークフローコンソール (argo) に移動して、DAG プロセスと結果を表示できます。
シナリオ 2: MapReduce
Argo ワークフローでは、MapReduce スタイルでデータを処理するための鍵は、DAG テンプレートを使用して複数のタスクを編成および調整し、Map フェーズと Reduce フェーズをシミュレートすることです。次のサンプルコードは、Hera を使用して、テキストファイル内の単語をカウントするために使用されるサンプル MapReduce ワークフローをオーケストレートする方法を示しています。各ステップは Python 関数で定義され、Python エコシステムと統合されます。
アーティファクトを構成するには、アーティファクトの構成 を参照してください。
map-reduce.py という名前のファイルを作成し、次の内容をファイルにコピーします。
次のコマンドを実行して、ワークフローを送信します。
python map-reduce.pyワークフローの実行が開始されたら、ワークフローコンソール (argo) に移動して、DAG プロセスと結果を表示できます。

参考資料
Hera のドキュメント:
Hera の詳細については、Hera の概要 を参照してください。
Hera を使用して大規模言語モデル (LLM) をトレーニングする方法の詳細については、Hera で LLM をトレーニングする を参照してください。
サンプル YAML デプロイ構成:
YAML ファイルを使用して simple-diamond をデプロイする方法の詳細については、dag-diamond.yaml を参照してください。
YAML ファイルを使用して map-reduce をデプロイする方法の詳細については、map-reduce.yaml を参照してください。
お問い合わせ
この製品に関するご提案やご質問がある場合は、DingTalk グループ 35688562 に参加してお問い合わせください。