Pod の異常状態、イメージのプル失敗、OOM (Out of Memory) エラーなど、Pod に関する一般的な問題を診断し、解決します。
このトピックについて
|
カテゴリ |
内容 |
|
診断プロセス |
|
|
一般的なトラブルシューティング方法 |
|
|
一般的な問題と解決策 |
診断プロセス
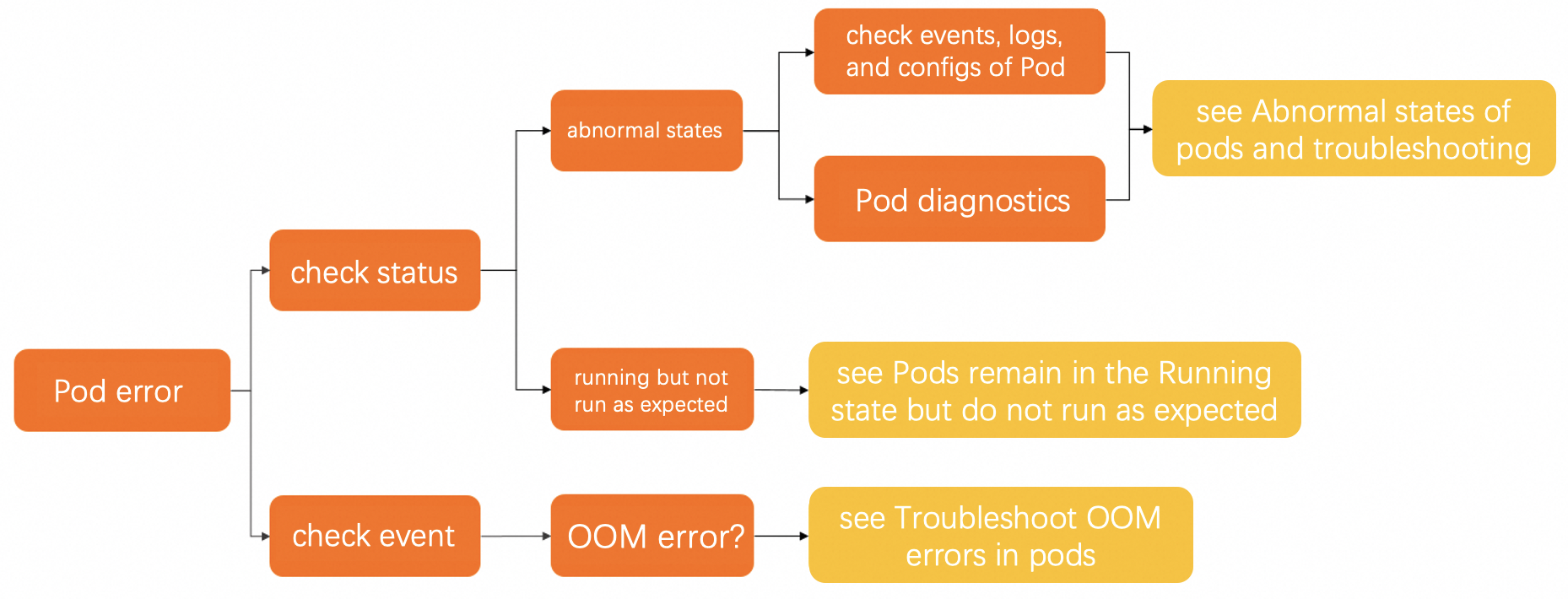
-
Pod の異常状態を確認します。詳細については、「Pod ステータスの確認」をご参照ください。
-
Pod が異常状態にある場合は、そのイベント、ログ、設定を確認して原因を特定します。詳細については、「一般的なトラブルシューティング方法」をご参照ください。Pod の異常状態とその対処方法については、「Pod の一般的な異常状態と解決策」をご参照ください。
-
Pod が
Running状態であるにもかかわらず期待どおりに動作しない場合は、「Running状態の Pod が期待どおりに動作しない場合」をご参照ください。
-
-
Pod の OOM 問題が確認された場合は、「Pod の OOM 問題のトラブルシューティング」をご参照ください。
-
問題が解決しない場合は、チケットを送信してください。
Pod の一般的な異常状態と解決策
|
Pod のステータス |
説明 |
解決策 |
|
Pending |
Pod がスケジュールされていません。 |
|
|
Init:N/M |
Pod には M 個の Init コンテナがあり、N 個が正常に起動しています。 |
|
|
Init:Error |
Init コンテナの起動に失敗しました。 |
|
|
Init:CrashLoopBackOff |
Init コンテナの起動に失敗し、再起動を繰り返しています。 |
|
|
Completed |
Pod は起動コマンドの実行を完了しました。 |
|
|
CrashLoopBackOff |
Pod の起動に失敗し、再起動を繰り返しています。 |
|
|
ImagePullBackOff |
Pod はイメージのプルに失敗しました。 |
|
|
Running |
|
|
|
Terminating |
Pod は終了処理中です。 |
一般的なトラブルシューティング方法
Pod ステータスの確認
ACS コンソール にログインします。左側のナビゲーションペインで、クラスター をクリックします。
クラスター ページで、管理するクラスターを見つけ、その ID をクリックします。クラスター詳細ページの左側のナビゲーションペインで、ワークロード > ポッド を選択します。
-
Pods ページの左上隅で、Pod の Namespace を選択し、そのステータスを確認します。
-
ステータスが
Runningの場合、Pod は期待どおりに動作しています。 -
ステータスが
Runningでない場合、Pod は異常状態にあります。解決策については、「Pod の一般的な異常状態と解決策」をご参照ください。
-
Pod 詳細の確認
ACS コンソール にログインします。左側のナビゲーションペインで、クラスター をクリックします。
クラスター ページで、管理するクラスターを見つけ、その ID をクリックします。クラスター詳細ページの左側のナビゲーションペインで、ワークロード > ポッド を選択します。
-
Pods ページの左上隅で、Pod の Namespace を選択します。次に、対象の Pod 名をクリックするか、[Actions] 列の [Details] をクリックして、名前、イメージ、IP アドレスなどの詳細を表示します。
Pod 設定の確認
ACS コンソール にログインします。左側のナビゲーションペインで、クラスター をクリックします。
クラスター ページで、管理するクラスターを見つけ、その ID をクリックします。クラスター詳細ページの左側のナビゲーションペインで、ワークロード > ポッド を選択します。
-
Pods ページの左上隅で、Pod の Namespace を選択します。次に、対象の Pod 名をクリックするか、[Actions] 列の [Details] をクリックします。
-
Pod の詳細ページで、右上隅の Edit をクリックして、Pod の YAML ファイルと詳細な設定を表示します。
Pod イベントの確認
ACS コンソール にログインします。左側のナビゲーションペインで、クラスター をクリックします。
クラスター ページで、管理するクラスターを見つけ、その ID をクリックします。クラスター詳細ページの左側のナビゲーションペインで、ワークロード > ポッド を選択します。
-
Pods ページの左上隅で、Pod の Namespace を選択します。次に、対象の Pod 名をクリックするか、[Actions] 列の [Details] をクリックします。
Pod 詳細ページの右上隅にあるEditをクリックすると、Pod の YAML ファイルと詳細設定を表示できます。
-
Pod の詳細ページで、Events タブをクリックします。
説明デフォルトでは、Kubernetes は過去 1 時間のイベントを保持します。イベントをより長期間保存するには、「Kubernetes イベントセンターの作成と使用」をご参照ください。
Pod ログの確認
ACS コンソール にログインします。左側のナビゲーションペインで、クラスター をクリックします。
クラスター ページで、管理するクラスターを見つけ、その ID をクリックします。クラスター詳細ページの左側のナビゲーションペインで、ワークロード > ポッド を選択します。
-
Pods ページの左上隅で、Pod の Namespace を選択します。次に、対象の Pod 名をクリックするか、[Actions] 列の [Details] をクリックします。
-
Pod の詳細ページで、Logs タブをクリックします。
説明Alibaba Cloud Container Service for Kubernetes (ACK) クラスターは Simple Log Service と統合されています。クラスター作成時に Simple Log Service を有効にすると、標準出力やコンテナ内のテキストファイルを含むコンテナログを収集できます。詳細については、「Pod 環境変数を使用したアプリケーションログ収集の設定」をご参照ください。
Pod モニタリングデータの確認
ACS コンソール にログインします。左側のナビゲーションペインで、クラスター をクリックします。
クラスター ページで、管理するクラスターを見つけ、その ID をクリックします。クラスター詳細ページの左側のナビゲーションペインで、ワークロード > Prometheus モニタリング を選択します。
-
Prometheus Monitoring ページで、クラスターの概要 タブをクリックして、Pod の CPU、メモリ、ネットワーク I/O のモニタリングダッシュボードを表示します。
ターミナルを使用したコンテナへの接続
ACS コンソール にログインします。左側のナビゲーションペインで、クラスター をクリックします。
クラスター ページで、管理するクラスターを見つけ、その ID をクリックします。クラスター詳細ページの左側のナビゲーションペインで、ワークロード > ポッド を選択します。
-
Pods ページで対象の Pod を見つけ、Actions 列の Terminal をクリックします。
説明ターミナルを使用して、コンテナ内のローカルファイルやその他の情報を確認します。
Pod 障害の診断
ACS コンソール にログインします。左側のナビゲーションペインで、クラスター をクリックします。
クラスター ページで、管理するクラスターを見つけ、その ID をクリックします。クラスター詳細ページの左側のナビゲーションペインで、ワークロード > ポッド を選択します。
-
Pods ページの左上隅で、Pod の Namespace を選択します。次に、対象の Pod 名をクリックするか、[Actions] 列の [Details] をクリックします。
-
Pods ページで対象の Pod を見つけ、Actions 列の Diagnose をクリックします。
説明Pod の診断を実行し、結果に基づいて問題を解決します。詳細については、「クラスター診断の使用」をご参照ください。
Pod が Pending 状態の場合
原因
Pending 状態の Pod はスケジュールできません。通常、リソースの依存関係やクォータの設定ミスが原因です。
現象
Pod のステータスが Pending です。
解決策
Pod イベントを調査して、Pod をスケジュールできない理由を特定します。主な原因は次のとおりです。
-
リソースの依存関係
Pod は、ConfigMap や永続ボリューム要求 (PVC) など、他のクラスターリソースに依存する場合があります。たとえば、永続ボリューム要求は、Pod で使用される前に永続ボリュームにバインドされる必要があります。
-
クォータの設定ミス
イベントと監査ログを確認します。
Pod の状態が Init、Error、または CrashLoopBackOff の場合
原因
-
Pod が
Init:N/M状態でスタックしている場合、M 個の Init コンテナのうち N 個のみが正常に起動し、残りの M-N 個のコンテナが起動に失敗しています。 -
Pod が
Init:Error状態の場合、Pod 内の Init コンテナの起動に失敗しています。 -
Pod が
Init:CrashLoopBackOff状態の場合、Init コンテナの起動に失敗し、再起動を繰り返しています。
現象
-
Pod のステータスが
Init:N/Mです。 -
Pod のステータスが
Init:Errorです。 -
Pod のステータスが
Init:CrashLoopBackOffです。
解決策
-
Pod イベントを確認し、起動していない Init コンテナに問題がないか調べます。詳細については、「Pod イベントの確認」をご参照ください。
-
起動していない Init コンテナのログを確認して、問題をトラブルシューティングします。詳細については、「Pod ログの確認」をご参照ください。
-
Pod の設定を確認し、起動していない Init コンテナの設定が正しいことを確認します。詳細については、「Pod 設定の確認」をご参照ください。Init コンテナの詳細については、「Initコンテナのデバッグ」をご参照ください。
Pod が ImagePullBackOff 状態の場合
原因
ImagePullBackOff 状態の Pod はスケジュールされましたが、コンテナイメージのプルに失敗しました。
現象
Pod のステータスが ImagePullBackOff です。
解決策
Pod イベントの説明を確認して、プルに失敗したイメージの名前を特定します。
-
コンテナイメージ名が正しいことを確認します。
-
プライベートイメージリポジトリを使用している場合の解決策については、「イメージリポジトリのイメージを使用した ACK ワークロードの作成」をご参照ください。
Pod が CrashLoopBackOff 状態の場合
原因
CrashLoopBackOff 状態は、コンテナ内のアプリケーションに問題があることを示します。
現象
Pod のステータスが CrashLoopBackOff です。
解決策
-
Pod イベントを確認して、Pod に問題があるかどうかを判断します。詳細については、「Pod イベントの確認」をご参照ください。
-
Pod のログを確認して、問題をトラブルシューティングします。詳細については、「Pod ログの確認」をご参照ください。
-
Pod の設定を確認し、コンテナのヘルスチェック設定が正しいことを確認します。詳細については、「Pod 設定の確認」をご参照ください。Pod のヘルスチェックの詳細については、「Liveness、Readiness、および Startup プローブの設定」をご参照ください。
Pod が Completed 状態の場合
原因
Pod は、すべてのコンテナプロセスが終了すると Completed 状態になります。
現象
Pod のステータスが Completed です。
解決策
Running 状態の Pod が期待どおりに動作しない場合
原因
デプロイに使用した YAML ファイルにエラーが含まれています。
現象
Pod は Running 状態ですが、期待どおりに動作しません。
解決策
-
Pod の設定を確認し、コンテナの設定が期待どおりであるかどうかを判断します。詳細については、「Pod 設定の確認」をご参照ください。
-
次の方法を使用して、環境変数のキーにスペルミスがないか確認します。
次の例は、
commandをcommndとスペルミスした場合に、その間違いを特定する方法を示しています。説明Pod を作成する際、クラスターは環境変数のキーのスペルミスを無視します。たとえば、
CommandをCommndとスペルミスしても、YAML ファイルを使用してリソースを作成できます。ただし、実行時にコンテナはスペルミスのあるコマンドを無視し、代わりにイメージからデフォルトのコマンドを実行します。-
kubectl apply -fコマンドに--validateを含めて、kubectl apply --validate -f XXX.yamlコマンドを実行します。command を commnd とスペルミスした場合、
"XXX] unknown field: commnd XXX] this may be a false alarm, see https://gXXXb.XXX/6842pods/test"というエラーメッセージが表示されます。 -
次のコマンドを実行し、出力された pod.yaml ファイルを、Pod の作成に使用した元のファイルと比較します。
kubectl get pods [$Pod] -o yaml > pod.yaml説明[$Pod]は異常な Pod の名前です。kubectl get podsコマンドを実行して Pod 名を確認できます。-
pod.yaml ファイルが、Pod の作成に使用したファイルよりも数行多い場合、作成された Pod は期待どおりです。
-
元のファイルのコード行が pod.yaml ファイルにない場合、元のファイルにスペルミスがあることを示しています。
-
-
-
Pod のログを確認して、問題をトラブルシューティングします。詳細については、「Pod ログの確認」をご参照ください。
-
ターミナルからコンテナにアクセスして、内部のローカルファイルが期待どおりであるかを確認します。詳細については、「ターミナルを使用したコンテナへの接続」をご参照ください。
Pod が Terminating 状態の場合
原因
Pod はシャットダウン中です。
現象
Pod のステータスが Terminating です。
解決策
Terminating 状態の Pod は、猶予期間が経過すると自動的に削除されます。スタックしたままの場合は、次のコマンドを実行して強制的に削除します。
kubectl delete pod [$Pod] -n [$namespace] --grace-period=0 --forcePod の OOM 問題のトラブルシューティング
原因
コンテナがメモリ制限を超えると、システムは OOM (Out of Memory) イベントでコンテナを終了させるため、予期しない終了が発生します。OOM イベントの詳細については、「コンテナと Pod へのメモリリソースの割り当て」をご参照ください。
現象
-
終了したプロセスがブロッキングプロセスの場合、コンテナが予期せず再起動することがあります。
-
OOM 問題が発生した場合、コンソールの Pod 詳細ページにある Events タブに OOM イベント "pod was OOM killed" が表示されます。
解決策
-
Pod モニタリングデータのメモリ増加曲線を確認して、問題が発生した時期を特定します。詳細については、「Pod モニタリングデータの確認」をご参照ください。
-
モニタリングデータ、メモリ増加のタイムライン、ログ、プロセス名に基づいて、対応するプロセスにメモリリークがあるかどうかを確認します。
-
OOM の原因がプロセスのメモリリークである場合は、アプリケーション側で根本原因をトラブルシューティングします。
-
プロセスが正常に実行されている場合は、ワークロードの要件に基づいて Pod のメモリ制限を増やします。Pod の実際のメモリ使用量が、メモリ制限の 80% を超えないようにしてください。詳細については、「Pod の管理」をご参照ください。
-