サービスメッシュ(ASM)では、サービスごとに異なる可観測性データを収集する必要がある場合があります。そのため、サイドカープロキシとゲートウェイポッドの可観測性データの収集設定ルールを個別に定義し、収集設定ルールを標準化して、クラウドネイティブアプリケーションの可観測性を向上させる必要があります。可観測性は、サービスの運用とパフォーマンスをリアルタイムで監視し、サービスの問題とボトルネックを発見して解決するために非常に重要です。したがって、アプリケーションの信頼性とパフォーマンスの向上に役立ちます。ASM は、クラウドネイティブアプリケーションの可観測性データを生成および収集するための中央集中型で標準化されたモードを提供します。このようにして、クラウドネイティブアプリケーションの可観測性を向上させることができます。このトピックでは、可観測性に関連する概念と機能について説明します。
はじめに
マイクロサービスアーキテクチャにおけるアプリケーションの複雑さのため、すべてのサービスが安定した状態で実行されていることを保証することは困難です。一部のサービスは、何らかの問題が原因でパフォーマンスが低下する可能性があります。したがって、アプリケーションは信頼性が高く、回復力があり、実行時にアプリケーションとインフラストラクチャの状態を監視するための可観測性ツールが利用可能である必要があります。ランタイム情報を取得できれば、予期しない状況が発生した場合に障害を検出し、詳細なデバッグを実行できます。これは、平均サービス復旧時間(MTTR)の短縮とビジネスへの影響の軽減に役立ちます。
可観測性は、アプリケーション、ネットワーク、インフラストラクチャ(データベースやストレージなど)などのさまざまなレベルのメトリクスに依存する機能です。これらのメトリクスを使用すると、予期しない問題が発生したときに、その問題を徹底的に理解できます。ASM は、可観測性の観点からアプリケーションメトリクスの収集を効果的に促進できます。実際的な観点からは、アプリケーションの安定性にさらに注意を払い、アプリケーションのリアルタイムの実行状態を把握する必要があります。このようにして、問題を迅速に検出し、適切な対策を講じてアプリケーションの可用性を維持できます。
データプレーン上のサイドカープロキシは、サービスリクエストパスにデプロイされます。サイドカープロキシの可観測性データを分析することにより、対応するサービスとサービスメッシュの実行状態を実行時に監視できます。
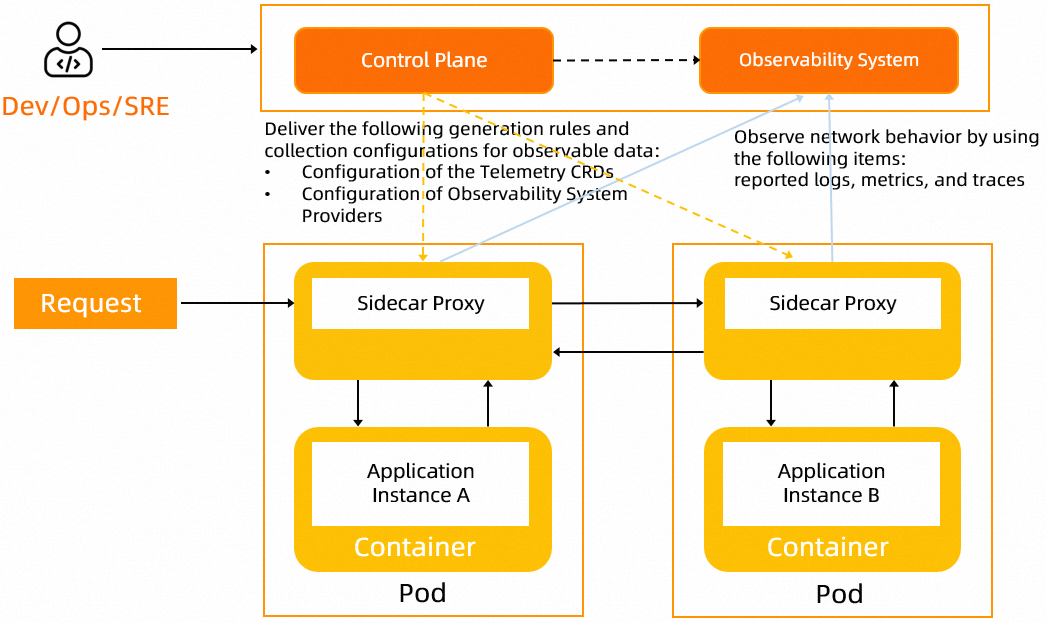
ASM の可観測性機能の実装には、ログ、メトリクス、トレーシング分析などの可観測性データを生成および収集するためのルールの構成が含まれます。さらに、可観測性機能は、クラウドベースのサービスまたはセルフマネージドサービスに可観測性データを収集する方法を提供する必要があります。さまざまな要件を満たすために、可観測性機能は、サイドカープロキシとゲートウェイポッドのカスタム収集構成をサポートする必要があります。ASM は、クラウドネイティブアプリケーションの可観測性データを生成および収集するための中央集中型で標準化されたモードを提供します。これは、クラウドネイティブアプリケーションの可観測性の向上に役立ちます。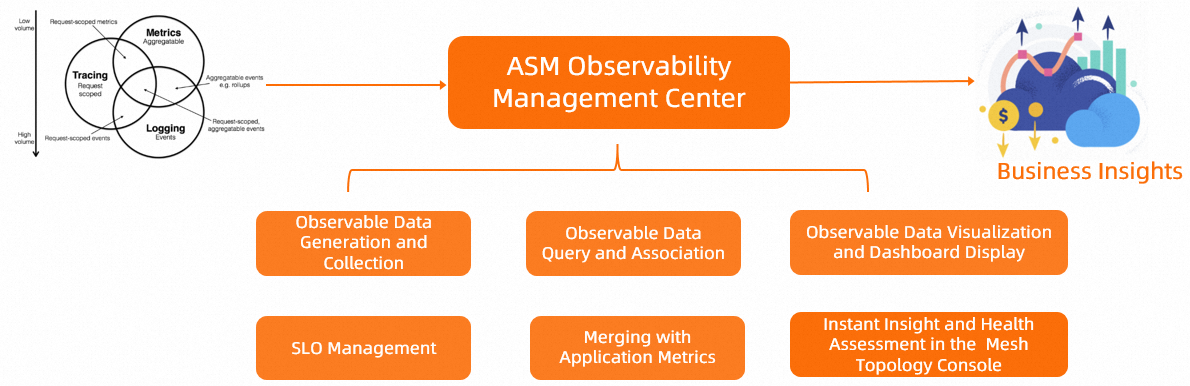
ベストプラクティス
Telemetry CustomResourceDefinitions(CRD)を使用して、複数のネームスペースに複数のリソースを作成できます。ただし、CRD を任意に定義すると、競合や予期しない結果が発生する可能性があります。次のセクションでは、実際の経験に基づいたベストプラクティスを示します。
istio-system ルートネームスペースには、1 つの Telemetry CRD のみが存在できます。 istio-system ネームスペースに複数の Telemetry CRD を定義することはできません。ASM はこのベストプラクティスを適用し、istio-system ネームスペースに default という名前の Telemetry CRD を 1 つだけ定義できます。
ワークロードセレクターが空で、名前が default である Telemetry CRD は、すべてのネームスペースで 1 つだけ定義できます。
特定のワークロードをオーバーライドするには、新しい Telemetry CRD でワークロードセレクターを定義して、目的のネームスペースのワークロードを選択できます。
2 つの Telemetry CRD に同じワークロードセレクターがある場合、2 つの CRD のどちらが実行されるかは不明です。
istio-system ネームスペースの Telemetry CRD でメトリクスが構成されていない場合、メトリクスは生成されません。
ログ
ASM では、ログ収集はサービスを観察するための重要な手段です。ログを統一的に管理および取得するには、すべてのサービスのログをまとめて集約する必要があります。これを行うには、各サービスのログを stdout または stderr に出力し、ロギングエージェントを使用してログを中央のロギングシステムに収集する必要があります。ASM は、ログフィルタリングとログフォーマット機能を提供します。ログをフィルタリングし、必要に応じてログ形式を設定して、ログの取得と分析を改善できます。
ログ形式ルールの構成
さまざまなサービスのログ形式は異なる場合があります。したがって、ログの生成方法を制御するために生成ルールを構成する必要があります。 Kubernetes クラスタを ASM インスタンスに追加すると、ASM インスタンスのデータプレーンにデプロイされた Envoy プロキシは、クラスタのすべてのアクセスログを出力できます。ASM では、Envoy プロキシによって出力されるアクセスログのフィールドをカスタマイズできます。
Telemetry CRD に基づいて、ASM は次の図に示すようにグラフィカルインターフェースを提供して、ログデータ形式の構成を簡素化します。詳細については、「データプレーンでのアクセスログのカスタマイズ」をご参照ください。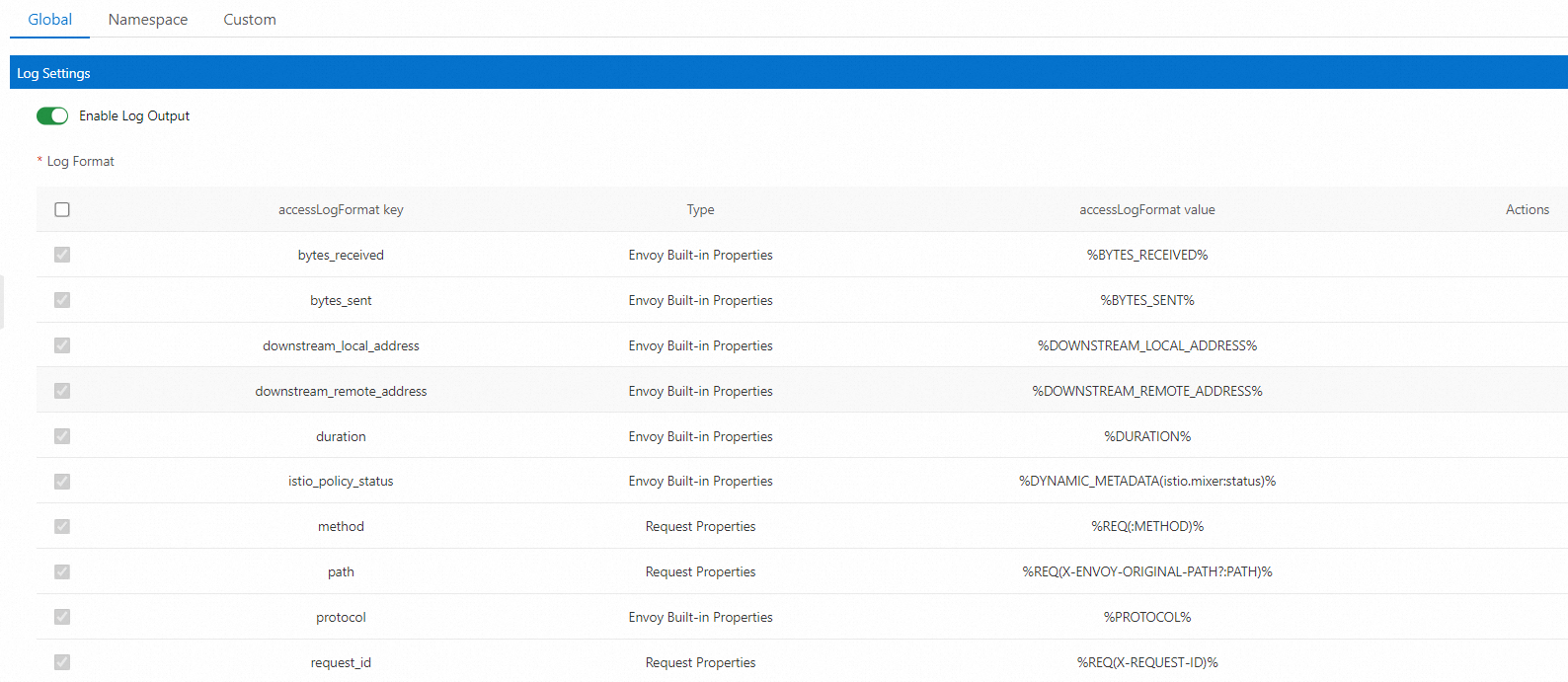
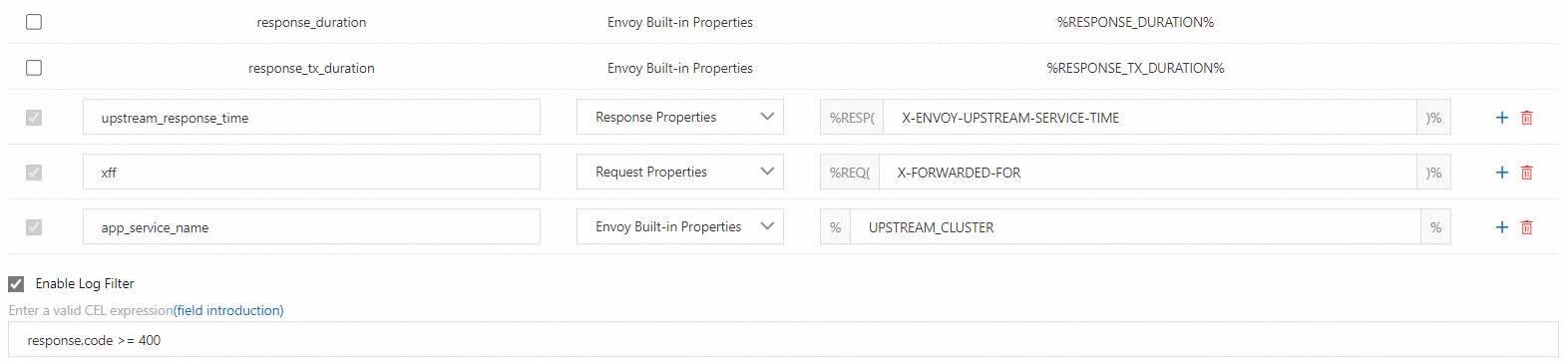
次のサンプルコードは、前のグラフィカルインターフェースのログ生成構成と同等です。
envoyFileAccessLog:
logFormat:
text: '{"bytes_received":"%BYTES_RECEIVED%","bytes_sent":"%BYTES_SENT%","downstream_local_address":"%DOWNSTREAM_LOCAL_ADDRESS%","downstream_remote_address":"%DOWNSTREAM_REMOTE_ADDRESS%","duration":"%DURATION%","istio_policy_status":"%DYNAMIC_METADATA(istio.mixer:status)%","method":"%REQ(:METHOD)%","path":"%REQ(X-ENVOY-ORIGINAL-PATH?:PATH)%","protocol":"%PROTOCOL%","request_id":"%REQ(X-REQUEST-ID)%","requested_server_name":"%REQUESTED_SERVER_NAME%","response_code":"%RESPONSE_CODE%","response_flags":"%RESPONSE_FLAGS%","route_name":"%ROUTE_NAME%","start_time":"%START_TIME%","trace_id":"%REQ(X-B3-TRACEID)%","upstream_cluster":"%UPSTREAM_CLUSTER%","upstream_host":"%UPSTREAM_HOST%","upstream_local_address":"%UPSTREAM_LOCAL_ADDRESS%","upstream_service_time":"%RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)%","upstream_transport_failure_reason":"%UPSTREAM_TRANSPORT_FAILURE_REASON%","user_agent":"%REQ(USER-AGENT)%","x_forwarded_for":"%REQ(X-FORWARDED-FOR)%","authority_for":"%REQ(:AUTHORITY)%","upstream_response_time":"%RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)%","xff":"%REQ(X-FORWARDED-FOR)%","app_service_name":"%UPSTREAM_CLUSTER%"}'
path: /dev/stdout次のサンプルコードは、前のグラフィカルインターフェースの対応するフィルター条件の構成と同等です。
accessLogging:
- disabled: false
filter:
expression: response.code >= 400
providers:
- name: envoyデータプレーンログ収集の構成
ログサービスにデータプレーンからログを収集する場合は、ログの収集方法とストレージの有効期間を制御するログ収集ルールを設定する必要があります。コンテナサービス Kubernetes 版(ACK)はログサービスと統合されています。ASM インスタンスのデータプレーンにあるクラスタのアクセスログを収集できます。詳細については、「ログサービスを使用してデータプレーンでアクセスログを収集する」をご参照ください。
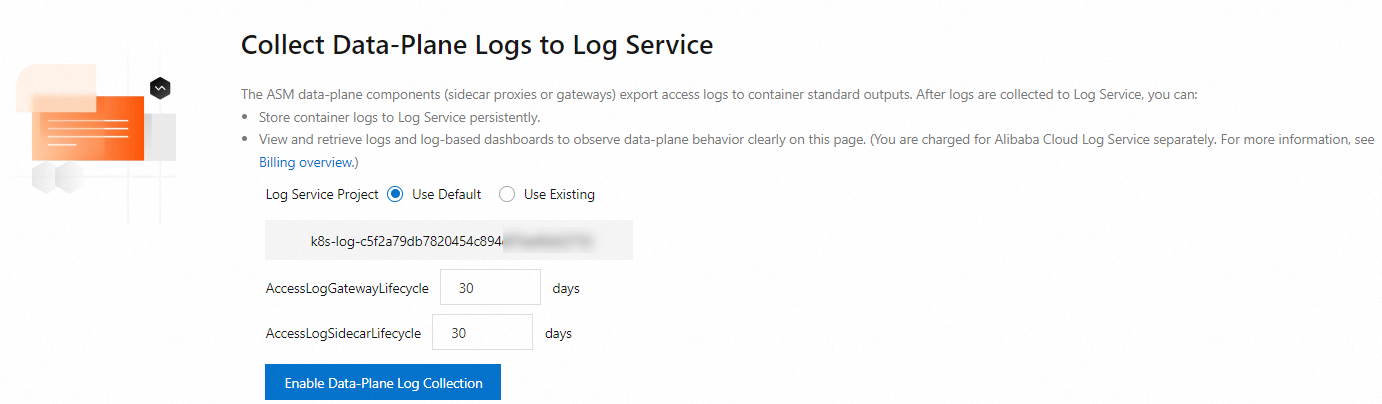
コントロールプレーンログの収集とアラートの構成
ASM では、コントロールプレーンログを収集し、ログデータに基づいてアラート通知を送信できます。たとえば、ASM インスタンスのコントロールプレーンからデータプレーン上のサイドカープロキシへの構成プッシュに関連するログを収集できます。ASM コントロールプレーン上のコンポーネントの主な機能の 1 つは、構成をデータプレーン上のサイドカープロキシまたはイングレスゲートウェイにプッシュすることです。構成の競合が発生した場合、サイドカープロキシまたはイングレスゲートウェイは構成を受信できません。サイドカープロキシまたはイングレスゲートウェイは、以前に受信した構成に基づいて引き続き実行される可能性があります。ただし、サイドカープロキシまたはイングレスゲートウェイが存在するポッドが再起動された場合、サイドカープロキシまたはイングレスゲートウェイは失敗する可能性があります。多くの実際的な状況では、構成が不適切なために、サイドカープロキシまたはイングレスゲートウェイが使用できなくなります。したがって、ログベースのアラートを有効にして、問題をタイムリーに検出して解決することをお勧めします。詳細については、「バージョン 1.17.2.35 より前の ASM インスタンスでコントロールプレーンログ収集とログベースのアラートを有効にする」または「バージョン 1.17.2.35 以降の ASM インスタンスでコントロールプレーンログ収集とログベースのアラートを有効にする」をご参照ください。
メトリクス
メトリクスは、ユーザーが ASM でサービスを観察するために重要です。メトリクスは、リクエストの処理とサービス間の通信を記述するために使用されます。Istio は Prometheus エージェントを使用してメトリクスを収集および保存します。各サービスの Envoy プロキシは、多数のメトリクスを生成します。メトリクスは、サービスの運用とパフォーマンスをリアルタイムで監視するために使用できます。メトリクスは、異常検出や自動スケーリングなどのシナリオでも使用できます。
メトリクスデータ生成ルールの構成
データプレーンメトリクスを有効にすると、データプレーンはゲートウェイとサイドカープロキシの動作状態に関連するメトリクスデータを生成します。メトリクスを Managed Service for Prometheus に収集して、監視レポートを表示できます。メトリクスの収集には料金が発生する場合があります。または、セルフマネージド Prometheus インスタンスを作成して、ASM インスタンスのデータプレーンからメトリクスを収集することもできます。
Telemetry CRD に基づいて、ASM は次の図に示すようにグラフィカルインターフェースを提供して、カスタムメトリクスの構成を簡素化します。詳細については、「ASM でカスタムメトリクスを作成する」をご参照ください。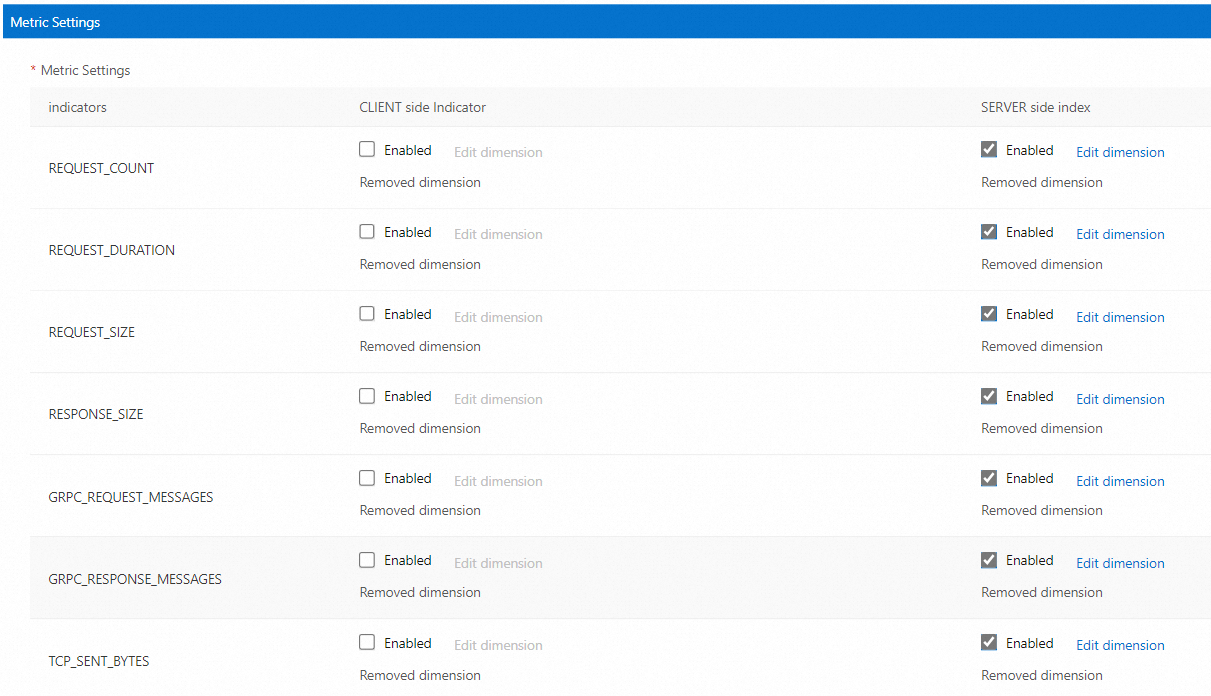
次のサンプルコードは、前のグラフィカルインターフェースのカスタムメトリクスの構成と同等です。
メトリクスの考慮事項
Managed Service for Prometheus は有料サービスです。初めて有効にする場合は、ビジネス要件に基づいて観察するメトリクスの範囲を決定します。多数のメトリクスを観察すると、過剰な料金が発生します。たとえば、ゲートウェイを監視する場合は、クライアント側のメトリクスを有効にする必要があります。メトリクスを有効にした場合、メトリクスを再度有効にすると、メトリクスの以前の設定が保持されます。
メッシュトポロジ機能は、サイドカープロキシによって報告されるメトリクスに依存します。メッシュトポロジを有効にした場合、一部のメトリクスを無効にすると、メッシュトポロジの通常の動作に影響を与える可能性があります。
REQUEST_COUNT のサーバー側メトリクスを有効にしないと、HTTP または gRPC サービスのトポロジを生成できません。
TCP_SENT_BYTES のサーバー側メトリクスを有効にしないと、TCP サービスのトポロジを生成できません。
REQUEST_SIZE と REQUEST_DURATION のサーバー側メトリクスと REQUEST_SIZE のクライアント側メトリクスを無効にすると、トポロジ内の一部のノードの監視情報が表示されない場合があります。
メトリクス収集の構成
Managed Service for Prometheus を有効にした後、Managed Service for Prometheus にメトリクスを収集して、ストレージと分析を行うことができます。ASM は Managed Service for Prometheus を統合して、サービスメッシュを監視します。詳細については、「Managed Service for Prometheus を統合して ASM インスタンスを監視する」をご参照ください。
メトリクス収集間隔は、メトリクス収集のオーバーヘッドに大きな影響を与えます。間隔が長いほど、データキャプチャ頻度が低くなります。これにより、メトリクスの処理、ストレージ、計算によって発生するオーバーヘッドが削減されます。メトリクス収集間隔はデフォルトで 15 秒に設定されています。この値は、本番シナリオでは小さい場合があります。ビジネス要件に基づいて適切なメトリクス収集間隔を設定できます。 Managed Service for Prometheus を使用してメトリクスを収集する場合は、Application Real-Time Monitoring Service(ARMS)コンソールで必要なパラメータを構成します。詳細については、「カスタムデータ統合」をご参照ください。
istio_request_duration_milliseconds_bucket、istio_request_bytes_bucket、istio_response_bytes_bucket などのヒストグラムで表されるメトリクスは、大量のデータを含み、高いオーバーヘッドを生成します。これらのカスタムメトリクスによって発生する継続的な料金を回避するために、これらのカスタムメトリクスを破棄できます。 Managed Service for Prometheus を使用している場合は、ARMS コンソールに移動してメトリクスを構成します。詳細については、「メトリクスの破棄」をご参照ください。
セルフマネージド Prometheus インスタンスをデプロイして、ASM インスタンスを監視できます。詳細については、「セルフマネージド Prometheus インスタンスを使用して ASM インスタンスを監視する」をご参照ください。
次の図に示すように、Grafana ダッシュボードでメトリクスを表示できます。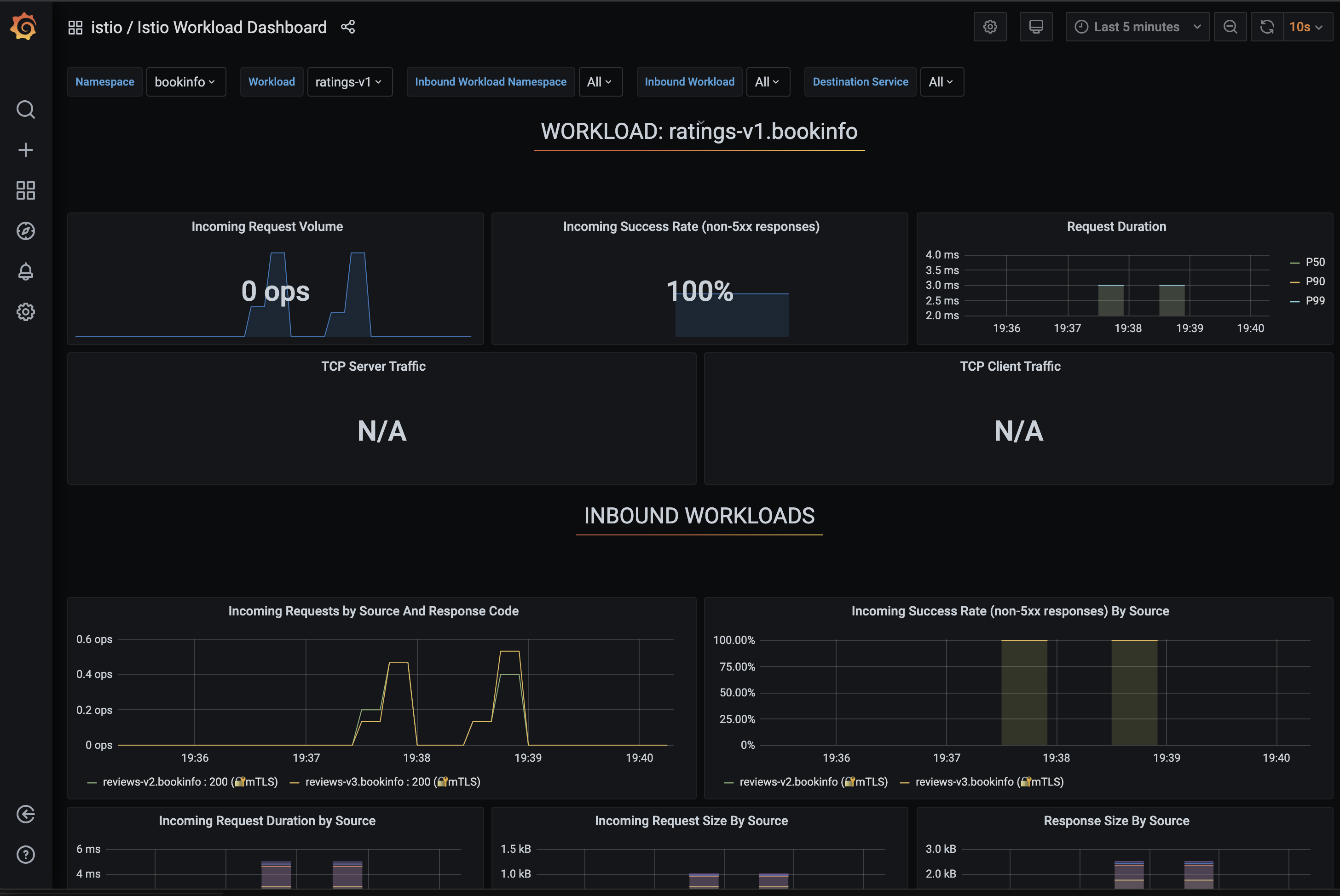
Istio メトリクスとアプリケーションメトリクスのマージ
Prometheus と統合されたアプリケーションの場合、サイドカープロキシを使用して、Istio メトリクスとアプリケーションメトリクスをマージすることにより、アプリケーションメトリクスを公開できます。Istio メトリクスとアプリケーションメトリクスをマージする機能を有効にすると、ASM はアプリケーションメトリクスを Istio メトリクスとマージします。アプリケーションの prometheus.io アノテーションは、データプレーンのすべてのポッドに追加され、Prometheus のメトリクススクレイピング機能を有効にします。これらのアノテーションが既に存在する場合は、上書きされます。サイドカープロキシは、Istio メトリクスとアプリケーションメトリクスをマージします。Prometheus は、:15020/stats/prometheus エンドポイントからマージされたメトリクスを取得できます。詳細については、「Istio メトリクスとアプリケーションメトリクスのマージ」をご参照ください。
メッシュトポロジ
メッシュトポロジは、ASM インスタンスを観察するために使用されるツールです。このツールは、関連するサービスと構成を表示できる GUI を提供します。次の図は、アプリケーションのサービストポロジを示しています。詳細については、「メッシュトポロジを有効にして可観測性を向上させる」をご参照ください。
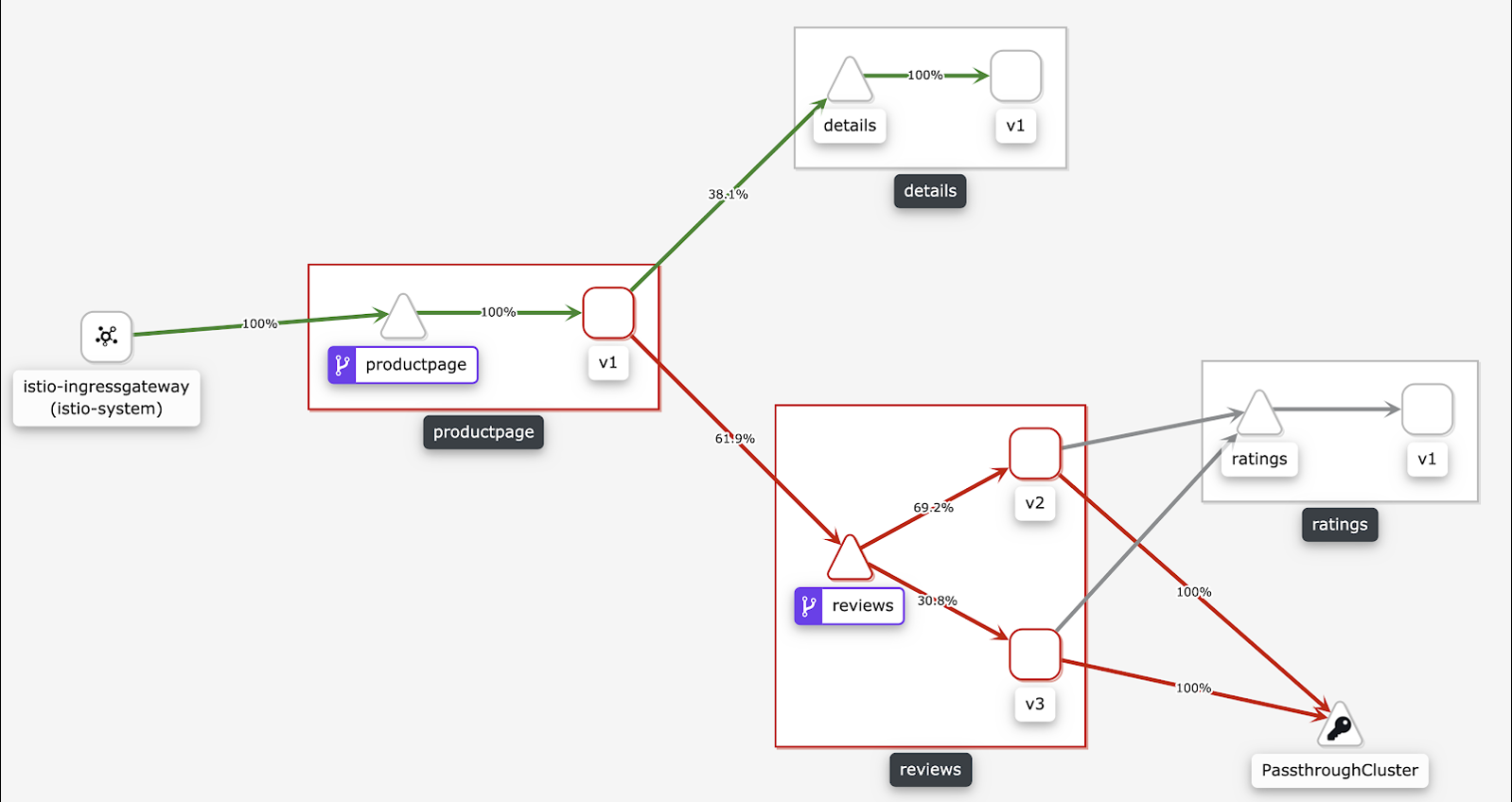
SLO
サービスレベル指標(SLI)は、サービスの健全性を測定するメトリクスです。サービスレベル目標(SLO)は、サービスが達成する必要がある目標または目標の範囲です。SLO は、1 つ以上の SLI で構成されます。
SLO は、マイクロサービス指向アプリケーションのパフォーマンス、品質、信頼性を記述、測定、監視するための正式な方法を提供します。SLO は、アプリケーション開発者、プラットフォームオペレーター、O&M 担当者にとって共有の品質ベンチマークです。SLO を参照として使用して、サービス品質を測定し、継続的に改善できます。SLO は、サービスの健全性をより正確に記述するのに役立ちます。
SLO の例:
1 秒あたりの平均クエリ数(QPS)> 100,000/秒
99% のアクセスリクエストのレイテンシ < 500 ミリ秒
99% のアクセスリクエストの 1 分あたりの帯域幅 > 200 MB/秒
ASM は、SLO に基づいてすぐに使用できる監視およびアラート機能を提供します。レイテンシやエラー率など、アプリケーションサービス間の呼び出しのパフォーマンスメトリクスを監視できます。
ASM は、次の SLI タイプをサポートしています。
サービスの可用性:正常に応答されたアクセスリクエストの割合を示します。この SLI タイプのプラグインタイプは availability です。アクセスリクエストに返された HTTP ステータスコードが 429 または 5XX の場合、アクセスリクエストは正常に応答されません。5XX は、ステータスコードが 5 で始まることを意味します。
レイテンシ:サービスがリクエストに応答を返すのに必要な時間を示します。この SLI タイプのプラグインタイプは latency です。最大レイテンシを指定できます。指定された期間より後に返された応答は、不適格と見なされます。
次の図は、ASM が SLO 構成を定義するために提供する GUI を示しています。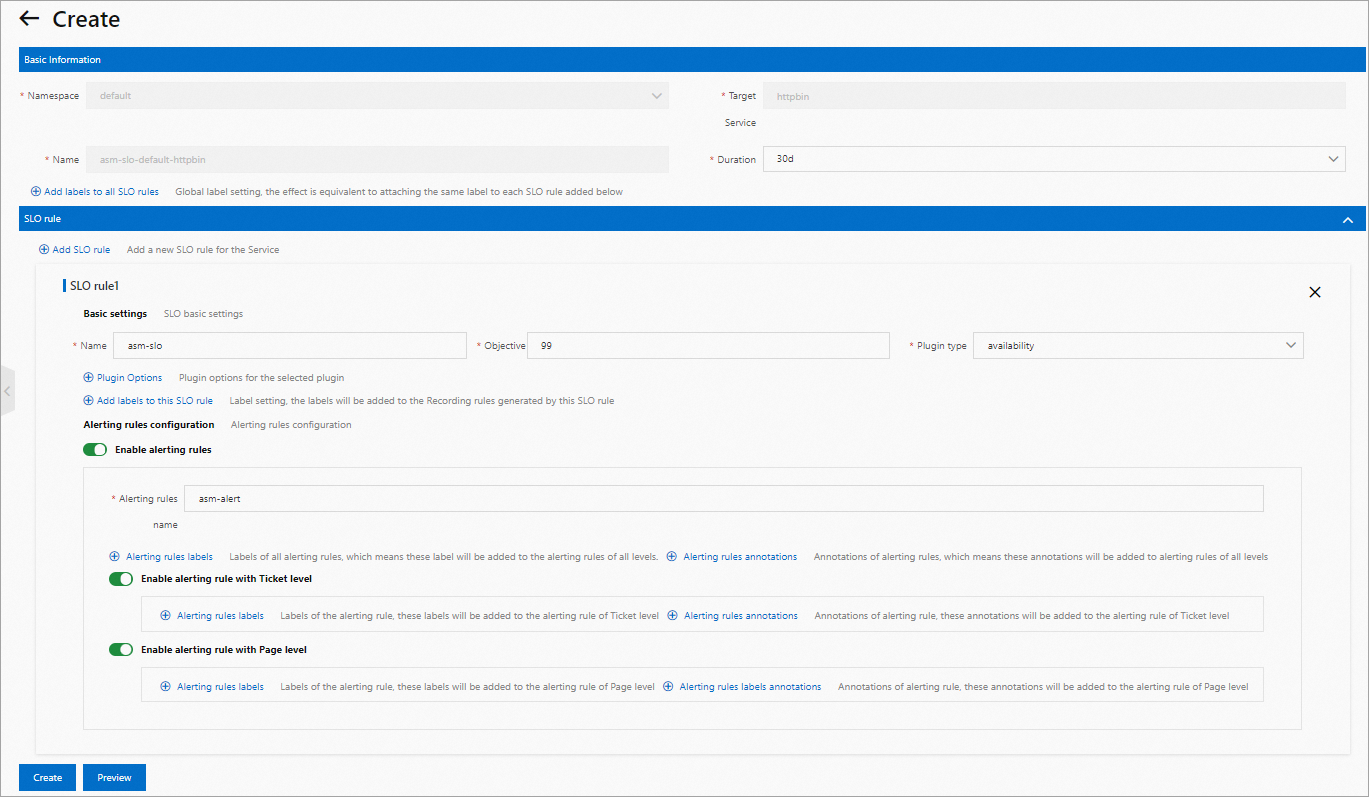
ASM でアプリケーションの SLO を構成すると、Prometheus ルールが自動的に生成されます。生成された Prometheus ルールを Prometheus システムにインポートして、SLO を有効にすることができます。 Alertmanager コンポーネントは、Prometheus サーバーによって生成されたアラートを収集し、指定された連絡先にアラートを送信します。次の図は、カスタムアラート情報が収集されている [alertmanager] ページを示しています。SLO の詳細については、「SLO 管理」をご参照ください。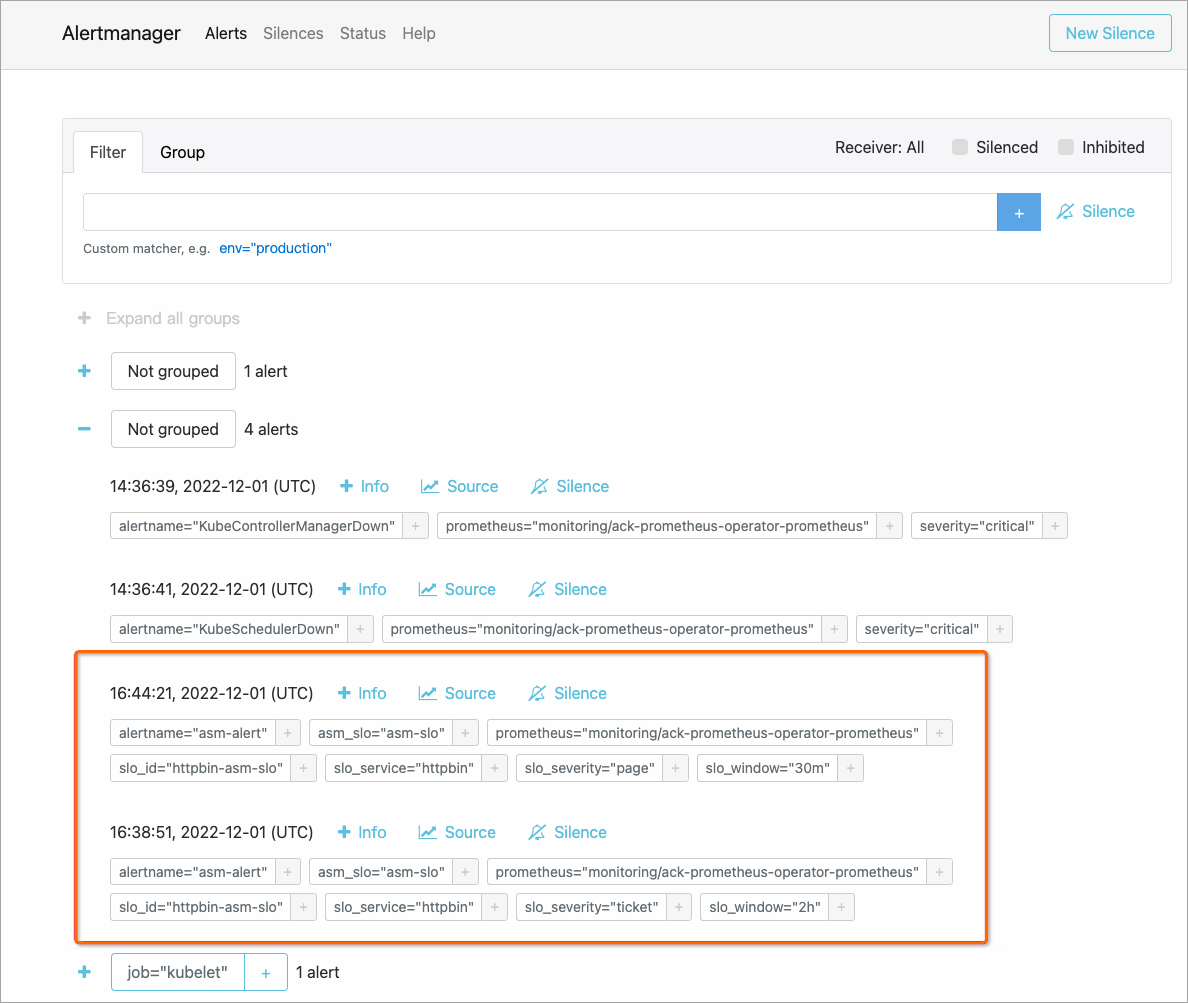
分散トレーシング
分散トレーシングは、アプリケーション、特にマイクロサービスモデルを使用して構築されたアプリケーションのプロファイリングと監視に使用できます。これは、ASM の可観測性の重要な機能です。マイクロサービスモデルでは、メッシュはサービス間の通信を制御します。したがって、分散トレーシングテクノロジーを使用して、サービス間の呼び出しを追跡および監視する必要があります。Istio では、Jaeger や Zipkin などの分散トレーシングツールを使用して、この目標を達成できます。分散トレーシングでは、トレースとスパンという 2 つの概念が重要です。
スパン:分散トレーシングの基本的な構成要素。スパンは、作業または操作の単位を表します。スパンはネストできます。複数のスパンがトレースを形成します。
トレース:リクエストの開始から完了までの完全なプロセスを表します。トレースは複数のスパンで構成されます。
Istio プロキシはスパンを自動的に送信できますが、トレース全体を結び付けるにはいくつかのヒントが必要です。アプリケーションは適切な HTTP ヘッダーを伝達する必要があり、Istio プロキシによって送信されたスパンを 1 つのトレースに正しく関連付けることができます。これを行うには、アプリケーションは次のヘッダーを収集し、インバウンドリクエストからすべてのアウトバウンドリクエストに伝達する必要があります。
x-request-id
x-b3-traceid
x-b3-spanid
x-b3-parentspanid
x-b3-sampled
x-b3-flags
x-ot-span-context
トレーシングデータ生成ルールの構成
Telemetry CRD に基づいて、ASM は次の図に示すようにグラフィカルインターフェースを提供して、分散トレーシングデータの生成ルールの構成を簡素化します。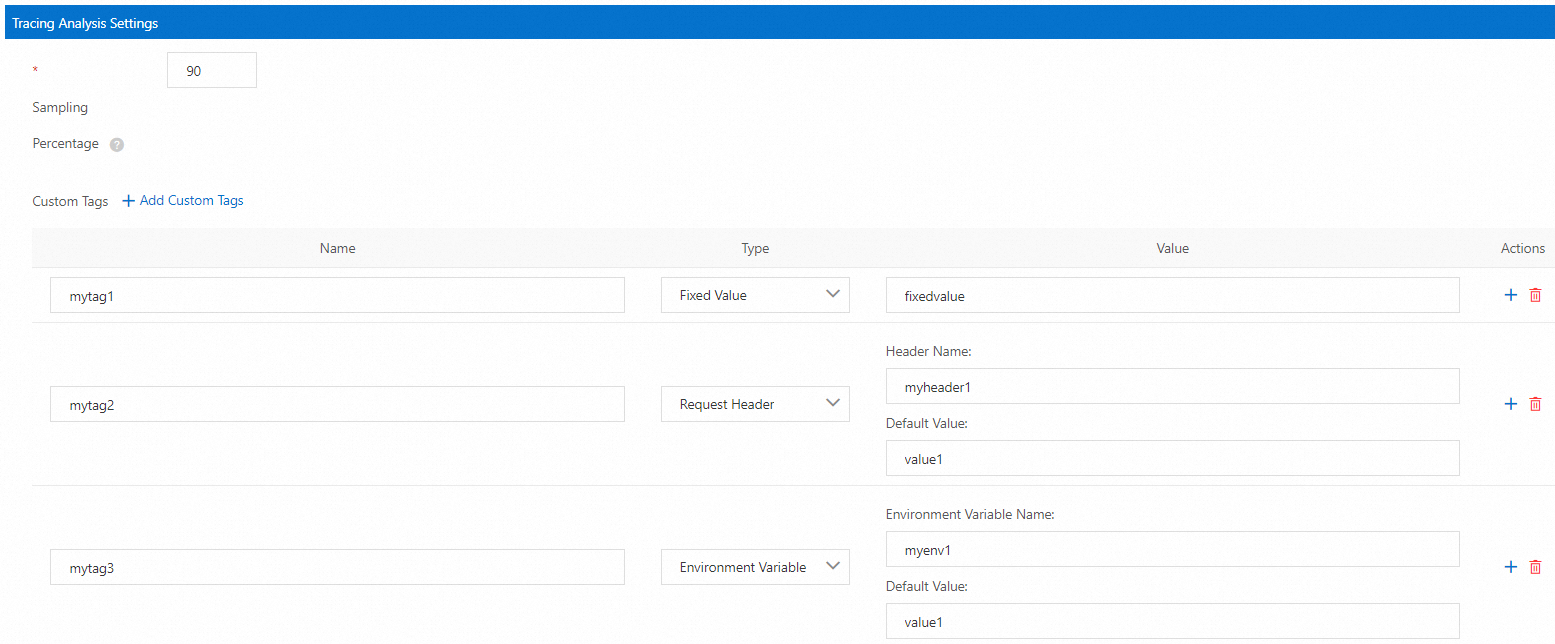
次のサンプルコードは、前のグラフィカルインターフェースの分散トレーシングデータの生成ルールの構成と同等です。
tracing:
- customTags:
mytag1:
literal:
value: fixedvalue
mytag2:
header:
defaultValue: value1
name: myheader1
mytag3:
environment:
defaultValue: value1
name: myenv1
providers:
- name: zipkin
randomSamplingPercentage: 90トレーシングデータ収集の構成
収集したトレーシングデータをマネージドクラウドサービスまたはセルフマネージドサービスに送信する必要がある場合は、次の方法を使用できます。
マネージドクラウドサービスでは、クラウドネイティブアプリケーション管理サービスを使用してデータを収集および分析できます。詳細については、「ASM で分散トレーシングを有効にする」をご参照ください。
セルフマネージドサービスでは、Zipkin や Jaeger などのオープンソースデータ収集および分析ツールを使用してデータを収集および分析できます。詳細については、「ASM トレーシングデータをセルフマネージドシステムにエクスポートする」をご参照ください。