インスタンスがモニタリングデータをレポートしないのはなぜですか?
2018 年 11 月より前にデプロイされた ApsaraMQ for Kafka クラスターは、モニタリングとアラートデータをレポートしません。コンソールにはモニタリングコントロールが表示されますが、基盤となるクラスターはモニタリングシステムにデータを送信しません。
この問題を解決するには、インスタンスをスペックアップしてください。スペックアップ後、クラスターはモニタリングおよびアラートデータのレポートを開始します。手順については、「インスタンスのバージョンをスペックアップする」をご参照ください。
アラートステータスが「データなし」と表示されるのはなぜですか?
最も可能性の高い原因は、マイナーバージョンが古いことです。古いマイナーバージョンでは、特定のメトリックが CloudMonitor にレポートされない場合があり、アラートルールが評価されません。
マイナーバージョンが既に最新の状態であり、[ステータス] が依然として [データなし] を表示している場合は、Alibaba Cloud テクニカルサポートにお問い合わせください。
マイナーバージョンの確認と更新
ApsaraMQ for Kafka コンソールにログインします。
[概要] ページの [リソース分布] セクションで、インスタンスが存在するリージョンを選択します。
[インスタンス] ページで、インスタンスの名前をクリックします。
[インスタンスの詳細] ページで、[インスタンス情報] タブをクリックします。
[基本情報] セクションで、[マイナーバージョン] フィールドの横に [マイナーバージョンアップデート] が利用可能かどうかを確認します。
アップデートがある場合、[マイナーバージョン更新] をクリックします。
表示されるパネルで、次の操作を行います。
[アップグレード前に必ずお読みください] セクションを読みます。
お名前を [緊急連絡先] フィールドに入力してください。
電話番号を [緊急連絡先電話番号] フィールドに入力してください。
[開始時刻] フィールドにアップグレード時間を入力します。
[OK] をクリックします。
マイナーバージョンアップが完了すると、[ステータス] 列の [リソースに関連付けられたアラートルール] パネルが [データなし] から [OK] や [アラート] などの有効な状態に変化します。
RAM ユーザーがモニタリングデータを表示できないのはなぜですか?
RAM ユーザーには、必要な CloudMonitor の権限がありません。RAM コンソールを使用して、RAM ユーザーに AliyunCloudMonitorReadOnlyAccess システムポリシーをアタッチします。
Alibaba Cloud アカウント (root ユーザー) で RAM コンソールにログインします。
AliyunCloudMonitorReadOnlyAccessポリシーを対象の RAM ユーザーにアタッチします。
ポリシーがアタッチされると、RAM ユーザーはモニタリングデータを表示できます。詳細については、「RAM ユーザーへの権限付与」をご参照ください。
ApsaraMQ for Kafka インスタンスにログインできますか?
いいえ、できません。ApsaraMQ for Kafka はフルマネージドサービスです。ApsaraMQ for Kafka チームがお客様に代わって基盤となるインフラストラクチャを運用および保守するため、インスタンスへの直接アクセスは不要であり、サポートされていません。
クラスターの健全性を監視するには、コンソールの [モニタリングとアラート] 機能を使用してください。これにより、インスタンスレベルのアクセスなしで必要なクラスター情報が提供されます。
オープンソース Apache Kafka をモニタリングするにはどうすればよいですか?
オープンソース Apache Kafka のモニタリングについては、次のリソースをご参照ください。
グループ削除後もメッセージ蓄積アラートが継続するのはなぜですか?
グループを削除しても、サーバーに保存されているコンシューマオフセットは削除されません。アラートシステムはこれらのオフセットを監視するため、オフセットが存在する限りアラートは継続します。
これには 2 つの理由があります。
削除後もオフセットは保持される。 サーバー側バージョン 2.2.0 (Apache Kafka 0.10.2 ベース) より前のバージョンでは、Kafka API はコンシューマオフセットの削除をサポートしていません。グループを削除しても、コンソールから削除されるだけで、基盤となるオフセットデータはサーバーに残ります。
コンシューマースレッドが依然としてアクティブである。 グループが削除された後でも、明示的に停止されていない場合、コンシューマースレッドは実行を継続する可能性があります。これらのスレッドはオフセットをコミットし続けるため、蓄積アラートがトリガーされます。
事前準備
以下のいずれかのソリューションを試行する前に、グループ内のすべてのコンシューマースレッドを停止してください。アクティブなコンシューマースレッドとは、subscribe メソッドを使用してメッセージをサブスクライブするスレッドのことです。いずれかのスレッドがまだオフセットをコミットしている場合、他の操作に関係なくアラートが継続します。
コンシューマオフセットのリセット (推奨)
このアプローチは、すべてのサーバー側バージョンで機能し、アラートを停止する最速の方法です。
グループがコンソールに存在することを確認します。すでに削除している場合は、再作成してください。
すべてのコンシューマースレッドを切断します。
ApsaraMQ for Kafka コンソールで、メッセージ蓄積の追跡を停止するパーティションのコンシューマオフセットを 0 にリセットします。手順については、「コンシューマオフセットのリセット」をご参照ください。
リセット後、アラートシステムはそれらのパーティションの蓄積量の追跡を停止します。
グループの直接削除 (サーバー側バージョン 2.2.0 以降)
ご利用のインスタンスがサーバー側バージョン 2.2.0 以降を実行しており、グループにアクティブなコンシューマースレッドがない場合は、グループを直接削除してください。サーバーはグループとそのコンシューマオフセットの両方を削除します。
削除後もアラートが継続する場合は、コンシューマースレッドがオフセットをコミットし続けていないことを確認してください。
オフセットの有効期限切れを待つ (サーバー側バージョン 2.2.0 より前)
古いサーバー側のバージョンでは、コンシューマオフセットは、設定されたコンシューマオフセットの保存期間が満了した後に自動的にクリアされます。ただし、コンシューマスレッドがそれらを更新しない場合に限ります。保存期間の確認または調整については、「メッセージ構成の変更」をご参照ください。
サーバー側バージョンのアップグレード (サーバー側バージョン 2.2.0 より前)
グループにアクティブなコンシューマースレッドがない場合、サーバー側のバージョンを 2.2.0 以降にアップグレードしてください。アップグレード後、オフセットを削除するには、グループを再作成してから削除してください。詳細については、「インスタンスバージョンのアップグレード」をご参照ください。
メッセージ蓄積アラートの無効化
前述のいずれのソリューションでも問題が解決しない場合は、 CloudMonitor でメッセージ蓄積のアラートルールを無効にします。 詳細については、「CloudMonitor」をご参照ください。
サーバー側のバージョン 2.2.0 以降では、グループにアクティブなコンシューマースレッドが少なくとも 1 つ存在する限り、コンシューマオフセットは、そのオフセットがコンシューマオフセットの保存期間を超過した場合でも削除されません。 詳細については、「コンシューマオフセットの有効期限が切れた後も削除されないのはなぜですか?
関連トピック
アラートの蓄積数がコンソールと異なるのはなぜですか?
アラートシステムとコンソールでは、メッセージ蓄積の計算方法が異なります。わずかな不一致は想定内であり、問題を示すものではありません。
どちらも同じパーティションごとの数式を使用します。
Accumulated messages = Maximum offset - Consumer offset合計はすべてのパーティションの合計です。不一致は、各メソッドがオフセットをフェッチするタイミングに起因します。
各メソッドによる蓄積量の計算方法
コンソール (グループ詳細ページ)
[グループ詳細] ページは、個別の連続したリモートプロシージャコール (RPC) リクエストで、各パーティションのコンシューマオフセットと最大オフセットを取得します。これら 2 つのリクエストの時間差が小さいため、結果はその時点での実際の蓄積状況をほぼ正確に反映します。
アラートシステム
アラートシステムは、インスタンス上のすべてのコンシューマーグループと Topic を同時に監視します。オーバーヘッドを削減するため、オフセットリクエストはバッチで処理されます。1 つの RPC リクエストで全てのコンシューマーグループのコンシューマオフセットを取得し、もう 1 つのリクエストでサブスクライブされている全ての Topic にわたる全パーティションの最大オフセットを取得します。これにより、RPC リクエストの総数は m x n x number of brokers から number of brokers のみに削減されます。ここで、m はコンシューマーグループの数、n は Topic の数です。
トレードオフはタイミングのずれです。2 つのバッチリクエストの間でプロデューサーはメッセージを送信し続けるため、コンシューマオフセットが固定されたままで最大オフセットが増加します。これにより、計算された蓄積量が増加します。
例: あるパーティションのコンシューマオフセットが 1,000、最大オフセットが 1,050 で、最初のバッチリクエストが実行されたとします。200 ミリ秒後に 2 番目のバッチリクエストが最大オフセットをフェッチするまでに、プロデューサーはさらに 30 個のメッセージを書き込み、最大オフセットを 1,080 に押し上げます。アラートは 80 個の蓄積メッセージ (1,080 - 1,000) をレポートしますが、コンソールでは 50 個 (1,050 - 1,000) に近い値がレポートされます。
期限切れメッセージがより大きな不一致を引き起こす場合
消費レートが非常に遅く、ディスク使用率が高い場合、インスタンスはコンシューマーが処理する前にメッセージを削除する可能性があります。この状況では、一部のパーティションのコンシューマオフセットがパーティションの最小オフセットを下回ります。
ApsaraMQ for Kafka とオープンソース Apache Kafka は、期限切れメッセージパーティションを異なる方法で処理します。
| 動作 | Apache Kafka | ApsaraMQ for Kafka |
|---|---|---|
| アラート計算 | コンシューマオフセット < 最小オフセットのパーティションを無視する | これらのパーティションをアラート合計に含める |
| コンソール表示 | N/A | グループの詳細これらのパーティションを の合計から除外する |
コンソールはこれらの異常なパーティションを除外しますが、アラートはそれらを含めるため、アラート値はコンソールに表示される値よりも大きくなります。次のスクリーンショットは、この動作を示しています。
コンソールとアラートで合計が異なる場合:
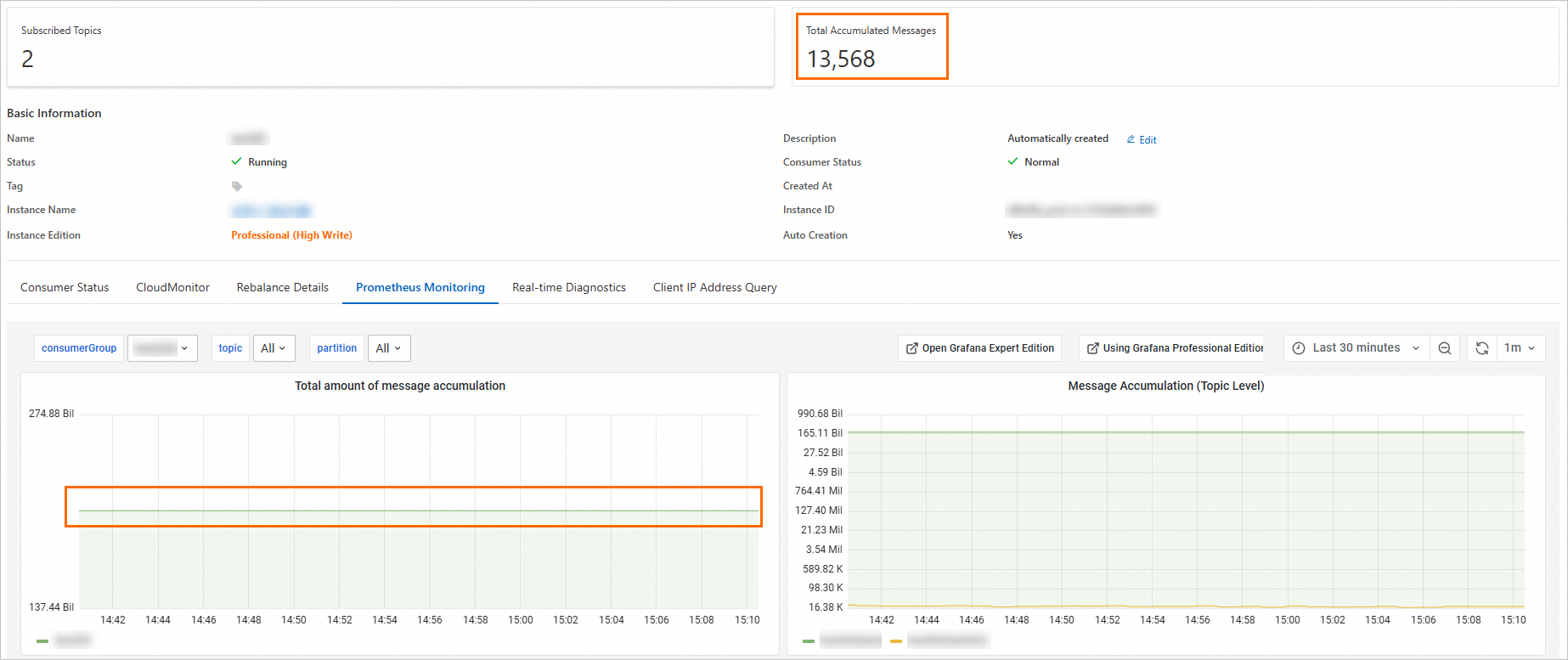
コンソール合計には異常トピックは含まれません。
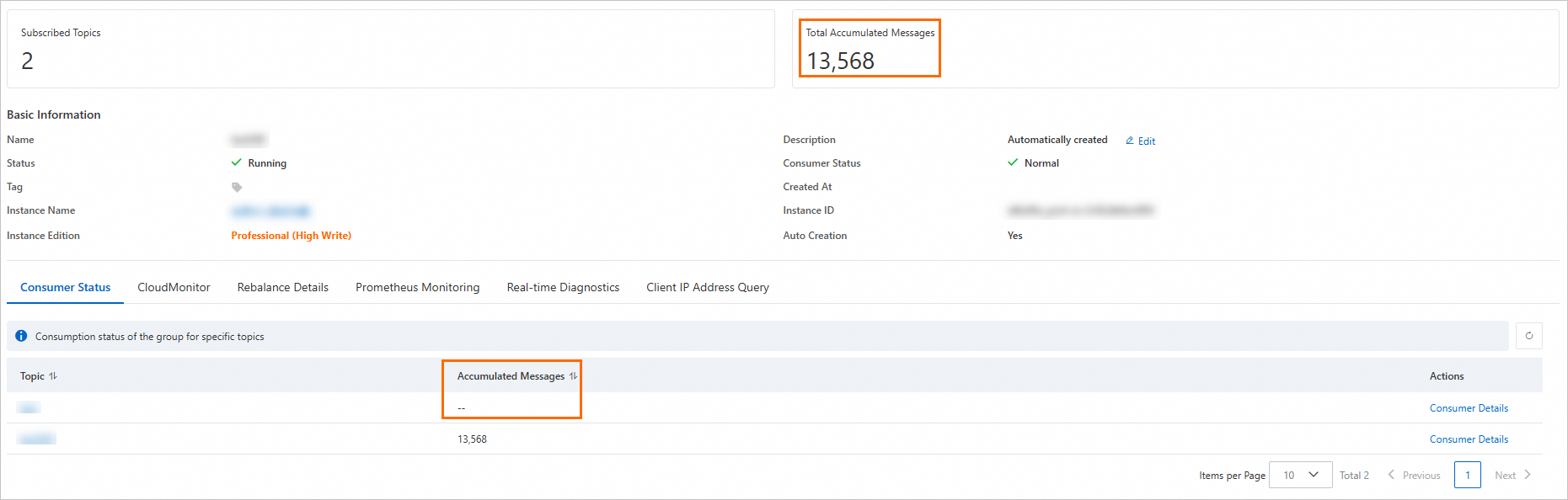
コンソールの合計には、コンシューマオフセットが最小オフセットを下回るパーティションが含まれない場合:
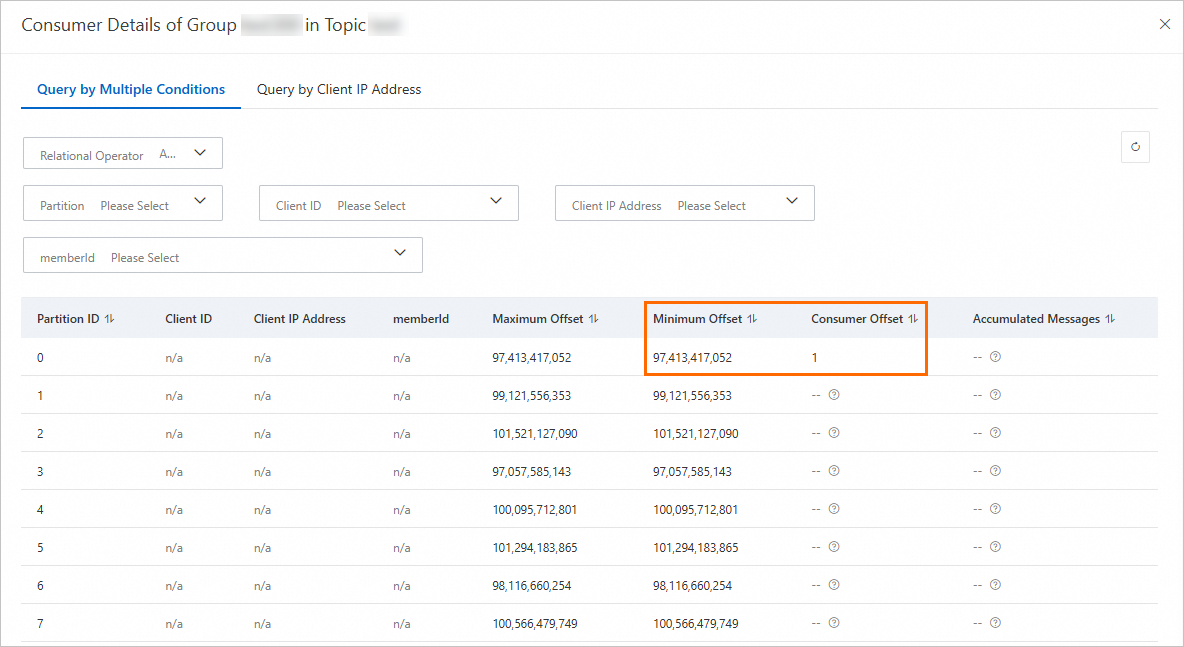
信頼すべき数値
ポイントインタイムの精度には、コンソールの [グループ詳細] ページを使用します。このページは、タイミングのずれを最小限に抑え、パーティションごとにオフセットをフェッチします。
多数のコンシューマーグループにわたるトレンドモニタリングについては、アラート値を使用してください。これは、精度ではなくスケーラビリティのために最適化されています。
両者の間にわずかな不一致があるのは正常です。不一致が継続的に大きいか、増加している場合にのみ調査してください。
不要な蓄積アラートの抑制
特定の Topic のアラートを無視する: ApsaraMQ for Kafka コンソールで、コンシューマーグループの コンシューマオフセットをリセット し、0 に設定します。アラートシステムは、これらの Topic の蓄積をレポートしなくなります。
蓄積アラートを完全に無効にする: チケットを提出して、メッセージ蓄積アラート機能を一時的にオフにします。
メトリックに関するよくある質問
どのメトリックをモニタリングすべきですか?
ご利用のインスタンスタイプに基づいて、次のメトリックに焦点を当ててください。
リザーブドインスタンス
| メトリック | 追跡対象 | 重要性 |
|---|---|---|
instance_disk_capacity(%) | インスタンス全体のディスク使用率 | ディスク使用率が高いと、メッセージ生成の失敗につながる可能性があります。ストレージ不足を避けるためにこれを監視してください。 |
ノード別インスタンスインターネット受信利用率 (%) | ノードごとのインバウンドインターネット帯域幅使用率 | 高い値が継続すると、ノードが帯域幅制限に近づいていることを示し、メッセージ遅延を引き起こす可能性があります。 |
InstanceInternetTxUtilizationByNode(%) | ノードごとのアウトバウンドインターネット帯域幅使用率 | 高い値が継続すると、ノードが帯域幅制限に近づいていることを示し、コンシューマースループットを低下させる可能性があります。 |
インスタンスタイプ別の本番トラフィックの割合 (%) | インスタンススペック制限に対するプロデューサースループットの割合 | 値が 100% に近づくと、生成スループットがインスタンス仕様の上限に近づいていることを意味します。 |
インスタンスタイプ別消費トラフィックの割合(%) | インスタンススペック制限に対するコンシューマースループットの割合 | 値が 100% に近づくと、消費スループットがインスタンス仕様の上限に近づいていることを意味します。 |
インスタンスタイプ内のパーティションの割合(%) | インスタンススペック制限に対するパーティション数の割合 | 値が 100% に近づくと、インスタンス仕様をアップグレードするか、パーティションを削減する必要があります。 |
サーバーレスインスタンス
| メトリック | 追跡対象 | 重要性 |
|---|---|---|
InstanceMessageInputRatioV3(%) | 容量に対するメッセージ入力レートの割合 | インスタンス全体のメッセージ生成が容量制限にどれだけ近いかを追跡します。 |
InstanceMessageOutputRatioV3(%) | 容量に対するメッセージ出力レートの割合 | インスタンス全体のメッセージ消費が容量制限にどれだけ近いかを追跡します。 |
InstanceMaxNodeInputRatioV3(%) | 最もビジーなノードでのピーク入力レート | ホットノードを特定します。ノード間の不均一な負荷分散を検出するためにこれを監視してください。 |
InstanceMaxNodeOutputRatioV3(%) | 最もビジーなノードでのピーク出力レート | ホットノードを特定します。ノード間の不均一な負荷分散を検出するためにこれを監視してください。 |
一部のメトリック値が不正確なのはなぜですか?
一般的な原因は 3 つあります。
トラフィック量が少ない。 システムは特定の数式に基づいて各メトリックを計算します。トラフィックが少ない場合、わずかな変動でも結果に不釣り合いに大きな偏差が生じます。
古いクライアントバージョン。 古い Kafka クライアントライブラリは、モニタリングシステムが依存するパラメーターを省略するため、レポートされる値が歪められます。これを修正するには、最新のクライアントバージョンにアップグレードしてください。
データ圧縮。 プロデューサーは、特定の転送またはストレージ要件を満たすためにデータを圧縮します。これにより、モニタリングデータに偏差が生じる可能性があります。
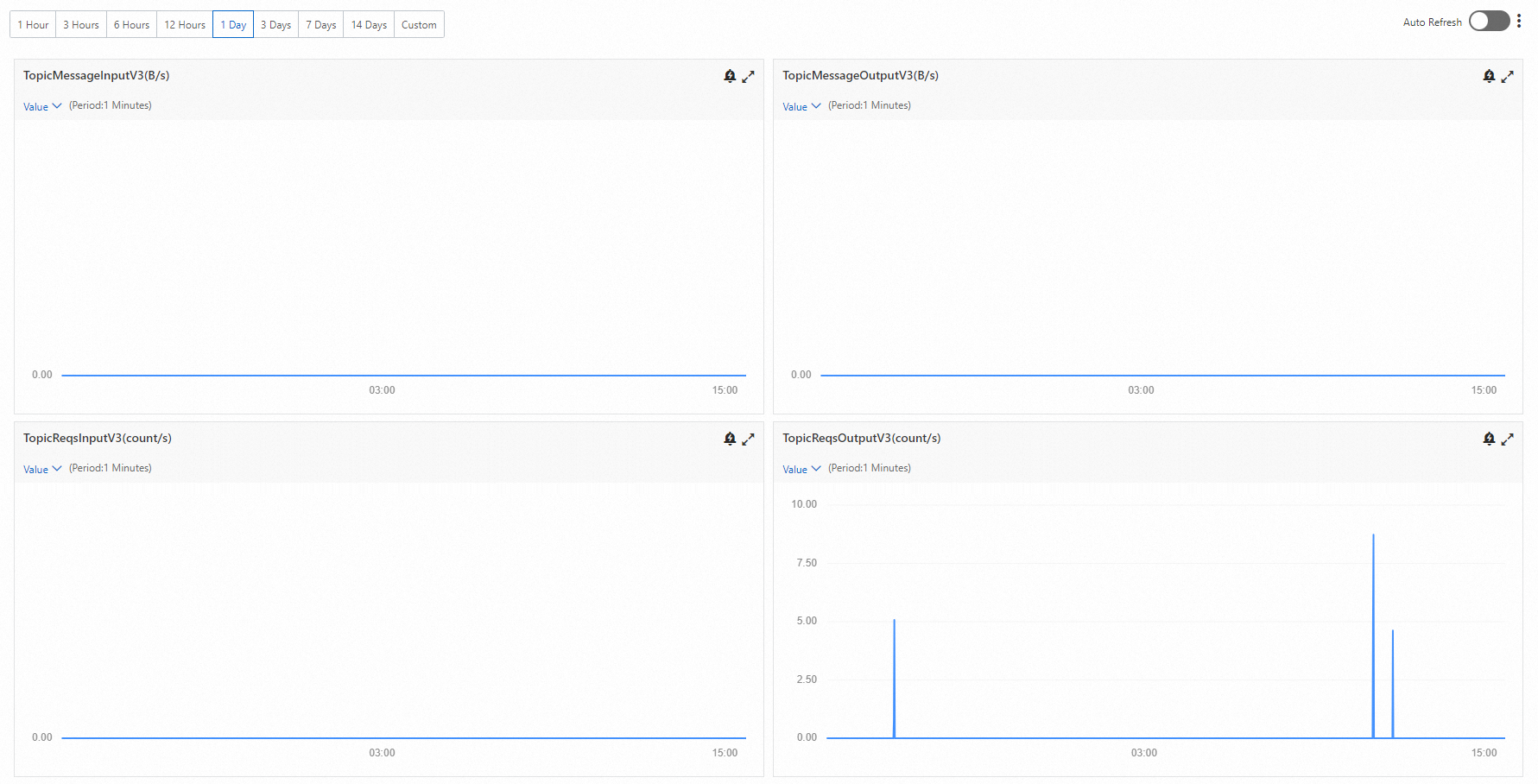
リクエスト出力がゼロより大きいのにメッセージ出力がゼロになるのはなぜですか?
これはエラーではなく、正常な動作です。コンシューマーがアクティブであるにもかかわらず、新しいメッセージがブローカーに公開されていない場合に発生します。
Kafka コンシューマーは、新しいメッセージが利用可能でない場合でも、ブローカーに対して継続的にポーリングを行います。各ポーリングは消費リクエストとして登録されるため、InstanceReqsOutput および TopicReqsOutput は、各試行ごとに増分されます。実際にはメッセージが配信されないため、InstanceMessageOutput および TopicMessageOutput はゼロのままです。
例: プロデューサーがメッセージを配信していない状態で、使用者グループがブローカーに対して 50 回ポーリングしたとします。TopicReqsOutput は 50 を示しますが、TopicMessageOutput は 0 を示します。プロデューサーが再び配信を開始すると、両方のメトリックが同時に増分し始めます。