このトピックでは、ApsaraMQ for Kafka インスタンスのソース・トピックから Function Compute の関数にデータを同期するために、Function Compute シンク・コネクタを作成する方法について説明します。
前提条件
以下の要件が満たされていること。
ApsaraMQ for Kafka
ApsaraMQ for Kafka インスタンスでコネクタ機能が有効になっていること。詳細については、コネクタ機能の有効化をご参照ください。
ApsaraMQ for Kafka インスタンスにトピックが作成されていること。詳細については、ステップ 1: トピックの作成をご参照ください。
この例では、トピックの名前は fc-test-input です。
Function Compute
Function Compute に関数が作成されていること。詳細については、関数のクイック作成をご参照ください。
重要作成する関数はイベント関数である必要があります。
この例では、Python ランタイム環境で実行される guide-hello_world サービス用に hello_world という名前のイベント関数が作成されています。関数コード:
# -*- coding: utf-8 -*- import logging # イニシャライザ機能を有効にするには # 以下のイニシャライザ関数を実装してください。 # def initializer(context): # logger = logging.getLogger() # logger.info('initializing') def handler(event, context): logger = logging.getLogger() logger.info('hello world:' + bytes.decode(event)) return 'hello world:' + bytes.decode(event)
オプション:EventBridge
EventBridge がアクティブ化されていること。 EventBridge のアクティブ化方法の詳細については、EventBridge のアクティブ化と RAM ユーザーへの権限の付与をご参照ください。
説明Function Compute シンク・コネクタが属するインスタンスが中国 (杭州) または中国 (成都) リージョンにある場合にのみ、EventBridge をアクティブ化する必要があります。
使用上の注意
ApsaraMQ for Kafka インスタンスのソース・トピックから Function Compute の関数にデータを同期できるのは、同じリージョン内のみです。コネクタの制限の詳細については、制限をご参照ください。
Function Compute シンク・コネクタが属するインスタンスが中国 (杭州) または中国 (成都) リージョンにある場合、コネクタは EventBridge にデプロイされます。
EventBridge は無料で使用できます。詳細については、課金をご参照ください。
コネクタを作成すると、EventBridge は以下のサービスリンクロールを自動的に作成します: AliyunServiceRoleForEventBridgeSourceKafka および AliyunServiceRoleForEventBridgeConnectVPC。
これらのサービスリンクロールが使用できない場合、EventBridge が ApsaraMQ for Kafka および Virtual Private Cloud (VPC) にアクセスするためにこれらのロールを使用できるように、EventBridge はそれらを自動的に作成します。
これらのサービスリンクロールが使用可能な場合、EventBridge はそれらを再度作成しません。
サービスリンクロールの詳細については、サービスリンクロールをご参照ください。
EventBridge にデプロイされたタスクの操作ログは表示できません。コネクタが実行された後、ソース・トピックをサブスクライブしているコンシューマー・グループの消費詳細を表示することで、同期タスクの進捗状況を確認できます。詳細については、コンシューマー詳細の表示をご参照ください。
手順
ApsaraMQ for Kafka インスタンスのソース・トピックから Function Compute の関数にデータを同期するために Function Compute シンク・コネクタを使用するには、以下の手順を実行します。
オプション: Function Compute シンク・コネクタがリージョンをまたいで Function Compute にアクセスできるようにします。
重要Function Compute シンク・コネクタを使用してリージョンをまたいで Function Compute にアクセスする必要がない場合は、この手順をスキップしてください。
オプション: Function Compute シンク・コネクタが Alibaba Cloud アカウントをまたいで Function Compute にアクセスできるようにします。
重要Function Compute シンク・コネクタを使用して Alibaba Cloud アカウントをまたいで Function Compute にアクセスする必要がない場合は、この手順をスキップしてください。
オプション: Function Compute シンク・コネクタに必要なトピックとコンシューマー・グループを作成します。
重要トピックとコンシューマー・グループの名前をカスタマイズする必要がない場合は、この手順をスキップしてください。
Function Compute シンク・コネクタに必要な特定のトピックは、ローカル・ストレージ・エンジンを使用する必要があります。ApsaraMQ for Kafka インスタンスのメジャーバージョンが V0.10.2 の場合、ローカル・ストレージ・エンジンを使用するトピックを手動で作成することはできません。この場合、これらのトピックは自動的に作成される必要があります。
結果を確認します。
Function Compute シンク・コネクタのインターネットアクセスを有効にする
Function Compute シンク・コネクタを使用してリージョンをまたいで他の Alibaba Cloud サービスにアクセスする必要がある場合は、Function Compute シンク・コネクタのインターネットアクセスを有効にします。詳細については、コネクタのインターネットアクセスを有効にするをご参照ください。
カスタムポリシーの作成
データを同期したい Alibaba Cloud アカウント内の Function Compute へのアクセスを許可するカスタムポリシーを作成します。
RAM コンソール にログインします。
左側のナビゲーションペインで、 を選択します。
[ポリシー] ページで、[ポリシーの作成] をクリックします。
[ポリシーの作成] ページで、カスタムポリシーを作成します。
[JSON] タブをクリックし、コードエディターにカスタムポリシーのスクリプトを入力して、[次のステップ] をクリックします。
サンプルスクリプト:
{ "Version": "1", "Statement": [ { "Action": [ "fc:InvokeFunction", "fc:GetFunction" ], "Resource": "*", "Effect": "Allow" } ] }[基本情報] セクションの KafkaConnectorFcAccess[名前] フィールドに と入力します。
[OK] をクリックします。
RAM ロールの作成
データを同期したい Alibaba Cloud アカウント内に RAM ロールを作成します。RAM ロールを作成する際に、信頼できるサービスとして ApsaraMQ for Kafka を選択することはできません。そのため、最初にサポートされているサービスを信頼できるサービスとして選択します。次に、作成した RAM ロールの信頼ポリシーを変更します。
左側のナビゲーションペインで、 を選択します。
[ロール] ページで、[ロールの作成] をクリックします。
[ロールの作成] パネルで、RAM ロールを作成します。
信頼できるエンティティの選択パラメーターを [alibaba Cloud サービス] に設定し、[次へ] をクリックします。
[ロールタイプ] パラメーターを [標準サービスロール] に設定します。[RAM ロール名] フィールドに AliyunKafkaConnectorRole と入力します。[信頼できるサービスの選択] ドロップダウンリストから、[function Compute] を選択します。次に、[OK] をクリックします。
[ロール] ページで、[aliyunkafkaconnectorrole] を見つけてクリックします。
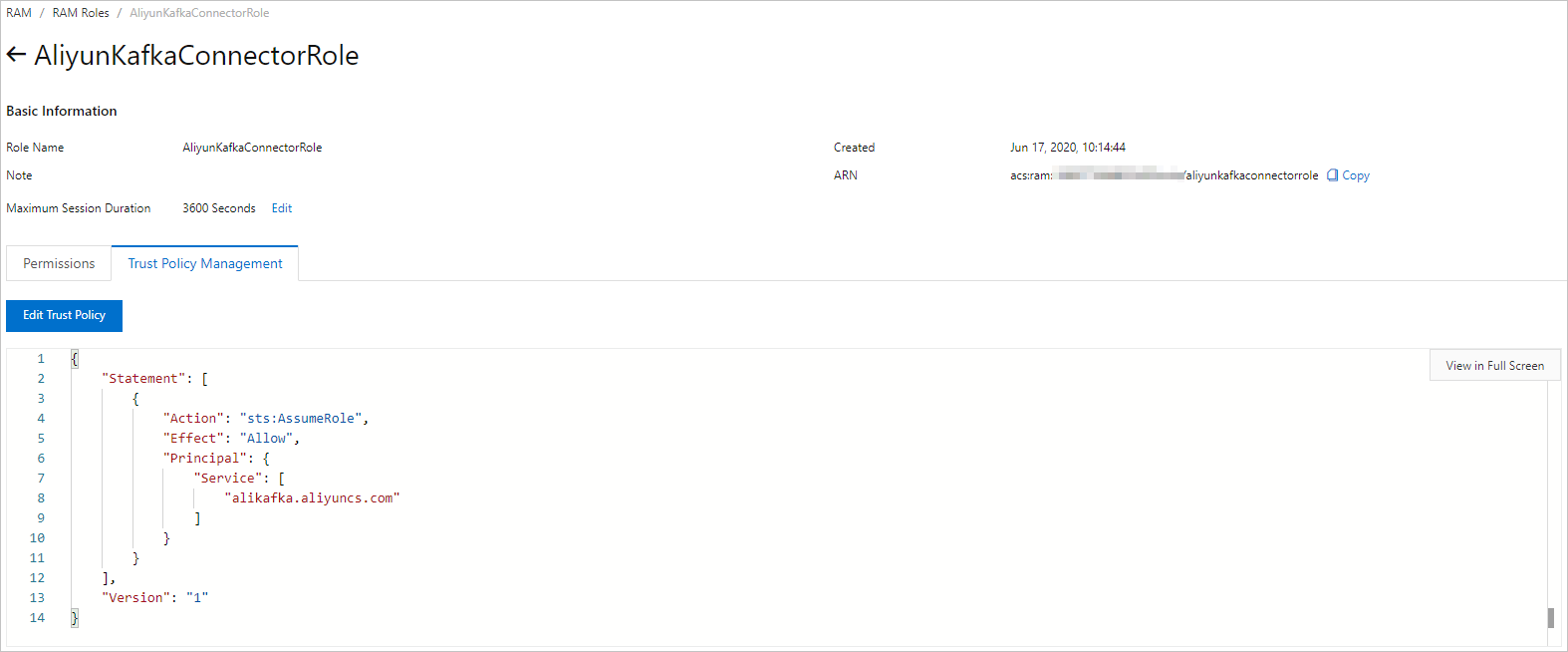
[aliyunkafkaconnectorrole] ページで、[信頼ポリシーの管理] タブをクリックします。このタブで、[信頼ポリシーの編集] をクリックします。
[信頼ポリシーの編集] パネルで、スクリプト内の [fc] を alikafka に置き換えて、[OK] をクリックします。
RAM ロールへの権限の付与
作成した RAM ロールに、データを同期したい Alibaba Cloud アカウント内の Function Compute にアクセスするための権限を付与します。
左側のナビゲーションペインで、 を選択します。
[ロール] ページで、[aliyunkafkaconnectorrole] を見つけ、権限の追加[アクション] 列の をクリックします。
[権限の追加] パネルで、[kafkaconnectorfcaccess] ポリシーを RAM ロールにアタッチします。
[ポリシーの選択] セクションで、[カスタムポリシー] をクリックします。
[承認ポリシー名] 列で、[kafkaconnectorfcaccess] を見つけてクリックします。
[OK] をクリックします。
[完了] をクリックします。
Function Compute シンク・コネクタに必要なトピックの作成
ApsaraMQ for Kafka コンソールで、Function Compute シンク・コネクタに必要な以下のトピックを作成します: タスクオフセットトピック、タスク設定トピック、タスクステータストピック、デッドレターキュー・トピック、およびエラデータ・トピック。これらのトピックは、パーティション数とストレージエンジンが異なります。詳細については、ソースサービスの設定ステップのパラメーターをご参照ください。
ApsaraMQ for Kafka コンソール にログインします。
リソースの分布 セクションの 概要 ページで、管理する ApsaraMQ for Kafka インスタンスが存在するリージョンを選択します。
重要トピックは、Elastic Compute Service (ECS) インスタンスがデプロイされているリージョンに作成する必要があります。トピックはリージョンをまたいで使用することはできません。たとえば、メッセージのプロデューサーとコンシューマーが中国 (北京) リージョンにデプロイされている ECS インスタンスで実行されている場合、トピックも中国 (北京) リージョンに作成する必要があります。
インスタンスリスト ページで、管理するインスタンスの名前をクリックします。
左側のナビゲーションペインで、トピック管理 をクリックします。
トピック管理 ページで、トピックの作成 をクリックします。
トピックの作成 パネルで、トピックのプロパティを指定し、[OK] をクリックします。
パラメーター
説明
例
名前
トピック名。
demo
記述
トピックの説明。
デモテスト
パーティションの数
トピック内のパーティションの数。
12
ストレージエンジン
説明Professional Edition インスタンスを使用している場合にのみ、ストレージエンジンのタイプを指定できます。Standard Edition インスタンスを使用している場合は、デフォルトでクラウドストレージが選択されます。
トピックにメッセージを格納するために使用されるストレージエンジンのタイプ。
ApsaraMQ for Kafka は以下のタイプのストレージエンジンをサポートしています:
クラウドストレージ: この値を選択すると、システムはトピックに Alibaba Cloud ディスクを使用し、分散モードで 3 つのレプリカにデータを格納します。このストレージエンジンは、低レイテンシ、高パフォーマンス、長期耐久性、高信頼性を備えています。インスタンスを作成したときに 仕様タイプ パラメーターを Standard Edition (High Write) に設定した場合、このパラメーターは クラウドストレージ にのみ設定できます。
ローカルストレージ: この値を選択すると、システムはオープンソースの Apache Kafka の同期レプリカ (ISR) アルゴリズムを使用し、分散モードで 3 つのレプリカにデータを格納します。
クラウドストレージ
メッセージタイプ
トピックのメッセージタイプ。有効な値:
通常のメッセージ: デフォルトでは、同じキーを持つメッセージは、メッセージが送信された順序で同じパーティションに格納されます。クラスター内のブローカーに障害が発生した場合、パーティションに格納されているメッセージの順序は保持されない場合があります。ストレージエンジン パラメーターを クラウドストレージ に設定すると、このパラメーターは自動的に 通常のメッセージ に設定されます。
パーティション順位メッセージ: デフォルトでは、同じキーを持つメッセージは、メッセージが送信された順序で同じパーティションに格納されます。クラスター内のブローカーに障害が発生した場合でも、メッセージは送信された順序でパーティションに格納されます。一部のパーティションのメッセージは、パーティションが復元されるまで送信できません。ストレージエンジン パラメーターを ローカルストレージ に設定すると、このパラメーターは自動的に パーティション順位メッセージ に設定されます。
通常のメッセージ
ログリリースポリシー
トピックで使用されるログクリーンアップポリシー。
ストレージエンジン パラメーターを ローカルストレージ に設定した場合、ログリリースポリシー パラメーターを設定する必要があります。ApsaraMQ for Kafka Professional Edition インスタンスを使用している場合にのみ、ストレージエンジンパラメーターをローカルストレージに設定できます。
ApsaraMQ for Kafka は以下のログクリーンアップポリシーを提供します:
Delete: デフォルトのログクリーンアップポリシー。システムに十分なストレージ容量がある場合、メッセージは最大保存期間に基づいて保存されます。ストレージ使用量が 85% を超えると、システムはサービスの可用性を確保するために最も古いメッセージを削除します。
Compact: Apache Kafka で使用されるログ圧縮ポリシー。ログ圧縮により、同じキーを持つメッセージの最新の値が保持されます。このポリシーは、障害が発生したシステムの復元や、システムの再起動後のキャッシュの再読み込みなどのシナリオに適しています。たとえば、Kafka Connect または Confluent Schema Registry を使用する場合、システムステータスと設定に関する情報をログ圧縮されたトピックに格納する必要があります。
重要ログ圧縮されたトピックは、Kafka Connect や Confluent Schema Registry などの特定のクラウドネイティブコンポーネントでのみ使用できます。詳細については、aliware-kafka-demos をご参照ください。
Compact
タグ
トピックにアタッチするタグ。
demo
トピックが作成された後、トピック管理 ページでトピックを表示できます。
Function Compute シンク・コネクタに必要なコンシューマー・グループの作成
ApsaraMQ for Kafka コンソールで、Function Compute シンク・コネクタに必要なコンシューマー・グループを作成します。コンシューマー・グループの名前は、connect-タスク名 形式である必要があります。詳細については、ソースサービスの設定ステップのパラメーターをご参照ください。
ApsaraMQ for Kafka コンソール にログインします。
リソースの分布 セクションの 概要 ページで、管理する ApsaraMQ for Kafka インスタンスが存在するリージョンを選択します。
インスタンスリスト ページで、管理するインスタンスの名前をクリックします。
左側のナビゲーションペインで、Group の管理 をクリックします。
Group の管理 ページで、グループの作成 をクリックします。
グループの作成 パネルで、Group ID フィールドにグループ名を入力し、記述 フィールドにグループの説明を入力し、グループにタグをアタッチして、[OK] をクリックします。
コンシューマー・グループが作成された後、Group の管理 ページでコンシューマー・グループを表示できます。
Function Compute シンク・コネクタの作成とデプロイ
ApsaraMQ for Kafka から Function Compute にデータを同期する Function Compute シンク・コネクタを作成してデプロイします。
ApsaraMQ for Kafka コンソール にログインします。
リソースの分布 セクションの 概要 ページで、管理する ApsaraMQ for Kafka インスタンスが存在するリージョンを選択します。
左側のナビゲーションペインで、Connector タスクリスト をクリックします。
Connector タスクリスト ページで、インスタンスの選択 ドロップダウンリストからコネクタが属するインスタンスを選択し、Connector の作成 をクリックします。
Connector の作成 ウィザードを完了します。
基本情報の設定 ステップで、以下の表に記載されているパラメーターを設定し、次へ をクリックします。
パラメーター
説明
例
名前
コネクタの名前。以下のルールに基づいてコネクタ名を指定します。
コネクタ名は 1 ~ 48 文字である必要があります。数字、小文字、ハイフン (-) を使用できますが、ハイフン (-) で始めることはできません。
各コネクタ名は、ApsaraMQ for Kafka インスタンス内で一意である必要があります。
コネクタのデータ同期タスクは、connect-タスク名 形式で名前が付けられたコンシューマー・グループを使用する必要があります。このようなコンシューマー・グループを作成していない場合、Message Queue for Apache Kafka は自動的にコンシューマー・グループを作成します。
kafka-fc-sink
インスタンス
Message Queue for Apache Kafka インスタンスに関する情報。デフォルトでは、インスタンスの名前と ID が表示されます。
demo alikafka_post-cn-st21p8vj****
ソースサービスの設定 ステップで、ソースサービスとして Message Queue for Apache Kafka を選択し、以下の表に記載されているパラメーターを設定して、次へ をクリックします。
説明トピックとコンシューマー・グループを事前に作成している場合は、リソース作成方法パラメーターを手動に設定し、以下のフィールドに作成したリソースの名前を入力します。そうでない場合は、リソース作成方法パラメーターを自動に設定します。
表 1. ソースサービスの設定ステップのパラメーター
パラメーター
説明
例
データソース Topic
データを同期するソース・トピックの名前。
fc-test-input
コンシューマースレッドの同時発生数
ソース・トピックからデータを同期するために使用されるコンシューマースレッドの同時実行数。デフォルトでは、6 つのコンシューマースレッドが使用されます。有効な値:
1
2
3
6
12
6
消費の開始位置
消費を開始するオフセット。有効な値:
一番古いオフセット: 最も古いオフセットから消費を開始します。
一番新しいオフセット: 最新のオフセットから消費を開始します。
一番古いオフセット
VPC ID
データ同期タスクが実行される VPC の ID。実行環境の設定 をクリックすると、パラメーターが表示されます。デフォルト値は、ApsaraMQ for Kafka インスタンスをデプロイしたときに指定した VPC ID です。値を変更する必要はありません。
vpc-bp1xpdnd3l***
VSwitch ID
データ同期タスクが実行される vSwitch の ID。実行環境の設定 をクリックすると、パラメーターが表示されます。vSwitch は、ApsaraMQ for Kafka インスタンスと同じ VPC にデプロイする必要があります。デフォルト値は、ApsaraMQ for Kafka インスタンスをデプロイしたときに指定した vSwitch ID です。
vsw-bp1d2jgg81***
失敗の処理
関連するメッセージの送信に失敗した後、エラーが発生したパーティションへのサブスクリプションを保持するかどうかを指定します。実行環境の設定 をクリックすると、パラメーターが表示されます。有効な値:
サブスクリプションの継続: エラーが発生したパーティションへのサブスクリプションを保持し、ログを返します。
サブスクリプションの停止: エラーが発生したパーティションへのサブスクリプションを停止し、ログを返します。
サブスクリプションの継続
リソースの作成方法
Function Compute シンク・コネクタに必要なトピックとコンシューマー・グループを作成するために使用される方法。実行環境の設定 をクリックすると、パラメーターが表示されます。有効な値:
自動作成
手動で作成します
自動作成
Connector コンシューマーグループ
コネクタのデータ同期タスクで使用されるコンシューマー・グループ。実行環境の設定 をクリックすると、パラメーターが表示されます。このコンシューマー・グループの名前は、connect-タスク名 形式である必要があります。
connect-kafka-fc-sink
タスクサイトの Topic
コンシューマーオフセットを格納するために使用されるトピック。実行環境の設定 をクリックすると、パラメーターが表示されます。
トピック: トピック名は connect-offset で始めることをお勧めします。
パーティション: トピック内のパーティションの数は 1 より大きい必要があります。
ストレージエンジン: トピックのストレージエンジンはローカルストレージに設定する必要があります。
cleanup.policy: トピックのログクリーンアップポリシーは Compact に設定する必要があります。
connect-offset-kafka-fc-sink
タスク設定の Topic
タスク設定を格納するために使用されるトピック。実行環境の設定 をクリックすると、パラメーターが表示されます。
トピック: トピック名は connect-config で始めることをお勧めします。
パーティション: トピックには 1 つのパーティションのみを含めることができます。
ストレージエンジン: トピックのストレージエンジンはローカルストレージに設定する必要があります。
cleanup.policy: トピックのログクリーンアップポリシーは Compact に設定する必要があります。
connect-config-kafka-fc-sink
タスクステータスの Topic
タスクステータスを格納するために使用されるトピック。実行環境の設定 をクリックすると、パラメーターが表示されます。
トピック: トピック名は connect-status で始めることをお勧めします。
パーティション: トピック内のパーティションの数を 6 に設定することをお勧めします。
ストレージエンジン: トピックのストレージエンジンはローカルストレージに設定する必要があります。
cleanup.policy: トピックのログクリーンアップポリシーは Compact に設定する必要があります。
connect-status-kafka-fc-sink
デッドレターキューの Topic
Kafka Connect フレームワークのエラデータを格納するために使用されるトピック。実行環境の設定 をクリックすると、パラメーターが表示されます。トピックリソースを節約するために、トピックを作成し、そのトピックをデッドレターキュー・トピックと エラデータ・トピック の両方として使用できます。
トピック: トピック名は connect-error で始めることをお勧めします。
パーティション: トピック内のパーティションの数を 6 に設定することをお勧めします。
ストレージエンジン: トピックのストレージエンジンは、ローカルストレージまたはクラウドストレージに設定できます。
connect-error-kafka-fc-sink
例外データ Topic
コネクタのエラデータを格納するために使用されるトピック。実行環境の設定 をクリックすると、パラメーターが表示されます。トピックリソースを節約するために、トピックを作成し、そのトピックを デッドレターキュー・トピック とエラデータ・トピックの両方として使用できます。
トピック: トピック名は connect-error で始めることをお勧めします。
パーティション: トピック内のパーティションの数を 6 に設定することをお勧めします。
ストレージエンジン: トピックのストレージエンジンは、ローカルストレージまたはクラウドストレージに設定できます。
connect-error-kafka-fc-sink
ターゲットサービスの設定 ステップで、宛先サービスとして Function Compute を選択し、以下の表に記載されているパラメーターを設定して、作成 をクリックします。
説明Function Compute シンク・コネクタが属するインスタンスが中国 (杭州) または中国 (成都) リージョンにある場合、宛先サービスとして Function Compute を選択すると、[サービス認証] メッセージが表示されます。[OK] をクリックすると、以下のサービスリンクロールが自動的に作成されます: AliyunServiceRoleForEventBridgeSourceKafka および AliyunServiceRoleForEventBridgeSourceKafka。[サービス認証] メッセージで [OK] をクリックし、以下の表に記載されているパラメーターを設定して、作成 をクリックします。サービスリンクロールがすでに作成されている場合は、[サービス認証] メッセージは表示されません。
パラメーター
説明
例
アカウントまたはリージョン間をクロスオーバーするかどうか
Function Compute シンク・コネクタが Alibaba Cloud アカウントまたはリージョンをまたいで Function Compute にデータを同期するかどうかを指定します。デフォルトでは、このパラメーターは いいえ に設定されています。有効な値:
いいえ: Function Compute シンク・コネクタは、同じリージョンおよび同じ Alibaba Cloud アカウント内の Function Compute にデータを同期します。
はい: Function Compute シンク・コネクタは、リージョンをまたいでいますが同じ Alibaba Cloud アカウント内、同じリージョン内ですが Alibaba Cloud アカウントをまたいで、またはリージョンと Alibaba Cloud アカウントをまたいで Function Compute にデータを同期します。
いいえ
サービスリージョン
Function Compute がアクティブ化されているリージョン。デフォルトでは、Function Compute シンク・コネクタが存在するリージョンが選択されています。リージョンをまたいでデータを同期するには、コネクタのインターネットアクセスを有効にし、宛先リージョンを選択します。詳細については、Function Compute シンク・コネクタのインターネットアクセスを有効にするをご参照ください。
重要サービスリージョン パラメーターは、アカウントまたはリージョン間をクロスオーバーするかどうか パラメーターを はい に設定した場合にのみ表示されます。
cn-hangzhou
サービスのアクセスポイント
Function Compute のエンドポイント。Function Compute コンソール の [概要] ページの [共通情報] セクションで、Function Compute のエンドポイントを表示できます。
内部エンドポイント: レイテンシを低くするために、内部エンドポイントを使用することをお勧めします。ApsaraMQ for Kafka インスタンスと Function Compute が同じリージョンにある場合、内部エンドポイントを使用できます。
パブリックエンドポイント: レイテンシが高いため、パブリックエンドポイントを使用しないことをお勧めします。ApsaraMQ for Kafka インスタンスと Function Compute が異なるリージョンにある場合は、パブリックエンドポイントを使用できます。パブリックエンドポイントを使用するには、コネクタのインターネットアクセスを有効にする必要があります。詳細については、「Function Compute シンクコネクタのインターネットアクセスを有効にする」をご参照ください。
重要サービスのアクセスポイント パラメーターは、アカウントまたはリージョン間をクロスオーバーするかどうか パラメーターを はい に設定した場合にのみ表示されます。
http://188***.cn-hangzhou.fc.aliyuncs.com
サービスアカウント
Function Computeへのログオンに使用するAlibaba CloudアカウントのIDです。Function Computeコンソールで、[概要] ページの [共通情報] セクションにAlibaba CloudアカウントのIDが表示されます。
重要サービスアカウント パラメーターは、アカウントまたはリージョン間をクロスオーバーするかどうか パラメーターを はい に設定した場合にのみ表示されます。
188***
権限が付与されたロール名
ApsaraMQ for Kafka が Function Compute にアクセスするために引き受ける RAM ロールの名前です。
Alibaba Cloud アカウント間でデータを同期する必要がない場合は、現在の Alibaba Cloud アカウント内に RAM ロールを作成し、その RAM ロールに特定の権限を付与する必要があります。次に、RAM ロールの名前を入力します。詳細については、「カスタムポリシーの作成」、「RAM ロールの作成」、および「RAM ロールへの権限の付与」をご参照ください。
Alibaba Cloud アカウント間でデータを同期する必要がある場合は、データを同期する先の Alibaba Cloud アカウントを使用して RAM ロールを作成する必要があります。次に、RAM ロールに特定の権限を付与し、RAM ロールの名前を入力します。詳細については、「カスタムポリシーの作成」、「RAM ロールの作成」、および「RAM ロールへの権限の付与」をご参照ください。
重要権限が付与されたロール名 パラメーターは、アカウントまたはリージョン間をクロスオーバーするかどうか パラメーターを はい に設定した場合にのみ表示されます。
AliyunKafkaConnectorRole
サービス名
Function Compute のサービス名です。
guide-hello_world
関数名
Function Compute のサービスにおける関数の名前です。
hello_world
バージョンまたはエイリアス
Function Compute のサービスのバージョンまたはエイリアスです。
重要アカウントまたはリージョン間をクロスオーバーするかどうか パラメーターを いいえ に設定した場合、このパラメーターを 指定されたバージョン または エイリアスの指定 に設定する必要があります。
アカウントまたはリージョン間をクロスオーバーするかどうか パラメーターを はい に設定する場合は、サービスバージョンまたはエイリアスを指定する必要があります。
LATEST
サービスバージョン
Function Compute のサービスのバージョンです。
重要サービスバージョン パラメーターは、アカウントまたはリージョン間をクロスオーバーするかどうか パラメーターを いいえ に設定し、バージョンまたはエイリアス パラメーターを 指定されたバージョン に設定した場合にのみ表示されます。
LATEST
サービスのエイリアス
Function Compute のサービスのエイリアスです。
重要サービスのエイリアス パラメーターは、アカウントまたはリージョン間をクロスオーバーするかどうか パラメーターを いいえ に設定し、バージョンまたはエイリアス パラメーターを エイリアスの指定 に設定した場合にのみ表示されます。
jy
送信モード
メッセージを送信するモード。有効な値:
非同期: 推奨。
同期: 非推奨。同期モードでは、Function Computeがメッセージを長時間処理する場合、ApsaraMQ for Kafka は Function Compute の処理が完了するまで待機します。メッセージのバッチが 5 分以内に処理されない場合、ApsaraMQ for Kafka クライアントはトラフィックをリバランスします。
非同期
ロットサイズを送信
一度に送信できるメッセージの最大数です。デフォルト値:20。コネクタは、リクエストで許可されるメッセージの最大数と最大メッセージサイズに基づいて、同時に送信されるメッセージを集約します。集約メッセージのサイズは、同期モードでは 6 MB、非同期モードでは 128 KB を超えることはできません。たとえば、メッセージは非同期モードで送信され、一度に最大 20 件のメッセージを送信できます。18 件のメッセージを送信する場合、そのうち 17 件のメッセージの合計サイズは 127 KB で、1 件のメッセージのサイズは 200 KB です。この場合、コネクタは 17 件のメッセージを 1 つのバッチに集約して最初に送信し、次にサイズが 128 KB を超える残りのメッセージを送信します。
説明メッセージを送信するときに キー パラメーターを null に設定すると、リクエストには キー パラメーターは含まれません。値 パラメーターを null に設定すると、リクエストには 値 パラメーターは含まれません。
バッチ内のメッセージのサイズがリクエストで許可される最大メッセージサイズを超えない場合、リクエストにはメッセージのすべてのコンテンツが含まれます。リクエスト例:
[ { "key":"this is the message's key2", "offset":8, "overflowFlag":false, "partition":4, "timestamp":1603785325438, "topic":"Test", "value":"this is the message's value2", "valueSize":28 }, { "key":"this is the message's key9", "offset":9, "overflowFlag":false, "partition":4, "timestamp":1603785325440, "topic":"Test", "value":"this is the message's value9", "valueSize":28 }, { "key":"this is the message's key12", "offset":10, "overflowFlag":false, "partition":4, "timestamp":1603785325442, "topic":"Test", "value":"this is the message's value12", "valueSize":29 }, { "key":"this is the message's key38", "offset":11, "overflowFlag":false, "partition":4, "timestamp":1603785325464, "topic":"Test", "value":"this is the message's value38", "valueSize":29 } ]単一メッセージのサイズがリクエストで許可される最大メッセージサイズを超える場合、リクエストにはメッセージのコンテンツは含まれません。リクエスト例:
[ { "key":"123", "offset":4, "overflowFlag":true, "partition":0, "timestamp":1603779578478, "topic":"Test", "value":"1", "valueSize":272687 } ]説明メッセージのコンテンツを取得するには、オフセットに基づいてメッセージをプルする必要があります。
50
再試行回数
メッセージの送信に失敗した場合に許可される最大再試行回数です。デフォルト値: 2 。有効な値: 1 ~ 3 。特定のケースでは、メッセージの送信に失敗した場合、再試行はサポートされません。次のルールは、エラーコードの種類と再試行がサポートされているかどうかを示しています。詳細については、「エラーコード」をご参照ください。
4XX: 429 が返される場合を除き、再試行はサポートされていません。
5XX: 再試行はサポートされています。
説明コネクタは InvokeFunction オペレーションを呼び出して、Function Compute にメッセージを送信します。
最大再試行回数後にメッセージが Function Compute への送信に失敗した場合、メッセージは配信不能キューのトピックに送信されます。配信不能キューのトピックにあるメッセージは、コネクタを使用して Function Compute に同期できません。トピックのリソースをリアルタイムで監視するために、トピックのアラートルールを設定することをお勧めします。これにより、できるだけ早く問題のトラブルシューティングを行うことができます。
2
コネクタが作成されると、Connector タスクリスト ページでコネクタを表示できます。
Connector タスクリスト ページに移動し、作成したコネクターを見つけ、デプロイ操作 列の をクリックします。
Function Compute リソースを設定するには、操作 列の を選択して Function Compute コンソールに移動し、構成を完了します。
テストメッセージを送信する
Function Compute シンクコネクタをデプロイした後、ApsaraMQ for Kafka インスタンスのソース トピックにメッセージを送信して、メッセージが Function Compute に同期されるかどうかをテストできます。
Connector タスクリスト ページで、管理するコネクタを見つけ、テスト操作 列の をクリックします。
メッセージの送信 パネルで、テスト メッセージを送信するためのパラメータを設定します。
送信方法 パラメータを コンソール に設定した場合は、次の手順を実行します。
メッセージキー フィールドに、メッセージ キーを入力します。例:demo。
メッセージの内容 フィールドに、メッセージの内容を入力します。例:{"key": "test"}。
指定されたパーティションに送信 パラメータを設定して、テスト メッセージを特定のパーティションに送信するかどうかを指定します。
テスト メッセージを特定のパーティションに送信する場合は、はい をクリックし、パーティション ID フィールドにパーティション ID を入力します。例:0。パーティション ID を照会する方法については、パーティションの状態を表示する を参照してください。
テスト メッセージを特定のパーティションに送信しない場合は、いいえ をクリックします。
送信方法 パラメータを [docker] に設定した場合は、Docker コンテナーを実行してサンプルメッセージを生成する セクションで Docker コマンドを実行して、テスト メッセージを送信します。
送信方法 パラメータを [SDK] に設定した場合は、必要なプログラミング言語またはフレームワークの SDK と、テスト メッセージを送受信するためのアクセス方法を選択します。
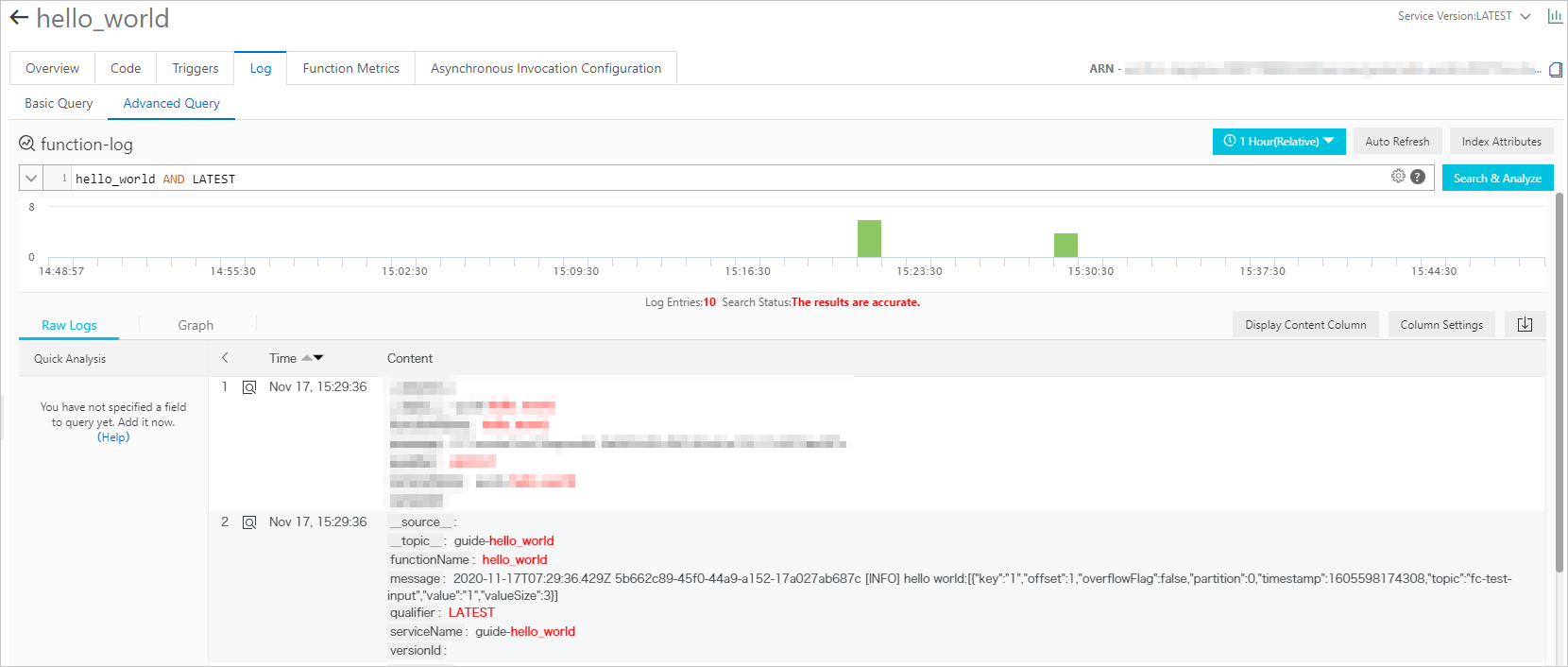
関数ログの表示
ApsaraMQ for Kafka インスタンスのソース トピックにメッセージを送信した後、関数ログを表示してメッセージが受信されたかどうかを確認できます。詳細については、「ロギングの設定」をご参照ください。
次の図に示すように、送信したテスト メッセージがログに表示されている場合、データ同期タスクは成功しています。