ビニングコンポーネントは、連続的な特徴量を離散的な区間(ビン)に変換する処理(特徴量の離散化)を行います。連続カラムの値が多すぎてモデル化が困難な場合、トレーニング用にカテゴリカルな範囲が必要な場合、または極端な値(外れ値)がモデルの学習に悪影響を及ぼしている場合に使用します。
ビニングを利用するタイミング
以下のシナリオでビニングが有効です:
カーディナリティの低減:年齢やトランザクション金額などの連続カラムが一意の値を多く持ちすぎている場合。これらの値を少数の離散的な範囲にグループ化することで、モデルがパターンをより効果的に学習できるようになります。
カテゴリカルな範囲の作成:数値をラベル付きの区間に置き換えます。たとえば、年齢を「1–15」「16–22」「23–30」のようにグループ化して、人口統計セグメントを表現します。
外れ値の影響の軽減:極端な値がモデルに過度に影響を与えることがあります。等頻度ビニングを適用することで、分位数ランクに基づきデータを均一な分布に変換できます。
ビニングモード
他のパラメーターを設定する前に、データの分布に最も適したモードを選択してください。ビニングモードによって適用可能なパラメーターが異なります。
| モード | 動作 |
|---|---|
| 等頻度 | 分位数ランクに基づき、各ビンにほぼ同数のサンプルが含まれるように値を分配します。データ分布にかかわらず均等なビンサイズを実現したい場合、または外れ値の影響を低減したい場合に使用します。 |
| 等幅 | 値の範囲を等しいサイズの区間に分割します。データが特定の値周辺に集中している場合、一部のビンには他のビンよりも大幅に多くのサンプルが含まれる可能性があります。 |
| 自動 | システムが各特徴量に対して最も適したビニングモードを自動的に選択します。検証テーブル(PAI コマンドにおける validTableName)を指定する必要があります。 |
ビニングコンポーネントの設定
方法 1:パイプラインキャンバス上で設定する
Machine Learning Designer のパイプラインキャンバス上で、ビニングコンポーネントを選択し、以下のパラメーターを設定します。
フィールド設定タブ
| パラメーター | 説明 |
|---|---|
| 特徴量カラム | ビニング対象のカラム。STRING、BIGINT、DOUBLE 型をサポートします。 |
| ラベルカラム | 二項分類の場合のみ必須です。 |
| 正の値 | ラベルカラム を指定した場合のみ有効です。 |
| ビニングパラメーターのソース | パラメーター設定タブの設定を使用:パラメーター設定タブで指定した設定を使用します。手動ビニングまたはカスタム JSON:ビニングおよび制約の定義を直接指定します。 |
| 未選択の特徴量カラムを保持 | 「[ビニング パラメータ ソース]」が「[手動ビニングまたはカスタム JSON]」に設定されている場合にのみ有効です。「[はい]」に設定すると、フィーチャー列にリストされていない列は出力で変更されません。「[いいえ]」に設定すると、それらの列は出力から削除されます。 |
| ビニングおよび制約の JSON コードをアップロード | ビニングパラメーターのソース を 手動ビニングまたはカスタム JSON に設定した場合のみ有効です。 |
パラメーター設定タブ
ビニングパラメーターのソース を パラメーター設定タブの設定を使用 に設定した場合のみ、これらのパラメーターが表示されます。
| パラメーター | 説明 |
|---|---|
| ビン数 | 作成する離散区間の数。デフォルト値:10。 |
| カスタムビン数 | 列ごとのビニング数のオーバーライド。形式:列名 1:ビニング数,列名 2:ビニング数。例:col0:3,col1:10,col2:5。[ビン数] より優先されます。ここにリストされているが Feature Columns には含まれていない列も、ビニング対象となります。 |
| カスタム離散値カウントしきい値 | カラムごとの「else ビン」への割り当てしきい値。フォーマット:col0:3。 |
| 区間タイプ | 左開区間・右閉区間(デフォルト)または 左閉区間・右開区間。 |
| ビニングモード | 等頻度、等幅、または自動ビニング。 |
| 離散値カウントしきい値 | このしきい値を下回るカウントを持つ離散値は、「else ビン」に割り当てられます。 |
チューニングタブ
| パラメーター | 説明 |
|---|---|
| コア数 | 使用するコア数。デフォルト値:システムが決定します。 |
| コアあたりのメモリサイズ | 各コアに割り当てるメモリ量。デフォルト値:システムが決定します。 |
方法 2:PAI コマンドを使用する
SQL スクリプトコンポーネント経由で PAI コマンドを実行し、ビニングコンポーネントを起動します。詳細については、「SQL スクリプト」をご参照ください。
PAI -name binning
-project algo_public
-DinputTableName=input
-DoutputTableName=output| パラメーター | 必須 | デフォルト | 説明 |
|---|---|---|---|
| inputTableName | はい | — | 入力テーブルの名前。 |
| outputTableName | はい | — | 出力テーブルの名前。 |
| selectedColNames | いいえ | ラベルカラムを除くすべてのカラム | ビニング対象のカラム。ラベルカラムが存在しない場合は、すべてのカラムが選択されます。 |
| labelColName | いいえ | なし | ラベルカラムの名前。 |
| validTableName | いいえ | Null | 検証テーブルの名前。binningMethod を auto に設定した場合に必須です。 |
| validTablePartitions | いいえ | 全テーブル | 検証テーブルから使用するパーティション。 |
| inputTablePartitions | いいえ | 完全な表 | 入力テーブルから使用するパーティション。 |
| inputBinTableName | いいえ | なし | 入力ビニングテーブルの名前。 |
| selectedBinColNames | いいえ | Null | 入力ビニングテーブルから使用するカラム。 |
| positiveLabel | いいえ | 1 | 正例を識別する値。 |
| nDivide | いいえ | 10 | ビン数。正の整数である必要があります。 |
| colsNDivide | いいえ | Null | カラムごとのビン数。フォーマット:カラム名 1:ビン数,カラム名 2:ビン数。例:col0:3,col2:5。ここに記載されても selectedColNames に含まれていないカラムも、ビニング対象となります。 |
| isLeftOpen | いいえ | true | 区間タイプ。true:左開区間・右閉区間。false:左閉区間・右開区間。 |
| stringThreshold | いいえ | なし | 「else ビン」への割り当てしきい値(離散値用)。 |
| colsStringThreshold | いいえ | Null | カラムごとの「else ビン」への割り当てしきい値。フォーマットは colsNDivide と同じです。 |
| binningMethod | いいえ | quantile | ビニングモード。quantile:等頻度。bucket:等幅。auto:自動。 |
| lifecycle | いいえ | なし | 出力テーブルのライフサイクル。正の整数である必要があります。 |
| coreNum | いいえ | システムが決定 | コア数。正の整数である必要があります。 |
| memSizePerCore | いいえ | システムが決定 | コアあたりのメモリ量。正の整数である必要があります。 |
colsNDivideに記載されてもselectedColNamesに含まれていないカラムも、ビニング対象となります。たとえば、selectedColNamesがcol0,col1、colsNDivideがcol0:3,col2:5、nDivideが10の場合、ビニングはcol0:3、col1:10、col2:5のように適用されます。
ビニング結果の確認と調整
ワークフローの実行が完了後、キャンバス上のビニングコンポーネントを右クリックし、ビニング を選択します。
変数一覧ページで、各変数の ビン数、タイプ、IV の値を確認します。

変数名(例:f1)をクリックしてビニング詳細ページを開きます。マージ または 分割 をクリックしてビン境界を調整し、個別のビンに対して制約を指定します。
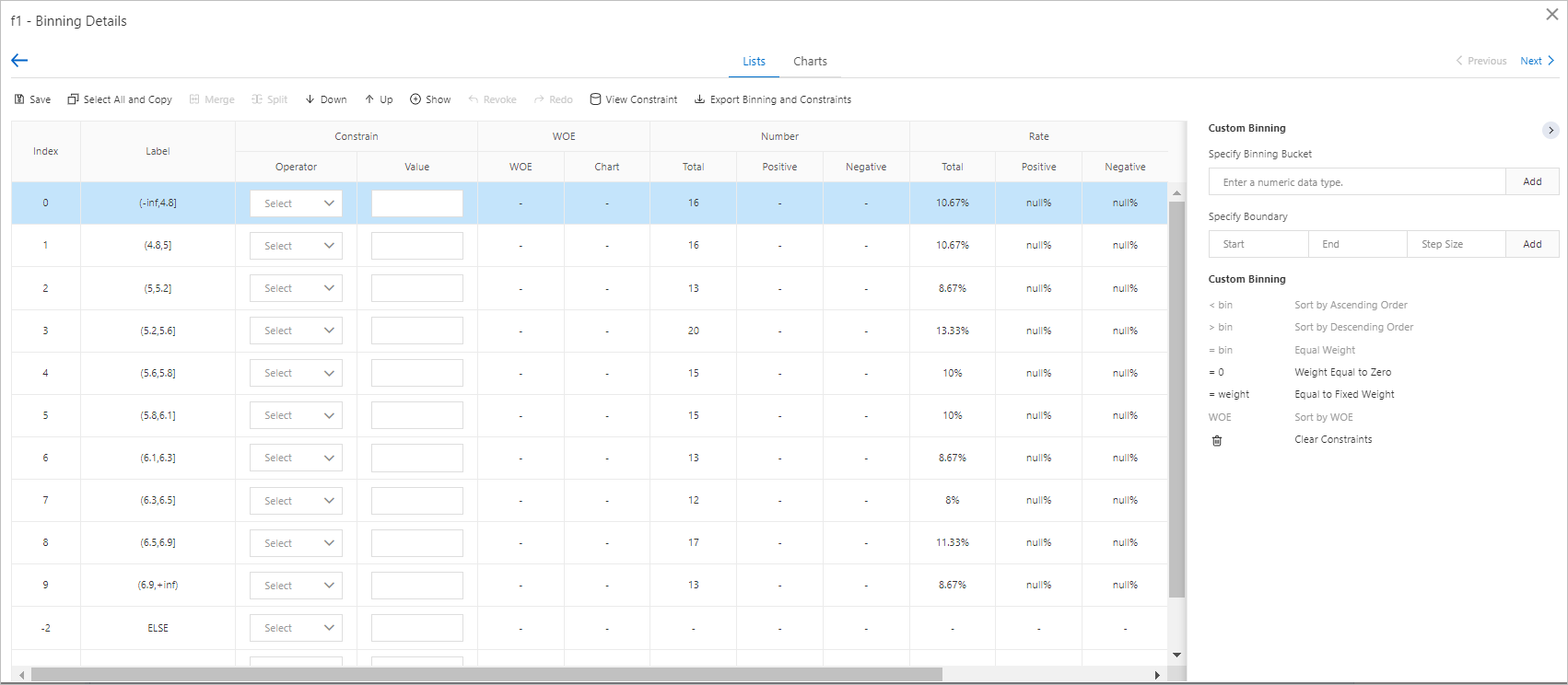
このページで指定した制約は、その後続のスコアカードトレーニングコンポーネントでのみ有効です。ビニングコンポーネントをスコアカードトレーニングコンポーネントと併用しない場合、制約は一切効果を発揮しません。
スコアカードトレーニングとの連携
スコアカードトレーニングコンポーネントと併用する場合、ビニングコンポーネントは連続的な特徴量を離散的なダミー変数に変換し、特徴量エンジニアリングを実施します。ダミー変数に対して重み制約を指定することで、スコアカードモデルが各ビンからどのように学習するかを制御できます。
利用可能な制約の種類は以下のとおりです:
| 制約 | 説明 |
|---|---|
| 昇順 | 重みがビンのインデックスとともに増加します。インデックスが大きいビンほど重みが高くなります。 |
| 降順 | 重みがビンのインデックスとともに減少します。インデックスが大きいビンほど重みが低くなります。 |
| 同一重み | 同一特徴量の 2 つのダミー変数は、必ず同一の重みを持たなければなりません。 |
| ゼロ重み | ダミー変数の重みを 0 に固定します。 |
| 特定の重み | ダミー変数の重みを特定の浮動小数点数値に設定します。 |
| WOE 順 | 重みがウェイト・オブ・エビデンス(WOE)値に従って昇順に並びます。WOE 値が高いビンほど重みが高くなります。 |