ゲノミクスコンピューティングは複雑でデータ集約型であり、科学者やライフサイエンスのデータアナリストにとって、爆発的に増加する量のデータを効率的かつ正確に集約および分析する上で課題となる可能性があります。 課題に取り組む効果的な方法は、ワークフローオーケストレーションを自動化することです。 Argoワークフローは、コンテナ化、柔軟性、使いやすさを特徴とする優れたワークフローエンジンです。 このトピックでは、Argoワークフローを使用してゲノミクスコンピューティングワークフローを調整する方法について説明します。
背景情報
Genomicsコンピューティングワークフロー
ゲノミクス計算ワークフローは、ゲノミクス研究のデータ分析に使用されます。 ゲノムコンピューティングワークフローは、特定の順序で実行される相互に関連するコンピューティングタスクとデータ処理ステップのコレクションで構成されます。 ゲノミクスコンピューティングワークフローには、データ処理、配列アライメント、変異検出、遺伝子発現分析、系統樹構築などの複雑なステップが含まれます。
Argo Workflows for genomics computingワークフローオーケストレーション
Argo Workflowsは、コンテナ化された環境でのワークフローの柔軟で効率的なオーケストレーションを容易にするオープンソースのKubernetesネイティブワークフローエンジンです。 Argoワークフローは、次の利点があるため、ゲノミクスコンピューティングに特に適しています。
コンテナ化と環境の一貫性: ゲノム分析では、さまざまなソフトウェアツールと依存関係ライブラリを使用する必要があります。 Argoワークフローは、すべての分析ステップをDockerコンテナーにカプセル化でき、プラットフォームと環境にデプロイできます。 これにより、クロスプラットフォームの一貫性とゲノム分析タスクの再利用性が保証されます。
柔軟なオーケストレーション: ほとんどのゲノミクスワークフローには、複数のステップ、条件付き分岐、および並列ジョブが含まれます。 Argoワークフローは複雑な実行ロジックと条件をサポートしているため、ワークフローを簡単かつ明示的にカスタマイズできます。
ただし、Argoワークフローには次の課題もあります。
大規模なO&M: ゲノミクスコンピューティングワークフローが多数のタスクで構成されている場合、特にユーザーのクラスターのメンテナンス経験が限られている場合、クラスターの最適化およびメンテナンスポリシーを効率的に実装できません。
複雑なワークフローオーケストレーション: 科学的実験には、大きなパラメータスペースと多数のステップが必要です。 科学実験は何万もの仕事を実行する必要があるかもしれません。 この場合、オープンソースのワークフローエンジンは、大規模な科学実験のためのワークフローを調整することができない。
コストの最適化とリソースの弾力性: ゲノム分析は大量の計算リソースを消費します。 ユーザーは、ワークロードのインテリジェントなリソーススケジューリングを有効にして、リソース使用率を最大化します。 さらに、ユーザーは、ワークロードのリソース需要に基づいてリソースのスケーリングを自動化したいと考えています。 オープンソースソリューションは、前述の要件を満たさない場合があります。
大規模なO&M、複雑なワークフローオーケストレーション、コスト最適化、およびリソースの柔軟性における上記の課題に対処するために、Distributed Cloud Container Platform for Kubernetes (ACK One) は、分散Argoワークフロー用のKubernetesクラスターを提供します。
分散Argoワークフロー用のKubernetesクラスター
分散Argoワークフロー用のKubernetesクラスター (ワークフロークラスター) は、サーバーレスアーキテクチャ上にデプロイされます。 このタイプのクラスターは、エラスティックコンテナインスタンスでArgoワークフローを実行し、クラスターパラメーターを最適化して、効率性、弾力性、費用対効果を備えた大規模なワークフローをスケジュールします。 ワークフロークラスターは、ワークフローを同時に実行したり、ワークフローをループしたり、ワークフローを再試行したりできます。 これらのワークフロー実行ポリシーは、ゲノミクスコンピューティングおよび複雑なワークフローオーケストレーションに適しています。

Argoワークフローは、コンテナ化、柔軟性、使いやすさに利点があるため、ゲノミクスコンピューティングやデータ集約型の科学タスクに適しています。 Argoワークフローは、ワークフローの自動化レベル、リソース使用率、およびデータ分析効率を大幅に向上させます。 Alibaba Cloud ACK Oneチームは、Argoワークフローを大規模なワークフローオーケストレーションに適用した最初のチームの1つです。 ACK Oneチームは、ゲノミクスコンピューティング、自動運転、財務シミュレーションなどのシナリオでのArgoワークフローのベストプラクティスについて豊富な経験を持っています。 DingTalkグループ (35688562) に参加して、ACK Oneチームに連絡することができます。
Argoワークフローを使用したゲノミクスコンピューティングワークフローの調整
このセクションでは、Argoワークフローを使用して、Burrows-Wheeler alignment algorithm (BWA) を使用してシーケンスアライメントワークフローを構成および実行する方法の例を示します。
Object Storage Service (OSS) ボリュームをワークフローにマウントします。 これにより、ワークフローは、ワークフローがローカルファイルにアクセスするのと同じ方法で、OSSボリューム内のファイルにアクセスできます。 詳しくは、『Use volumes』をご参照ください。
次のYAMLコンテンツに基づいてワークフローを作成します。 詳細については、「ワークフローの作成」をご参照ください。
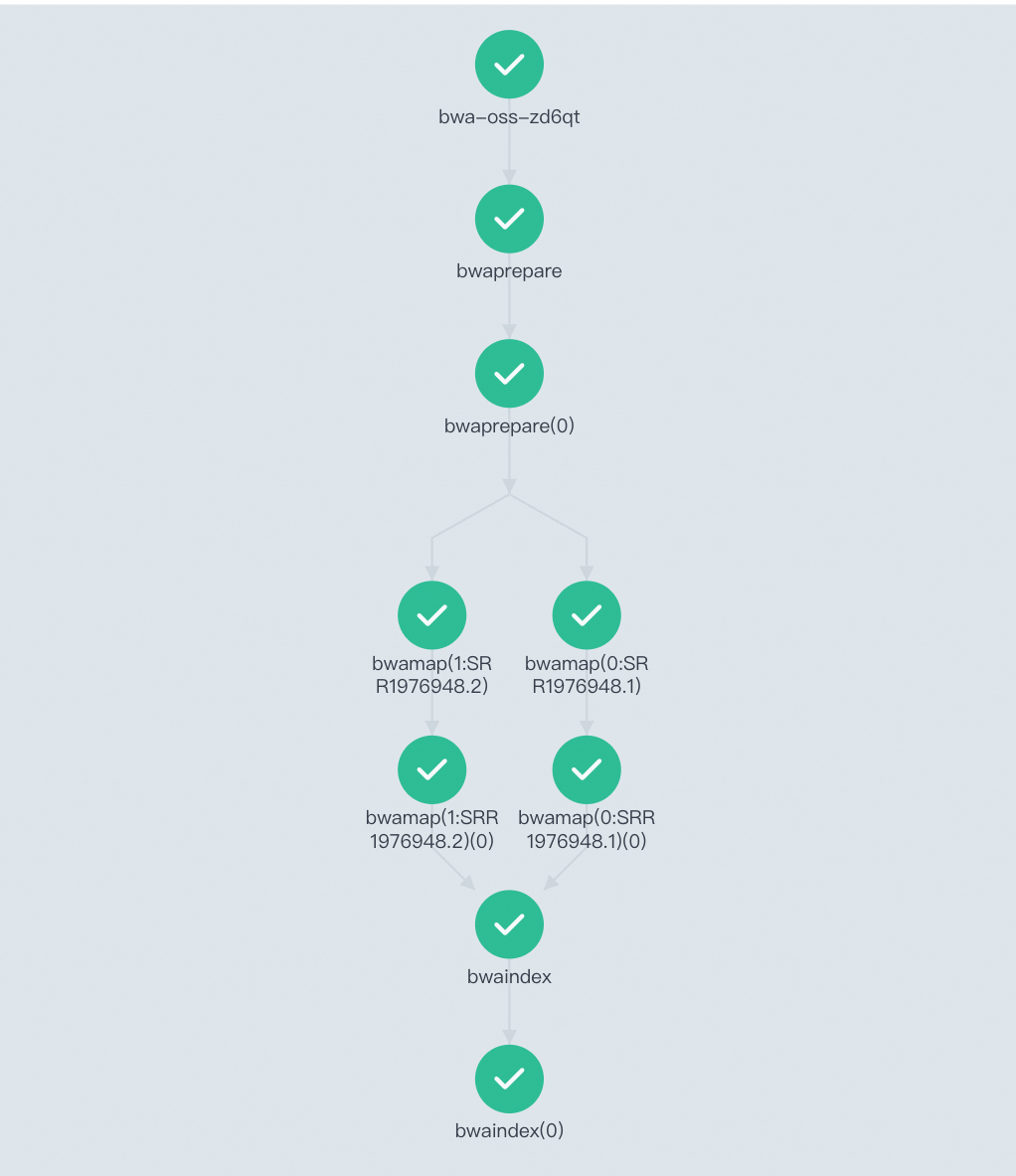
ワークフローは3つのステップで構成されます。
bwaprepare: データ準備ステップ。 このステップでは、FASTQファイルと参照ファイルをダウンロードして解凍し、参照ゲノムのインデックスを作成します。bwamap: 配列アラインメント工程。 このステップは、配列データを参照ゲノムに整列させる。 このステップは、複数のファイルを並列に処理する。bwaindex: 結果生成ステップ。 このステップでは、バイナリ整列およびマップ (BAM) ファイルを生成して整列を記録し、整列をソートし、BAMファイルのインデックスを作成します。 アライメントを表示することもできます。
ワークフローの実行が開始されたら、ワークフローコンソール (Argo) に移動して、有向非巡回グラフ (DAG) プロセスと結果を表示できます。
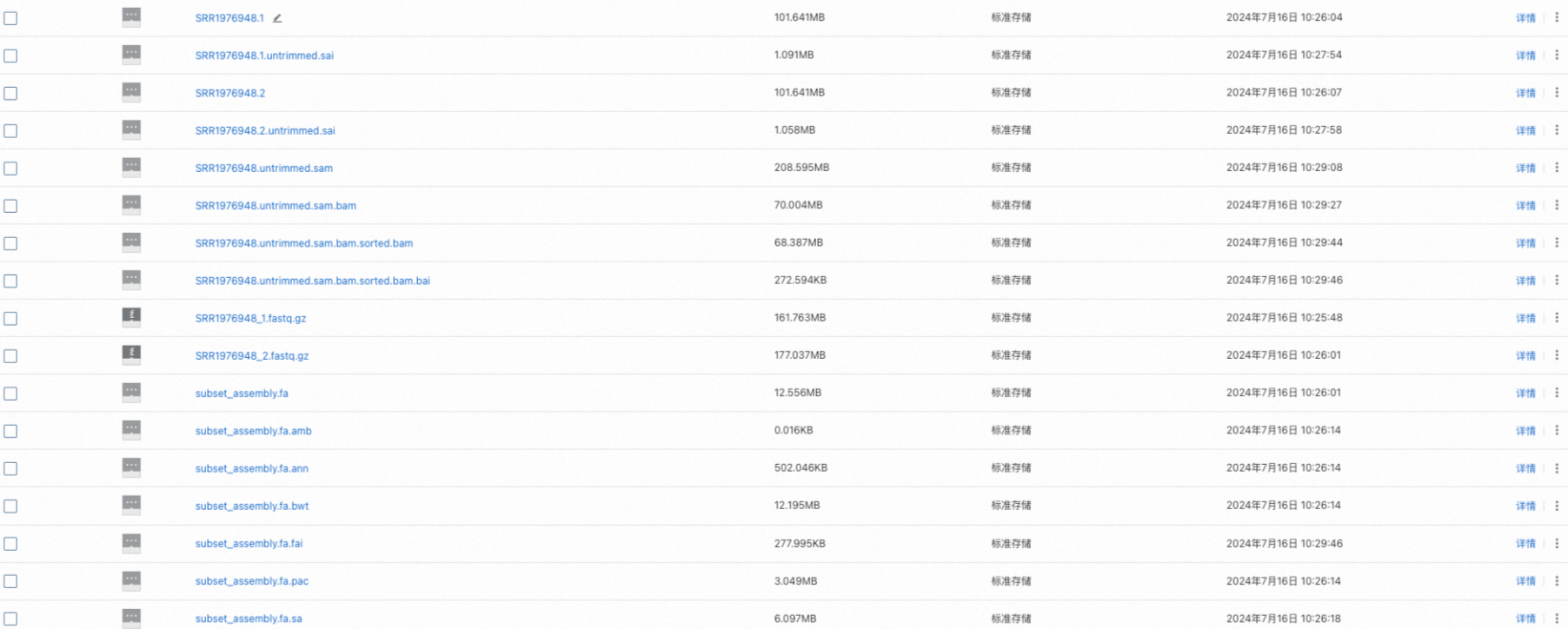
OSSコンソールにログインして、アライメントを格納するファイルが生成されているかどうかを確認することもできます。
関連ドキュメント
分散ArgoワークフローのKubernetesクラスターの詳細については、「分散ArgoワークフローのKubernetesクラスターの概要 (ワークフロークラスター) 」をご参照ください。
Argoワークフローの詳細については、「オープンソースのArgoワークフロー」をご参照ください。