Gateway with Inference Extension コンポーネントを使用すると、生成 AI 推論サービスにおいて、基盤モデルの置き換えやアップグレード、または複数の LoRA モデルの段階的アップデートを実行できます。このアプローチにより、サービスの中断を最小限に抑えることができます。このトピックでは、Gateway with Inference Extension コンポーネントを使用して、生成 AI 推論サービスの段階的リリースを実装する方法について説明します。
開始する前に、InferencePool と InferenceModel の概念を理解していることを確認してください。
前提条件
-
GPU ノードプールを備えた ACK マネージドクラスター があること。また、ACK マネージドクラスターに ACK Virtual Node コンポーネントをインストールして、ACS GPU 計算能力 を使用することもできます。
-
Gateway with Inference Extension コンポーネントをインストールし、Gateway API 推論拡張の有効化 オプションを選択済みであること。手順については、「コンポーネントのインストール」をご参照ください。
事前準備
推論サービスの段階的リリースをデモする前に、サンプル推論サービスをデプロイして検証します。
-
Qwen-2.5-7B-Instruct 基盤モデルに基づいて、サンプル推論サービスをデプロイします。
-
InferencePool および InferenceModel リソースをデプロイします。
kubectl apply -f- <<EOF apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferencePool metadata: name: mymodel-pool-v1 namespace: default spec: extensionRef: group: "" kind: Service name: mymodel-v1-ext-proc selector: app: custom-serving release: qwen targetPortNumber: 8000 --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceModel metadata: name: mymodel-v1 spec: criticality: Critical modelName: mymodel poolRef: group: inference.networking.x-k8s.io kind: InferencePool name: mymodel-pool-v1 targetModels: - name: mymodel weight: 100 EOF -
ゲートウェイとゲートウェイのルーティングルールをデプロイします。
-
ゲートウェイの IP アドレスを取得します。
export GATEWAY_IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}') -
推論サービスを検証します。
curl -X POST ${GATEWAY_IP}:8080/v1/chat/completions -H 'Content-Type: application/json' -d '{ "model": "mymodel", "temperature": 0, "messages": [ { "role": "user", "content": "Who are you?" } ] }'期待される出力:
{"id":"chatcmpl-6bd37f84-55e0-4278-8f16-7b7bf04c6513","object":"chat.completion","created":1744364930,"model":"mymodel","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"I am Qwen, a large language model created by Alibaba Cloud. I am designed to assist with a wide range of tasks, from answering questions and providing information to helping with creative projects and more. How can I assist you today?","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":32,"total_tokens":74,"completion_tokens":42,"prompt_tokens_details":null},"prompt_logprobs":null}期待される出力は、推論サービスが Gateway with Inference Extension を介して正常に機能していることを示します。
シナリオ 1:InferencePool の更新によるインフラストラクチャと基盤モデルの段階的リリース
実際のシナリオでは、InferencePool を更新して、モデルサービスの段階的リリースを実装できます。たとえば、同じ InferenceModel 定義とモデル名に基づいて 2 つの InferencePool を設定し、それぞれ異なる計算構成、GPU カードタイプ、または基盤モデルで実行できます。この方法は、次のシナリオに適用されます。
-
インフラストラクチャの段階的アップデート:新しい GPU カードタイプまたは新しいモデル構成を使用する新しい InferencePool を作成します。ワークロードを段階的に移行します。これにより、推論リクエストのトラフィックを中断することなく、ノードのハードウェアをアップグレードしたり、ドライバーを更新したり、セキュリティ問題を解決したりできます。
-
基盤モデルの段階的アップデート:新しい InferencePool を作成して、新しいモデルアーキテクチャまたはファインチューニングされたモデルの重みをロードします。新しい推論モデルを段階的にリリースして、推論サービスのパフォーマンスを向上させたり、基盤モデルに関連する問題を解決したりします。
以下に、グレースケール更新の主なフローについて説明します。
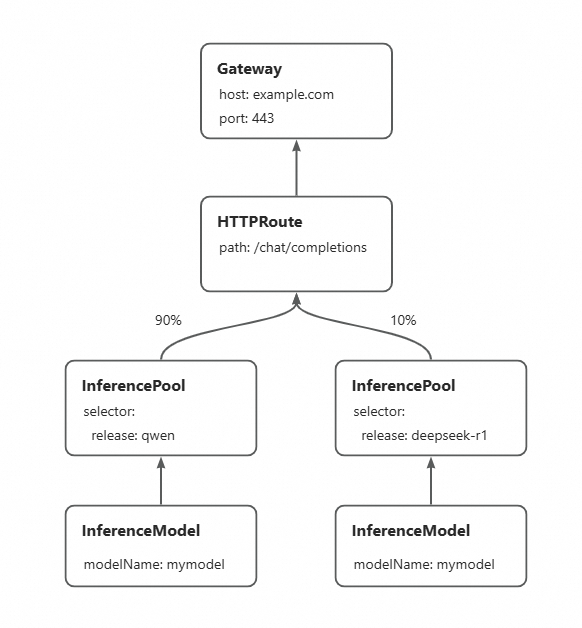
新しい基盤モデル用に新しい InferencePool を作成し、HTTPRoute を設定して異なる InferencePool 間でトラフィックを割り当てることができます。これにより、トラフィックを新しい基盤モデルの推論サービス (新しい InferencePool で表される) に徐々にシフトさせ、中断ゼロのアップデートを実現できます。次の例では、デプロイ済みの Qwen-2.5-7B-Instruct 基盤モデルサービスから DeepSeek-R1-Distill-Qwen-7B サービスへの段階的アップデートを実行する方法を示します。HTTPRoute のトラフィック比率を更新して、基盤モデルの完全な切り替えを実現できます。
-
DeepSeek-R1-Distill-Qwen-7B 基盤モデルに基づいて推論サービスをデプロイします。
-
新しい推論サービス用に InferencePool と InferenceModel を設定します。InferencePool
mymodel-pool-v2は、新しいラベルを使用して DeepSeek-R1-Distill-Qwen-7B 基盤モデルに基づく推論サービスを選択します。また、同じモデル名mymodelを持つ InferenceModel も宣言します。kubectl apply -f- <<EOF apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferencePool metadata: name: mymodel-pool-v2 namespace: default spec: extensionRef: group: "" kind: Service name: mymodel-v2-ext-proc selector: app: custom-serving release: deepseek-r1 targetPortNumber: 8000 --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceModel metadata: name: mymodel-v2 spec: criticality: Critical modelName: mymodel poolRef: group: inference.networking.x-k8s.io kind: InferencePool name: mymodel-pool-v2 targetModels: - name: mymodel weight: 100 EOF -
トラフィック分割ポリシーを設定します。
HTTPRoute を設定して、既存の InferencePool (
mymodel-pool-v1) と新しい InferencePool (mymodel-pool-v2) の間でトラフィックを分割できます。backendRefsの `weight` フィールドは、各 InferencePool に割り当てられるトラフィックの割合を制御します。たとえば、モデルのトラフィックの重みを 9:1 に設定します。これにより、トラフィックの 10% がmymodel-pool-v2に対応する DeepSeek-R1-Distill-Qwen-7B 基盤サービスに転送されます。kubectl apply -f- <<EOF apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: inference-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway sectionName: llm-gw rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: mymodel-pool-v1 port: 8000 weight: 90 - group: inference.networking.x-k8s.io kind: InferencePool name: mymodel-pool-v2 weight: 10 matches: - path: type: PathPrefix value: / EOF -
基盤モデルの段階的リリースを検証します。
次のコマンドを繰り返し実行し、モデルの出力を確認して、基盤モデルの段階的リリースを検証できます。
curl -X POST ${GATEWAY_IP}:8080/v1/chat/completions -H 'Content-Type: application/json' -d '{ "model": "mymodel", "temperature": 0, "messages": [ { "role": "user", "content": "Who are you?" } ] }'ほとんどのリクエストに対する期待される出力:
{"id":"chatcmpl-6e361a5e-b0cb-4b57-8994-a293c5a9a6ad","object":"chat.completion","created":1744601277,"model":"mymodel","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"I am Qwen, a large language model created by Alibaba Cloud. I am designed to assist with a wide range of tasks, from answering questions and providing information to helping with creative projects and more. How can I assist you today?","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":32,"total_tokens":74,"completion_tokens":42,"prompt_tokens_details":null},"prompt_logprobs":null}約 10% のリクエストに対する期待される出力:
{"id":"chatcmpl-9e3cda6e-b284-43a9-9625-2e8fcd1fe0c7","object":"chat.completion","created":1744601333,"model":"mymodel","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"Hello! I am DeepSeek-R1, an intelligent assistant developed by DeepSeek, a company based in China. If you have any questions, I will do my best to assist you.\n</think>\n\nHello! I am DeepSeek-R1, an intelligent assistant developed by DeepSeek, a company based in China. If you have any questions, I will do my best to assist you.","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":8,"total_tokens":81,"completion_tokens":73,"prompt_tokens_details":null},"prompt_logprobs":null}ほとんどの推論リクエストは、引き続き従来の Qwen-2.5-7B-Instruct 基盤モデルによって処理されますが、一部は新しい DeepSeek-R1-Distill-Qwen-7B 基盤モデルによって処理されます。
シナリオ 2:InferenceModel の設定による LoRA モデルの段階的リリース
Multi-LoRA シナリオでは、Gateway with Inference Extension を使用して、同じ基盤となる大規模言語モデル (LLM) 上に複数のバージョンの LoRA モデルをデプロイできます。トラフィックを柔軟に割り当てて段階的なテストを行い、各バージョンがパフォーマンスの最適化、バグ修正、または機能の反復に与える効果を検証できます。
この例では、Qwen-2.5-7B-Instruct からファインチューニングされた 2 つの LoRA バージョンを使用して、InferenceModel を用いた LoRA モデルの段階的リリースの実装方法を説明します。
LoRA モデルの段階的リリースを実装する前に、新しいモデルバージョンが推論サービスインスタンスに正常にデプロイされていることを確認してください。この例の基盤サービスには、すでに 2 つの LoRA モデル (travel-helper-v1とtravel-helper-v2) がマウントされています。
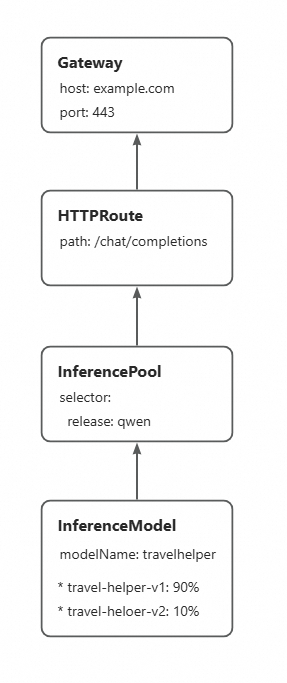
InferenceModel 内の異なる LoRA モデル間のトラフィック比率を更新することで、新しい LoRA モデルバージョンのトラフィックの重みを徐々に増やすことができます。これにより、トラフィックを中断することなく、新しい LoRA モデルへの段階的なアップデートが可能になります。
-
InferenceModel 設定をデプロイして、LoRA モデルの複数バージョンを定義し、それらの間のトラフィック比率を指定します。設定が完了すると、`travelhelper` モデルへのリクエストがあった場合に、トラフィックはバックエンドの LoRA モデルバージョン間で分割されます。たとえば、比率を 9:1 に設定します。これは、トラフィックの 90% が
travel-helper-v1モデルに送信され、10% がtravel-helper-v2モデルに送信されることを意味します。kubectl apply -f- <<EOF apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceModel metadata: name: loramodel spec: criticality: Critical modelName: travelhelper poolRef: group: inference.networking.x-k8s.io kind: InferencePool name: mymodel-pool-v1 targetModels: - name: travel-helper-v1 weight: 90 - name: travel-helper-v2 weight: 10 EOF -
段階的リリースを検証します。
次のコマンドを繰り返し実行し、モデルの出力を確認して、LoRA モデルの段階的リリースを検証できます。
curl -X POST ${GATEWAY_IP}:8080/v1/chat/completions -H 'Content-Type: application/json' -d '{ "model": "travelhelper", "temperature": 0, "messages": [ { "role": "user", "content": "I just arrived in Beijing. Can you recommend a tourist spot?" } ] }'ほとんどのリクエストに対する期待される出力:
{"id":"chatcmpl-2343f2ec-b03f-4882-a601-aca9e88d45ef","object":"chat.completion","created":1744602234,"model":"travel-helper-v1","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"Beijing is a city rich in history and culture, with many attractions worth visiting. Here are some recommended attractions:\n\n1. The Forbidden City: This is the largest ancient imperial palace in China and one of the largest ancient timber-frame architectural complexes in the world. You can learn about ancient Chinese imperial life and history here.\n\n2. The Great Wall: The section of the Great Wall near Beijing is among the most famous. You can admire magnificent mountain scenery and the grandeur of the Great Wall here.\n\n3. Tian'anmen Square: This is the largest city square in the world. You can see the Tian'anmen Rostrum and the Monument to the People's Heroes here.\n\n4. The Summer Palace: This is the largest royal garden in China. You can enjoy beautiful lakes and mountain views, along with exquisite architecture and sculptures.\n\n5. Beijing Zoo: If you love animals, this zoo houses many species, including giant pandas and golden snub-nosed monkeys.\n\n6. 798 Art Zone: This is an artistic district filled with galleries, art studios, and cafés, where you can view diverse artworks.\n\n7. 751 D-Park: This is a creative park integrating art, culture, and technology, where you can experience various exhibitions and events.\n\nHere are the Beijing attractions I recommend for you. I hope you enjoy them.","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":38,"total_tokens":288,"completion_tokens":250,"prompt_tokens_details":null},"prompt_logprobs":null}約 10% のリクエストに対する期待される出力:
{"id":"chatcmpl-c6df57e9-ff95-41d6-8b35-19978f40525f","object":"chat.completion","created":1744602223,"model":"travel-helper-v2","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"Beijing is a city rich in history and culture, with many attractions worth visiting.\n\nHere are some recommended attractions:\n\n1. The Forbidden City: This is China's largest ancient palace complex and one of the best-preserved ancient imperial palaces in the world. You can learn about ancient Chinese court life and history here.\n\n2. The Great Wall: The sections of the Great Wall in Beijing are among the most famous in the world. You can enjoy the magnificent mountain scenery and the grandeur of the Great Wall here.\n\n3. Tiananmen Square: This is the largest city square in the world. You can see the solemn Monument to the People's Heroes and the Tiananmen Gate Tower here.\n\n4. The Summer Palace: This is China's largest imperial garden. You can admire the exquisite garden architecture and beautiful lake views here.\n\n5. Beijing Zoo: If you like animals, this is a great choice. You can see a wide variety of animals, including giant pandas.\n\n6. 798 Art Zone: This is a place full of artistic atmosphere. You can see various art exhibitions and creative markets here.\n\nI hope these suggestions are helpful!","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":38,"total_tokens":244,"completion_tokens":206,"prompt_tokens_details":null},"prompt_logprobs":null}ほとんどの推論リクエストは
travel-helper-v1LoRA モデルによって処理され、一部はtravel-helper-v2LoRA モデルによって処理されます。