AHPA は Prometheus Adapter からの GPU 使用率データを使用し、過去の負荷トレンドと予測アルゴリズムを組み合わせて、将来の GPU リソース要件を予測します。GPU リソースが逼迫する前にスケールアウトし、リソースがアイドル状態のときにスケールインするように、Pod のレプリカ数を自動的に調整したり、GPU リソースを割り当てたりします。このアプローチにより、コストを削減し、クラスターの効率を向上させます。
前提条件
-
マネージド GPU クラスターが作成されていること。詳細については、「クラスターへの GPU ノードの追加」をご参照ください。
-
AHPA コンポーネントをインストールし、メトリックソースが設定されていること。詳細については、「弾力的スケーリング予測 (AHPA)」をご参照ください。
-
Prometheus モニタリングが有効になっており、Prometheus に少なくとも 7 日間の過去のアプリケーションデータ (GPU) が収集されていること。詳細については、「Alibaba Cloud Prometheus モニタリングへの接続と設定」をご参照ください。
仕組み
ハイパフォーマンスコンピューティング (HPC)、特にディープラーニングのモデルトレーニングや推論において、GPU リソースの詳細な管理と動的な調整は、使用率の向上とコスト削減につながります。Container Service for Kubernetes は、GPU メトリックに基づく弾力的スケーリングをサポートしています。Prometheus を使用して、リアルタイムの使用率や GPU メモリ使用量などの主要な GPU メトリックを収集できます。次に、Prometheus Adapter を使用してこれらのメトリックを Kubernetes 互換のフォーマットに変換し、AHPA と統合します。AHPA はこのデータと、過去の負荷トレンドおよび予測アルゴリズムを使用して、将来の GPU リソース要件を予測し、Pod のレプリカ数や GPU リソースの割り当てを自動的に調整します。これにより、リソースが逼迫する前にスケールアウトが行われ、リソースがアイドル状態になると迅速にスケールインが行われるため、コストを削減し、クラスターの効率を向上させることができます。
ステップ 1:Metrics Adapter のデプロイ
-
内部 HTTP API エンドポイントを取得します。
-
ARMS コンソールにログインします。
-
左側のナビゲーションウィンドウで、を選択します。
-
インスタンスページで、ご利用の ACK クラスターが配置されているリージョンを選択します。
-
対象の Prometheus インスタンスの名前をクリックします。左側のナビゲーションウィンドウで 設定 をクリックし、HTTP API アドレスの下にある内部エンドポイントを取得します。
-
-
ack-alibaba-cloud-metrics-adapter をデプロイします。
ACK コンソールにログインします。左側のナビゲーションウィンドウで、 をクリックします。
-
Marketplace ページで、アプリカタログ タブをクリックし、ack-alibaba-cloud-metrics-adapter を検索してクリックします。
-
ack-alibaba-cloud-metrics-adapter ページで、右上の ワンクリックデプロイメント をクリックします。
-
基本情報 ウィザードで、クラスター と 名前空間 を選択し、次 をクリックします。
-
パラメーター ウィザードで、Chart バージョン を選択します。パラメータ セクションで、ステップ 1 で取得した内部 HTTP API エンドポイントを
prometheus.urlの値として設定し、OK をクリックします。prometheus: enabled: true url: http://
ステップ 2:GPU メトリックに基づく AHPA の弾力的予測の実装
このトピックでは、GPU 上にモデル推論サービスをデプロイし、継続的にリクエストを送信します。AHPA は GPU 使用率に基づいて弾力的予測を実行します。
-
推論サービスをデプロイします。
-
次のコマンドを実行して、推論サービスをデプロイします。
-
次のコマンドを実行して、Pod のステータスを確認します。
kubectl get pods -o wide想定される出力:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES bert-intent-detection-7b486f6bf-f**** 1/1 Running 0 3m24s 10.15.1.17 cn-beijing.192.168.94.107 <none> <none> -
次のコマンドを実行して推論サービスを呼び出し、デプロイを検証します。
kubectl get svc bert-intent-detection-svcコマンドを使用して GPU ノードの IP アドレスを取得し、次のコマンドの47.95.XX.XXを置き換えます。curl -v "http://47.95.XX.XX/predict?query=Music"想定される出力:
* Trying 47.95.XX.XX... * TCP_NODELAY set * Connected to 47.95.XX.XX (47.95.XX.XX) port 80 (#0) > GET /predict?query=Music HTTP/1.1 > Host: 47.95.XX.XX > User-Agent: curl/7.64.1 > Accept: */* > * HTTP 1.0, assume close after body < HTTP/1.0 200 OK < Content-Type: text/html; charset=utf-8 < Content-Length: 9 < Server: Werkzeug/1.0.1 Python/3.6.9 < Date: Wed, 16 Feb 2022 03:52:11 GMT < * Closing connection 0 PlayMusic # インテント認識の結果。HTTP リクエストがステータスコード
200とインテント認識の結果を返した場合、推論サービスは正常にデプロイされています。
-
-
AHPA を設定します。
この例では、GPU 使用率を使用します。Pod の GPU 使用率が 20% を超えると、スケールアウトがトリガーされます。
-
AHPA メトリックソースを設定します。
-
次の内容で application-intelligence.yaml という名前のファイルを作成します。
prometheusUrlは Alibaba Cloud Prometheus のエンドポイントを設定します。ステップ 1 で取得した内部エンドポイントを使用します。apiVersion: v1 kind: ConfigMap metadata: name: application-intelligence namespace: kube-system data: prometheusUrl: "http://cn-shanghai-intranet.arms.aliyuncs.com:9090/api/v1/prometheus/da9d7dece901db4c9fc7f5b*******/1581204543170*****/c54417d182c6d430fb062ec364e****/cn-shanghai" -
次のコマンドを実行して application-intelligence をデプロイします。
kubectl apply -f application-intelligence.yaml
-
-
AHPA をデプロイします。
-
次の内容で fib-gpu.yaml という名前のファイルを作成します。
モードは
observerに設定されています。パラメーターの詳細については、「メトリックの説明」をご参照ください。 -
次のコマンドを実行して AHPA をデプロイします。
kubectl apply -f fib-gpu.yaml -
次のコマンドを実行して AHPA のステータスを確認します。
kubectl get ahpa想定される出力:
NAME STRATEGY REFERENCE METRIC TARGET(%) CURRENT(%) DESIREDPODS REPLICAS MINPODS MAXPODS AGE fib-gpu observer bert-intent-detection gpu 20 0 0 1 10 50 6d19h想定される出力では、
CURRENT(%)が0で、TARGET(%)が20であることが示されています。これは、現在の GPU 使用率が 0% であることを意味します。GPU 使用率が 20% を超えると、弾力的スケールアウトがトリガーされます。
-
-
-
推論サービスの弾力的スケーリングをテストします。
-
次のコマンドを実行して推論サービスにアクセスします。
-
サービスにアクセス中に、次のコマンドを実行して AHPA のステータスを確認します。
kubectl get ahpa想定される出力:
NAME STRATEGY REFERENCE METRIC TARGET(%) CURRENT(%) DESIREDPODS REPLICAS MINPODS MAXPODS AGE fib-gpu observer bert-intent-detection gpu 20 189 10 4 10 50 6d19h想定される出力では、現在の GPU 使用率
CURRENT(%)がTARGET(%)の値を超えていることが示されています。弾力的スケーリングがトリガーされ、望ましい Pod 数DESIREDPODSは10になります。 -
次のコマンドを実行して予測トレンドを表示します。
kubectl get --raw '/apis/metrics.alibabacloud.com/v1beta1/namespaces/default/predictionsobserver/fib-gpu'|jq -r '.content' |base64 -d > observer.html次の図は、7 日間の過去の GPU メトリックに基づく予測トレンドの例を示しています:
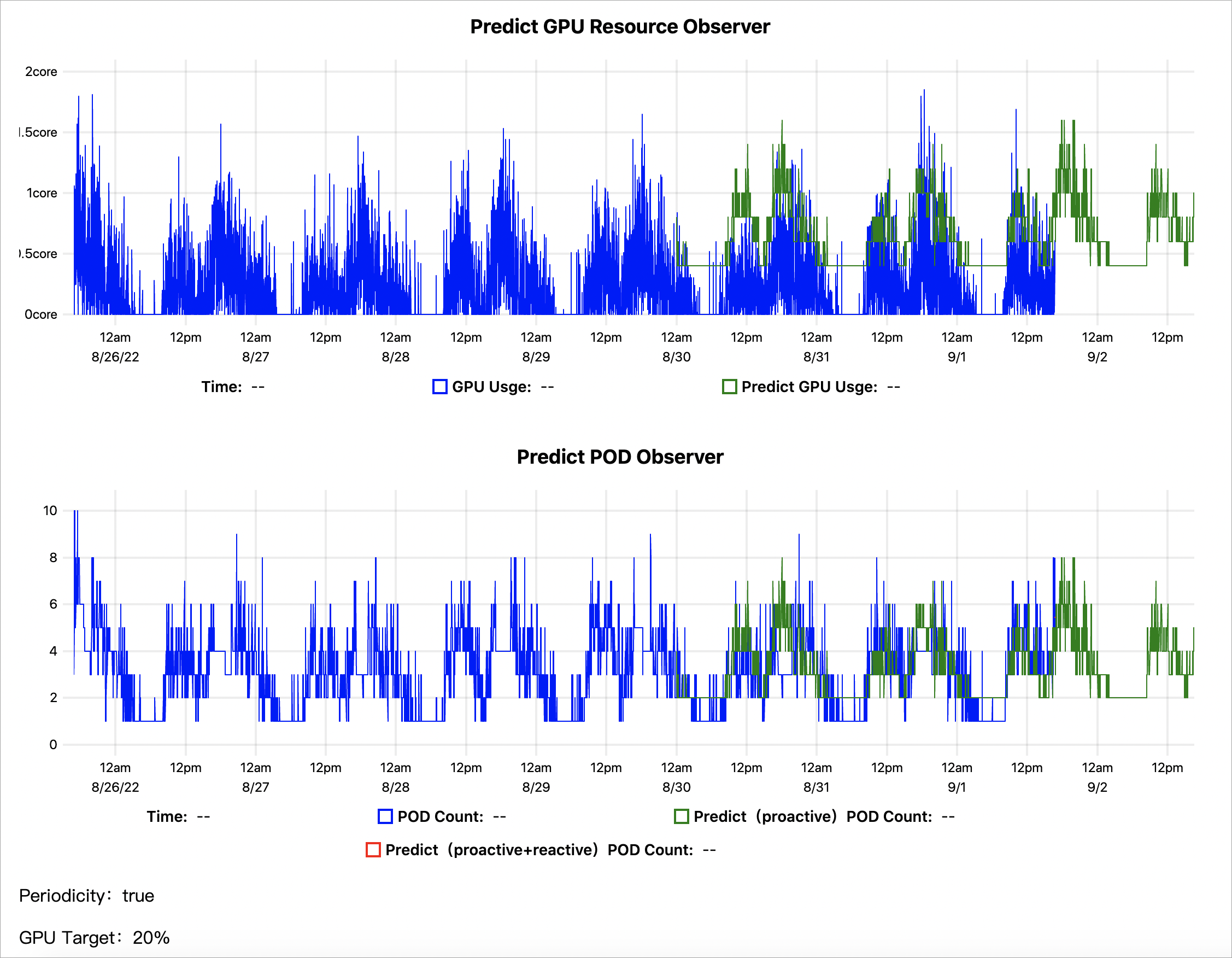
-
Predict GPU Resource Observer:青い線は実際の GPU 使用量を示します。緑の線は AHPA によって予測された GPU 使用量を示します。緑の曲線がほとんど青い曲線の上にあることは、予測された GPU 容量が十分であることを示しています。
-
Predict POD Observer:青い線は実際にスケールされた Pod の数を示します。緑の線は AHPA によって予測された Pod の数を示します。緑の曲線がほとんど青い曲線の下にあることは、AHPA がより少ない Pod 数を予測していることを示しています。弾力的スケーリングモードを
autoに設定して予測された Pod 数を使用することで、Pod リソースを節約し、無駄を避けることができます。
予測結果は期待どおりです。観測後、結果が引き続き良好であれば、弾力的スケーリングモードを
autoに設定して、AHPA にスケーリングを処理させます。 -
-
参考資料
-
Knative Serverless は AHPA (Advanced Horizontal Pod Autoscaler) の弾力的機能をサポートしています。アプリケーションのリソース要件が周期的である場合、弾力的予測はリソースを事前にウォームアップし、Knative のコールドスタート問題を解決します。詳細については、「Knative で AHPA の弾力的予測を使用する」をご参照ください。
-
多くのシナリオでは、アプリケーションは HTTP リクエストの QPS やメッセージキューの長さなどのカスタムメトリックに基づいてスケーリングする必要があります。AHPA は外部メトリックメカニズムを提供します。alibaba-cloud-metrics-adapter コンポーネントと組み合わせることで、より豊富なスケーリングオプションを提供します。詳細については、「AHPA でカスタムメトリックを設定してアプリケーションをスケーリングする」をご参照ください。