Container Service for Kubernetes は、Advanced Horizontal Pod Autoscaler (AHPA) をサポートしています。AHPA は履歴データを分析して将来のリソース需要を予測します。そして、Pod レプリカの数を動的に調整し、トラフィックのピークが発生する前にリソースをスケールアウトして事前にウォームアップします。これにより、システムの応答性と安定性が向上します。AHPA はまた、オフピーク期間中にリソースをスケールインしてコストを削減します。
前提条件
ACK マネージドクラスターまたはACK サーバーレスクラスターが必要です。詳細については、「ACK マネージドクラスターの作成」または「クラスターの作成」をご参照ください。
Managed Service for Prometheus が有効になっており、CPU やメモリ使用量などのアプリケーションの履歴データが少なくとも 7 日間収集されている必要があります。有効化する方法の詳細については、「Managed Service for Prometheus へのアクセスと設定」をご参照ください。
ステップ 1: AHPA コントローラーのインストール
ACK コンソールにログインします。左側のナビゲーションウィンドウで、クラスターリスト をクリックします。
クラスターリスト ページで、対象クラスターの名前をクリックします。左側のナビゲーションウィンドウで、[コンポーネントとアドオン] をクリックします。
アドオン管理 ページで、AHPA Controller コンポーネントを見つけます。コンポーネントカードの インストール をクリックし、画面の指示に従ってインストールを完了します。
ステップ 2: Prometheus データソースの設定
ARMS コンソールにログインします。
-
左側のナビゲーションウィンドウで、 を選択します。
インスタンス ページの上部で、Prometheus インスタンスのリージョンを選択し、インスタンス名 (ACK クラスター名と同じ) をクリックします。
設定 ページの HTTP API アドレス (Grafana 読み取りアドレス) セクションで、次のフィールドの値を記録します:
(オプション) トークンベースの認証が有効になっている場合は、アクセストークンを記録します。
インターネット エンドポイント (Prometheus URL) を表示して記録します。
ACK クラスターで Prometheus クエリ URL を設定します。
次の内容で
application-intelligence.yamlという名前のファイルを作成します。prometheusUrl:Managed Service for Prometheus のエンドポイント。token:Prometheus のアクセストークン。
apiVersion: v1 kind: ConfigMap metadata: name: application-intelligence namespace: kube-system data: prometheusUrl: "http://cn-hangzhou-intranet.arms.aliyuncs.com:9443/api/v1/prometheus/da9d7dece901db4c9fc7f5b9c40****/158120454317****/cc6df477a982145d986e3f79c985a****/cn-hangzhou" token: "eyJhxxxxx"説明Managed Service for Prometheus で AHPA ダッシュボードを表示するには、この ConfigMap で次のフィールドも設定する必要があります:
詳細については、「AHPA の Prometheus ダッシュボードの有効化」をご参照ください。
次のコマンドを実行して
application-intelligenceをデプロイします。kubectl apply -f application-intelligence.yaml
ステップ 3: テストサービスのデプロイ
このテストサービスには、Deployment fib-deployment、Service fib-svc、およびトラフィックの変動をシミュレートするための負荷ジェネレーター fib-loader が含まれています。また、AHPA との比較のためのベースラインを確立するために、HorizontalPodAutoscaler (HPA) リソースもデプロイします。
次の内容で demo.yaml という名前のファイルを作成します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: fib-deployment
namespace: default
annotations:
k8s.aliyun.com/eci-use-specs: "1-2Gi"
spec:
replicas: 1
selector:
matchLabels:
app: fib-deployment
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: fib-deployment
spec:
containers:
- image: registry.cn-huhehaote.aliyuncs.com/kubeway/knative-sample-fib-server:20200820-171837
imagePullPolicy: IfNotPresent
name: user-container
ports:
- containerPort: 8080
name: user-port
protocol: TCP
resources:
limits:
cpu: "1"
memory: 2000Mi
requests:
cpu: "1"
memory: 2000Mi
---
apiVersion: v1
kind: Service
metadata:
name: fib-svc
namespace: default
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
selector:
app: fib-deployment
sessionAffinity: None
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: fib-loader
namespace: default
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: fib-loader
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: fib-loader
spec:
containers:
- args:
- -c
- |
/ko-app/fib-loader --service-url="http://fib-svc.${NAMESPACE}?size=35&interval=0" --save-path=/tmp/fib-loader-chart.html
command:
- sh
env:
- name: NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
image: registry.cn-huhehaote.aliyuncs.com/kubeway/knative-sample-fib-loader:20201126-110434
imagePullPolicy: IfNotPresent
name: loader
ports:
- containerPort: 8090
name: chart
protocol: TCP
resources:
limits:
cpu: "8"
memory: 16000Mi
requests:
cpu: "2"
memory: 4000Mi
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: fib-hpa
namespace: default
spec:
maxReplicas: 50
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: fib-deployment
targetCPUUtilizationPercentage: 50
---ステップ 4: AHPA のデプロイ
スケーリングポリシーを設定するには、AdvancedHorizontalPodAutoscaler リソースを作成します。
次の内容で
ahpa-demo.yamlという名前のファイルを作成します。apiVersion: autoscaling.alibabacloud.com/v1beta1 kind: AdvancedHorizontalPodAutoscaler metadata: name: ahpa-demo spec: scaleStrategy: observer metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 40 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: fib-deployment maxReplicas: 100 minReplicas: 2 stabilizationWindowSeconds: 300 prediction: quantile: 95 scaleUpForward: 180 instanceBounds: - startTime: "2021-12-16 00:00:00" endTime: "2031-12-16 00:00:00" bounds: - cron: "* 0-8 ? * MON-FRI" maxReplicas: 15 minReplicas: 4 - cron: "* 9-15 ? * MON-FRI" maxReplicas: 15 minReplicas: 10 - cron: "* 16-23 ? * MON-FRI" maxReplicas: 20 minReplicas: 15次の表に、一部のパラメーターを示します。
パラメーター
必須
説明
scaleTargetRef
はい
ターゲットの Deployment を指定します。
metrics
はい
スケーリングのためのメトリックを設定します。サポートされているメトリックには、CPU、GPU、メモリ、QPS、RT があります。
target
はい
ターゲットのしきい値。たとえば、
averageUtilization: 40は、ターゲット CPU 使用率を 40% に設定します。scaleStrategy
いいえ
スケーリングモードを指定します。デフォルト値は
observerです。auto:AHPA がスケーリング操作を実行します。observer:AHPA は観測のみ行い、スケーリング操作は実行しません。このモードを使用して、AHPA が期待どおりに動作するかどうかを確認できます。proactive:プロアクティブな予測のみが有効になります。reactive:リアクティブなスケーリングのみが有効になります。
maxReplicas
はい
スケールアウトするレプリカの最大数。
minReplicas
はい
スケールインするレプリカの最小数。
stabilizationWindowSeconds
いいえ
スケーリング操作の安定化ウィンドウ。これにより、レプリカ数の急激な変動を防ぎます。デフォルト値は 300 秒です。
prediction.quantile
はい
予測の分位数。値が大きいほど、より保守的な予測になります。値は 0 から 100 の間でなければなりません。推奨範囲は 90 から 99 で、デフォルトは 99 です。
prediction.scaleUpForward
はい
新しい Pod が
Readyになるまでにかかる時間。これはコールドスタート時間とも呼ばれます。instanceBounds
いいえ
特定の期間内におけるレプリカ数の境界。
startTime:開始時刻。endTime:終了時刻。
instanceBounds.bounds.cron
いいえ
定期タスクを設定します。cron 式は、スペースで区切られた複数のフィールドを使用して、一連の時間を指定します。たとえば、
- cron: "* 0-8 ? * MON-FRI"は、タスクが月曜日から金曜日の 00:00 から 08:59 まで毎分実行されることを指定します。cron 式のフィールドは次のとおりです。詳細については、「Cron 定期タスク」をご参照ください。
フィールド
必須
有効値
特殊文字
分
はい
0–59
* / , -
時
はい
0–23
* / , -
日
はい
1–31
* / , - ?
月
はい
1–12 または JAN–DEC
* / , -
曜日
はい
0–6 または SUN–SAT
* / , - ?
説明月と曜日のフィールドでは、大文字と小文字は区別されません。たとえば、
SUN、Sun、sunは同じ効果を持ちます。曜日のフィールドが設定されていない場合、デフォルトで
*になります。特殊文字:
*:フィールド内のすべての有効な値に一致します。/:値の増分を指定します。,:列挙値をリストします。-:範囲を指定します。?:特定の値が設定されていないことを示します。日または曜日のいずれかを指定した場合に、もう一方のフィールドで使用します。
次のコマンドを実行して AHPA スケーリングポリシーを作成します。
kubectl apply -f ahpa-demo.yaml
ステップ 5: 予測結果の表示
AHPA の予測スケーリング結果を表示するには、「AHPA の Prometheus ダッシュボードの有効化」ができます。
予測には 7 日間の履歴データが必要なため、予測結果を確認するには、デプロイ後にサンプルアプリケーションを 7 日間実行する必要があります。既存の本番アプリケーションがある場合は、AHPA リソースで直接指定できます。
この例では、observer スケーリングモード (オブザーバーモード) を使用して、AHPA の予測結果を標準の HPA ポリシーの結果と比較します。HPA の結果は、アプリケーションの実際のリソース要件のベースラインとして機能します。この比較により、AHPA の予測が期待どおりであるかどうかを観測できます。
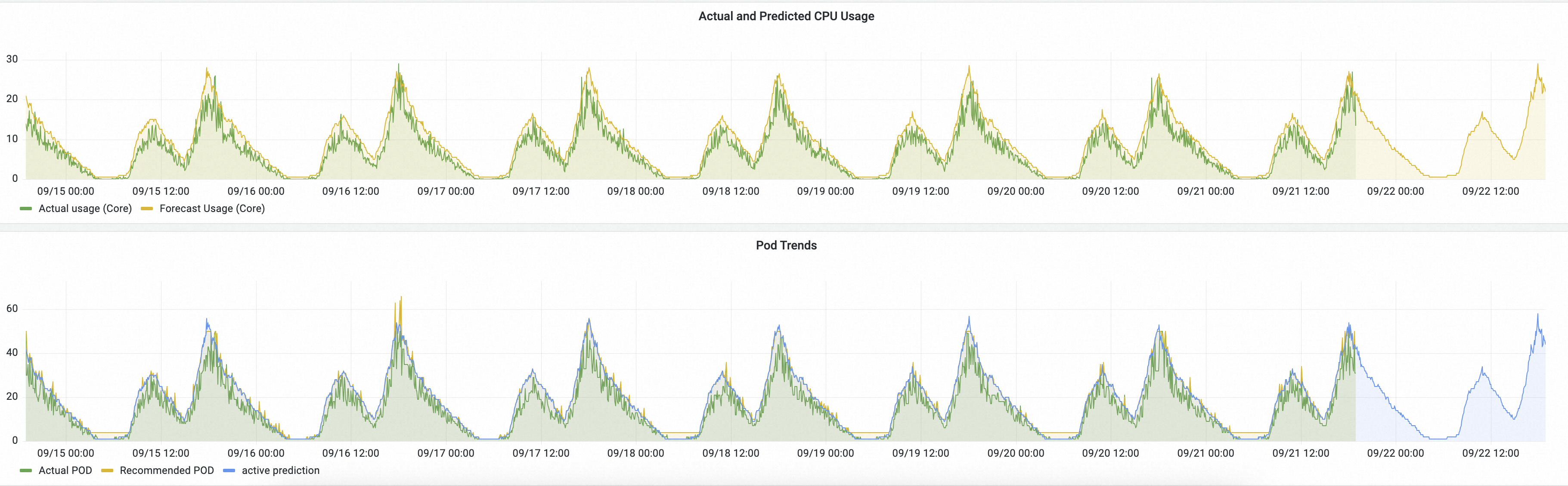
実際の CPU 使用率と予測された CPU 使用率:緑色の曲線は HPA によって管理される実際の CPU 使用率を表します。黄色の曲線は AHPA によって予測された CPU 使用率を表します。
黄色の曲線が緑色の曲線を上回っている場合、予測された CPU 容量が十分であることを示します。
黄色の曲線が緑色の曲線より先に上昇する場合、AHPA が必要なリソースを事前に準備していることを示します。
Pod の傾向:緑色の曲線は HPA によってスケーリングされた実際の Pod 数を表します。黄色の曲線は AHPA によって予測された Pod 数を表します。
黄色の曲線が低い場合、AHPA がより少ない Pod で同じ目標を達成していることを示している可能性があります。
黄色の曲線は緑色の曲線よりも滑らかであり、AHPA によって管理されるスケーリングイベントの変動が少ないことを示しています。これにより、サービスの安定性が向上します。
予測結果は、スケーリングの傾向が期待どおりであることを示しています。一定期間の観測の後、傾向が期待どおりであれば、スケーリングモードを auto に設定し、AHPA にスケーリングを管理させることができます。
関連ドキュメント
Managed Service for Prometheus の GPU メトリックを AHPA の予測スケーリングに使用する方法については、「GPU メトリックに基づく AHPA 予測スケーリングの設定」をご参照ください。
Managed Service for Prometheus が提供するモニタリングダッシュボードを表示する方法については、「AHPA の Prometheus ダッシュボードの有効化」をご参照ください。