LangStudio menyediakan node alur kerja siap pakai untuk pengendalian alur, model bahasa besar (LLM), agen, pengambilan data, penguraian dokumen, pengenalan ucapan, dan skrip Python.
Pengendalian alur
Start
Sebuah alur aplikasi hanya boleh memiliki satu node Start.
Node Start menandai titik awal eksekusi dan mendeklarasikan parameter input untuk alur aplikasi.
-
Untuk alur percakapan, sistem menyediakan dua bidang bawaan: riwayat percakapan dan input pengguna. Tambahkan variabel kustom sesuai kebutuhan. Untuk menerima file yang diunggah pengguna, definisikan variabel input dengan tipe file. Untuk detail selengkapnya, lihat Input dan output tipe file.

-
Saat menjalankan alur aplikasi, konfigurasikan parameter input untuk sesi saat ini di panel percakapan.

Cabang kondisional
Node ini menerapkan logika if-else untuk pengendalian alur. Node ini mengevaluasi kondisi dan mengarahkan eksekusi ke cabang pertama yang memenuhi syarat. Jika tidak ada kondisi yang bernilai true, cabang else akan dijalankan. Pasangkan node ini dengan node Variable aggregate untuk menggabungkan hasil dari berbagai cabang.
-
Konfigurasi

-
Input
Saat mengonfigurasi kondisi cabang, perhatikan hal berikut:
-
Setiap cabang mewakili jalur eksekusi. Cabang terakhir adalah cabang else, yang dijalankan ketika tidak ada kondisi lain yang cocok dan tidak dapat diedit.
-
Setiap cabang dapat berisi beberapa kondisi, yang dapat dikombinasikan menggunakan logika and/or.
-
Verifikasi output dari node upstream, operator (seperti
=,≠,is empty, dandoes not include), serta nilai-nilainya guna memastikan kondisi akurat dan valid.
-
-
Output
Node ini tidak menghasilkan output.
-
Contoh penggunaan
Saat menghubungkan node Cabang kondisional ke node downstream, setiap cabang memiliki port koneksi tersendiri. Jika kondisi cabang terpenuhi, sistem menjalankan node downstream pada cabang tersebut dan melewati cabang lainnya. Gunakan node Variable aggregate untuk mengumpulkan hasil eksekusi dari cabang aktif.

Variable aggregate
Node ini menggabungkan hasil output dari berbagai cabang menjadi variabel terpadu. Saat node Cabang kondisional atau node Pengenalan maksud dijalankan, hanya satu cabang yang dieksekusi. Node ini memungkinkan node downstream merujuk satu variabel agregat tunggal tanpa memedulikan cabang mana yang dijalankan, sehingga mencegah logika redundan.
-
Konfigurasi

-
Input
Saat mengonfigurasi grup variabel, perhatikan hal berikut:
-
Node upstream umumnya merupakan beberapa cabang eksekusi yang dihasilkan oleh node Cabang kondisional atau Pengenalan maksud.
-
Variabel dalam grup yang sama harus memiliki tipe yang sama. Nilai non-kosong pertama menjadi output untuk grup tersebut.
-
Karena hanya satu cabang upstream yang dijalankan, setiap grup akan memiliki paling banyak satu nilai non-kosong. Node Variable aggregate mengekstrak nilai ini untuk digunakan oleh node downstream.
-
Jika setiap cabang memiliki beberapa output yang perlu dikumpulkan, Anda dapat menambahkan beberapa grup untuk mengekstrak masing-masing nilai output yang bersesuaian.
-
-
Output
Output variabel node bergantung pada grup yang dikonfigurasi. Jika terdapat beberapa grup, node menghasilkan pasangan kunci-nilai untuk setiap grup, di mana kuncinya adalah nama grup dan nilainya adalah nilai variabel non-kosong pertama dari grup tersebut.
-
Contoh penggunaan
Lihat kasus penggunaan untuk node Cabang kondisional.
Loop
Node Loop menjalankan tugas berulang di mana setiap iterasi bergantung pada hasil sebelumnya. Loop berlanjut hingga kondisi keluar terpenuhi atau jumlah maksimum iterasi tercapai. Di dalam node Loop, konfigurasikan sub-alur yang dijalankan berulang kali oleh sistem berdasarkan variabel loop.
-
Konfigurasi

-
Input
-
Variabel loop: Meneruskan data antar-iterasi. Nilai akhirnya tetap tersedia untuk node downstream setelah loop selesai. Konfigurasikan beberapa variabel loop yang nilainya dapat dimasukkan secara manual atau dipilih dari output node upstream.
-
Kondisi keluar loop: Anda dapat mengonfigurasi kondisi keluar berdasarkan variabel loop. Loop berhenti ketika variabel loop tertentu memenuhi kondisi yang telah ditetapkan.
-
Jumlah maksimum iterasi: Membatasi jumlah maksimum eksekusi loop untuk mencegah loop tak terbatas.
-
-
Output
Output node adalah nilai variabel loop setelah iterasi terakhir. Variabel loop hanya dapat diperbarui oleh node Variable Assigner. Tanpa node ini, output loop akan tetap identik dengan input awalnya, terlepas dari jumlah iterasi.
-
Node terkait
Node terkait loop hanya dapat digunakan di dalam sebuah loop. Tambahkan node terkait berikut dengan mengklik ikon + di sebelah kanan node di dalam loop:
-
Break Loop
Menghentikan loop secara langsung. Biasanya didahului oleh node Cabang kondisional.
-
Variable Assigner
Menetapkan output node di dalam loop ke variabel loop, sehingga memajukan status loop.

-
Direct output
Node Direct output mengonfigurasi konten balasan langsung dengan menggunakan templat output. Node ini mendukung referensi output node upstream menggunakan sintaks {{node.variable}} dan keluaran streaming.
Contoh: Tambahkan node Direct output sebelum node LLM untuk mengirim pesan awal ke pengguna, seperti "Sedang memikirkan...", sementara tugas utama sedang diproses.


Pemrosesan batch
Node Pemrosesan batch memproses data berupa daftar secara paralel. Node ini menerapkan sub-alur yang sama ke setiap elemen daftar, yang secara signifikan meningkatkan efisiensi. Untuk tugas iteratif di mana setiap langkah bergantung pada langkah sebelumnya, gunakan node Loop sebagai gantinya.
Input
-
Daftar input: Daftar data yang akan diproses. Node mengirimkan setiap elemen ke sub-alur untuk dieksekusi sebagai item independen.
-
Bidang output: Pilih variabel output dari node di dalam sub-alur untuk menjadi hasil tugas tiap item.
-
Jumlah paralel: Opsional. Mengontrol jumlah tugas yang dijalankan secara bersamaan. Nilai bawaan adalah 4, dengan rentang valid 1 hingga 10.
Output
result: Daftar berisi hasil output dari semua tugas batch, dalam urutan yang sama dengan daftar input. Node ini mengagregasi nilai output aktual dari "Bidang output" yang ditentukan dalam input.
Node terkait
Batch Start
Node Batch Start adalah titik masuk untuk sub-alur pemrosesan batch. Node ini menyediakan variabel output berikut untuk dirujuk oleh node berikutnya di dalam sub-alur:
-
item: Item data yang sedang diproses, yang sesuai dengan elemen dalam daftar input.
-
index: Indeks item data saat ini dalam daftar input (dimulai dari 0).
Batch Break
Node Batch Break digunakan untuk menghentikan proses item data saat ini secara prematur ketika kondisi tertentu terpenuhi.
Catatan: Node Batch Break hanya menghentikan iterasi saat ini dan tidak memengaruhi proses item data lainnya.
Contoh penggunaan
Penguraian dokumen batch dan pemrosesan cerdas
Skenario: Sebuah perusahaan perlu menguraikan beberapa file dokumen secara batch, memanggil LLM untuk memproses konten pada dokumen yang berhasil diuraikan, serta melewati dokumen yang gagal diuraikan secara otomatis.
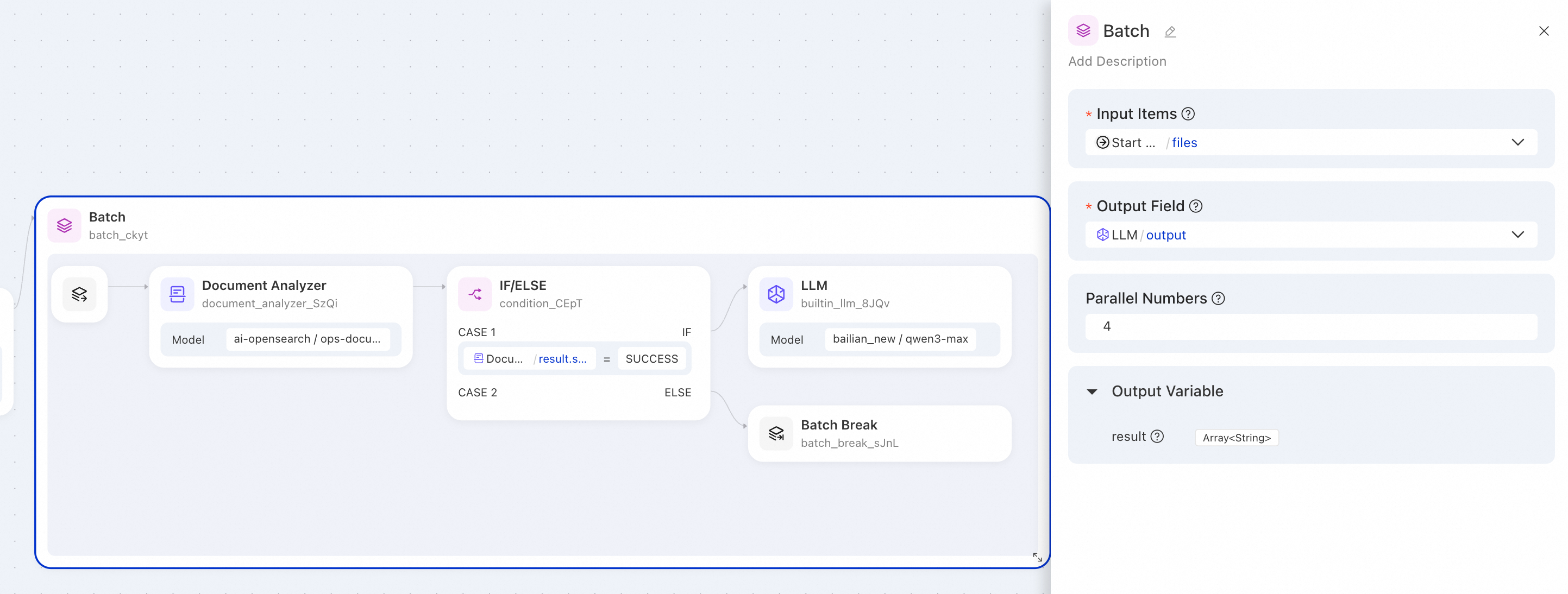
Konfigurasi node Pemrosesan batch:
|
Parameter |
Nilai |
Deskripsi |
|
Daftar input |
|
Rujuk output daftar file dari node Start upstream. |
|
Bidang output |
|
Pilih bidang output node LLM sebagai output untuk node Pemrosesan batch. |
|
Jumlah paralel |
|
Proses 4 file secara bersamaan. |
Contoh output:
{
"result": [
"Dokumen ini adalah panduan pengguna untuk produk XX, yang mencakup pengenalan fitur produk, langkah-langkah instalasi...",
"Ini adalah kontrak pengadaan layanan perangkat lunak dengan masa berlaku 12 bulan...",
null,
"Faktur pajak pertambahan nilai biasa, tanggal 15 Januari 2026..."
]
}Catatan: Nilai null dalam output menunjukkan bahwa file gagal diuraikan, dan node Batch Break melewati pemrosesan berikutnya.
Catatan
-
Jaminan urutan hasil: Urutan daftar output konsisten dengan urutan daftar input.
-
Fleksibilitas sub-alur: Di dalam sub-alur, item data yang berbeda dapat memicu jalur eksekusi yang berbeda.
-
Penanganan nilai null: Jika alur eksekusi suatu item berhenti secara prematur atau outputnya kosong, posisi yang bersesuaian dalam daftar output akan bernilai null.
End
Node End menandai penyelesaian sebuah alur aplikasi dan mendefinisikan parameter output-nya. Sebuah alur aplikasi hanya boleh memiliki satu node End.
-
Konfigurasi parameter output
Output alur aplikasi dapat merujuk output dari node upstream mana pun. Misalnya, dalam contoh di bawah ini, output 'answer' dari alur aplikasi menggunakan output node LLM, sedangkan 'search_results' menggunakan output node pencarian.
 Catatan
Catatan-
Alur percakapan memiliki bidang output bawaan 'Chat', yang berfungsi sebagai output percakapan dari alur aplikasi.
-
Alur aplikasi harus mencakup node Start dan End. Hanya node yang terhubung di antara keduanya yang dieksekusi; node yang terisolasi diabaikan.
-
Kemampuan AI
LLM
Node LLM adalah komponen inti dari sebuah alur aplikasi yang memanggil model bahasa besar untuk tugas bahasa alami seperti generasi teks, jawaban atas pertanyaan, dan pemrosesan input kompleks. Node ini menyediakan opsi konfigurasi untuk menyesuaikan parameter model, mengelola riwayat percakapan, serta menyesuaikan prompt.
-
Contoh penggunaan
-
Generasi teks: Hasilkan konten teks berdasarkan topik dan kata kunci.
-
Klasifikasi konten: Klasifikasikan jenis email secara otomatis (misalnya, pertanyaan, keluhan, atau spam).
-
Terjemahan teks: Terjemahkan teks ke bahasa tertentu.
-
RAG: Jawab pertanyaan pengguna dengan menggabungkan pengetahuan yang diambil dengan penalaran model.
-
-
Konfigurasi

-
Input
-
Pengaturan model: Mendukung model yang dikerahkan dari ModelGallery, layanan model yang dikerahkan secara kustom, dan model dari penyedia seperti Dashscope dan DeepSeek. Untuk kinerja terbaik, pilih model dengan kemampuan tinggi. Konfigurasikan parameter model berikut:
-
Temperature: Nilai biasanya antara 0 dan 1 yang mengontrol keacakan output. Nilai mendekati 0 menghasilkan output lebih deterministik, sedangkan nilai mendekati 1 menghasilkan hasil lebih beragam.
-
Top P: Ambang batas sampling nukleus. Model melakukan sampling dari himpunan token terkecil yang probabilitas kumulatifnya melebihi ambang batas P, sehingga memengaruhi keragaman output.
-
Top K: Membatasi kandidat token ke K token paling mungkin. Ini mengurangi keacakan dan membuat output lebih fokus, serta membatasi kreativitas secara lebih langsung dibandingkan Top P.
-
Presence penalty: Mengurangi pengulangan entitas atau informasi yang sama. Memberikan penalti pada token yang sudah ada dalam teks yang dihasilkan. Nilai yang lebih tinggi mengurangi pengulangan secara lebih agresif.
-
Frequency penalty: Memberikan penalti pada token berdasarkan frekuensinya dalam teks yang dihasilkan, sehingga mengurangi kata atau frasa yang terlalu sering muncul. Nilai yang lebih tinggi mendorong keragaman leksikal yang lebih besar.
-
Max tokens: Panjang output maksimum (dalam token) per eksekusi. Nilai lebih rendah dapat memotong output, sedangkan nilai lebih tinggi memungkinkan respons lebih panjang.
-
Seed: Ketika ditentukan, model berupaya melakukan sampling deterministik. Permintaan berulang dengan seed dan parameter yang sama seharusnya menghasilkan hasil yang sama, meskipun determinisme penuh tidak dijamin. Rujuk parameter respons system_fingerprint untuk memantau perubahan.
-
Stop sequences: Maksimal empat urutan yang menginstruksikan model untuk berhenti menghasilkan output lebih lanjut. Ketika model menemukan salah satu urutan ini, ia berhenti menghasilkan token. Teks yang dikembalikan tidak mencakup urutan penghentian tersebut.
-
-
Riwayat percakapan: Jika diaktifkan, riwayat obrolan alur aplikasi secara otomatis disisipkan ke dalam prompt.
-
Variabel input: Variabel dapat merujuk output dari semua node sebelumnya.
-
Prompt: Prompt berisi konten kustom untuk System (SYSTEM), User (USER), atau Assistant (ASSISTANT). Prompt merupakan templat Jinja2 di mana Anda dapat merujuk variabel input menggunakan kurung kurawal ganda
{{}}.
-
-
Output
Node secara bawaan menghasilkan output String tetapi juga mendukung JSON. Jenis JSON mendukung variabel output kustom, dan model menghasilkan output berdasarkan nama variabel tersebut.
-
Contoh penggunaan
Pengenalan maksud
Node Pengenalan maksud terutama digunakan untuk pengendalian alur. Node ini menggunakan model bahasa besar untuk menganalisis maksud pengguna dan mengarahkan eksekusi ke cabang yang sesuai berdasarkan hasilnya. Node ini mendukung konfigurasi multi-maksud dan riwayat percakapan.
-
Konfigurasi

-
Input
-
Input pengguna: Pilih input pengguna yang akan digunakan untuk pengenalan maksud.
-
Konfigurasi multi-maksud: Atur maksud sesuai kebutuhan, pastikan deskripsi setiap maksud jelas dan tidak ada tumpang tindih semantik antar-maksud. Maksud terakhir secara bawaan adalah "Lainnya", yang dicocokkan ketika tidak ada maksud lain yang berlaku dan tidak dapat diedit.
-
Pengaturan model: Konfigurasikan model bahasa besar untuk pengenalan maksud. Untuk kinerja lebih baik, pilih model dengan kemampuan lebih tinggi, seperti qwen-max.
-
Riwayat percakapan: Ketika diaktifkan, model bahasa besar secara otomatis menyisipkan riwayat percakapan alur aplikasi ke dalam prompt selama penalaran.
-
Prompt tambahan: Konten ini ditambahkan ke prompt sistem untuk membantu model melakukan pengenalan maksud secara lebih akurat.
-
-
Output
Node ini tidak menghasilkan output.
-
Contoh penggunaan
Saat menghubungkan node Pengenalan maksud ke node downstream, setiap cabang maksud memiliki port koneksi tersendiri di node. Ketika maksud dikenali, node downstream yang terhubung ke cabang tersebut dijalankan, sedangkan node di cabang lain dilewati. Anda kemudian dapat menggunakan node Variable aggregate untuk mengumpulkan hasil eksekusi dari setiap cabang.

Agen
Node Agen memungkinkan model bahasa besar (LLM) merencanakan, memilih alat, dan bertindak secara otonom. Node ini mendukung strategi penalaran dan kemampuan penggunaan alat. Dengan mengintegrasikan strategi seperti FunctionCalling dan ReAct, node ini memungkinkan LLM memanggil alat secara otonom yang sesuai dengan Model Context Protocol (MCP) pada waktu proses untuk mencapai penalaran multi-langkah.
Parameter node
-
Strategi agen: Pilih strategi penalaran agen yang diinginkan. Saat ini, strategi FunctionCalling dan ReAct didukung.
FunctionCalling
Fitur ini memungkinkan interaksi antara Large Language Model (LLM) dan alat eksternal berdasarkan definisi
tool callterstruktur (dalam format JSON) dari OpenAI Chat API. LLM menganalisis instruksi bahasa alami pengguna untuk secara otomatis mengidentifikasi maksud, memilih alat yang tepat, serta mengekstrak parameter. Sistem kemudian memanggil alat yang sesuai dan mengembalikan hasilnya ke model untuk melakukan penalaran lebih lanjut serta menghasilkan jawaban akhir.Contoh penggunaan dan keunggulan:
-
Panggilan terstruktur, kompatibilitas kuat: Menggunakan data terstruktur untuk secara jelas mendefinisikan nama alat dan parameter panggilan, sehingga kompatibel dengan semua model yang mendukung pemanggilan alat.
-
Kinerja stabil: Cocok untuk tugas dengan tujuan jelas dan langkah-langkah terdefinisi dengan baik, seperti memeriksa cuaca, mencari informasi, atau menanyakan data.
ReAct
ReAct (Reasoning + Acting) adalah strategi penalaran fleksibel yang menggunakan prompt untuk memandu model agar secara eksplisit menghasilkan Thoughts dan Actions, sehingga menciptakan lingkaran tertutup untuk penalaran multi-langkah dan pemanggilan alat. Strategi ini biasanya menggunakan bahasa alami untuk menggambarkan proses pemanggilan. Strategi ini memicu eksekusi alat backend dengan menghasilkan teks seperti "Action=xxx, Action Input=xxx" dan menyuntikkan hasilnya kembali ke rantai penalaran model. Metode ini tidak memerlukan
tool_callsdi tingkat API, sehingga cocok untuk model dan kerangka kerja yang lebih umum.Contoh penggunaan dan keunggulan:
-
Kemampuan penalaran yang ditingkatkan: Memandu model untuk berpikir langkah demi langkah, dengan setiap langkah secara eksplisit menyatakan logika penalarannya.
-
Strategi transparan: Ideal untuk aplikasi agen yang memerlukan debugging dan interpretabilitas kuat.
-
Tidak memerlukan dukungan Pemanggilan alat: Dapat digunakan bahkan dengan model yang tidak mendukung output terstruktur.
-
-
Pengaturan model: Strategi FunctionCalling memerlukan model yang secara native mendukung pemanggilan alat. Strategi ReAct tidak memiliki batasan ini, namun kami merekomendasikan memilih model dengan kemampuan penalaran kuat.
-
Riwayat percakapan: Mengaktifkan riwayat percakapan memberikan memori kontekstual kepada agen. Sistem secara otomatis menyertakan pesan percakapan sebelumnya dalam prompt, sehingga agen dapat memahami dan merujuk bagian percakapan sebelumnya. Misalnya, agen dengan riwayat percakapan aktif dapat menyelesaikan kata ganti (seperti "dia" atau "itu") tanpa memerlukan pengulangan informasi dari pengguna.
-
Perencanaan tugas: Ketika diaktifkan, sistem secara otomatis menambahkan alat bawaan
write_todoske daftar alat yang tersedia bagi agen. Untuk pertanyaan pengguna yang kompleks, agen secara otomatis memanggil alatwrite_todosuntuk merencanakan tugas dan mengeksekusinya langkah demi langkah, serta memperbarui rencana secara dinamis berdasarkan informasi terbaru. -
Alat MCP & alat lainnya: Mendukung konfigurasi alat MCP dan non-MCP. Untuk informasi selengkapnya, lihat Mengonfigurasi alat untuk Agen.
-
Konfigurasi prompt
-
Variabel input: Saat Anda ingin merujuk variabel dari node upstream alur aplikasi dalam prompt, Anda harus mendefinisikan variabel input yang sesuai di node saat ini dan mengatur nilainya sebagai referensi ke variabel node upstream. Kemudian, di bagian Prompt di bawah ini, Anda dapat menggunakan sintaks templat Jinja2, yang ditandai dengan kurung kurawal ganda (
{{}}), untuk merujuk variabel input yang telah didefinisikan tersebut dan memungkinkan penerusan data dinamis. -
Prompt sistem: Digunakan untuk menentukan tujuan tugas dan konteks agen, memberikan model latar belakang yang diperlukan untuk memandu pembuatan respons. Ini opsional untuk strategi ReAct.
-
Prompt pengguna: Menerima input atau kueri pengguna, yang berfungsi sebagai dasar bagi pembuatan respons model.
-
-
Jumlah loop: Menetapkan jumlah maksimum siklus eksekusi untuk agen, berkisar antara 1 hingga 99. Agen mengulang tugas untuk menghasilkan respons hingga salah satu kondisi berikut terpenuhi:
-
LLM menentukan bahwa ia telah mengumpulkan cukup informasi melalui pemanggilan alat untuk menghasilkan hasil lengkap.
-
Jumlah maksimum loop yang ditetapkan tercapai.
Menetapkan jumlah loop yang wajar membantu menyeimbangkan kelengkapan respons dengan efisiensi eksekusi. Jika Perencanaan tugas diaktifkan, kami merekomendasikan menggunakan jumlah maksimum loop bawaan untuk memastikan model dapat sepenuhnya mengeksekusi semua langkah sesuai rencana.
-
-
Variabel output:
-
intermediate_steps: String berisi langkah-langkah perantara eksekusi agen.
-
text: String berisi output akhir agen.
-
Jejak dan log
Setelah mengklik Run di sudut kanan atas halaman alur aplikasi, Anda dapat melihat jejak atau log di bawah hasil eksekusi dalam kotak dialog yang muncul.
-
Lihat output perantara: Klik ikon status eksekusi di sudut kanan atas node Agen di dalam alur kerja. Di panel tarik turun di bawahnya, cari
intermediate_stepsdi bagian Output untuk melihat proses penalaran agen. -
Lihat jejak: Lihat informasi jejak dari eksekusi saat ini untuk memahami input dan output agen untuk setiap permintaan model (termasuk pemanggilan alat dan parameter permintaan), biaya token, serta konsumsi waktu.
-
Lihat log: Jika alur aplikasi mengalami kesalahan, Anda dapat melihat log eksekusi saat ini untuk mendapatkan detail lebih lanjut tentang proses eksekusi node.
Selain itu, Anda dapat mengklik ikon di sebelah kanan tombol Run di sudut kanan atas halaman alur aplikasi untuk melihat Riwayat Eksekusi. Pilih catatan eksekusi tertentu untuk melihat jejak atau log-nya.
Penguraian dokumen
Mendukung penggunaan parser dokumen cerdas bawaan sistem dan layanan penguraian dokumen dari AI Search Open Platform.
-
Parser bawaan: Mengekstrak konten terstruktur dan metadata dari dokumen, mendukung berbagai format dokumen utama, termasuk PDF, DOCX, PPTX, TXT, HTML, CSV, XLSX, XLS, JSONL, dan MD.
-
AI Search Open Platform: Mencapai penguraian dokumen terstruktur presisi tinggi, mendukung ekstraksi informasi hierarki logis seperti judul dan paragraf, serta konten seperti teks, tabel, dan gambar. Hal ini meningkatkan efektivitas dan akurasi ekstraksi dokumen. Anda perlu terlebih dahulu mengonfigurasi koneksi layanan model AI Search Open Platform. Format file yang didukung meliputi PDF, DOCX, PPTX, TXT, dan HTML.
Alat ini mendukung skenario RAG, ringkasan, dan jawaban atas pertanyaan. Antarmuka konfigurasinya adalah sebagai berikut: 
-
Berkas dokumen: Berkas dokumen yang akan diuraikan. Pilih bidang bertipe berkas dari node upstream.
-
Pengaturan model: (Opsional) Pilih koneksi layanan model AI Search Open Platform yang telah dibuat di LangStudio. Jika tidak dikonfigurasi, sistem menggunakan metode penguraian dasar bawaan secara bawaan.
-
Output:
-
file_id: Pengidentifikasi unik berkas input.
-
content: Konten teks terstruktur hasil penguraian, termasuk informasi hierarki seperti judul dan paragraf.
-
status: Status penguraian, yang bisa berupa SUCCESS atau FAIL.
-
metadata: Metadata dokumen dan detail penguraian.
-
file_name: Nama berkas.
-
file_type: Jenis berkas.
-
source_uri: URI asli berkas.
-
download_url: URL unduh berkas.
-
analysis_method: Metode penguraian yang digunakan. "opensearch" menunjukkan penguraian terstruktur menggunakan AI Search Open Platform, sedangkan "builtin" menunjukkan penggunaan metode penguraian dasar bawaan.
-
-
Contoh penggunaan downstream: Di node downstream, rujuk bidang hasil node penguraian dokumen sesuai kebutuhan. Untuk menggunakan hasil penguraian dokumen di node LLM, Anda dapat menyertakan konten hasil penguraian dalam prompt pengguna seperti ditunjukkan di bawah ini:

Pengenalan ucapan
Gunakan node Pengenalan ucapan untuk mengonversi berkas audio atau video menjadi teks. Node ini mendukung berbagai format audio dan pengenalan bahasa.
Input
-
Pengaturan model: Konfigurasikan model pengenalan ucapan. Saat ini, layanan pengenalan ucapan yang disediakan oleh Alibaba Cloud Model Studio didukung. Kami merekomendasikan menggunakan
paraformer-v2untuk kinerja pengenalan yang lebih baik dan dukungan multibahasa. -
Berkas audio/video: Pilih berkas audio atau video yang akan dienali. Untuk format yang didukung, lihat Input dan output tipe file.
-
Bahasa pengenalan: Menentukan bahasa untuk pengenalan audio. Bahasa yang didukung adalah Mandarin, Inggris, Jepang, Kanton, Korea, Jerman, Prancis, Rusia, atau deteksi otomatis. Catatan: Fitur ini hanya didukung oleh model
paraformer-v2. Model lain menggunakan deteksi bahasa otomatis secara bawaan.
Output
-
file_id: Pengidentifikasi unik berkas input.
-
status: Status pengenalan. Nilai yang mungkin adalah
SUCCESSatauFAIL. -
content: Konten teks hasil transkripsi.
-
segments: Daftar informasi fragmen kalimat, termasuk timestamp, fragmen teks, dan detail lainnya.
-
metadata: Metadata berkas, termasuk:
-
file_name: Nama berkas.
-
file_type: Jenis berkas.
-
source_uri: URI berkas.
-
download_url: URL unduh berkas.
-
Pengambilan data
Untuk mengonfigurasi node berikut, lihat Node pengambilan data:
-
Pengambilan basis pengetahuan
-
Alibaba Cloud IQS - pencarian web
-
SerpAPI - pencarian umum
-
Permintaan HTTP
Pemrosesan data
Pengembangan Python (Python)
Alur aplikasi mendukung node dengan kode Python kustom untuk pemrosesan data kompleks. Node ini mendukung input dan output streaming. Halaman konfigurasinya adalah sebagai berikut:

Cukup isi kode Python. Input dan output secara otomatis diurai dari kode. Perhatikan hal berikut:
-
Fungsi entri harus didekorasi dengan
@toolagar dapat dimuat sebagai node.CatatanUntuk mengaktifkan input streaming pada node Python, Anda harus mengonfigurasi
@tool(properties={"streaming_pass_through": True}). Jika tidak, input ke node Python, seperti dari LLM, akan berupa teks output lengkap, bukan aliran. -
Fungsi mendukung jenis input/output berikut: int, float, bool, str, dict, TypedDict, dataclass (output saja), list, dan File.
-
Parameter fungsi entri diurai secara dinamis sebagai input node. Output ditempatkan dalam kamus
outputdan dapat dirujuk oleh node lain.PentingPenguraian otomatis parameter input dan output untuk node Python bergantung pada runtime. Jika runtime belum diluncurkan, Anda tidak dapat mengonfigurasi informasi input dan output node.
-
Jika kode Python Anda memerlukan dependensi, pilih Install Dependencies di sudut kanan atas kanvas dan masukkan paket yang diperlukan. File
requirements.txtdisimpan bersama alur aplikasi. Dependensi diinstal saat Anda meluncurkan runtime atau menerapkan layanan.

Kasus penggunaan 1: Masukkan kode berikut di area kode. Kode ini dipetakan ke input dan output node:
from langstudio.core import tool
from dataclasses import dataclass
@dataclass
class Result:
output1: str
output2: int
@tool
def invoke(foo: str, bar: int) -> Result:
return Result(
output1="hello" + foo,
output2=bar + 10
)

Kasus penggunaan 2: Input dan output streaming. Gunakan node Python untuk memangkas aliran teks dari node LLM atau agen yang mencakup proses berpikir. Dengan menghapus konten dalam bagian <think>\n\n</think>, Anda bisa mendapatkan aliran teks akhir dari hasilnya. Berikut adalah contohnya:
import re
from typing import Iterator
from langstudio.core import tool
@tool(properties={"streaming_pass_through": True})
def strip_think(
stream: Iterator[str],
) -> Iterator[str]: # Input berupa iterator string streaming, dan output berupa iterator string streaming yang telah difilter.
# Cocokkan struktur <think>\n...\n</think> dan tangkap teks setelah tag penutup.
pattern = re.compile(r"<think>\n[\s\S]*\n</think>(.*)")
in_thinking = True # Flag untuk menunjukkan apakah posisi saat ini berada di dalam blok <think>.
think_buf = "" # Buffer untuk menyimpan konten yang belum diproses.
for chunk in stream:
if in_thinking:
think_buf += chunk
m = pattern.search(think_buf) # Periksa apakah buffer berisi blok pikiran lengkap.
if m:
in_thinking = False
result_part = m.groups()[0]
if result_part:
yield result_part # Jika teks hasil ada, hasilkan segera.
else:
yield chunk # Setelah keluar dari blok pikiran, hasilkan semua potongan berikutnya secara langsung.
Transformasi templat
Alat Transformasi templat menggunakan sintaks templat Jinja2 untuk memungkinkan pemformatan teks dan transformasi data yang fleksibel.
Input
Mode transformasi mendukung mode Jinja2 dan mode referensi node.
-
Mode Jinja2: Menggunakan sintaks templat Jinja2 penuh untuk menyesuaikan format output. Mode ini cocok untuk output terstruktur kompleks, logika kondisional, dan rendering loop.
-
Variabel templat: Definisikan variabel yang digunakan dalam templat.
PentingNama variabel tidak boleh berupa nama metode bawaan Python, seperti
items,keys, atauvalues. Gunakan nama bidang spesifik, sepertiitem_listatauproduct_list. -
Konten templat: Sebuah string templat yang ditulis dalam sintaks Jinja2. Templat ini mendukung sintaks penuh, termasuk substitusi variabel
{{ variable }}, loop{% for %}, pernyataan kondisional{% if %}, dan filter{{ value | filter }}.PentingSemua variabel yang dirujuk dalam templat harus didefinisikan dalam daftar variabel. Jika tidak, akan terjadi kesalahan.
-
-
Mode referensi node: Secara langsung merujuk output node upstream dan menggabungkannya secara otomatis menjadi string. Mode ini cocok untuk skenario kombinasi teks sederhana.
-
Konten templat: Pilih bidang output dari node upstream. Sistem secara otomatis menggabungkannya dalam urutan.
-
Output
output: Hasil teks setelah templat dirender. Catatan: Panjang konten templat input dan output dibatasi hingga 100.000 karakter. Konten yang melebihi batas ini akan dipotong.
Contoh penggunaan
Contoh 1: Hasilkan email konfirmasi pesanan
Konfigurasi variabel:
|
Nama variabel |
Nilai variabel |
|
customer_name |
|
|
order_id |
|
|
products |
|
|
total |
|
Konten templat:
Kepada {{ customer_name }}:
Pesanan Anda {{ order_id }} telah dikonfirmasi. Detailnya adalah sebagai berikut:
{% for product in products %}
- {{ product.name }}: ¥{{ product.price }}
{% endfor %}
Total: ¥{{ total }}
Terima kasih atas pembelian Anda!Hasil output:
Kepada John Doe:
Pesanan Anda ORD-2025-001 telah dikonfirmasi. Detailnya adalah sebagai berikut:
- Laptop: ¥8999
- Wireless Mouse: ¥199
Total: ¥9198
Terima kasih atas pembelian Anda!Contoh 2: Format hasil pengambilan basis pengetahuan
Konfigurasi variabel:
|
Nama variabel |
Nilai variabel |
|
chunks |
|
Konten templat:
{% for chunk in chunks %}
### Relevansi: {{ "%.2f" % chunk.score }}
#### {{ chunk.title }}
{{ chunk.content }}
---
{% endfor %}Hasil output:
### Relevansi: 0.95
#### Product Introduction
This is a detailed introduction to the product...
---Operasi daftar
Alat Operasi daftar memungkinkan Anda melakukan penyaringan dan pengurutan yang fleksibel pada berbagai jenis data daftar untuk pemrosesan dan seleksi data detail halus.
Input
-
Daftar input: Data daftar yang akan diproses. Alat ini mendukung semua subtipe, seperti string, angka, boolean, objek berkas, dan kamus.
-
Operasi: Rangkaian operasi berantai yang dieksekusi secara berurutan. Alat ini mendukung dua jenis operasi: penyaringan dan pengurutan.
-
Operasi penyaringan (filter): Operasi penyaringan menyediakan metode penyaringan berbeda secara dinamis berdasarkan tipe daftar input. Catatan: Semua operasi penyaringan bersifat case-sensitive.
Kunci penyaringan
Deskripsi
Cakupan
Index
Menyaring berdasarkan posisi elemen dalam daftar.
Berlaku untuk semua tipe daftar.
Nilai elemen
Menyaring berdasarkan nilai elemen itu sendiri.
Berlaku untuk semua tipe daftar.
Atribut kustom
Menyaring berdasarkan atribut kustom.
Hanya berlaku untuk daftar kamus.
Atribut berkas
Menyaring berdasarkan atribut berkas.
Hanya berlaku untuk daftar berkas.
-
Operasi pengurutan (sort): Operasi pengurutan menyediakan metode pengurutan berbeda berdasarkan tipe daftar input.
Kunci pengurutan
Deskripsi
Cakupan
Nilai elemen
Mengurutkan berdasarkan nilai elemen itu sendiri.
Hanya berlaku untuk daftar string, angka, atau boolean.
Atribut kustom
Mengurutkan berdasarkan atribut kustom.
Hanya berlaku untuk daftar kamus.
Atribut berkas
Mengurutkan berdasarkan atribut berkas.
Hanya berlaku untuk daftar berkas. Atribut yang tersedia sama dengan operasi penyaringan.
-
Output
-
result: Hasil daftar yang telah diproses.
-
first_item: Elemen pertama dari daftar hasil. Jika daftar kosong, nilainya adalah
None. -
last_item: Elemen terakhir dari daftar hasil. Jika daftar kosong, nilainya adalah
None.
Contoh penggunaan
Contoh 1: Klasifikasi berkas – Saring berkas gambar, urutkan berdasarkan panjang nama berkas, dan ambil 3 teratas
Skenario: Pengguna mengunggah daftar berkas campuran dari berbagai tipe. Anda perlu menyaring berkas gambar, mengurutkannya berdasarkan panjang nama berkas, dan menyimpan hanya 3 teratas untuk pemrosesan pengenalan gambar berikutnya.
Konfigurasi operasi:
Operasi 1 - Penyaringan (berdasarkan kategori berkas):
Kunci penyaringan: item.category
Operator penyaringan: equals
Nilai penyaringan: image
Operasi 2 - Pengurutan (berdasarkan panjang nama berkas):
Kunci pengurutan: item.file_name
Arah pengurutan: asc
Operasi 3 - Penyaringan (ambil 3 teratas):
Kunci penyaringan: index
Operator penyaringan: less than
Nilai penyaringan: 3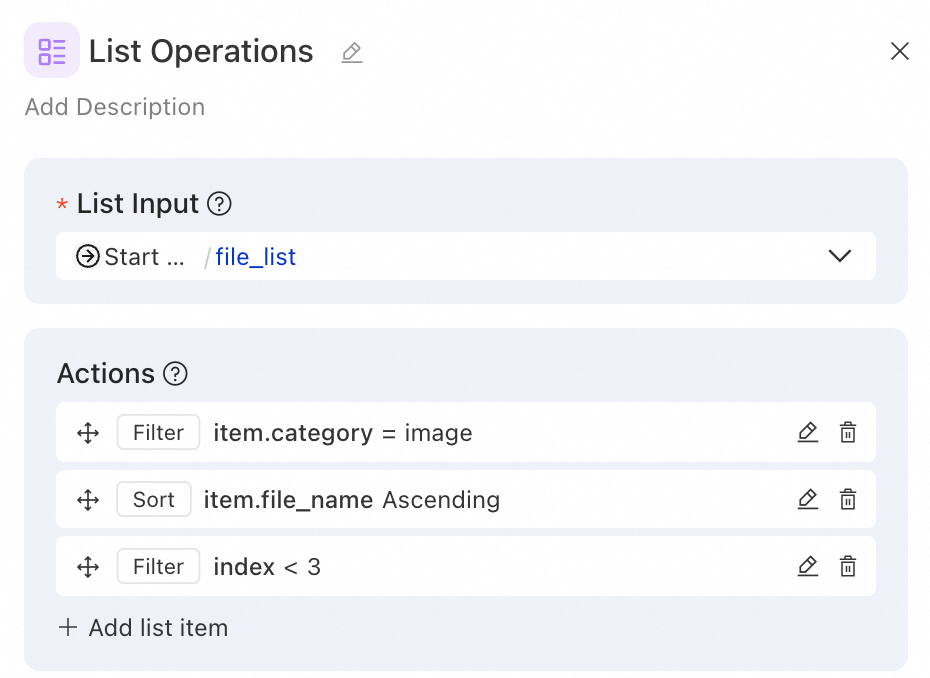
Contoh 2: Analisis data – Saring pengguna dengan skor tinggi dan ambil 5 teratas
Skenario: Dari daftar peringkat pengguna, saring pengguna dengan skor 80 atau lebih tinggi, urutkan berdasarkan skor secara menurun, dan ambil 5 teratas.
Daftar input:
[
{"name": "Zhang San", "score": 95, "department": "Tech Dept"},
{"name": "Li Si", "score": 72, "department": "Marketing Dept"},
{"name": "Wang Wu", "score": 88, "department": "Tech Dept"},
{"name": "Zhao Liu", "score": 91, "department": "Product Dept"},
{"name": "Qian Qi", "score": 65, "department": "Marketing Dept"},
{"name": "Sun Ba", "score": 98, "department": "Tech Dept"}
]Konfigurasi operasi:
Operasi 1 - Penyaringan (pengguna dengan skor tinggi):
Kunci penyaringan: item.score
Operator penyaringan: greater than or equal to
Nilai penyaringan: 80
Operasi 2 - Pengurutan (berdasarkan skor menurun):
Kunci pengurutan: item.score
Arah pengurutan: desc
Operasi 3 - Penyaringan (ambil 5 teratas):
Kunci penyaringan: index
Operator penyaringan: less than
Nilai penyaringan: 5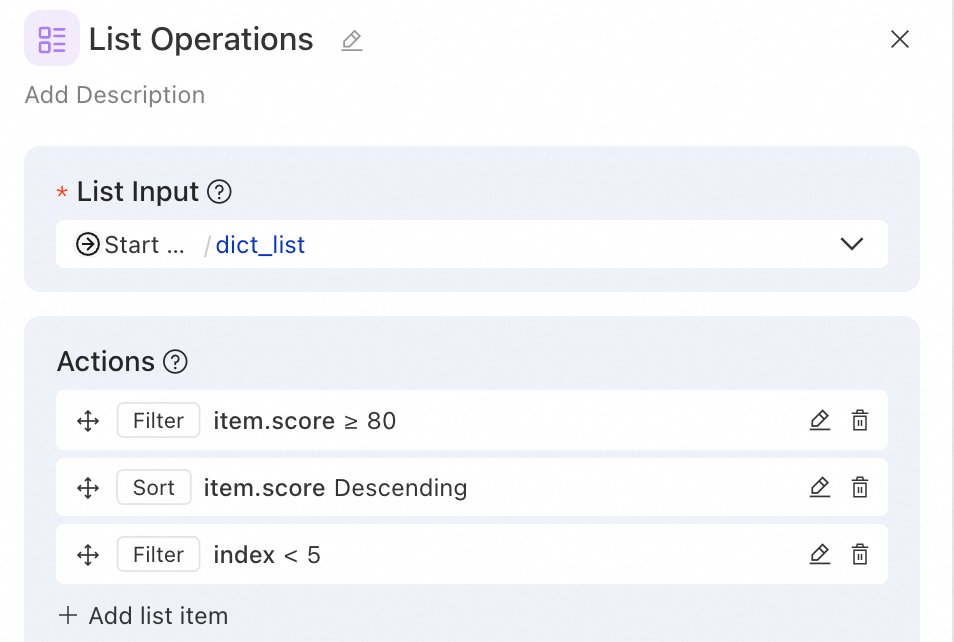
Hasil output:
[
{"name": "Sun Ba", "score": 98, "department": "Tech Dept"},
{"name": "Zhang San", "score": 95, "department": "Tech Dept"},
{"name": "Zhao Liu", "score": 91, "department": "Product Dept"},
{"name": "Wang Wu", "score": 88, "department": "Tech Dept"}
]Catatan:
-
Jika input alat ini merujuk variabel output bertipe
listyang dikustomisasi di node Python, definisikan tipe elemen yang jelas untuk daftar di node Python, sepertilist[str]. Ini memastikan pencocokan operator yang lebih akurat di node Operasi daftar.