AI Search Open Platform menyediakan layanan algoritma berbasis komponen untuk skenario pencarian cerdas dan Generasi yang Diperkaya dengan Pengambilan Data (RAG). Layanan ini mencakup seluruh pipeline—mulai dari penguraian dokumen, chunking, penyematan teks, analisis kueri, pengambilan, pengurutan, evaluasi performa, hingga generasi berbasis model bahasa besar (LLM)—dengan setiap tahap tersedia sebagai layanan independen yang dapat dipanggil. Pilih hanya komponen yang dibutuhkan oleh kasus penggunaan Anda.
Aktivasi gratis. Akun Alibaba Cloud baru menerima 10 panggilan layanan gratis, yang dibagikan di antara semua Pengguna RAM dalam akun tersebut. Setelah kuota gratis habis, biaya akan dikenakan berdasarkan penggunaan aktual panggilan layanan LLM. Activate Now
Kasus penggunaan
RAG dan pencarian percakapan
Bangun basis pengetahuan, sistem layanan pelanggan cerdas, dan aplikasi pencarian percakapan. Contoh kueri khas: "Apa langkah-langkah untuk mengonfigurasi X?" atau "Ringkas poin-poin utama dalam dokumen ini."
Layanan pelanggan cerdas
Pencarian percakapan
Peningkatan graf pengetahuan
Rekomendasi personalisasi
Untuk contoh pengembangan, lihat Bangun aplikasi pencarian percakapan berbasis RAG.
Pencarian multi-modal
Lakukan pencarian lintas konten teks dan gambar menggunakan pemahaman semantik dan pengenalan visual. Contoh kueri khas: pencarian berbasis gambar, penemuan konten lintas modalitas, dan pencarian dokumen berbasis OCR.
E-dagang dan ritel
Konten berita
Gaming
Kesehatan
Keuangan
Untuk contoh pengembangan, lihat Pengembangan bisnis pencarian multi-modal.
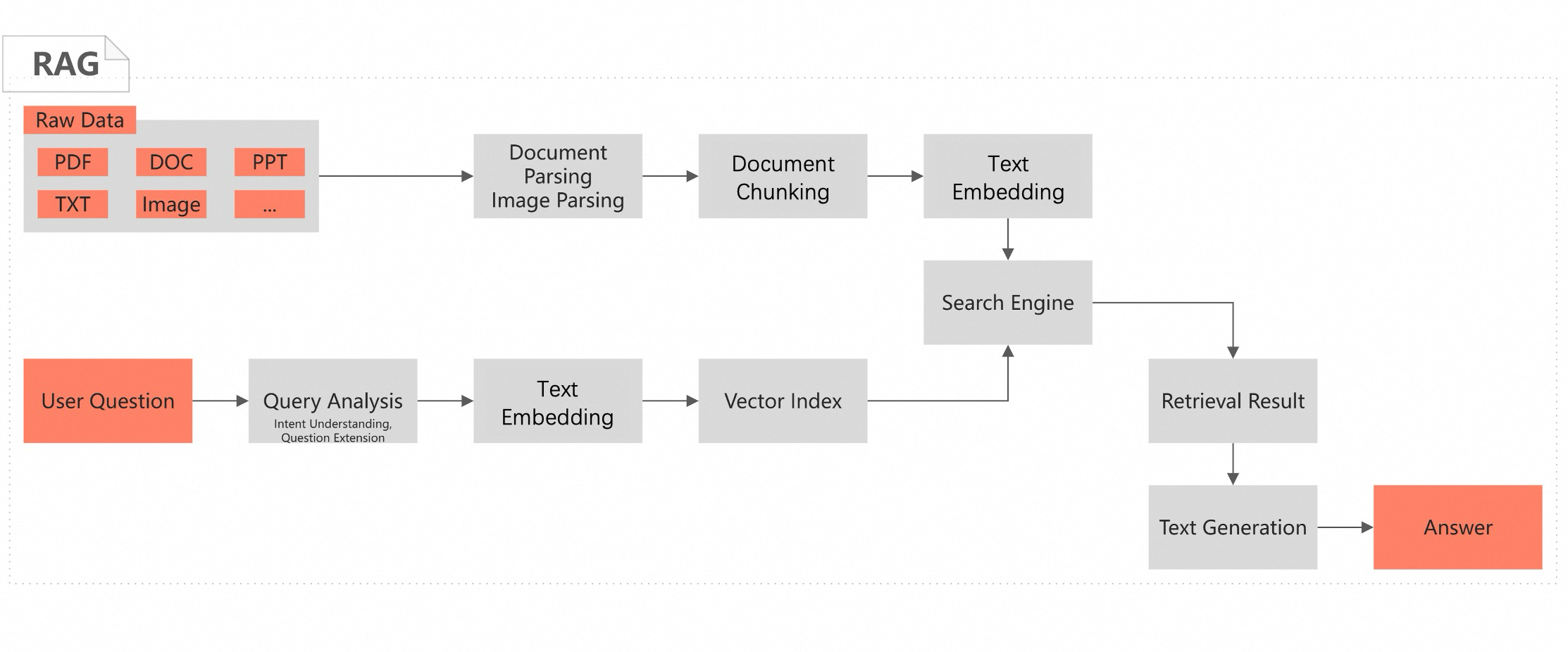
Cara kerja
AI Search Open Platform memproses data melalui pipeline modular. Setiap tahap merupakan layanan independen yang dapat dipanggil:
Urai dokumen — Ekstrak teks, tabel, gambar, dan kode dari format PDF, DOC, HTML, TXT, dan lainnya. Kecepatan penguraian dalam hitungan menit.
Chunk konten — Pisahkan dokumen berdasarkan semantik dan struktur paragraf. Struktur pohon chunk yang dihasilkan mendukung pelengkapan konteks selama pengambilan.
Sematkan teks — Konversi chunk menjadi vektor padat atau vektor jarang menggunakan model penyematan multibahasa. Gabungkan keduanya untuk pencarian hibrida.
Analisis kueri — Pahami maksud pengguna, perluas pertanyaan serupa, atau konversi bahasa alami menjadi SQL menggunakan kemampuan LLM dan Pemrosesan Bahasa Alami (NLP).
Ambil hasil — Jalankan pengambilan vektor dan teks terhadap data yang telah diindeks.
Urutkan dan peringkat — Terapkan pengurutan tingkat kueri dan dokumen untuk menampilkan konten yang paling relevan.
Hasilkan tanggapan — Gunakan LLM bawaan untuk menghasilkan jawaban yang didasarkan pada konten yang diambil.
Fitur
Penguraian konten dokumen
Mengurai format PDF, DOC, HTML, TXT, dan lainnya dengan kecepatan tingkat menit. Membedakan tata letak, mengekstrak struktur logis (judul, paragraf), serta mengidentifikasi elemen konten termasuk teks, tabel, gambar, dan kode. Menghapus header dan footer serta mendeteksi superskrip dan subskrip. Output-nya terstruktur.
Penguraian konten gambar
Mengurai konten gambar—seperti diagram arsitektur dan grafik analitis—menggunakan LLM multi-modal. Mendukung Pengenalan Karakter Optik (OCR) untuk mengekstrak teks dari gambar guna digunakan dalam pengambilan berbasis gambar dan tanya-jawab berbasis gambar.
Chunking dokumen
Memisahkan dokumen berdasarkan semantik, struktur paragraf, dan aturan yang dapat dikonfigurasi. Menghasilkan pohon chunk untuk pelengkapan konteks selama pengambilan.
Model penyematan multibahasa
Penyematan teks: Mengonversi teks menjadi vektor padat. Berbagai model mendukung bahasa, panjang input, dan dimensi output yang berbeda. Digunakan untuk pencarian, klasifikasi teks, dan perbandingan relevansi.
Penyematan jarang: Mengonversi teks menjadi vektor jarang yang menggunakan lebih sedikit ruang penyimpanan. Menangkap kata kunci dan istilah frekuensi tinggi. Gabungkan dengan vektor padat untuk pencarian hibrida guna meningkatkan performa pengambilan.
Tuning model penyematan: Latih model reduksi dimensionalitas untuk mengurangi dimensi vektor tanpa secara signifikan memengaruhi kualitas pengambilan.
Analisis kueri
Menganalisis kueri menggunakan LLM dan NLP untuk memahami maksud pengguna, memperluas pertanyaan serupa, serta mengonversi bahasa alami menjadi SQL. Meningkatkan akurasi pencarian percakapan dalam skenario RAG.
Mesin pencari
Menyediakan mesin pengambilan vektor dan teks. Simpan vektor dan teks, bangun indeks, serta jalankan pengambilan vektor dan teks secara online. Gunakan mesin ini bersama API AI Search Open Platform untuk memproses dan mengambil data secara end-to-end.
Pengurutan
Menerapkan pengurutan tingkat kueri dan dokumen dalam skenario RAG dan pencarian untuk menampilkan konten yang paling relevan. Meningkatkan akurasi pengambilan dan kualitas tanggapan yang dihasilkan LLM.
Generasi teks berbasis LLM
Menyediakan berbagai model, termasuk Qwen3-235B-A22B, QwQ, seluruh model DeepSeek (DeepSeek R1, V3, dan varian distilasi 7B/14B), serta seri Qwen (Qwen-Turbo, Qwen-Plus, dan Qwen-Max). Model bawaan OpenSearch-Qwen-Turbo didasarkan pada qwen-turbo dan ditingkatkan kemampuan RAG-nya setelah melalui supervised fine-tuning untuk mengurangi laju halusinasi.
Manfaat
Pipeline end-to-end, tidak perlu dirakit — Semua layanan tersedia segera setelah aktivasi. Alih-alih mengintegrasikan alat terpisah untuk setiap tahap pipeline pencarian atau RAG, Anda mendapatkan satu platform yang mencakup penguraian, penyematan, pengambilan, peringkat, dan generasi.
Panggil yang Anda butuhkan, lewati yang tidak — Pengembang, pelanggan perusahaan, dan ISV (vendor perangkat lunak independen) dapat memanggil operasi API tertentu atau menggunakan SDK untuk mengintegrasikan subset layanan apa pun. Desain modular memastikan arsitektur Anda hanya membawa komponen yang digunakan.
Model yang dioptimalkan untuk pencarian, siap pakai — AI Search Open Platform memungkinkan Anda melatih model pencarian AI khusus di atas model dasar terkemuka. Model bawaan OpenSearch-Qwen-Turbo telah disesuaikan khusus untuk RAG, sehingga mengurangi halusinasi dibandingkan model tujuan umum.
Dibangun di atas pola pencarian yang terbukti — Desain pipeline mencerminkan pengalaman bertahun-tahun dalam pencarian cerdas dan RAG. Praktik terbaik sudah terintegrasi, sehingga Anda menghabiskan lebih sedikit waktu mempelajari apa yang efektif dan lebih banyak waktu membangun.