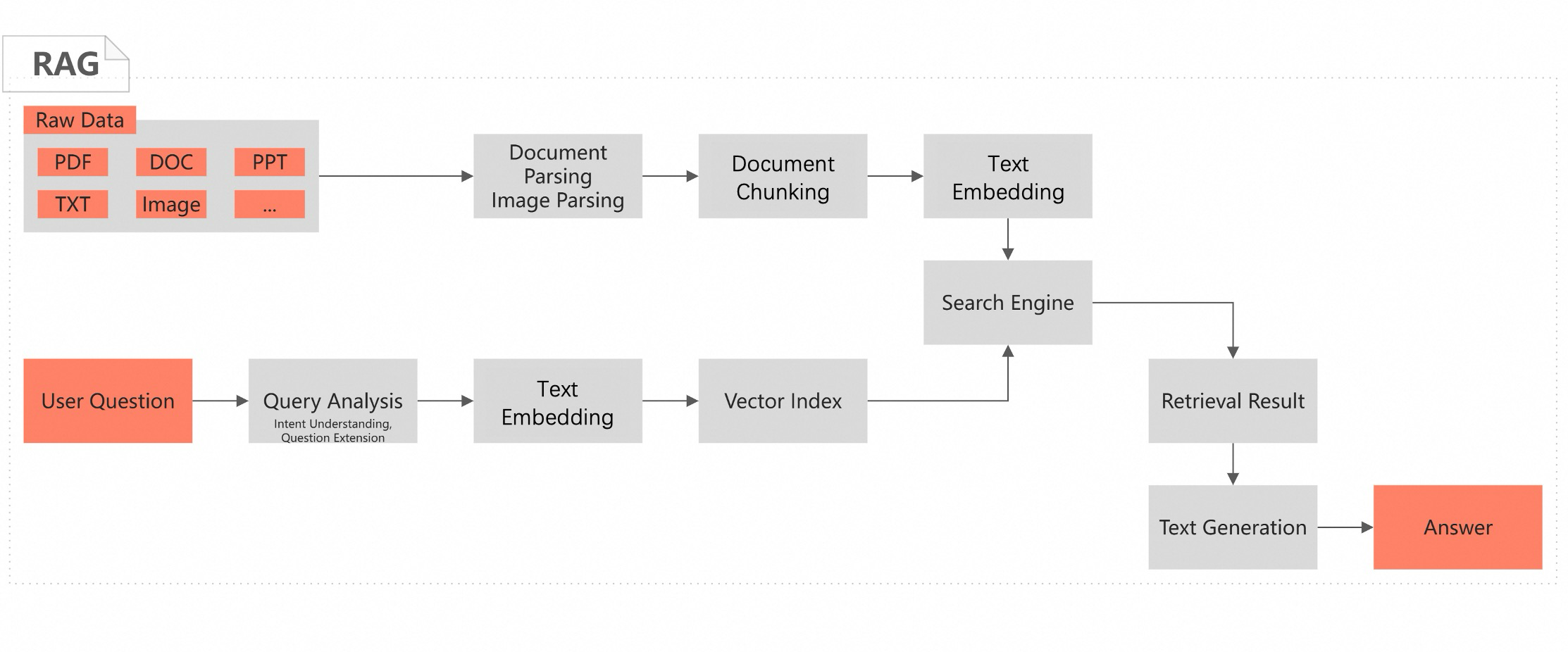
Untuk pencarian percakapan di atas basis pengetahuan, AI Search Open Platform menyediakan pipeline pengembangan lengkap guna membangun aplikasi Retrieval-Augmented Generation (RAG). Pipeline ini mencakup tiga modul utama: pra-pemrosesan data, pengambilan (retrieval), dan pembangkitan jawaban. AI Search Open Platform menyediakan kemampuan masing-masing modul sebagai layanan algoritma berbasis komponen yang dapat dikomposisikan—seperti parsing dokumen, reranking, dan pembangkitan jawaban—sehingga Anda dapat dengan cepat menghasilkan kode pengembangan. Layanan-layanan tersebut diekspos melalui API. Unduh kode yang disediakan dan ganti kunci API, titik akhir layanan, serta informasi basis pengetahuan lokal sesuai petunjuk dalam topik ini untuk segera membangun aplikasi pencarian percakapan berbasis RAG Anda.
Cara kerja
Retrieval-Augmented Generation (RAG) adalah teknik AI yang menggabungkan pengambilan informasi dengan model bahasa besar (LLM) untuk meningkatkan relevansi, akurasi, dan keragaman konten yang dihasilkan. Saat menangani kueri, sistem RAG pertama-tama mengambil cuplikan informasi paling relevan dari basis pengetahuan eksternal. Informasi tersebut, bersama dengan kueri asli, kemudian diberikan sebagai konteks kepada LLM. Pendekatan ini memungkinkan model menghasilkan jawaban yang lebih tepat dan informatif dengan merujuk pada data eksternal yang mutakhir atau spesifik domain, bukan hanya mengandalkan data pelatihan internalnya.
Kasus penggunaan
Pencarian percakapan di atas basis pengetahuan sangat ideal untuk kasus penggunaan seperti pengambilan pengetahuan internal perusahaan dan tanya jawab spesialisasi di domain vertikal. Penerapan Retrieval-Augmented Generation (RAG) dan model bahasa besar (LLM) pada dokumen basis pengetahuan profesional Anda memungkinkan sistem memahami dan merespons kueri bahasa alami yang kompleks. Hal ini membantu pengguna perusahaan menemukan informasi yang dibutuhkan dengan cepat dalam berbagai format dokumen, termasuk PDF, Word, tabel, dan gambar.
Dalam antarmuka pencarian percakapan, pengguna mengajukan pertanyaan dalam bahasa alami. Sistem mengembalikan jawaban terstruktur dan memberikan rekomendasi pertanyaan lanjutan untuk eksplorasi lebih jauh.
Prasyarat
-
Layanan AI Search Open Platform telah diaktifkan. Untuk informasi selengkapnya, lihat Aktifkan layanan.
-
Dapatkan titik akhir layanan dan kredensial autentikasi. Untuk informasi selengkapnya, lihat Dapatkan titik akhir layanan dan Kelola kunci API.
AI Search Open Platform mendukung panggilan layanan melalui titik akhir publik dan titik akhir VPC. Panggilan lintas wilayah didukung melalui titik akhir VPC. Saat ini, pengguna di wilayah China (Shanghai), China (Hangzhou), China (Shenzhen), China (Beijing), China (Zhangjiakou), dan China (Qingdao) dapat memanggil layanan AI Search Open Platform melalui titik akhir VPC.
Pada halaman API Keys, pesan di bagian atas berbunyi, "Kunci API digunakan untuk izin pemanggilan layanan. Harap simpan dengan aman. Jika kunci API dikompromikan, segera nonaktifkan. Anda dapat mengaktifkan hingga 10 kunci API secara bersamaan." Bagian Access Domain menampilkan Public API Domain dan Private API Domain, keduanya mendukung akses HTTPS.
-
Buat kluster Alibaba Cloud Elasticsearch versi 8.5 atau lebih baru. Untuk informasi selengkapnya, lihat Buat kluster Alibaba Cloud Elasticsearch. Saat mengakses kluster melalui jaringan publik atau VPC, Anda harus menambahkan alamat IP perangkat Anda ke daftar putih alamat IP kluster. Untuk informasi selengkapnya, lihat Konfigurasikan daftar putih alamat IP publik atau privat untuk kluster Elasticsearch.
-
Anda memiliki lingkungan Python 3.7 atau lebih baru dengan paket
aiohttp 3.8.6danelasticsearch 8.14yang telah diinstal.
Bangun pipeline pengembangan RAG
Untuk kenyamanan Anda, AI Search Open Platform menyediakan empat jenis framework pengembangan:
-
Java SDK
-
Python SDK
-
LangChain: Pilih opsi ini jika bisnis Anda sudah menggunakan framework LangChain.
-
LlamaIndex: Pilih opsi ini jika bisnis Anda sudah menggunakan framework LlamaIndex.
Langkah 1: Pilih layanan dan unduh kode
Berdasarkan basis pengetahuan dan kebutuhan bisnis Anda, pilih layanan algoritma dan framework pengembangan untuk pipeline RAG Anda. Topik ini menggunakan Python SDK sebagai contoh.
-
Masuk ke Konsol AI Search Open Platform.
-
Pilih wilayah China (Shanghai), beralih ke AI Search Open Platform, lalu pilih ruang kerja target Anda.
Catatan-
AI Search Open Platform hanya tersedia di wilayah China (Shanghai) dan Jerman (Frankfurt).
-
Pengguna di wilayah China (Hangzhou), China (Shenzhen), China (Beijing), China (Zhangjiakou), dan China (Qingdao) dapat menggunakan titik akhir VPC untuk memanggil layanan AI Search Open Platform lintas wilayah.
-
-
Di panel navigasi sebelah kiri, klik Scene Center. Pada kartu RAG Scene-Knowledge Base Online Q & A., klik Enter.
-
Dari daftar drop-down, pilih layanan yang Anda butuhkan sesuai kebutuhan bisnis. Anda dapat melihat informasi detail setiap layanan pada tab Service Details.
Catatan-
Saat memanggil layanan algoritma dalam pipeline RAG melalui API, Anda harus menyediakan ID layanan (
service_id). Misalnya, ID untuk layanan parsing konten dokumen adalahops-document-analyze-001. -
Saat Anda mengganti layanan dalam daftar,
service_iddalam kode yang dihasilkan akan diperbarui secara otomatis. Setelah mengunduh kode, Anda tetap dapat mengubahservice_iduntuk memanggil layanan berbeda.
Tahap
Deskripsi layanan
Document content parsing
Document content parsing service (ops-document-analyze-001): Layanan umum yang mengekstraksi struktur logis seperti judul dan paragraf dari dokumen tidak terstruktur (teks, tabel, dan gambar) serta mengeluarkannya dalam format terstruktur.
Image content parsing
-
Image content understanding service (ops-image-analyze-vlm-001): Menggunakan model besar multimodal untuk mengurai, memahami, dan mengenali teks dari gambar. Teks yang diekstraksi dapat digunakan untuk skenario pengambilan dan tanya jawab berbasis gambar.
-
Image text recognition service (ops-image-analyze-ocr-001): Menggunakan OCR untuk mengenali teks dalam gambar. Teks yang diurai dapat digunakan untuk skenario pengambilan dan tanya jawab berbasis gambar.
Document chunking
Document chunking service (ops-document-split-001): Layanan chunking teks umum yang membagi data terstruktur dalam format HTML, Markdown, dan TXT berdasarkan paragraf dokumen, semantik teks, atau aturan tertentu. Layanan ini juga mendukung ekstraksi kode, gambar, dan tabel sebagai teks kaya dari dokumen.
Text embedding
-
OpenSearch text embedding service-001 (ops-text-embedding-001): Menyediakan penyematan teks multibahasa (40+). Panjang input maksimum adalah 300 token, dan dimensi vektor output adalah 1536.
-
OpenSearch general text embedding service-002 (ops-text-embedding-002): Menyediakan penyematan teks multibahasa (100+). Panjang input maksimum adalah 8.192 token, dan dimensi vektor output adalah 1024.
-
OpenSearch text embedding service-Chinese-001 (ops-text-embedding-zh-001): Menyediakan penyematan teks bahasa Tionghoa. Panjang input maksimum adalah 1.024 token, dan dimensi vektor output adalah 768.
-
OpenSearch text embedding service-English-001 (ops-text-embedding-en-001): Menyediakan penyematan teks bahasa Inggris. Panjang input maksimum adalah 512 token, dan dimensi vektor output adalah 768.
Sparse text embedding
Mengonversi data teks menjadi representasi vektor jarang. Vektor jarang menggunakan lebih sedikit penyimpanan dan sering digunakan untuk merepresentasikan kata kunci dan frekuensi istilah. Vektor ini dapat dikombinasikan dengan vektor padat untuk pencarian hibrid guna meningkatkan kinerja pengambilan.
OpenSearch sparse text embedding service (ops-text-sparse-embedding-001): Menyediakan penyematan teks jarang multibahasa (100+). Panjang input maksimum adalah 8.192 token.
Query analysis
Query analysis service 001 (ops-query-analyze-001): Layanan analisis kueri umum yang menggunakan model bahasa besar untuk memahami maksud kueri pengguna dan memperluasnya dengan pertanyaan serupa.
Search engine
-
Alibaba Cloud Elasticsearch: Layanan cloud terkelola penuh yang dibangun di atas Elasticsearch open-source. Layanan ini 100% kompatibel dengan fitur open-source dan menawarkan pengalaman siap pakai dengan model bayar sesuai penggunaan.
CatatanJika Anda memilih Alibaba Cloud Elasticsearch sebagai mesin pencari, layanan sparse text embedding tidak tersedia karena masalah kompatibilitas. Kami menyarankan menggunakan layanan text embedding sebagai gantinya.
-
OpenSearch Vector Search Edition: Mesin pencarian vektor terdistribusi berskala besar yang dikembangkan oleh Alibaba. Layanan ini mendukung berbagai algoritma pencarian vektor, memberikan kinerja unggul dengan presisi tinggi, serta memungkinkan pengindeksan dan pengambilan hemat biaya dalam skala besar. Indeksnya mendukung skalabilitas horizontal dan penggabungan, pembuatan streaming, kueri real-time, serta pembaruan data dinamis.
CatatanJika Anda perlu menggunakan OpenSearch Vector Search Edition, Anda dapat mengganti konfigurasi mesin dan kode dalam pipeline RAG.
Reranking service
BGE reranker model (ops-bge-reranker-larger): Layanan penilaian dokumen umum. Layanan ini mengurutkan dokumen berdasarkan relevansi antara kueri dan konten dokumen, mengurutkannya dari skor tertinggi ke terendah, serta mengeluarkan hasil penilaian tersebut.
Large language model
-
OpenSearch-Qwen-Turbo (ops-qwen-turbo): Dibangun di atas model bahasa besar Qwen-Turbo, layanan ini telah dilatih ulang dengan Supervised Learning untuk meningkatkan augmentasi pengambilan dan mengurangi respons berbahaya.
-
Qwen-Turbo (qwen-turbo): Model bahasa besar dari seri Qwen yang mendukung berbagai bahasa, termasuk Tionghoa dan Inggris. Untuk informasi selengkapnya, lihat Pengantar LLM seri Qwen.
-
Qwen-Plus (qwen-plus): Versi peningkatan dari model bahasa besar Qwen-Turbo yang mendukung berbagai bahasa, termasuk Tionghoa dan Inggris. Untuk informasi selengkapnya, lihat Pengantar LLM seri Qwen.
-
Qwen-Max (qwen-max): Model bahasa ultra-besar berskala triliunan parameter dari seri Qwen yang mendukung berbagai bahasa, termasuk Tionghoa dan Inggris. Untuk informasi selengkapnya, lihat Pengantar LLM seri Qwen.
-
-
Setelah memilih layanan Anda, klik After the configuration is completed, enter the code query untuk melihat dan mengunduh kode.
Kode tersebut terstruktur menjadi dua bagian yang mencerminkan alur waktu proses pipeline RAG: pemrosesan dokumen offline dan pencarian percakapan online.
Proses
Fungsi
Deskripsi
Offline document processing
Memproses dokumen, termasuk parsing, ekstraksi gambar, chunking, embedding, dan menulis hasil ke indeks Elasticsearch.
Fungsi utama
document_pipeline_executemenyelesaikan alur kerja berikut. Anda dapat memasukkan dokumen melalui URL atau encoding Base64.-
Document parsing. Untuk detail API, lihat Document Parsing API.
-
Panggil API parsing dokumen asinkron untuk mengekstraksi konten dari URL dokumen atau mendekode konten dari file berkode Base64.
-
Gunakan fungsi
create_async_extraction_taskuntuk membuat tugas parsing dan fungsipoll_task_resultuntuk memeriksa status penyelesaian tugas.
-
-
Image extraction. Untuk detail API, lihat Image Content Extraction API.
-
Panggil API parsing gambar asinkron untuk mengekstraksi konten dari URL gambar atau mendekodenya dari file berkode Base64.
-
Gunakan fungsi
create_image_analyze_taskuntuk membuat tugas parsing gambar dan fungsiget_image_analyze_task_statusuntuk mendapatkan statusnya.
-
-
Document chunking. Untuk detail API, lihat Document Chunking API.
-
Panggil API chunking dokumen untuk membagi dokumen yang telah diurai sesuai strategi tertentu.
-
Gunakan fungsi
document_splituntuk chunking dokumen dan parsing konten teks kaya.
-
-
Text embedding. Untuk detail API, lihat Text Embedding API.
-
Panggil API text embedding untuk membuat representasi vektor dari teks yang telah di-chunk.
-
Gunakan fungsi
text_embeddinguntuk menghitung vektor embedding setiap chunk.
-
-
Write to Elasticsearch. Untuk detail layanan, lihat Gunakan fitur pencarian k-nearest neighbor (kNN) Elasticsearch.
-
Buat konfigurasi indeks Elasticsearch yang menentukan bidang vektor
embeddingdan bidang konten dokumencontent.PentingSaat Anda membuat indeks Elasticsearch, indeks yang sudah ada dengan nama yang sama akan dihapus. Untuk menghindari kehilangan data secara tidak sengaja, ubah nama indeks dalam kode.
-
Gunakan fungsi
helpers.async_bulkuntuk menulis secara massal hasil vektorisasi ke indeks Elasticsearch.
-
Online conversational search
Memproses kueri pengguna online, termasuk menghasilkan vektor kueri, melakukan analisis kueri, mengambil chunk dokumen relevan, menyusun ulang hasil pencarian, dan menghasilkan jawaban akhir.
Fungsi utama
query_pipeline_executemenyelesaikan alur kerja berikut untuk memproses kueri pengguna dan mengembalikan jawaban.-
Vectorize the query. Untuk detail API, lihat Text Embedding API.
-
Panggil API text embedding untuk mengonversi kueri pengguna menjadi vektor.
-
Gunakan fungsi
text_embeddinguntuk menghasilkan vektor kueri.
-
-
Panggil layanan analisis kueri. Untuk detailnya, lihat Query Analysis API.
Layanan ini mengidentifikasi maksud pengguna dan menghasilkan pertanyaan serupa dengan menganalisis riwayat percakapan.
-
Search for embedding chunks. Untuk detail layanan, lihat Gunakan fitur pencarian k-nearest neighbor (kNN) Elasticsearch.
-
Gunakan Elasticsearch untuk mengambil chunk dokumen dari indeks yang mirip dengan vektor kueri.
-
Gunakan API
searchdariAsyncElasticsearchyang dikombinasikan dengan kueri kNN untuk melakukan pencarian kemiripan.
-
-
Panggil layanan reranking. Untuk detailnya, lihat Reranking API.
-
Panggil API layanan reranking untuk memberi skor dan mengurutkan chunk yang diambil.
-
Gunakan fungsi
documents_rankinguntuk memberi skor dan mengurutkan dokumen berdasarkan kueri pengguna.
-
-
Generate an answer with the large language model. Untuk detail API, lihat Answer Generation API.
Panggil layanan LLM, menggunakan fungsi
llm_calldengan hasil pengambilan dan kueri pengguna untuk menghasilkan jawaban akhir.
Di bawah Code Query, pilih Document processing flow dan Online Q & A Process, lalu klik Copy Code atau Download File untuk menyimpan kode secara lokal.
-
Langkah 2: Konfigurasikan dan uji pipeline
Setelah mengunduh kode ke dalam dua file lokal, seperti offline.py dan online.py, Anda perlu mengonfigurasi parameter kunci dalam kode.
|
Kategori |
Parameter |
Deskripsi |
|
AI Search Open Platform |
|
Kunci API untuk autentikasi. Untuk informasi selengkapnya, lihat Kelola kunci API. |
|
|
Titik akhir layanan untuk panggilan API. Untuk informasi selengkapnya, lihat Dapatkan titik akhir layanan. Catatan
Hapus awalan "http://" dari URL titik akhir. Panggilan API didukung melalui titik akhir publik maupun VPC. |
|
|
|
Nama ruang kerja Anda di AI Search Open Platform. |
|
|
|
ID layanan. Untuk kenyamanan, Anda dapat mengonfigurasi ID layanan untuk berbagai layanan di kedua file |
|
|
Elasticsearch search engine |
|
Titik akhir kluster Elasticsearch. Saat mengakses kluster melalui jaringan publik atau VPC, Anda harus menambahkan alamat IP perangkat Anda ke daftar putih alamat IP kluster. Untuk informasi selengkapnya, lihat Konfigurasikan daftar putih alamat IP publik atau privat untuk kluster Elasticsearch. |
|
|
Username dan password untuk mengakses kluster Elasticsearch. Username-nya adalah |
|
|
Parameter lainnya |
Tidak perlu modifikasi jika Anda menggunakan data sampel. |
|
Setelah mengonfigurasi parameter, jalankan skrip offline.py terlebih dahulu, diikuti skrip online.py, dalam lingkungan Python 3.7 atau lebih baru untuk menguji hasilnya.
Jika dokumen basis pengetahuan adalah Pengantar AI Search Open Platform, ajukan pertanyaan berikut: What can AI Search Open Platform do?
Anda seharusnya melihat output berikut:
-
Hasil pemrosesan dokumen offline
image analyze :https://img.alicdn.com/imgextra/i2/O1CN01bYc1m81RrcSAyOjMu_!!6000000002165-54-tps-60-60.apng https://img.alicdn.com/imgextra/i2/O1CN01bYc1m81RrcSAyOjMu_!!6000000002165-54-tps-60-60.apng is not analyzable. image analyze :https://help-static-aliyun-doc.aliyuncs.com/assets/img/zh-CN/3873436171/p802381.png image analyze :https://help-static-aliyun-doc.aliyuncs.com/assets/img/zh-CN/0650850271/p819277.png image analyze :https://help-static-aliyun-doc.aliyuncs.com/assets/img/zh-CN/0650850271/p819277.png image analyze ://gw.alicdn.com/tfs/TB1GxwdSXXXXXa.aXXXXXXXXXXX-65-70.gif https://gw.alicdn.com/tfs/TB1GxwdSXXXXXa.aXXXXXXXXXXX-65-70.gif is not analyzable. image analyze ://img.alicdn.com/tfs/TB1..50QpXXXX7XpXXXXXXXXXX-40-40.png image analyze :https://img.alicdn.com/tfs/TB1A0dINW6qK1RjSZFmXXX0PFXa-258-258.jpg image analyze ://gw.alicdn.com/tfs/TB1GxwdSXXXXXa.aXXXXXXXXXXX-65-70.gif https://gw.alicdn.com/tfs/TB1GxwdSXXXXXa.aXXXXXXXXXXX-65-70.gif is not analyzable. image analyze ://img.alicdn.com/tfs/TB1..50QpXXXX7XpXXXXXXXXXX-40-40.png image analyze ://gw.alicdn.com/tfs/TB1GxwdSXXXXXa.aXXXXXXXXXXX-65-70.gif https://gw.alicdn.com/tfs/TB1GxwdSXXXXXa.aXXXXXXXXXXX-65-70.gif is not analyzable. image analyze ://img.alicdn.com/tfs/TB1..50QpXXXX7XpXXXXXXXXXX-40-40.png text-embedding done OS write response: {"status":"OK","code":200} -
Hasil pencarian percakapan online
/opt/miniconda3/envs/QA-pytest-base-lib1/bin/python /Users/liu/codeRepos/QA-pytest-base-lib/rag/case/SDK/python_sdk_es_zx.py query analysis rewrite result:What can the OpenSearch AI Search Open Platform do? Final answer from the large model: AI Search Open Platform provides intelligent search services that power the core search functions for Alibaba's businesses, including Taobao and Tmall, and offers intelligent search solutions to external clients across various industries. It features industry-specific query semantic understanding and machine learning ranking algorithms to help developers build high-quality intelligent search services. The platform is suitable for a wide range of scenarios, including but not limited to: - E-commerce and retail intelligent search - Content and news search - Gaming industry search - Healthcare industry search - Financial industry search AI Search Open Platform focuses on intelligent search and Retrieval-Augmented Generation (RAG) scenarios, providing component-based services and flexible calling mechanisms. It has built-in services for document parsing, document chunking, text embedding, retrieval, reranking, and large language models, enabling a one-stop, flexible development experience for AI search applications. Process finished with exit code 0 -
File kode sumber
FAQ
Saat eksekusi kode, Anda mungkin melihat pesan "Unclosed connector" karena sumber daya belum dilepas tepat waktu. Anda dapat mengabaikan pesan ini dengan aman.