Manajemen state secara langsung memengaruhi kinerja, stabilitas, dan pemanfaatan sumber daya di Realtime Compute for Apache Flink. Ketika ukuran state melebihi kapasitas memori yang tersedia, backend status akan memindahkan data yang jarang diakses ke disk. Akses ke disk jauh lebih lambat dibandingkan akses ke memori, sehingga menyebabkan lonjakan latensi yang menyebar sebagai backpressure sepanjang pipeline. Jika tidak dikendalikan, kondisi ini dapat menyebabkan deployment crash.
Diagnosis backpressure terkait state
Backpressure merupakan indikator utama bottleneck kinerja di Apache Flink. Dalam sebagian besar kasus, backpressure terjadi karena ukuran state terus bertambah hingga melebihi memori yang dialokasikan. Backend status memindahkan data state yang jarang digunakan ke disk, dan jika suatu operator sering membaca state dari disk, latensi data meningkat signifikan—menciptakan bottleneck kinerja.
Untuk menentukan apakah backpressure disebabkan oleh state yang besar, analisis status berjalan deployment beserta operator-operatornya. Untuk detail selengkapnya, lihat Diagnostic tools.
Metode penyetelan
Tetapkan nilai TTL yang tepat untuk mengontrol ukuran state
Mengubah TTL deployment dari 0 menjadi nilai lebih besar dari 0, atau sebaliknya, menyebabkan masalah kompatibilitas dan memunculkan error StateMigrationException.
Konfigurasikan parameter State Expiration Time pada halaman Deployments di Konsol pengembangan Realtime Compute for Apache Flink. Untuk detail selengkapnya, lihat Parameters.
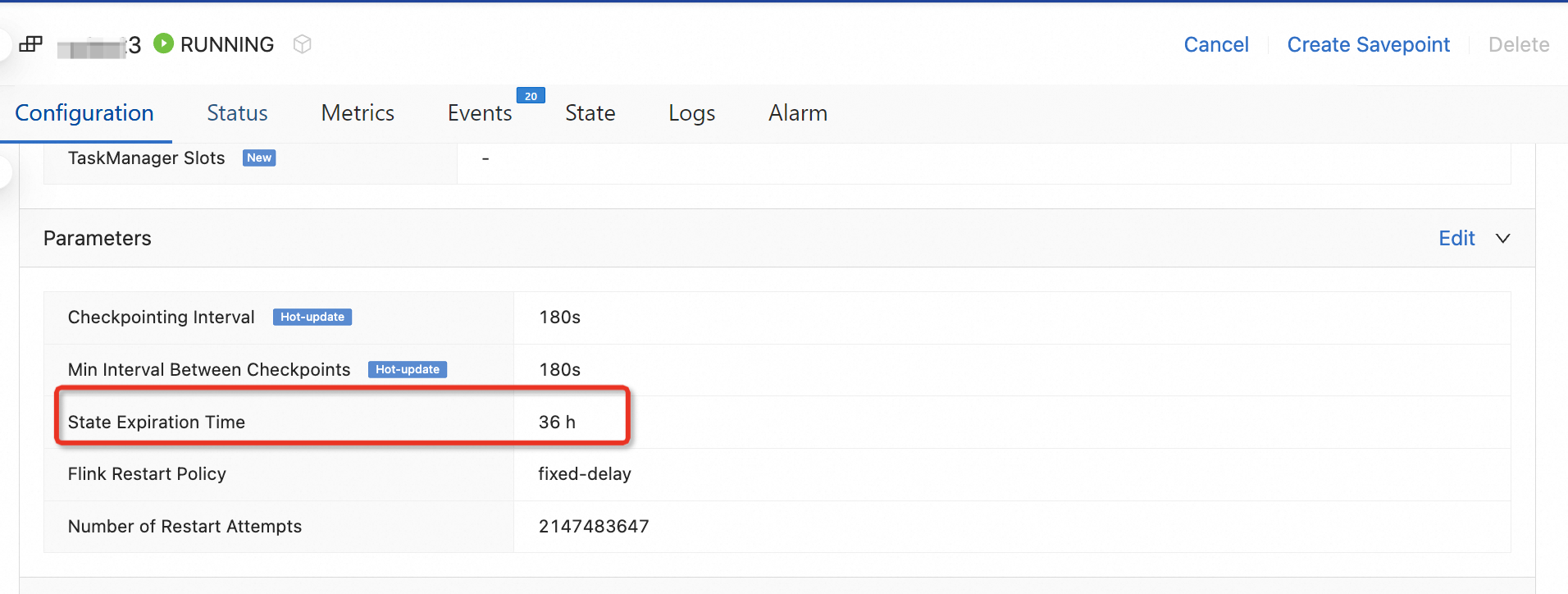
TTL yang terlalu pendek dapat menghasilkan perhitungan yang salah. Misalnya, jika data tiba terlambat dan state terkait telah kedaluwarsa selama agregasi atau join, hasilnya menjadi tidak akurat. Sebaliknya, TTL yang terlalu panjang meningkatkan konsumsi sumber daya dan mengurangi stabilitas. Tetapkan TTL berdasarkan karakteristik data dan kebutuhan bisnis. Sebagai contoh, jika komputasi harian memiliki deviasi maksimum 1 jam antar hari, atur TTL menjadi 25 jam.
TTL per-stream dengan JOIN_STATE_TTL (VVR 8.0.1+)
VVR 8.0.1 dan versi setelahnya memungkinkan penggunaan hint JOIN_STATE_TTL untuk menetapkan nilai TTL berbeda pada stream kiri dan kanan dalam regular join. Hal ini mengurangi penyimpanan state yang tidak perlu dan meningkatkan kinerja. Untuk detail sintaksis, lihat Query hints.
SELECT /*+ JOIN_STATE_TTL('left_table' = '..', 'right_table' = '..') */ *
FROM left_table [LEFT | RIGHT | INNER] JOIN right_table ON ...Tabel berikut menunjukkan dampak penggunaan JOIN_STATE_TTL pada deployment nyata:
| Item | Rincian Penyebaran | Ukuran state |
|---|---|---|
| Sebelum | Stream kiri memiliki volume data 20 hingga 50 kali lebih besar daripada stream kanan. TTL stream kanan diatur menjadi 10 hari (seharusnya 18 hari) demi menjaga kinerja, sehingga mengorbankan keakuratan data. Ukuran state sekitar 5,8 TB. Deployment mengonsumsi hingga 700 CU. | 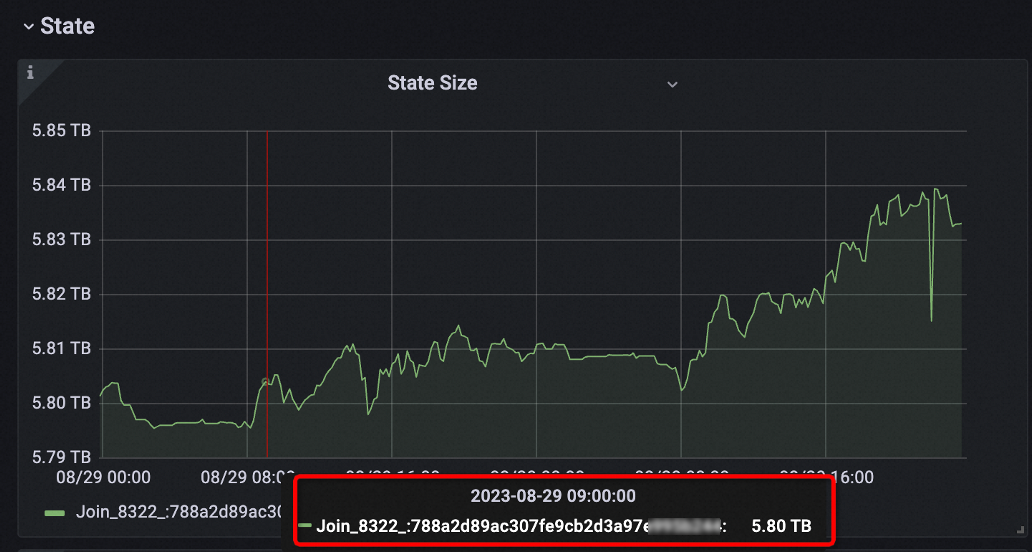 |
| Setelah | JOIN_STATE_TTL mengatur TTL stream kiri menjadi 12 jam dan TTL stream kanan menjadi 18 hari, sehingga menjamin integritas data. Ukuran state turun menjadi sekitar 590 GB—sepuluh persen dari ukuran awal. Deployment hanya mengonsumsi 200 hingga 300 CU, menghemat 50% hingga 70% resource. | 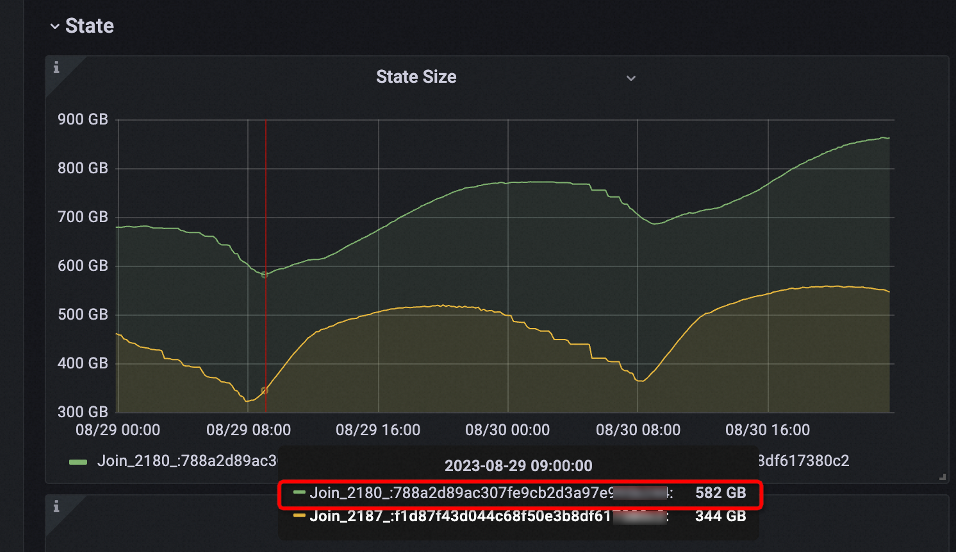 |
Hapus operator stateful yang tidak diperlukan
Metode ini hanya berlaku untuk operator yang diturunkan oleh pengoptimal. Operator yang dipanggil melalui SQL umumnya diperlukan oleh logika kueri itu sendiri.
ChangelogNormalize
Operator ini dipanggil dalam sebagian besar skenario yang melibatkan tabel sumber upsert, kecuali untuk temporal join berbasis event time. Sebelum menggunakan konektor Upsert Kafka atau konektor serupa, pastikan tidak ada temporal join yang dilakukan berdasarkan event time. Pantau metrik terkait state dari operator ChangelogNormalize saat runtime. Jika tabel sumber memiliki banyak primary key, ukuran state akan bertambah karena operator tersebut memelihara keyed state. Pembaruan primary key yang sering juga meningkatkan frekuensi akses dan modifikasi state.
Hindari penggunaan konektor Upsert Kafka untuk skenario sinkronisasi data. Gunakan alat sinkronisasi data yang menjamin pemrosesan exactly-once sebagai gantinya.
SinkUpsertMaterializer
Secara default, parameter table.exec.sink.upsert-materialize diatur ke auto. Artinya, sistem secara otomatis menambahkan operator SinkUpsertMaterializer untuk menjamin kebenaran dalam skenario tertentu, seperti catatan changelog yang tidak terurut. Kehadiran operator ini tidak selalu berarti catatan tidak terurut. Misalnya, ketika mengelompokkan data berdasarkan beberapa kunci lalu menggabungkannya ke dalam satu kolom, pengoptimal tidak dapat menurunkan upsert key secara akurat, sehingga menambahkan operator ini sebagai langkah pengaman.
Jika pola distribusi data sudah dipahami dengan baik dan hasil akhir tetap benar tanpa operator ini, atur table.exec.sink.upsert-materialize ke none untuk meningkatkan kinerja.
Periksa apakah SinkUpsertMaterializer aktif di Konsol pengembangan Realtime Compute for Apache Flink. Jika ada, operator ini akan muncul berantai dengan operator Sink dalam diagram topologi:
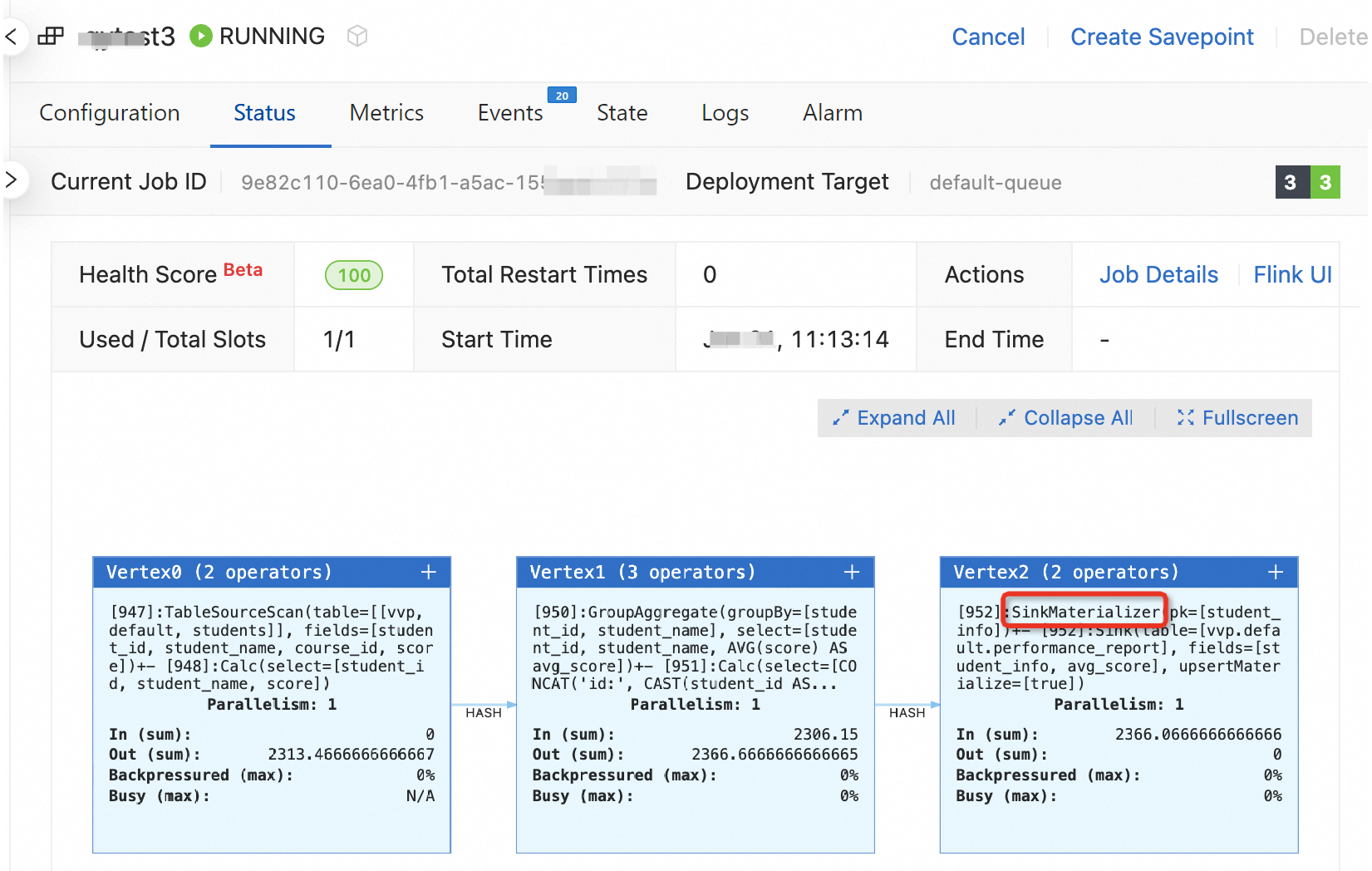
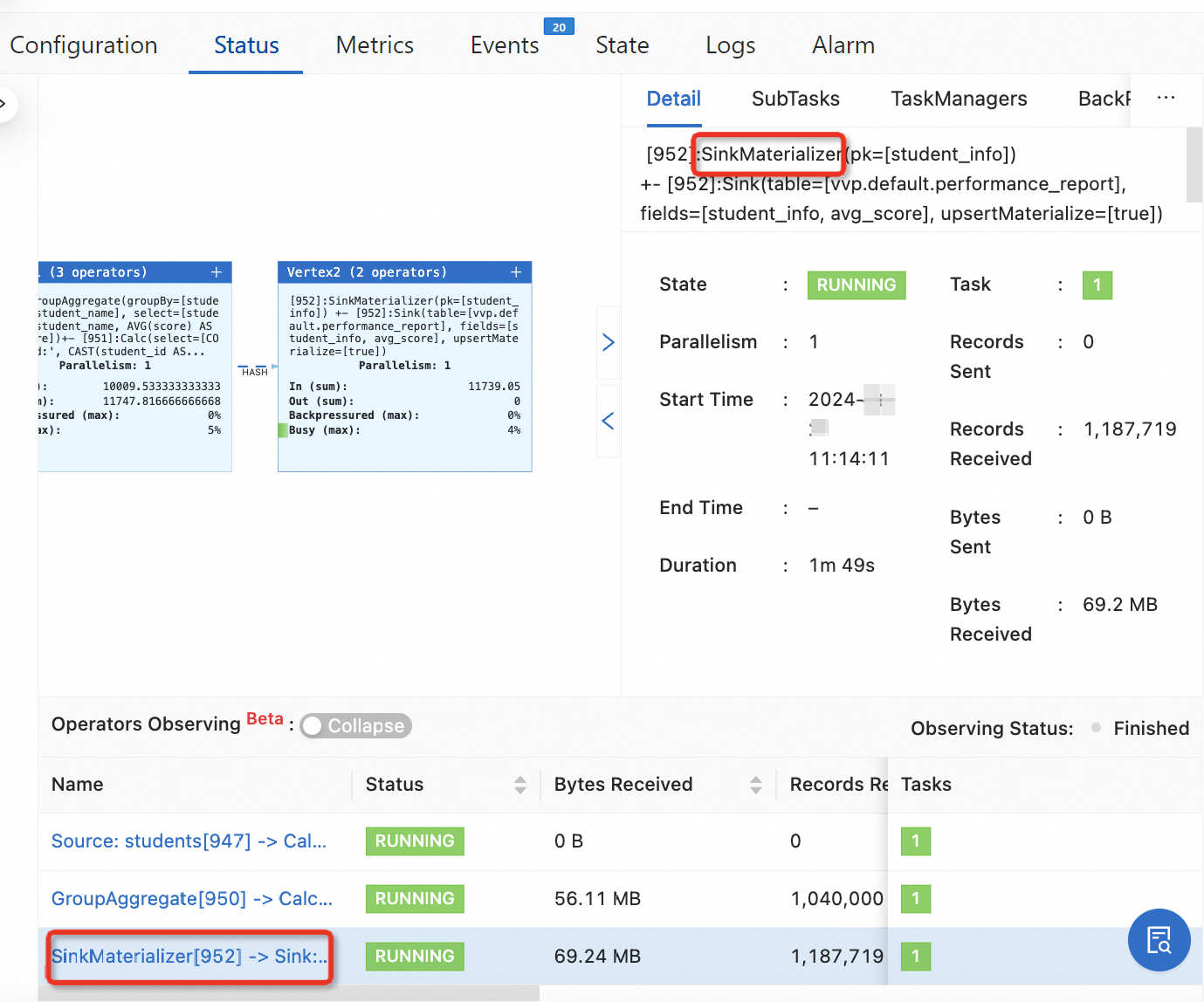
Jika operator SinkUpsertMaterializer tidak diperlukan dan hasil komputasi tetap benar, tambahkan 'table.exec.sink.upsert-materialize'='none' untuk mencegah penggunaan yang tidak perlu. Untuk petunjuk konfigurasi, lihat How do I configure parameters for deployment running?.
Ververica Runtime (VVR) 8.0 dan versi setelahnya mendukung analisis cerdas terhadap rencana eksekusi SQL untuk membantu mengidentifikasi masalah semacam ini:
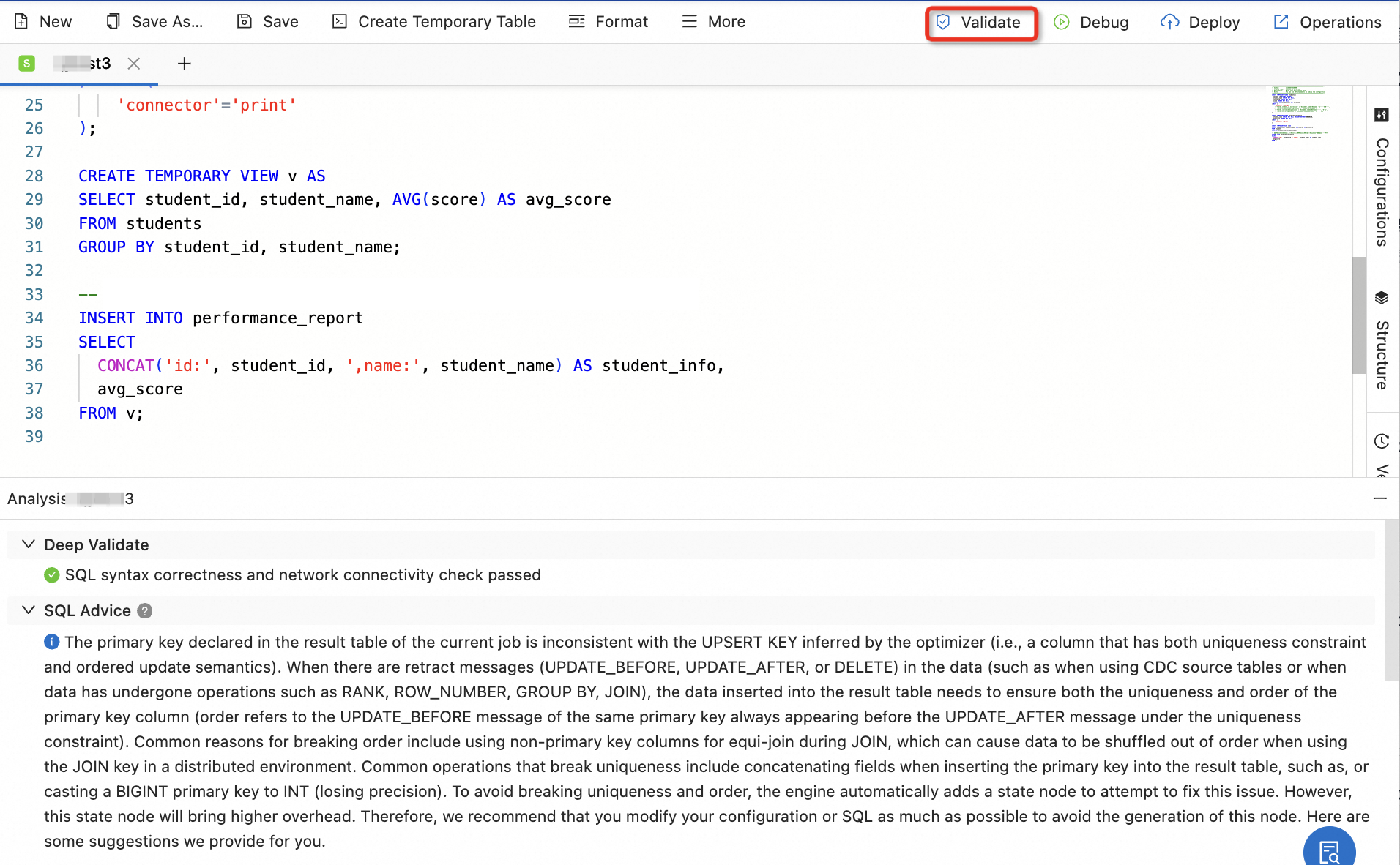
Kurangi frekuensi akses state dengan miniBatch
Jika latensi tingkat menit dapat diterima, aktifkan miniBatch untuk mengurangi frekuensi akses dan pembaruan state. Untuk detail selengkapnya, lihat Enable miniBatch to improve throughput.
Operator berikut mendukung miniBatch di Realtime Compute for Apache Flink:
| Nama operator | Deskripsi |
|---|---|
| ChangelogNormalize | N/A |
| Deduplicate | Konfigurasikan table.exec.deduplicate.mini-batch.compact-changes-enable untuk mengompaksi changelog selama deduplikasi berbasis event time. |
| GroupAggregate / GlobalGroupAggregate / IncrementalGroupAggregate | N/A |
| RegularJoin | Konfigurasikan table.exec.stream.join.mini-batch-enabled untuk mengaktifkan miniBatch pada operasi join. Parameter ini berlaku untuk stream update dan skenario outer join. |
Optimalkan rencana eksekusi
Pengoptimal memilih implementasi state dan menghasilkan rencana eksekusi berdasarkan pernyataan SQL dan konfigurasi. Penyesuaian berikut dapat secara signifikan mengurangi ukuran state.
Gunakan primary key dalam regular join
Jika kunci gabungan (join keys) berisi primary key, sistem menggunakan objek
ValueState<RowData>untuk menyimpan hanya nilai terbaru per kunci gabungan. Ini memaksimalkan efisiensi penyimpanan.Jika kunci gabungan berisi non-primary key, sistem menggunakan objek
MapState<RowData, RowData>untuk menyimpan catatan terbaru dari tabel sumber per primary key untuk setiap kunci gabungan.Jika tidak ada primary key yang didefinisikan, sistem menggunakan objek
MapState<RowData, Integer>untuk menyimpan seluruh catatan data untuk setiap kunci gabungan beserta jumlah kemunculannya.
Definisikan primary key dalam pernyataan DDL dan lakukan regular join pada primary key untuk mengoptimalkan efisiensi penyimpanan.
Gunakan ROW_NUMBER untuk deduplikasi pada stream append-only
Gunakan fungsi ROW_NUMBER alih-alih FIRST_VALUE atau LAST_VALUE untuk deduplikasi. Dengan ROW_NUMBER, operator Deduplicate hanya menyimpan catatan pertama atau terbaru per kunci, bukan mempertahankan seluruh state yang diperlukan oleh fungsi agregasi.
Gunakan sintaksis FILTER untuk agregasi multi-dimensi
Gunakan sintaksis FILTER alih-alih CASE WHEN untuk agregasi multi-dimensi—misalnya, menghitung jumlah pengunjung unik di perangkat mobile, desktop, dan semua perangkat. Pengoptimal SQL mengenali argumen filter berbeda pada kunci yang sama dan membagikan data state di antara beberapa komputasi COUNT DISTINCT. Hal ini mengurangi jumlah akses state. Pengujian menunjukkan bahwa sintaksis FILTER dapat memberikan kinerja dua kali lipat dibandingkan sintaksis CASE WHEN.
Sesuaikan urutan join untuk join multi-stream
Apache Flink menggunakan binary hash join untuk memproses stream data. Saat melakukan join pada beberapa stream, redundansi state meningkat secara eksponensial dengan setiap join tambahan.
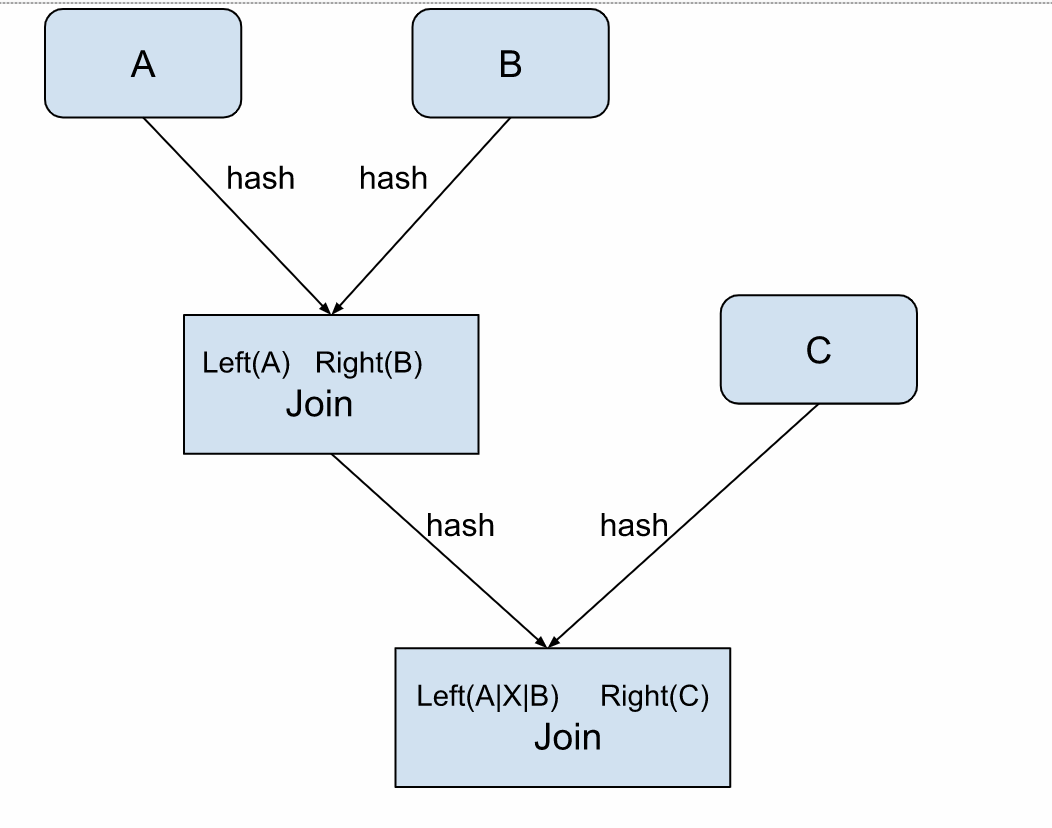
Lakukan join stream yang lebih kecil terlebih dahulu sebelum stream yang lebih besar untuk mengurangi efek amplifikasi dari redundansi state dan meningkatkan efisiensi pemrosesan.
Minimalkan pembacaan disk
Kurangi akses penyimpanan disk untuk meningkatkan kinerja sistem dan mengoptimalkan pemanfaatan memori. Untuk teknik spesifik, lihat Minimize disk reads.
Referensi operator stateful
Flink SQL mengandalkan mekanisme state backend dan checkpointing Apache Flink untuk menjamin konsistensi akhir hasil komputasi. Pengoptimal memilih operator stateful berdasarkan pernyataan SQL dan parameter konfigurasi Anda. Memahami operator mana yang memelihara state—dan bagaimana cara membersihkannya—sangat penting untuk menyetel deployment dengan state besar.
Operator stateful terbagi menjadi dua kategori:
Operator turunan pengoptimal — ditambahkan secara otomatis oleh pengoptimal berdasarkan struktur SQL dan konfigurasi
Operator yang dipanggil SQL — dipicu langsung oleh sintaksis pernyataan SQL (agregasi, join, deduplikasi, windowing)
Operator turunan pengoptimal
Pengoptimal dapat memperkenalkan operator stateful berikut. Ketiganya menggunakan TTL (Time-to-live) untuk pembersihan state.
| Nama operator | Mekanisme pembersihan state |
|---|---|
| ChangelogNormalize | Time-to-live (TTL) |
| SinkUpsertMaterializer | |
| LookupJoin (*) |
ChangelogNormalize
Operator ChangelogNormalize memproses changelog yang melibatkan primary key dan menjamin efisiensi, konsistensi data, serta akurasi data. Operator ini digunakan dalam dua skenario:
Skenario 1: Tabel sumber memiliki primary key dan mendukung operasi UPSERT.
Jenis tabel ini dikenal sebagai tabel sumber upsert. Tabel ini menghasilkan stream changelog yang hanya berisi operasi UPDATE (INSERT dan UPDATE_AFTER) dan DELETE pada primary key, sekaligus mempertahankan urutan primary key. Sebagai contoh, konektor Upsert Kafka membuat tabel sumber upsert. Konektor sumber kustom juga dapat mendukung operasi UPSERT dengan meng-override metode getChangelogMode:
@Override
public ChangelogMode getChangelogMode() {
return ChangelogMode.upsert();
}Skenario 2: Konfigurasi 'table.exec.source.cdc-events-duplicate' = 'true' ditentukan.
Pemrosesan at-least-once untuk Change Data Capture (CDC) dapat menghasilkan catatan changelog duplikat. Untuk mencapai pemrosesan exactly-once, tentukan konfigurasi ini untuk menghapus duplikat. Diagram berikut mengilustrasikan skenario ini:

Dalam contoh ini, data masukan di-hash-shuffle berdasarkan primary key yang didefinisikan dalam pernyataan DDL tabel sumber. Operator ChangelogNormalize membuat objek ValueState untuk menyimpan catatan terbaru untuk setiap primary key. Gambar berikut menunjukkan bagaimana operator memperbarui state-nya dan menghasilkan output. Ketika catatan kedua -U(2, 'Jerry', 77) tiba, nilai yang sesuai yang disimpan dalam state kosong. Artinya, jumlah perubahan ADD (+I dan +UA) sama dengan jumlah perubahan RETRACT (-D dan -UB) untuk primary key 2. Catatan duplikat tersebut dibuang.

SinkUpsertMaterializer
Operator SinkUpsertMaterializer menjamin bahwa materialisasi data sesuai dengan semantik upsert ketika tabel sink memiliki primary key. Selama pemrosesan stream, jika keunikan dan urutan catatan data terganggu sebelum ditulis ke tabel sink, pengoptimal secara otomatis menambahkan operator ini. Operator ini memelihara state berdasarkan primary key tabel sink. Untuk skenario terkait, lihat Handle out-of-order changelog events in Flink SQL.
LookupJoin
Ketika konfigurasi 'table.optimizer.non-deterministic-update.strategy'='TRY_RESOLVE' diterapkan pada lookup join dan pengoptimal mengidentifikasi potensi pembaruan non-deterministik (lihat How to eliminate the impact of non-deterministic update in streaming), sistem mencoba menyelesaikan masalah tersebut dengan menambahkan operator LookupJoin.
Contoh skenario:
Primary key tabel sink tumpang tindih sebagian atau sepenuhnya dengan kunci tabel dimensi, dan tabel dimensi diperbarui melalui CDC atau alat lain.
Join melibatkan bidang non-primary-key di tabel dimensi.
Dalam kedua skenario tersebut, operator LookupJoin menangani perubahan data dinamis sekaligus menjaga akurasi dan konsistensi kueri.
Operator yang dipanggil SQL
Operator ini dipicu langsung oleh sintaksis pernyataan SQL. Operator ini membersihkan state berdasarkan TTL atau progres watermark.
Operator berbasis window (WindowAggregate, WindowDeduplicate, WindowJoin, WindowTopN) membersihkan state-nya berdasarkan progres watermark. Ketika timestamp watermark melebihi waktu akhir window, timer bawaan memicu pembersihan state.
| Nama operator | Memanggil metode | Pembersihan state |
|---|---|---|
| Deduplicate | Gunakan fungsi ROW_NUMBER, tentukan bidang atribut waktu dalam klausa ORDER BY, dan ambil hanya baris pertama. Atribut waktu dapat berupa event time atau processing time. | TTL |
| RegularJoin | Gunakan klausa JOIN di mana kondisi kesetaraan tidak melibatkan bidang atribut waktu. | TTL |
| GroupAggregate | Gunakan klausa GROUP BY dengan fungsi agregasi (SUM, COUNT, MIN, MAX, FIRST_VALUE, LAST_VALUE) atau kata kunci DISTINCT. | TTL |
| GlobalGroupAggregate | Aktifkan agregasi lokal-global. | TTL |
| IncrementalGroupAggregate | Gunakan kueri agregasi grup dua tingkat dan aktifkan agregasi lokal-global. Operator GlobalGroupAggregate dan LocalGroupAggregate digabung menjadi operator IncrementalGroupAggregate. | TTL |
| Rank | Gunakan fungsi ROW_NUMBER tanpa bidang atribut waktu dalam klausa ORDER BY. | TTL |
| GlobalRank | Gunakan fungsi ROW_NUMBER tanpa bidang atribut waktu dalam klausa ORDER BY, dan aktifkan agregasi lokal-global. | TTL |
| IntervalJoin | Gunakan klausa JOIN dengan kondisi atribut waktu (event time atau processing time). Contoh: L.time between R.time + X and R.time + Y atau R.time between L.time - Y and L.time - X | watermark |
| TemporalJoin | Lakukan inner join atau left join berdasarkan event time. | watermark |
| WindowDeduplicate | Gunakan fungsi bernilai tabel (TVF) window untuk deduplikasi. | watermark |
| WindowAggregate | Gunakan TVF window untuk agregasi. | watermark |
| GlobalWindowAggregate | Gunakan TVF window untuk agregasi dan aktifkan agregasi lokal-global. | watermark |
| WindowJoin | Gunakan TVF window untuk join. | watermark |
| WindowRank | Gunakan TVF window untuk sorting. | watermark |
| GroupWindowAggregate | Gunakan sintaksis lama agregasi window. | watermark |
Referensi
Performance tuning for large-state deployments — membahas isu yang disebabkan oleh state besar dan alur kerja penyetelan.
Control state size to reduce backpressure using the DataStream API — manajemen state fleksibel dengan DataStream API.
Diagnose and prevent checkpoint and savepoint timeout — identifikasi dan atasi masalah timeout checkpoint/savepoint.
Improve startup and scaling speed — hilangkan bottleneck kinerja selama startup dan scaling deployment.