Manajemen status memengaruhi performa, stabilitas, dan pemanfaatan sumber daya. Manajemen yang tidak tepat dapat menyebabkan sistem crash. Datastream API memungkinkan pengelolaan ukuran status secara fleksibel. Topik ini menjelaskan cara mengontrol ukuran status pada deployment yang dibangun dengan Datastream API.
Informasi latar belakang
Apache Flink mendukung dua jenis status: operator state dan keyed state. Penggunaan keyed state lebih cenderung menghasilkan ukuran status yang besar. Untuk mengatasi masalah ini, Anda dapat menggunakan DataStream API, seperti antarmuka ValueState, ListState, dan MapState, untuk mengelola keyed state. Anda juga dapat mengonfigurasi waktu hidup status (TTL) agar data status kadaluwarsa. Untuk informasi lebih lanjut, lihat Menggunakan Keyed State.
Alat diagnostik
Tekanan balik adalah indikator hambatan performa dalam Apache Flink. Dalam banyak kasus, tekanan balik terjadi karena ukuran status terus bertambah dan melebihi memori yang dialokasikan. Dalam situasi ini, backend status memindahkan data jarang digunakan ke penyimpanan disk. Namun, akses ke disk jauh lebih lambat daripada akses ke memori. Jika operator sering membaca data dari disk, latensi akan meningkat secara signifikan, mengakibatkan hambatan performa.
Untuk mengidentifikasi apakah tekanan balik disebabkan oleh ukuran status yang besar, analisis status operasi deployment dan operator secara menyeluruh. Gunakan pemantauan dan alat diagnostik untuk mengidentifikasi serta menyelesaikan masalah performa akibat akses status.
Tabel berikut menjelaskan alat diagnostik pada konsol pengembangan Realtime Compute for Apache Flink. Alat-alat ini dapat digunakan bersama fitur diagnostik penyebaran cerdas dan penyetelan otomatis untuk memfasilitasi penyetelan performa deployment berstatus besar.
Alat | Deskripsi | Penggunaan |
Thread dumps | Periksa apakah utas operator utamanya mengakses data status pada waktu saat ini. | |
Aktivitas thread | Periksa apakah utas operator utamanya mengakses data status selama periode tertentu. | |
Grafik flame | Periksa apakah sebagian besar waktu CPU digunakan untuk mengakses data status dalam periode tertentu. | |
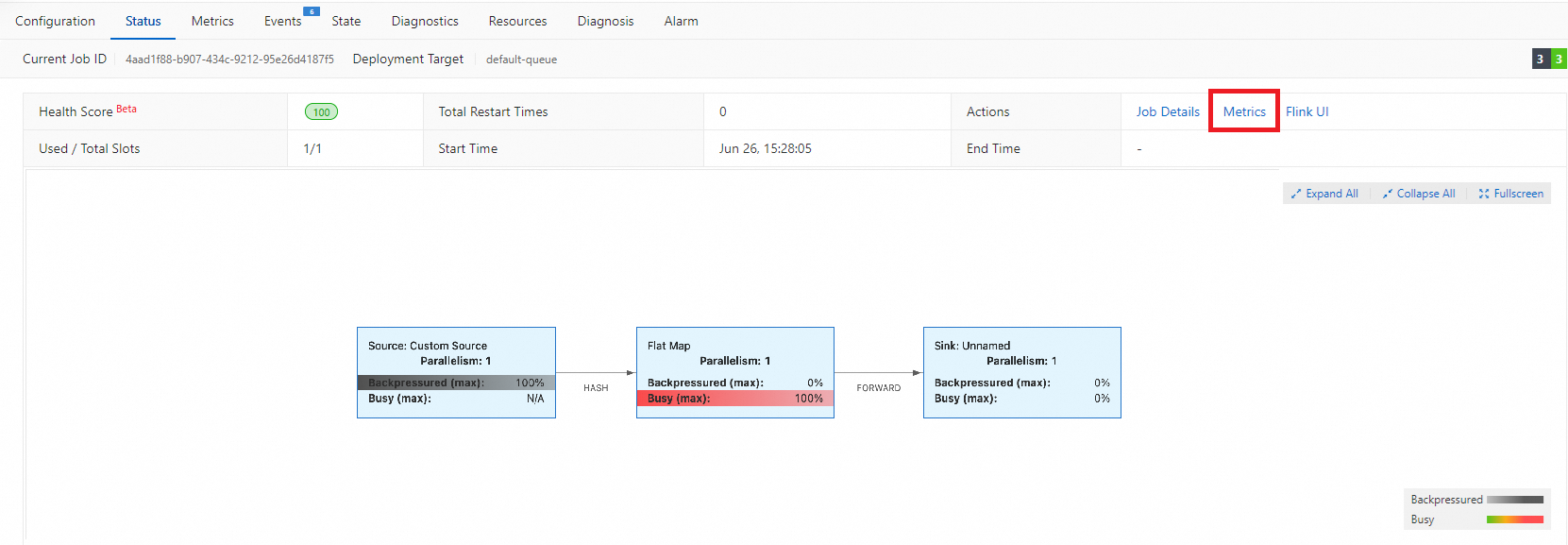
Pemantauan metrik runtime | Lihat metrik terkait untuk memeriksa ukuran status dan overhead I/O. | Klik deployment yang ingin Anda lihat di halaman Deployments, klik tab Status, lalu klik Metrics di bagian Actions.
Anda dapat melihat metrik berikut:
|
Metode penyetelan
Evaluasi ulang desain aplikasi Anda
Desain penyimpanan dan manajemen status dalam aplikasi sangat penting. Untuk mencegah pertumbuhan status tak terbatas, simpan hanya informasi yang diperlukan di status.
Konfigurasikan TTL untuk mengurangi ukuran status
Apache Flink menyediakan metode untuk membantu Anda mengelola siklus hidup data status. Misalnya, panggil metode setTTL() dari antarmuka ValueStateDescriptor untuk membuat dan membersihkan data status yang kedaluwarsa secara otomatis. Anda juga dapat memanggil metode clear() dan remove() untuk menghapus data status yang tidak lagi diperlukan, sehingga membantu mengontrol ukuran status.
Gunakan timer untuk pembersihan status
Anda dapat menggunakan timer untuk memicu pembersihan status secara berkala. Ini memastikan bahwa data status yang kedaluwarsa dihapus tepat waktu dan mencegah pertumbuhan status tak terbatas. Selain itu, Anda dapat mengelola siklus hidup data status secara halus.
Pantau performa, hasilkan log, dan analisis file status
Pantau metrik performa terkait ukuran status dan backend status untuk mendeteksi anomali secara tepat waktu. Hasilkan log rinci untuk memfasilitasi pemecahan masalah. Secara rutin analisis file status historis untuk mengidentifikasi pola dan risiko potensial, lalu gunakan informasi tersebut untuk mengoptimalkan manajemen status.
Minimalkan pembacaan disk
Kurangi jumlah pembacaan disk dan optimalkan alokasi memori untuk meningkatkan performa sistem.
Optimalkan Alokasi Memori
Alokasikan lebih banyak sumber daya ke memori terkelola tanpa memengaruhi total sumber daya sistem. Ini meningkatkan pemanfaatan memori secara efektif, sehingga mengurangi akses ke disk. Sebelum menggunakan metode ini, pastikan bahwa sumber daya memori cukup untuk bagian lain dari sistem.
Tambahkan Sumber Daya Memori
Tambahkan sumber daya memori dan alokasikan lebih banyak memori terkelola ke mesin penyimpanan status. Ini meningkatkan pemanfaatan memori dan mengurangi akses ke disk. Anda dapat menggunakan metode ini dalam mode ahli konfigurasi sumber daya untuk mencapai alokasi sumber daya halus dan performa optimal.
Tingkatkan Paralelisme
Paralelisme yang lebih tinggi menghasilkan ukuran status yang lebih kecil untuk setiap subtask, sehingga mengurangi jumlah data yang ditulis ke disk. Metode ini secara efektif mengurangi operasi I/O disk dan meningkatkan efisiensi pemrosesan data.
Tabel berikut menjelaskan cara menggunakan metode di atas dalam skenario berbeda.
Skenario | Metode | Operasi | Perhatian |
Sumber daya memori lainnya, seperti memori heap, cukup | Alokasikan lebih banyak sumber daya ke memori terkelola. | Konfigurasikan parameter | Pastikan bahwa sumber daya memori lainnya cukup. Jika tidak, pengumpulan sampah penuh (Full GC) mungkin sering terjadi, yang menurunkan performa. |
Semua skenario | Tambahkan sumber daya memori. | Tidak ada | |
Tingkatkan paralelisme. |
Referensi
Untuk informasi tentang masalah yang disebabkan oleh ukuran status besar dan alur kerja penyetelan, lihat Penyetelan Performa untuk Deployment Berstatus Besar.
Flink SQL menggunakan pengoptimal untuk memilih operator stateful berdasarkan konfigurasi parameter dan pernyataan SQL. Pemahaman dasar tentang mekanisme yang mendasarinya diperlukan untuk mengoptimalkan performa komputasi stateful pada data masif. Untuk informasi lebih lanjut, lihat Kontrol Ukuran Status untuk Mengurangi Tekanan Balik dalam Deployment SQL.
Untuk informasi tentang cara mendiagnosis dan mencegah timeout checkpoint dan savepoint, lihat Diagnosis dan Pencegahan Timeout Checkpoint dan Savepoint.
Untuk informasi tentang cara mengidentifikasi dan menghilangkan hambatan performa selama startup dan penskalaan deployment, lihat Tingkatkan Kecepatan Startup dan Penskalaan.