Saat menggunakan Flink SQL untuk pemrosesan data real-time, event changelog yang tidak berurutan dapat merusak hasil secara diam-diam—catatan dihapus padahal seharusnya tetap ada, atau pembaruan diterapkan dalam urutan yang salah. Topik ini menjelaskan penyebab ketidakteraturan event, cara SinkUpsertMaterializer mengatasinya, serta cara menyetel atau menghindari operator tersebut ketika kinerja menjadi pertimbangan utama.
Konsep utama
Changelog dan jenis aliran
Pada database relasional seperti MySQL, binary log (binlog) mencatat setiap operasi INSERT, UPDATE, dan DELETE. Flink SQL menggunakan mekanisme serupa yang disebut changelog untuk melacak perubahan data dan memungkinkan pemrosesan inkremental di seluruh pipeline streaming.
Aliran changelog termasuk dalam salah satu dari dua kategori berikut:
| Jenis aliran | Jenis event | Deskripsi |
|---|---|---|
| Append-only stream | +I only | Hanya berisi event INSERT. Tidak ada pembaruan atau penghapusan. Disebut juga aliran non-update. |
| Update stream | +I, +U, -U, -D | Berisi event pembaruan atau penghapusan selain insert. Operator seperti agregasi grup dan deduplikasi menghasilkan jenis ini. |
Tidak semua operator dapat mengonsumsi update stream. Operator agregasi over dan interval join hanya menerima append-only stream sebagai input.
Jenis event changelog
Flink SQL menggunakan empat jenis event, berdasarkan enum RowKind dalam API Apache Flink:
| Nama singkat | Nama lengkap | Semantik |
|---|---|---|
+I |
INSERT | Menyisipkan baris baru. |
-U |
UPDATE_BEFORE | Membatalkan konten sebelumnya dari baris yang diperbarui. Selalu dipasangkan dengan event +U. |
+U |
UPDATE_AFTER | Berisi konten baru dari baris yang diperbarui. Selalu dipasangkan dengan event -U. |
-D |
DELETE | Menghapus sebuah baris. |
Flink mempertahankan UPDATE_BEFORE (-U) dan UPDATE_AFTER (+U) sebagai jenis event terpisah, bukan menggabungkannya menjadi satu event UPDATE komposit, karena dua alasan:
-
Struktur seragam: Kedua event memiliki struktur baris yang sama, hanya dibedakan oleh properti
RowKind. Jenis event komposit akan memerlukan struktur heterogen atau penyelarasan khusus antara event INSERT dan DELETE. -
Pengacakan terdistribusi: Dalam pipeline paralel, operasi join dan agregasi melakukan pengacakan data di antara tugas. Event UPDATE komposit tetap harus dipisah menjadi event terpisah selama pengacakan agar tetap akurat—sehingga mempertahankannya terpisah sejak awal menyederhanakan model.
Bagaimana event tidak berurutan terjadi
Pertimbangkan contoh berikut, yang digunakan sepanjang topik ini untuk mengilustrasikan masalah dan solusinya:
-- Tabel sumber CDC
CREATE TEMPORARY TABLE s1 (
id BIGINT,
level BIGINT,
PRIMARY KEY(id) NOT ENFORCED
) WITH (...);
CREATE TEMPORARY TABLE s2 (
id BIGINT,
attr VARCHAR,
PRIMARY KEY(id) NOT ENFORCED
) WITH (...);
-- Tabel sink
CREATE TEMPORARY TABLE t1 (
id BIGINT,
level BIGINT,
attr VARCHAR,
PRIMARY KEY(id) NOT ENFORCED
) WITH (...);
-- Join s1 dan s2 lalu tulis hasilnya ke t1
INSERT INTO t1
SELECT s1.*, s2.attr
FROM s1 JOIN s2
ON s1.level = s2.id;Ketika catatan (id=1, level=10) pada tabel s1 disisipkan pada waktu t0 lalu diperbarui menjadi (id=1, level=20) pada waktu t1, tiga event changelog dihasilkan:
| Event | Jenis |
|---|---|
+I (id=1, level=10) |
INSERT |
-U (id=1, level=10) |
UPDATE_BEFORE |
+U (id=1, level=20) |
UPDATE_AFTER |
Kunci primer s1 adalah id, tetapi klausa JOIN melakukan pengacakan data berdasarkan kolom level. Dengan paralelisme operator Join sebesar 2, ketiga event tersebut dapat diarahkan ke dua tugas berbeda—satu menangani level=10 dan lainnya menangani level=20.
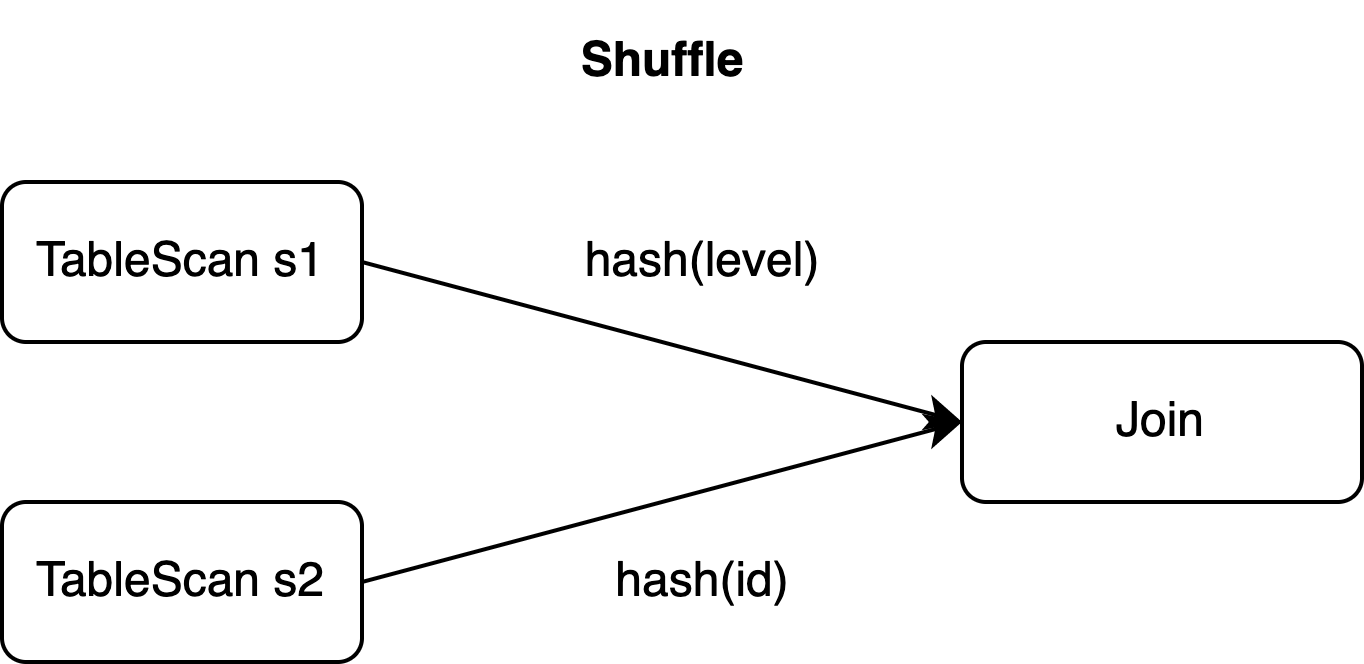
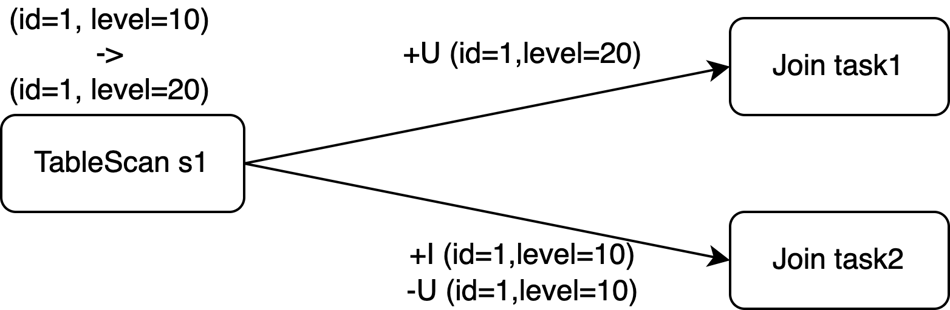
Karena event diproses secara paralel, operator Sink downstream dapat menerimanya dalam salah satu dari tiga urutan berikut:
| Kasus 1 (urutan benar) | Kasus 2 (tidak berurutan) | Kasus 3 (tidak berurutan) |
|---|---|---|
+I (id=1, level=10, attr='a1') |
+U (id=1, level=20, attr='b1') |
+I (id=1, level=10, attr='a1') |
-U (id=1, level=10, attr='a1') |
+I (id=1, level=10, attr='a1') |
+U (id=1, level=20, attr='b1') |
+U (id=1, level=20, attr='b1') |
-U (id=1, level=10, attr='a1') |
-U (id=1, level=10, attr='a1') |
Kasus 1 memproses event dalam urutan aslinya—tidak ada masalah. Pada Kasus 2 dan Kasus 3, tabel sink memiliki id sebagai kunci primernya. Jika penyimpanan eksternal melakukan upsert, catatan dengan id=1 berakhir dihapus, meskipun keadaan akhir yang diharapkan adalah (id=1, level=20, attr='b1').
Event tidak berurutan hanya terjadi ketika paralelisme operator Join lebih besar dari 1. Sepasang event dengan kunci upsert yang sama selalu diarahkan ke tugas yang sama, sehingga hanya tiga kemungkinan urutan yang muncul dalam skenario ini.
SinkUpsertMaterializer
Cara kerjanya
SinkUpsertMaterializer adalah operator perantara yang disisipkan Flink untuk menyelesaikan masalah pengurutan. Operator ini diperkenalkan untuk mengatasi FLINK-20374.
Untuk memahami mengapa SinkUpsertMaterializer diperlukan, penting memahami upsert key. upsert key adalah kolom (atau kumpulan kolom) yang mempertahankan urutan sortir kunci unik melalui operasi SQL. Ketika upsert key tersedia, operator downstream menerima event pembaruan dalam urutan yang benar. Namun, ketika operasi pengacakan data memutus urutan kunci unik—seperti JOIN berdasarkan level dalam contoh ini—upsert key menjadi kosong.
Dalam contoh ini, baris dari s1 diacak berdasarkan level, sehingga output Join berisi baris dengan nilai s1.id yang sama tetapi dalam urutan acak. Kunci uniknya adalah (s1.id), (s1.id, s1.level), dan (s1.id, s2.id), tetapi upsert key-nya kosong. Selain itu, kunci primer tabel sink (id) tidak sesuai dengan upsert key pada output Join. SinkUpsertMaterializer menjembatani kesenjangan ini.
Event changelog yang tidak berurutan mengikuti aturan tertentu: untuk kunci upsert tertentu (atau untuk semua kolom jika upsert key kosong), event ADD (+I dan +U) selalu terjadi sebelum event RETRACT (-D dan -U) yang bersesuaian. Sepasang event changelog dengan kunci upsert yang sama diproses oleh tugas yang sama meskipun terjadi pengacakan data. Jaminan pengurutan inilah yang diandalkan SinkUpsertMaterializer untuk merekonstruksi hasil yang benar.
Operator ini bekerja sebagai berikut:
-
Memelihara daftar nilai
RowDatadalam state, dengan kunci berdasarkan upsert key yang disimpulkan (atau seluruh baris jika upsert key kosong). -
Pada event ADD (
+Iatau+U): menambahkan atau memperbarui baris dalam state. -
Pada event RETRACT (
-Uatau-D): menghapus baris dari state. -
Menghasilkan event changelog yang benar berdasarkan kunci primer tabel sink.
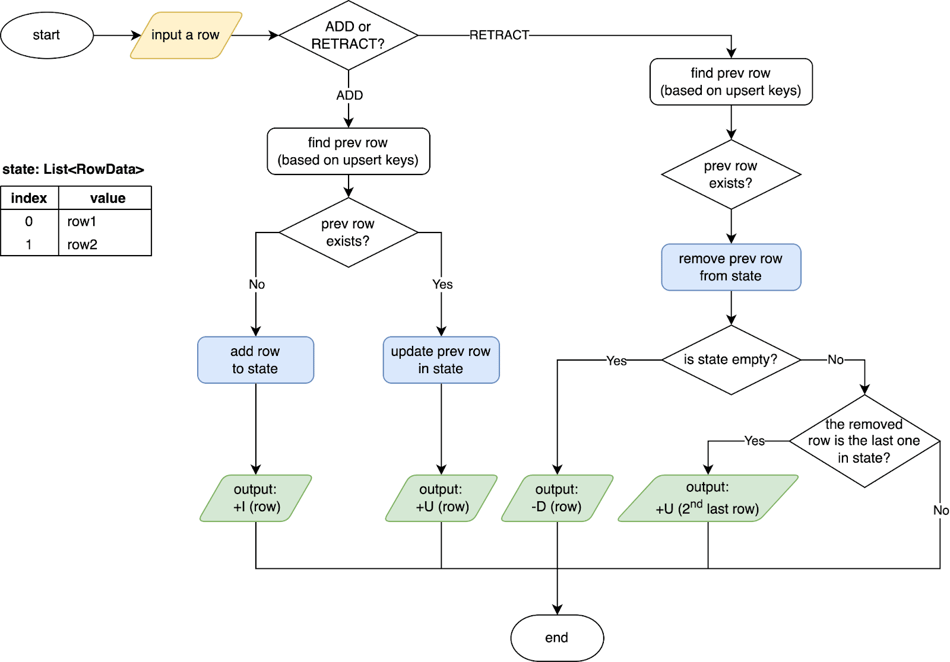
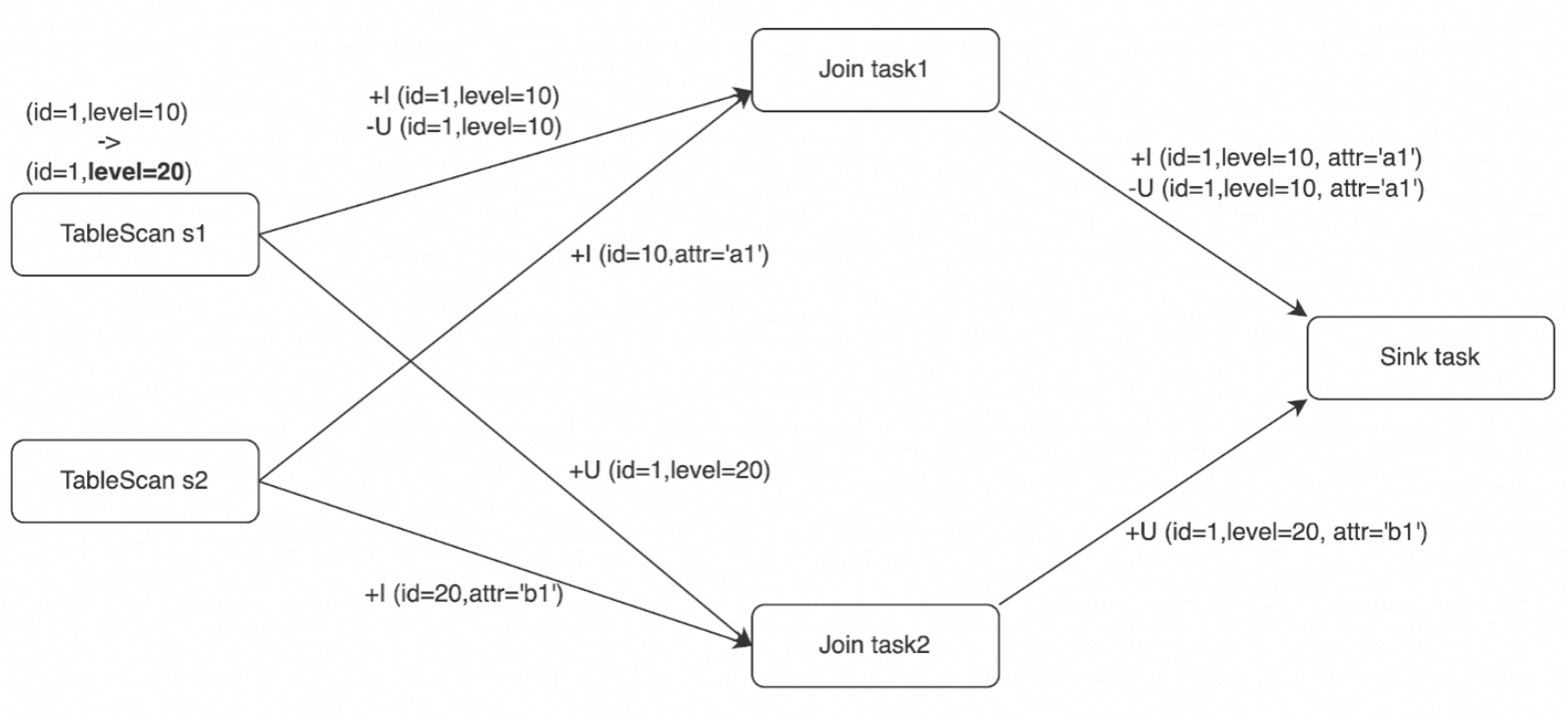
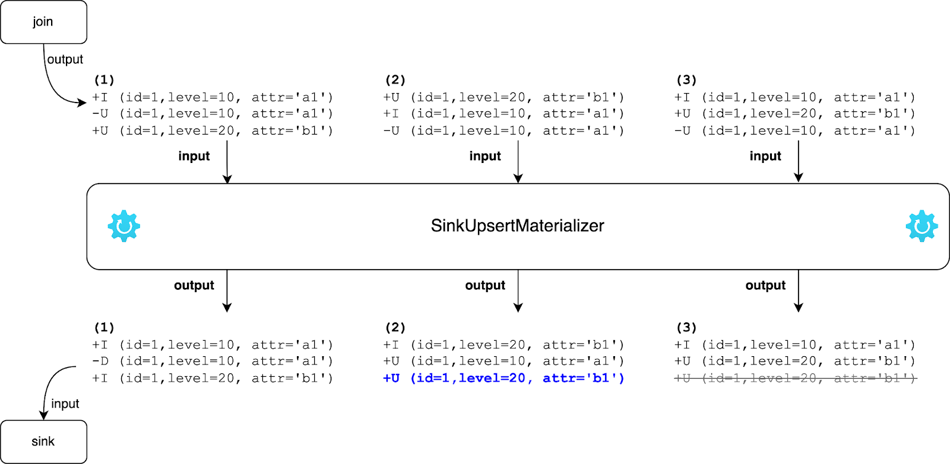
Diagram berikut menunjukkan bagaimana SinkUpsertMaterializer menangani Kasus 2 dan 3 dari contoh di atas:
-
Kasus 2: Ketika
-U (id=1, level=10, attr='a1')tiba paling akhir, SinkUpsertMaterializer menghapus baris tersebut dari state dan menghasilkan event UPDATE berdasarkan baris kedua dari akhir. Hasil akhirnya adalah(id=1, level=20, attr='b1'). -
Kasus 3: Ketika
+U (id=1, level=20, attr='b1')tiba, operator meneruskannya ke downstream. Ketika-U (id=1, level=10, attr='a1')tiba kemudian, operator menghapus baris yang sesuai dari state tanpa mengeluarkan event. Hasil akhirnya tetap(id=1, level=20, attr='b1').
Untuk kode sumbernya, lihat SinkUpsertMaterializer (Flink release-1.17).
Kapan SinkUpsertMaterializer dipicu
Flink menambahkan operator SinkUpsertMaterializer dalam skenario berikut:
-
Tabel sink memiliki kunci primer tetapi data masuk tidak memenuhi kendala UNIK. Penyebab umum meliputi:
-
Menentukan kunci primer pada tabel sink saat tabel sumber tidak memiliki kunci primer.
-
Mengecualikan kolom kunci primer sumber saat menulis ke sink, atau memetakan kolom non-kunci-primer sumber ke kunci primer sink.
-
Mengurangi presisi kolom kunci primer melalui konversi tipe atau agregasi grup (misalnya, casting dari BIGINT ke INT).
-
Transformasi kolom kunci primer, seperti menggabungkan beberapa kolom menjadi satu:
CREATE TABLE students ( student_id BIGINT NOT NULL, student_name STRING NOT NULL, course_id BIGINT NOT NULL, score DOUBLE NOT NULL, PRIMARY KEY(student_id) NOT ENFORCED ) WITH (...); CREATE TABLE performance_report ( student_info STRING NOT NULL PRIMARY KEY NOT ENFORCED, avg_score DOUBLE NOT NULL ) WITH (...); CREATE TEMPORARY VIEW v AS SELECT student_id, student_name, AVG(score) AS avg_score FROM students GROUP BY student_id, student_name; -- Hasil penggabungan tidak lagi memenuhi kendala UNIK -- tetapi digunakan sebagai kunci primer tabel sink. INSERT INTO performance_report SELECT CONCAT('id:', student_id, ',name:', student_name) AS student_info, avg_score FROM v;
-
-
Operasi pengacakan data mengganggu urutan sortir kunci unik sebelum menulis ke tabel sink. Ini adalah skenario dalam contoh join di atas: JOIN berdasarkan
levelmengacak baris dari s1, sehingga memutus urutan sortir kunci primerid. -
Parameter
table.exec.sink.upsert-materializediatur keforce.
Konfigurasi SinkUpsertMaterializer
Gunakan parameter table.exec.sink.upsert-materialize untuk mengontrol kapan Flink menambahkan operator SinkUpsertMaterializer:
| Nilai | Perilaku |
|---|---|
auto (default) |
Flink memprediksi apakah event tidak berurutan mungkin terjadi dan menambahkan operator jika diperlukan. |
none |
Menonaktifkan operator sepenuhnya. |
force |
Selalu menambahkan operator, bahkan ketika tidak ada kunci primer yang ditentukan pada tabel sink. |
Mengaturautotidak menjamin bahwa event benar-benar tidak berurutan. Misalnya, penggunaan klausaGROUPING SETSdenganCOALESCEuntuk mengonversi nilai null dapat mencegah planner SQL menentukan apakah upsert key sesuai dengan kunci primer sink. Dalam kasus tersebut, Flink menambahkan SinkUpsertMaterializer sebagai tindakan pencegahan. Jika hasil sudah benar tanpa operator tersebut, aturtable.exec.sink.upsert-materializekenone.
Untuk informasi tentang operasi kueri yang didukung dalam Realtime Compute for Apache Flink yang menggunakan Ververica Runtime (VVR) 6.0 atau lebih baru, operator runtime yang sesuai, serta dukungan update stream, lihat Eksekusi kueri.
Catatan kinerja dan operasional
SinkUpsertMaterializer memelihara state untuk setiap baris yang diproses. Hal ini meningkatkan ukuran state dan menambahkan overhead I/O untuk pembacaan dan penulisan state, sehingga mengurangi throughput. Hindari penggunaan operator ini bila memungkinkan.
Hindari pemicuan SinkUpsertMaterializer
-
Buat kunci partisi yang digunakan untuk deduplikasi atau agregasi grup sesuai dengan kunci primer tabel sink.
-
Jika paralelisme tunggal sesuai dengan dataset Anda dan Anda ingin menghindari event tidak berurutan, atur paralelisme ke 1 dan nonaktifkan SinkUpsertMaterializer dengan mengatur
table.exec.sink.upsert-materializekenone. -
Jika rantai operator ada antara operator Sink dan operator stateful upstream (seperti operator deduplikasi atau agregasi grup), dan tidak terjadi masalah akurasi data dengan versi VVR sebelum 6.0, migrasikan penerapan ke VVR 6.0 atau lebih baru. Atur
table.exec.sink.upsert-materializekenonedan pertahankan konfigurasi lainnya tanpa perubahan. Untuk langkah migrasi, lihat Tingkatkan versi engine penerapan.
Kapan Anda harus menggunakan SinkUpsertMaterializer
-
Jangan menulis kolom yang dihasilkan oleh fungsi non-deterministik (seperti
CURRENT_TIMESTAMPatauNOW()) ke tabel sink. Saat upsert key tidak tersedia, SinkUpsertMaterializer membandingkan seluruh baris, dan nilai non-deterministik mencegah pencocokan dan penghapusan baris historis, sehingga state terus bertambah tanpa batas. -
Jika state operator tumbuh cukup besar hingga memengaruhi kinerja, tingkatkan paralelisme penerapan. Lihat Konfigurasi sumber daya untuk penerapan.
Isu yang diketahui
SinkUpsertMaterializer dapat menyebabkan pertumbuhan state tanpa batas dalam situasi berikut:
-
Tidak ada TTL state, TTL terlalu panjang, atau TTL terlalu pendek: Tanpa Waktu hidup (TTL) yang dikonfigurasi, state terakumulasi tanpa henti. TTL yang terlalu pendek juga dapat menimbulkan masalah: jika interval antara event DELETE dan event ADD yang bersesuaian melebihi TTL yang dikonfigurasi, Flink menyimpan baris dalam state sebagai data kotor (lihat FLINK-29225) dan menghasilkan pesan log berikut:
int index = findremoveFirst(values, row); if (index == -1) { LOG.info(STATE_CLEARED_WARN_MSG); return; }Konfigurasikan TTL berdasarkan kebutuhan bisnis Anda. Lihat Konfigurasi penerapan. Realtime Compute for Apache Flink dengan VVR 8.0.7 atau lebih baru mendukung konfigurasi TTL per-operator untuk mengurangi konsumsi sumber daya pada penerapan dengan state besar. Lihat Konfigurasi paralelisme, strategi chaining, dan TTL operator.
-
Kolom non-deterministik tanpa upsert key: Jika update stream yang tiba di SinkUpsertMaterializer tidak memiliki upsert key yang dapat disimpulkan dan mencakup kolom dari fungsi non-deterministik, baris historis tidak dapat dicocokkan berdasarkan nilai dan tidak pernah dihapus, sehingga state terus bertambah.
Langkah selanjutnya
-
Catatan rilis — Pemetaan versi engine antara Realtime Compute for Apache Flink dan Apache Flink
-
Eksekusi kueri — Operasi kueri yang didukung dan dukungan update stream untuk VVR 6.0 dan lebih baru
-
Konfigurasi sumber daya untuk penerapan — Tingkatkan paralelisme untuk menangani state SinkUpsertMaterializer yang besar