Topik ini menjelaskan parameter kunci untuk pengembangan SQL serta memberikan penjelasan dan contoh penggunaannya.
table.exec.sink.keyed-shuffle
Untuk mengatasi masalah out-of-order saat menulis data ke tabel dengan primary key, Anda dapat menggunakan parameter table.exec.sink.keyed-shuffle untuk melakukan hash shuffle. Operasi ini memastikan bahwa catatan (record) dengan primary key yang sama diarahkan ke instans operator yang sama, sehingga mengurangi masalah out-of-order.
Catatan penggunaan
-
Operasi hash shuffle hanya efektif jika operator hulu (upstream) dapat menjamin urutan catatan pembaruan (update records) untuk primary key yang sama. Jika tidak, operasi ini tidak dapat menyelesaikan masalah out-of-order.
-
Jika Anda mengubah parallelism suatu operator dalam mode expert, aturan parallelism berikut tidak berlaku.
Nilai yang tersedia
-
AUTO (default): Jika parallelism sink bukan 1 dan berbeda dari parallelism operator hulu, Flink secara otomatis melakukan hash shuffle pada primary key saat data mengalir ke sink.
-
FORCE: Jika parallelism sink bukan 1, Flink memaksa hash shuffle pada primary key saat data mengalir ke sink.
-
NONE: Flink tidak melakukan hash shuffle berdasarkan parallelism sink dan operator hulu.
Contoh
-
Atur parameter ke AUTO
-
Buat Pekerjaan streaming SQL, salin kode SQL berikut, lalu deploy pekerjaan tersebut. Kode ini secara eksplisit mengatur parallelism sink menjadi 2.
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts TIMESTAMP(3) ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.ts.kind'='random','fields.ts.max-past'='5s', 'fields.b.kind'='random','fields.b.min'='0','fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a INT, b INT, ts TIMESTAMP(3), PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='print', --Anda dapat langsung menentukan parallelism sink dengan menggunakan parameter sink.parallelism. 'sink.parallelism'='2' ); INSERT INTO sink SELECT * FROM s1; --Anda juga dapat menentukan parallelism sink dengan menggunakan opsi tabel dinamis. --INSERT INTO sink /*+ OPTIONS('sink.parallelism' = '2') */ SELECT * FROM s1; -
Pada halaman Job O&M, di tab Deployment Details, pada bagian Resource Configuration, atur Parallelism menjadi 1. Di bagian Running Parameter Configuration di bawah Other Configurations, jangan atur parameter
table.exec.sink.keyed-shuffleatau tambahkan secara eksplisittable.exec.sink.keyed-shuffle: AUTO(keduanya memiliki efek yang sama). -
Start pekerjaan tersebut. Di tab Status, koneksi data dari operator hulu ke sink adalah HASH.
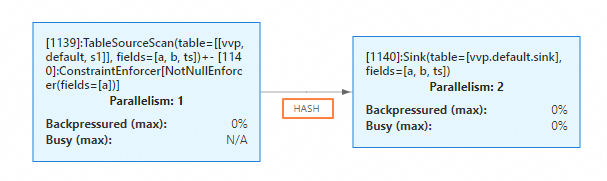
-
-
Atur parameter ke FORCE
-
Buat Pekerjaan streaming SQL, salin kode SQL berikut, lalu deploy pekerjaan tersebut. Kode ini tidak secara eksplisit menentukan parallelism sink.
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts TIMESTAMP(3) ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.ts.kind'='random','fields.ts.max-past'='5s', 'fields.b.kind'='random','fields.b.min'='0','fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a INT, b INT, ts TIMESTAMP(3), PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='print' ); INSERT INTO sink SELECT * FROM s1; -
Di bagian Resource Configuration pada tab Deployment Details halaman Job O&M, atur Parallelism menjadi 2. Di bagian Runtime Parameter Configuration, tambahkan
table.exec.sink.keyed-shuffle: FORCEke Other Configurations. -
Setelah Anda start pekerjaan tersebut, buka tab Status. Parallelism untuk sink dan operator hulu keduanya bernilai 2, dan koneksi data telah berubah menjadi HASH.
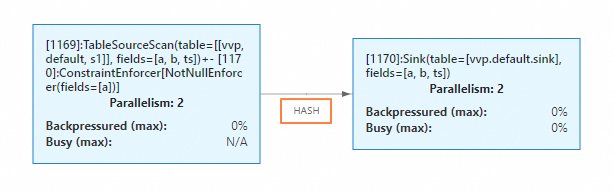
-
table.exec.mini-batch.size
Parameter ini mengontrol jumlah maksimum catatan yang dapat dibuffer untuk operasi micro-batch. Ketika jumlah ini tercapai, sistem akan memicu komputasi dan mengeluarkan data. Parameter ini hanya berlaku jika digunakan bersama dengan table.exec.mini-batch.enabled dan table.exec.mini-batch.allow-latency. Untuk informasi lebih lanjut tentang optimasi MiniBatch, lihat MiniBatch Aggregation dan MiniBatch Regular Joins.
Catatan penggunaan
Sebelum pekerjaan dimulai, jika Anda tidak secara eksplisit mengatur parameter ini di bagian Parameters, managed memory digunakan untuk mem-buffer data dalam mode mini-batch. Salah satu kondisi berikut akan memicu komputasi akhir dan output data:
-
Pesan watermark diterima dari operator MiniBatchAssigner.
-
Managed memory penuh.
-
Sebelum checkpoint dimulai.
-
Pekerjaan dihentikan.
Nilai yang tersedia
-
-1 (default): Menunjukkan bahwa managed memory digunakan untuk mem-buffer data.
-
Nilai Long negatif lainnya: Sama seperti pengaturan default.
-
Nilai Long positif lainnya: Menunjukkan bahwa heap memory digunakan untuk mem-buffer data. Saat jumlah catatan yang dibuffer mencapai nilai ini (N), sistem secara otomatis memicu operasi output.
Contoh
-
Buat Pekerjaan streaming SQL, salin kode SQL berikut, lalu deploy pekerjaan tersebut.
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts TIMESTAMP(3), PRIMARY KEY (a) NOT ENFORCED, WATERMARK FOR ts AS ts - INTERVAL '1' SECOND ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.ts.kind'='random', 'fields.ts.max-past'='5s', 'fields.b.kind'='random', 'fields.b.min'='0', 'fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a INT, b BIGINT, PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='print' ); INSERT INTO sink SELECT a, sum(b) FROM s1 GROUP BY a; -
Di tab Deployment Details halaman Job O&M, di field Other Configurations bagian Runtime Parameter Configuration, atur parameter
table.exec.mini-batch.enabled: truedantable.exec.mini-batch.allow-latency: 2s, dan jangan aturtable.exec.mini-batch.sizeagar menggunakan nilai default -1. -
Start pekerjaan tersebut. Di tab Status, topologi pekerjaan mencakup operator MiniBatchAssigner, LocalGroupAggregate, dan GlobalGroupAggregate.
table.exec.agg.mini-batch.output-identical-enabled
Saat State TTL diaktifkan, node MinibatchGlobalAgg dan MinibatchAgg secara default tidak mengirim data duplikat ke hilir (downstream) jika hasil agregasi tidak berubah setelah data dikonsumsi. Hal ini dapat menyebabkan state node stateful di hilir kedaluwarsa karena tidak menerima data dari hulu dalam periode yang lama. Parameter ini mengontrol apakah data duplikat tetap dikirim ke hilir saat State TTL diaktifkan dan hasil agregasi tidak berubah. Anda dapat mengatur parameter ini ke true agar node MinibatchGlobalAgg dan MinibatchAgg mengirim data dalam kasus ini. Jika hasil agregasi pekerjaan Anda berubah lebih sering daripada TTL State yang dikonfigurasi, Anda tidak perlu mengatur parameter ini secara manual. Untuk detail mengenai isu komunitas, lihat FLINK-33936.
Catatan penggunaan
-
Parameter ini hanya berlaku di VVR 8.0.8 dan versi setelahnya. Di versi sebelum VVR 8.0.8, perilakunya setara dengan mengatur parameter ini ke false.
-
Saat mengubah nilai dari false ke true, jumlah data yang dikirim ke hilir dari operator MinibatchGlobalAgg dan MinibatchAgg dapat meningkat, sehingga memberikan tekanan lebih besar pada operator hilir.
Nilai yang tersedia
-
false (default): Saat state TTL diaktifkan, operator MinibatchGlobalAgg dan MinibatchAgg tidak mengeluarkan data ke hilir jika hasil agregasi tidak berubah.
-
true: Saat state TTL diaktifkan, operator MinibatchGlobalAgg dan MinibatchAgg tetap mengeluarkan catatan (record) terbaru (duplikat) ke hilir meskipun hasil agregasi tidak berubah.
Contoh
-
Buat Pekerjaan streaming SQL, salin kode SQL berikut, lalu deploy pekerjaan tersebut.
create temporary table src( a int, b string ) with ( 'connector' = 'datagen', 'rows-per-second' = '10', 'fields.a.min' = '1', 'fields.a.max' = '1', 'fields.b.length' = '3' ); create temporary table snk( a int, max_length_b bigint ) with ( 'connector' = 'blackhole' ); insert into snk select a, max(CHAR_LENGTH(b)) from src group by a; -
Di bagian Other Configurations area Runtime Parameter Configuration pada tab Deployment Details halaman Job O&M, atur parameter
table.exec.mini-batch.enabled: truedantable.exec.mini-batch.allow-latency: 2suntuk mengaktifkan optimasi Minibatch Aggregate. -
Start pekerjaan tersebut. Di tab Status, pekerjaan mencakup operator MinibatchGlobalAggregate. Klik tanda "+" pada operator tersebut untuk melihat bahwa operator GlobalGroupAggregate tidak mengirim data ke hilir saat hasil agregasi tidak berubah.
Operator tersebut menampilkan RecordsIn sebesar 19 dan RecordsOut sebesar 1, yang berarti 19 catatan input hanya menghasilkan 1 output agregat.
-
Hentikan pekerjaan tersebut, lalu tambahkan parameter
table.exec.agg.mini-batch.output-identical-enabled: trueke Other Configurations di bagian Running Parameter Configuration pada halaman Deployment Details halaman Job O&M. -
Start pekerjaan tersebut. Di tab Status, Anda dapat melihat pekerjaan mencakup operator MinibatchGlobalAggregate. Klik tanda "+" pada operator tersebut untuk mengamati bahwa operator GlobalGroupAggregate kini mengirim data ke hilir meskipun hasil agregasi tidak berubah. Setelah pekerjaan dimulai ulang, tab Status menunjukkan bahwa RecordsIn dan RecordsOut operator GlobalGroupAggregate keduanya bernilai 94. Ini menunjukkan bahwa dengan
table.exec.agg.mini-batch.output-identical-enabled: truediaktifkan, operator tersebut mengirim data ke hilir meskipun hasil agregasi tidak berubah.
table.exec.async-lookup.key-ordered-enabled
Saat Anda menggunakan join tabel dimensi untuk penguatan data (data enrichment), mengaktifkan mode asinkron sering kali dapat meningkatkan throughput. Dalam join tabel dimensi, parameter table.exec.async-lookup.output-mode dan apakah input merupakan aliran pembaruan (update stream) menentukan urutan output operasi I/O asinkron.
|
Output mode |
Update stream |
Non-update stream |
|
ORDERED |
ordered mode |
ordered mode |
|
ALLOW_UNORDERED |
ordered mode |
unordered mode |
Seperti ditunjukkan dalam tabel, kombinasi update stream dan ALLOW_UNORDERED memastikan kebenaran dengan menggunakan ordered mode, tetapi mengorbankan sebagian throughput. Untuk mengoptimalkan skenario ini, diperkenalkan parameter table.exec.async-lookup.key-ordered-enabled. Parameter ini menyeimbangkan semantik kebenaran update stream dengan performa throughput I/O asinkron. Pesan dalam aliran yang memiliki kunci pembaruan (update key) yang sama (yang dapat dianggap sebagai primary key dari changelog) diproses sesuai urutan masuknya ke operator.
-
Ordered mode: Mode ini mempertahankan urutan aliran. Pesan hasil dikeluarkan dalam urutan yang sama dengan pemicuan permintaan asinkron (urutan pesan masuk ke operator).
-
Unordered mode: Pesan hasil dikeluarkan segera setelah permintaan asinkron selesai. Operator I/O asinkron mengubah urutan pesan dalam aliran. Untuk informasi lebih lanjut, lihat Asynchronous I/O | Apache Flink.
Kasus penggunaan
-
Gunakan optimasi ini untuk mempertahankan urutan pemrosesan per kunci dalam join tabel dimensi ketika aliran memiliki sedikit pesan dengan kunci pembaruan yang sama dalam periode waktu tertentu.
-
Dalam aliran Change Data Capture (CDC) dengan primary key, Anda melakukan penguatan data dengan join tabel dimensi dan menulis ke sink di mana primary key sink cocok dengan primary key sumber. Kunci gabungan (join key) untuk join tabel dimensi berbeda dari primary key, dan join key sisi dimensi adalah primary key. Optimasi ini melakukan shuffle berdasarkan primary key CDC, yang diturunkan sebagai kunci pembaruan (update key). Dibandingkan dengan mengaktifkan optimasi SHUFFLE_HASH untuk skenario yang sama, optimasi ini menghindari pembuatan operator SinkMaterializer sebelum sink pada parallelism yang lebih tinggi. Hal ini menghindari potensi masalah performa dari operator tersebut, terutama state besar yang dapat terakumulasi selama eksekusi jangka panjang. Untuk informasi tentang SinkUpsertMaterializer, lihat Rekomendasi.
-
Kunci gabungan (join key) untuk join tabel dimensi berbeda dari primary key, join key sisi dimensi adalah primary key, dan diikuti oleh operator rank. Optimasi ini melakukan shuffle berdasarkan primary key CDC, yang diturunkan sebagai kunci pembaruan (update key). Dibandingkan dengan mengaktifkan optimasi SHUFFLE_HASH untuk skenario yang sama, optimasi ini mencegah UpdateFastRank menurun menjadi RetractRank. Untuk informasi tentang cara mengoptimalkan RetractRank menjadi UpdateFastRank, lihat Teknik optimasi TopN.
Catatan penggunaan
-
Jika aliran tidak memiliki kunci pembaruan (update key), seluruh baris digunakan sebagai kunci.
-
Throughput menurun jika kunci pembaruan yang sama diperbarui secara sering dalam periode singkat, karena catatan untuk kunci pembaruan yang sama diproses dalam urutan yang ketat.
-
Dibandingkan dengan join tabel dimensi asinkron asli, mode Key-Ordered memperkenalkan keyed state. Mengaktifkan atau menonaktifkan mode ini memengaruhi kompatibilitas state.
-
Fitur ini hanya berlaku untuk VVR 8.0.10 dan versi setelahnya ketika input join tabel dimensi merupakan update stream dan Anda mengonfigurasi
table.exec.async-lookup.output-mode='ALLOW_UNORDERED'dantable.exec.async-lookup.key-ordered-enabled='true'.
Nilai yang tersedia
-
false (default): Menonaktifkan mode Key-Ordered.
-
true: Mengaktifkan mode Key-Ordered.
Contoh
-
Contoh berikut menggunakan join tabel dimensi Hologres asinkron. Buat Pekerjaan streaming SQL, salin kode SQL berikut, lalu deploy pekerjaan tersebut.
Untuk informasi lebih lanjut tentang konektor Hologres, lihat Hologres.
create TEMPORARY table bid_source( auction BIGINT, bidder BIGINT, price BIGINT, channel VARCHAR, url VARCHAR, dateTime TIMESTAMP(3), extra VARCHAR, proc_time as proctime(), WATERMARK FOR dateTime AS dateTime - INTERVAL '4' SECOND ) with ( 'connector' = 'kafka', -- Konektor aliran non-insert-only 'topic' = 'user_behavior', 'properties.bootstrap.servers' = 'localhost:9092', 'properties.group.id' = 'testGroup', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv' ); CREATE TEMPORARY TABLE users ( user_id STRING PRIMARY KEY NOT ENFORCED, -- Definisikan primary key user_name VARCHAR(255) NOT NULL, age INT NOT NULL ) WITH ( 'connector' = 'hologres', -- Konektor yang mendukung lookup asinkron 'async' = 'true', 'dbname' = 'holo db name', --Nama database Hologres Anda 'tablename' = 'schema_name.table_name', --Nama tabel Hologres yang menerima data 'username' = 'access id', --ID AccessKey Akun Alibaba Cloud Anda 'password' = 'access key', --Secret AccessKey Akun Alibaba Cloud Anda 'endpoint' = 'holo vpc endpoint', --Titik akhir VPC instans Hologres Anda ); CREATE TEMPORARY TABLE bh ( auction BIGINT, age int ) WITH ( 'connector' = 'blackhole' ); insert into bh SELECT bid_source.auction, u.age FROM bid_source JOIN users FOR SYSTEM_TIME AS OF bid_source.proc_time AS u ON bid_source.channel = u.user_id; -
Di halaman Job O&M, di tab Deployment Details, di bagian Other Configurations area Runtime Parameter Configuration, atur parameter
table.exec.async-lookup.output-mode='ALLOW_UNORDERED'dantable.exec.async-lookup.key-ordered-enabled='true'. -
Start pekerjaan tersebut. Di tab Status, Anda dapat melihat bahwa atribut async pekerjaan tersebut adalah KEY_ORDERED:true.
table.optimizer.window-join-enabled
Parameter ini mengontrol apakah operasi window join diaktifkan. Saat diaktifkan, Flink mengoptimalkan rencana eksekusi yang sesuai sebagai window join. Untuk jendela (window) kecil, hal ini mengurangi overhead state dan meningkatkan performa. Dibandingkan dengan regular join, window join juga dapat menghindari pengiriman pesan pembaruan ke operator hilir, yang berguna untuk kasus penggunaan yang memerlukan join dengan kondisi jendela waktu kecil.
Catatan penggunaan
-
Window join memiliki batasan tambahan pada sintaks SQL dibandingkan dengan regular join, dan tidak mendukung update stream.
-
Window join memiliki latensi output lebih tinggi daripada regular join. Latensi tersebut bergantung pada ukuran jendela dan seberapa cepat watermark sumber maju.
-
Saat diaktifkan, window join berbasis event-time membuang data terlambat (late data), sedangkan regular join tidak.
-
Setelah Anda mengubah parameter ini, Anda tidak dapat melanjutkan dari checkpoint yang ada karena struktur state dasar dari kedua metode eksekusi tersebut tidak kompatibel.
Nilai yang tersedia
-
false (default): Pernyataan untuk window join dikonversi menjadi regular join untuk eksekusi.
-
true: Mengaktifkan window join. Pernyataan yang sesuai dikonversi menjadi window join untuk eksekusi.
Contoh
-
Buat Pekerjaan streaming SQL, salin kode SQL berikut, atur parameter
table.optimizer.window-join-enabledketruedengan menggunakan pernyataan SET, lalu eksekusi teks SQL tersebut untuk melihat rencana eksekusi.SET 'table.optimizer.window-join-enabled' = 'true'; CREATE TEMPORARY TABLE LeftTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '5' SECONDS ) WITH ( 'connector'='datagen' ); CREATE TEMPORARY TABLE RightTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '10' SECONDS ) WITH ( 'connector'='datagen' ); EXPLAIN SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id, COALESCE(L.window_start, R.window_start) as window_start, COALESCE(L.window_end, R.window_end) as window_end FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L JOIN ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R ON L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end;Bagian Optimized Execution Plan pada output menunjukkan bahwa rencana tersebut berisi operator WindowJoin.
== Optimized Execution Plan == Calc(select=[num AS L_Num, id AS L_Id, num0 AS R_Num, id0 AS R_Id, CASE(window_start IS NOT NULL, window_start, window_start0) AS window_start, CASE(window_end IS NOT NULL, window_end, window_end0) AS window_end]) +- WindowJoin(leftWindow=[TUMBLE(win_start=[window_start], win_end=[window_end], size=[5 min])], rightWindow=[TUMBLE(win_start=[window_start], win_end=[window_end], size=[5 min])], joinType=[InnerJoin], where=[(num = num0)], select=[id, num, window_start, window_end, id0, num0, window_start0, window_end0]) :- Exchange(distribution=[hash[num]]) : +- Calc(select=[id, num, window_start, window_end]) : +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) : +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 5000:INTERVAL SECOND)]) : +- TableSourceScan(table=[[vvp, default, LeftTable]], fields=[id, row_time, num]) +- Exchange(distribution=[hash[num]]) +- Calc(select=[id, num, window_start, window_end]) +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 10000:INTERVAL SECOND)]) +- TableSourceScan(table=[[vvp, default, RightTable]], fields=[id, row_time, num]) -
Ubah pernyataan SET dalam kode SQL untuk mengatur parameter
table.optimizer.window-join-enabledkefalseatau hapus klausa SET tersebut, lalu eksekusi teks SQL untuk melihat rencana eksekusi yang dimodifikasi.-- set to 'false' or remove this setting clause SET 'table.optimizer.window-join-enabled' = 'false'; CREATE TEMPORARY TABLE LeftTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '5' SECONDS ) WITH ( 'connector'='datagen' ); CREATE TEMPORARY TABLE RightTable ( id VARCHAR, row_time TIMESTAMP_LTZ(3), num INT, WATERMARK FOR row_time as row_time - INTERVAL '10' SECONDS ) WITH ( 'connector'='datagen' ); EXPLAIN SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id, COALESCE(L.window_start, R.window_start) as window_start, COALESCE(L.window_end, R.window_end) as window_end FROM ( SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) L JOIN ( SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES)) ) R ON L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end;Bagian Optimized Execution Plan pada output tidak lagi berisi operator WindowJoin. Operasi tersebut kini menjadi regular join.
== Optimized Execution Plan == Calc(select=[num AS L_Num, id AS L_Id, num0 AS R_Num, id0 AS R_Id, CASE(window_start IS NOT NULL, window_start, window_start0) AS window_start, CASE(window_end IS NOT NULL, window_end, window_end0) AS window_end]) +- Join(joinType=[InnerJoin], where=[((num = num0) AND (window_start = window_start0) AND (window_end = window_end0))], select=[id, num, window_start, window_end, id0, num0, window_start0, window_end0], leftInputSpec=[NoUniqueKey], rightInputSpec=[NoUniqueKey]) :- Exchange(distribution=[hash[num, window_start, window_end]]) : +- Calc(select=[id, num, window_start, window_end]) : +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) : +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 5000:INTERVAL SECOND)]) : +- TableSourceScan(table=[[vvp, default, LeftTable]], fields=[id, row_time, num]) +- Exchange(distribution=[hash[num, window_start, window_end]]) +- Calc(select=[id, num, window_start, window_end]) +- WindowTableFunction(window=[TUMBLE(time_col=[row_time], size=[5 min])]) +- WatermarkAssigner(rowtime=[row_time], watermark=[(row_time - 10000:INTERVAL SECOND)]) +- TableSourceScan(table=[[vvp, default, RightTable]], fields=[id, row_time, num])
Dokumentasi terkait
Mengapa data macet di operator LocalGroupAggregate tanpa output?